收藏 | 多标签分类实用的经典方法
Posted 人工智能博士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了收藏 | 多标签分类实用的经典方法相关的知识,希望对你有一定的参考价值。
点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :机器之心
这可能是最实用的多标签分类小贴士。
众所周知,二分类任务旨在将给定的输入分为 0 和 1 两类。而多标签分类(又称多目标分类)一次性地根据给定输入预测多个二分类目标。例如,模型可以预测给定的图片是一条狗还是一只猫,同时预测其毛皮是长还是短。
在多分类任务中,预测目标是互斥的,这意味着一个输入可以对应于多个分类。本文将介绍一些可能提升多标签分类模型性能的小技巧。
模型评估函数
通过在「每一列」(分类标签)上计算模型评估函数并取得分均值,我们可以将大多数二分类评估函数用于多标签分类任务。对数损失或二分类交叉熵就是其中一种评估函数。为了更好地考虑到类别不均衡现象,我们可以使用 ROC-AUC 作为评估函数。
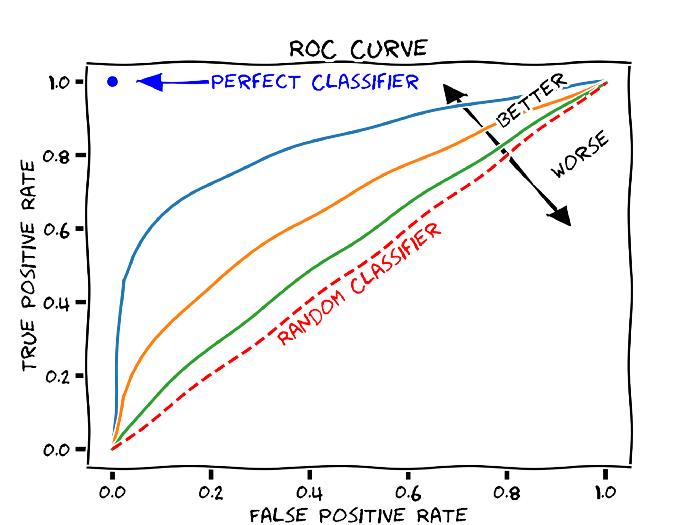
图 1:ROC-AUC 曲线
建模技巧
在介绍构建特征的技巧之前,本文将介绍一些设计适用于多标签分类场景的模型的小技巧。
对于大多数非神经网络模型而言,我们唯一的选择是为每个目标训练一个分类器,然后将预测结果融合起来。为此,「scikit-learn」程序库提供了一个简单的封装类「OneVsRestClassifier」。尽管这个封装类可以使分类器能够执行多标签任务,但我们不应采用这种方法,其弊端如下:(1)我们会为每个目标训练一个新模型,因此训练时间相对较长。(2)模型无法学习不同标签之间的关系或标签的相关性。
第二个问题可以通过执行一个两阶段训练过程来解决。其中,我们将目标的预测结果和原始特征相结合,作为第二阶段训练的输入。这样做的缺点是,由于需要训练的模型数量是之前的两倍,训练时间将大幅度提升。神经网络(NN)则适用于这种场景,其中标签的数量即为网络中输出神经元的数量。我们可以直接将任意的二分类损失应用于神经网络模型,同时该模型会输出所有的目标。此时,我们只需要训练一个模型,且网络可以通过输出神经元学习不同标签的相关性,从而解决上文中提出的非神经网络模型的两个问题。
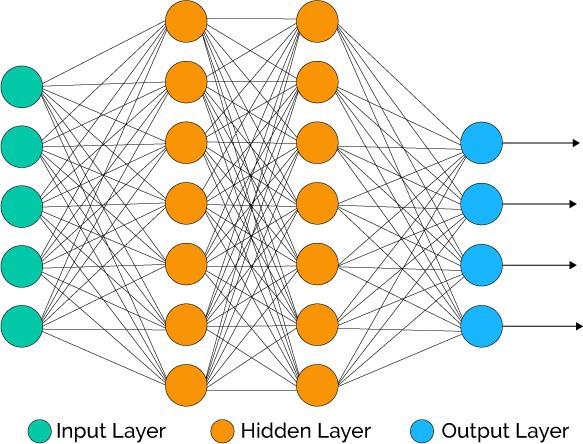
图 2:神经网络
有监督的特征选择方法
在开始特征工程或特征选择之前,需要对特征进行归一化和标准化处理。使用「scikit-learn」库中的「Quantile Transformer」将减小数据的偏度,使特征服从正态分布。此外,还可以通过对数据采取「减去均值,除以标准差」的操作,对特征进行标准化处理。该过程与「Quantile Transformer」完成了类似的工作,其目的都是对数据进行变换,使数据变得更加鲁棒。然而,「Quantile Transformer」的计算开销较高。
