conda安装与使用--ubuntu20.04
Posted 梦中的飞行家
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了conda安装与使用--ubuntu20.04相关的知识,希望对你有一定的参考价值。
不同的Python项目可能依赖不同版本的包,如项目1依赖numpy 1.20,项目2依赖numpy 1.23。如果想在系统中同时运行项目1和项目2,环境的配置是个问题。conda可以针对项目1和项目2分别生成两个相互独立的虚拟环境,大大降低了环境配置的难度。
conda安装
安装环境:ubuntu20.04
安装步骤:
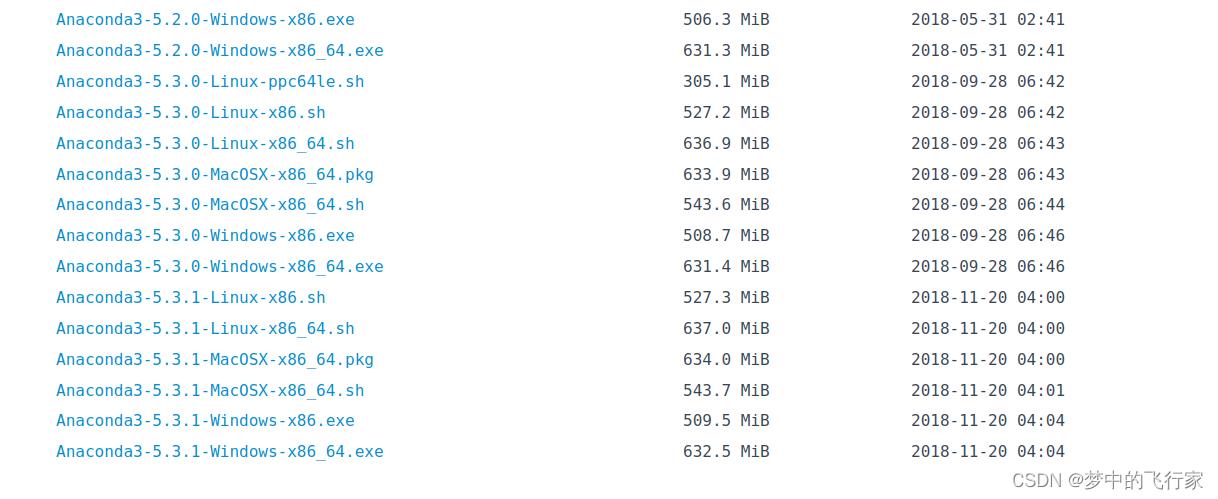
1.安装程序下载。为加快下载速度,从国内大学开源镜像进行下载。页面拉到最下面,选择最新发布的Linux-x86_64.sh下载。(PS:x86是32为处理器架构,x86_64是64位处理器架构)
2.程序安装。
#进入安装程序所在目录
cd /Downloads
#运行安装程序,按照操作指示依次选择:回车、q、yes、回车、yes,这样程序安装在home/miniconda3(文件名可能不同,根据安装包变化)目录下,并在~/.bashrc中自动添加系统路径
bash Anaconda3-5.3.1-Linux-x86_64.sh
#为了能让系统找到conda程序
source ~/.bashrc
3.更换国内源
这一步的目的是加快库文件的下载速度,国内源地址
#生成 ~/.condarc文件
conda config --set show_channel_urls yes
gedit ~/.condarc
#清空文件,并将以下内容复制到文件中
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch-lts: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
conda卸载
#miniconda3为安装时生成的安装路径的名字
rm -rf miniconda3
基本操作
#创建名为 my_env的虚拟环境,指定Python 和 numpy的版本
conda create -n my_env python=3.8 numpy=1.23
#查看现有的虚拟环境
conda info -e
#切换到my_env虚拟环境下
conda activate my_env
#查看shapely包可用版本
conda search shapely
#安装shapely版本1.8.4
conda install shapely=1.8.4
#查看当前虚拟环境的信息
conda info
#查看当前虚拟环境下已安装的包
conda list
#退出当前虚拟环境
conda deactivate
参考链接
更换源:https://cloud.tencent.com/developer/ask/sof/1181823
安装:https://blog.csdn.net/weixin_64316191/article/details/127435729
安装:https://www.bilibili.com/read/cv8956636?spm_id_from=333.999.0.0
讲解:https://www.bilibili.com/video/BV1Mv411x775/?spm_id_from=333.999.0.0&vd_source=8f7ba44240673347d961ba9d0df2174f
使用 conda 进行全新 ubuntu 20.04 安装的 Segfault
【中文标题】使用 conda 进行全新 ubuntu 20.04 安装的 Segfault【英文标题】:Segfault with for fresh ubuntu 20.04 install using conda 【发布时间】:2021-03-30 10:00:51 【问题描述】:在全新安装的 ubuntu 20.04.2 的 miniconda 环境中运行时,python 解释器会出现段错误。这似乎是间歇性发生的,无论是在环境的 conda 设置期间运行“pip”时,还是在执行如下代码期间。
运行以下代码时总是会发生段错误,该代码从文件中读取文本并对结果进行标记。段错误位置从运行更改为运行。此外,完全相同的代码可以在另一台具有相同 conda 环境的 ubuntu 18.04 计算机上运行。
核心转储总是指向 python 中 unicodeobject.c 文件中的某个函数,但确切的函数会随着崩溃而变化。至少有一次崩溃有一个明确的取消引用指针 0x0,“unicode 对象”应该在哪里。
我的猜测是某些原因导致 python 解释器丢弃指向 unicode 的对象,而它仍在处理导致段错误。但是解释器或 NLTK 中的任何错误应该已经被更多用户注意到了,我找不到任何有类似问题的人。
没有解决问题的尝试:
-
重新格式化并重新安装 ubuntu
切换到ubuntu 18.04(在这台电脑上,另一台18.04的电脑可以正常运行代码)
更换硬件,以确保 RAM 或 SSD 磁盘没有损坏
更改为 python 版本 3.8.6、3.8.8、3.9.2
将 conda 环境从正常工作的计算机克隆到损坏的计算机
附加的是故障处理程序的一个堆栈跟踪以及来自 gdb 的相应核心转储堆栈跟踪。
(eo) axel@minimind:~/test$ python tokenizer_mini.py
2021-03-30 11:10:15.588399: W tensorflow/stream_executor/platform/default/dso_loader.cc:60] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory
2021-03-30 11:10:15.588426: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
Fatal Python error: Segmentation fault
Current thread 0x00007faa73bbe740 (most recent call first):
File "tokenizer_mini.py", line 36 in preprocess_string
File "tokenizer_mini.py", line 51 in <module>
Segmentation fault (core dumped)