大多数算法都是为单一目标设计的,因此使用有监督特征选择方法稍微有些困难。为了解决这个问题,我们可以将多标签分类任务转化为多类分类问题。「Label Powerset」就是其中一种流行的解决方案,它将训练数据中的每一个独特的标签组合转化为一个类。「scikit-multilearn」程序库中包含实现该方案的工具。
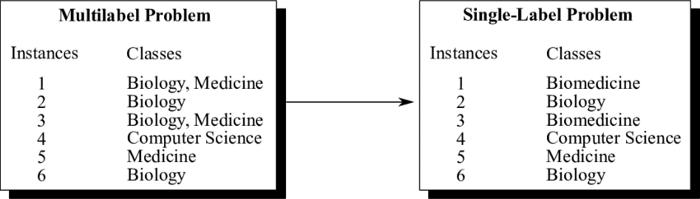
图 3:Label Powerset 方法
在完成转换后,我们可以使用「信息增益」和「卡方」等方法来挑选特征。尽管这种方法是可行的,但是却很难处理上百甚至上千对不同的独特标签组合。此时,使用无监督特征选择方法可能更合适。
无监督特征选择方法
在无监督方法中,我们不需要考虑多标签任务的特性,这是因为无标签方法并不依赖于标签。典型的无监督特征选择方法包括:
主成分分析(PCA)或其它的因子分析方法。此类方法会去除掉特征中的冗余信息,并为模型抽取出有用的特征。请确保在使用 PCA 之前对数据进行标准化处理,从而使每个特征对分析的贡献相等。另一个使用 PCA 的技巧是,我们可以将该算法简化后的数据作为模型可选择使用的额外信息与原始数据连接起来,而不是直接使用简化后的数据。
方差阈值。这是一种简单有效的降低特征维度的方法。我们丢弃具有低方差或离散型的特征。可以通过找到一个更好的选择阈值对此进行优化,0.5 是一个不错的初始阈值。
聚类。通过根据输入数据创建聚类簇来构建新特征,然后将相应的聚类分配给每一行输入数据,作为一列新的特征。
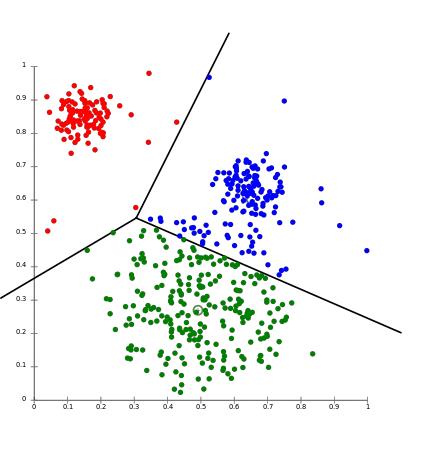
图 4:K - 均值聚类
上采样方法
当分类数据高度不均衡时,可以使用上采样方法为稀有类生成人造样本,从而让模型关注稀有类。为了在多标签场景下创建新样本,我们可以使用多标签合成少数类过采样技术(MLSMOTE)。
代码链接:https://github.com/niteshsukhwani/MLSMOTE
该方法由原始的 SMOTE 方法修改而来。在生成少数类的数据并分配少数标签后,我们还通过统计每个标签在相邻数据点中出现的次数来生成其它相关的标签,并保留出现频次高于一半统计的数据点的标签。
原文链接:https://andy-wang.medium.com/bags-of-tricks-for-multi-label-classification-dc54b87f79ec
---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


点个在看支持一下吧

以上是关于收藏 | 多标签分类实用的经典方法的主要内容,如果未能解决你的问题,请参考以下文章