#0 raise (sig=<optimized out>) at ../sysdeps/unix/sysv/linux/raise.c:50
#1 <signal handler called>
#2 find_maxchar_surrogates (num_surrogates=<synthetic pointer>, maxchar=<synthetic pointer>,
end=0x4 <error: Cannot access memory at address 0x4>, begin=0x0)
at /home/conda/feedstock_root/build_artifacts/python-split_1613835706476/work/Objects/unicodeobject.c:1703
#3 _PyUnicode_Ready (unicode=0x7f7e4e04d7f0)
at /home/conda/feedstock_root/build_artifacts/python-split_1613835706476/work/Objects/unicodeobject.c:1742
#4 0x000055cd65f6df6a in PyUnicode_RichCompare (left=0x7f7e4cf43fb0, right=<optimized out>, op=2)
at /home/conda/feedstock_root/build_artifacts/python-split_1613835706476/work/Objects/unicodeobject.c:11205
#5 0x000055cd6601712a in do_richcompare (op=2, w=0x7f7e4e04d7f0, v=0x7f7e4cf43fb0)
at /home/conda/feedstock_root/build_artifacts/python-split_1613835706476/work/Objects/object.c:726
#6 PyObject_RichCompare (op=2, w=0x7f7e4e04d7f0, v=0x7f7e4cf43fb0)
at /home/conda/feedstock_root/build_artifacts/python-split_1613835706476/work/Objects/object.c:774
#7 PyObject_RichCompareBool (op=2, w=0x7f7e4e04d7f0, v=0x7f7e4cf43fb0)
at /home/conda/feedstock_root/build_artifacts/python-split_1613835706476/work/Objects/object.c:796
#8 list_contains (a=0x7f7e4e04b4c0, el=0x7f7e4cf43fb0)
at /home/conda/feedstock_root/build_artifacts/python-split_1613835706476/work/Objects/listobject.c:455
#9 0x000055cd660be41b in PySequence_Contains (ob=0x7f7e4cf43fb0, seq=0x7f7e4e04b4c0)
at /home/conda/feedstock_root/build_artifacts/python-split_1613835706476/work/Objects/abstract.c:2083
#10 cmp_outcome (w=0x7f7e4e04b4c0, v=0x7f7e4cf43fb0, op=<optimized out>, tstate=<optimized out>)
at /home/conda/feedstock_root/build_artifacts/python-split_1613835706476/work/Python/ceval.c:5082
#11 _PyEval_EvalFrameDefault (f=<optimized out>, throwflag=<optimized out>)
at /home/conda/feedstock_root/build_artifacts/python-split_1613835706476/work/Python/ceval.c:2977
#12 0x000055cd6609f706 in PyEval_EvalFrameEx (throwflag=0, f=0x7f7e4f4d3c40)
at /home/conda/feedstock_root/build_artifacts/python-split_1613835706476/work/Python/ceval.c:738
#13 function_code_fastcall (globals=<optimized out>, nargs=<optimized out>, args=<optimized out>, co=<optimized out>)
at /home/conda/feedstock_root/build_artifacts/python-split_1613835706476/work/Objects/call.c:284
#14 _PyFunction_Vectorcall (func=<optimized out>, stack=<optimized out>, nargsf=<optimized out>, kwnames=<optimized out>)
at /home/conda/feedstock_root/build_artifacts/python-split_1613835706476/work/Objects/call.c:411
#15 0x000055cd660be54f in _PyObject_Vectorcall (kwnames=0x0, nargsf=<optimized out>, args=0x7f7f391985b8, callable=0x7f7f39084160)
at /home/conda/feedstock_root/build_artifacts/python-split_1613835706476/work/Include/cpython/abstract.h:115
#16 call_function (kwnames=0x0, oparg=<optimized out>, pp_stack=<synthetic pointer>, tstate=0x55cd66c2e880)
at /home/conda/feedstock_root/build_artifacts/python-split_1613835706476/work/Python/ceval.c:4963
#17 _PyEval_EvalFrameDefault (f=<optimized out>, throwflag=<optimized out>)
at /home/conda/feedstock_root/build_artifacts/python-split_1613835706476/work/Python/ceval.c:3500
#18 0x000055cd6609e503 in PyEval_EvalFrameEx (throwflag=0, f=0x7f7f39198440)
at /home/conda/feedstock_root/build_artifacts/python-split_1613835706476/work/Python/ceval.c:4298
#19 _PyEval_EvalCodeWithName (_co=<optimized out>, globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=<optimized out>, kwnames=<optimized out>, kwargs=<optimized out>, kwcount=<optimized out>, kwstep=<optimized out>,
defs=<optimized out>, defcount=<optimized out>, kwdefs=<optimized out>, closure=<optimized out>, name=<optimized out>,
qualname=<optimized out>) at /home/conda/feedstock_root/build_artifacts/python-split_1613835706476/work/Python/ceval.c:4298
#20 0x000055cd6609f559 in PyEval_EvalCodeEx (_co=<optimized out>, globals=<optimized out>, locals=<optimized out>,
args=<optimized out>, argcount=<optimized out>, kws=<optimized out>, kwcount=0, defs=0x0, defcount=0, kwdefs=0x0, closure=0x0)
at /home/conda/feedstock_root/build_artifacts/python-split_1613835706476/work/Python/ceval.c:4327
#21 0x000055cd661429ab in PyEval_EvalCode (co=<optimized out>, globals=<optimized out>, locals=<optimized out>)
at /home/conda/feedstock_root/build_artifacts/python-split_1613835706476/work/Python/ceval.c:718
#22 0x000055cd66142a43 in run_eval_code_obj (co=0x7f7f3910f240, globals=0x7f7f391fad80, locals=0x7f7f391fad80)
at /home/conda/feedstock_root/build_artifacts/python-split_1613835706476/work/Python/pythonrun.c:1165
#23 0x000055cd6615c6b3 in run_mod (mod=<optimized out>, filename=<optimized out>, globals=0x7f7f391fad80, locals=0x7f7f391fad80,
flags=<optimized out>, arena=<optimized out>)
at /home/conda/feedstock_root/build_artifacts/python-split_1613835706476/work/Python/pythonrun.c:1187
--Type <RET> for more, q to quit, c to continue without paging--
#24 0x000055cd661615b2 in pyrun_file (fp=0x55cd66c2cdf0, filename=0x7f7f391bbee0, start=<optimized out>, globals=0x7f7f391fad80,
locals=0x7f7f391fad80, closeit=1, flags=0x7ffe3ee6f8e8)
at /home/conda/feedstock_root/build_artifacts/python-split_1613835706476/work/Python/pythonrun.c:1084
#25 0x000055cd66161792 in pyrun_simple_file (flags=0x7ffe3ee6f8e8, closeit=1, filename=0x7f7f391bbee0, fp=0x55cd66c2cdf0)
at /home/conda/feedstock_root/build_artifacts/python-split_1613835706476/work/Python/pythonrun.c:439
#26 PyRun_SimpleFileExFlags (fp=0x55cd66c2cdf0, filename=<optimized out>, closeit=1, flags=0x7ffe3ee6f8e8)
at /home/conda/feedstock_root/build_artifacts/python-split_1613835706476/work/Python/pythonrun.c:472
#27 0x000055cd66161d0d in pymain_run_file (cf=0x7ffe3ee6f8e8, config=0x55cd66c2da70)
at /home/conda/feedstock_root/build_artifacts/python-split_1613835706476/work/Modules/main.c:391
#28 pymain_run_python (exitcode=0x7ffe3ee6f8e0)
at /home/conda/feedstock_root/build_artifacts/python-split_1613835706476/work/Modules/main.c:616
#29 Py_RunMain () at /home/conda/feedstock_root/build_artifacts/python-split_1613835706476/work/Modules/main.c:695
#30 0x000055cd66161ec9 in Py_BytesMain (argc=<optimized out>, argv=<optimized out>)
at /home/conda/feedstock_root/build_artifacts/python-split_1613835706476/work/Modules/main.c:1127
#31 0x00007f7f3a3620b3 in __libc_start_main (main=0x55cd65fe3490 <main>, argc=2, argv=0x7ffe3ee6fae8, init=<optimized out>,
fini=<optimized out>, rtld_fini=<optimized out>, stack_end=0x7ffe3ee6fad8) at ../csu/libc-start.c:308
#32 0x000055cd660d7369 in _start () at /home/conda/feedstock_root/build_artifacts/python-split_1613835706476/work/Python/ast.c:937
使用的 conda 环境如下,使用 Miniconda3-py38_4.9.2-Linux-x86_64.sh (请注意,在设置 conda 环境期间有时会出现段错误,因此它可能与 env 无关)
name: eo
channels:
- conda-forge
- defaults
dependencies:
- python=3.8.8
- pip=20.3.1
- pip:
- transformers==4.3.2
- tensorflow_gpu==2.4.0
- scikit-learn==0.23.2
- nltk==3.5
- matplotlib==3.2.1
- seaborn==0.11.0
- tensorflow-addons==0.11.2
- tf-models-official==2.4.0
- gspread==3.6.0
- oauth2client==4.1.3
- ipykernel==5.4.2
- autopep8==1.5.4
- torch==1.7.1
下面的代码一致地重现了这个问题,读取的文件是包含 unicode 文本的简单文本文件:
from nltk.tokenize import wordpunct_tokenize
from tensorflow.keras.preprocessing.text import Tokenizer
from nltk.stem.snowball import SnowballStemmer
from nltk.corpus import stopwords
import pickle
from pathlib import Path
import faulthandler
faulthandler.enable()
def load_data(root_path, feature, index):
feature_root = root_path / feature
dir1 = str(index // 10_000)
base_path = feature_root / dir1 / str(index)
full_path = base_path.with_suffix('.txt')
data = None
with open(full_path, 'r', encoding='utf-8') as f:
data = f.read()
return data
def preprocess_string(text, stemmer, stop_words):
word_tokens = wordpunct_tokenize(text.lower())
alpha_tokens = []
for w in word_tokens:
try:
if (w.isalpha() and w not in stop_words):
alpha_tokens.append(w)
except:
print("Something went wrong when handling the word: ", w)
clean_tokens = []
for w in alpha_tokens:
try:
word = stemmer.stem(w)
clean_tokens.append(word)
except:
print("Something went wrong when stemming the word: ", w)
clean_tokens.append(w)
return clean_tokens
stop_words = stopwords.words('english')
stemmer = SnowballStemmer(language='english')
tokenizer = Tokenizer()
root_path = '/srv/patent/EbbaOtto/E'
for idx in range(0, 57454):
print(f'Processed idx/57454', end='\r')
desc = str(load_data(Path(root_path), 'clean_description', idx))
desc = preprocess_string(desc, stemmer, stop_words)
tokenizer.fit_on_texts([desc])
【问题讨论】:
抱歉在错误的部分发帖,但我不确定这是否是一个错误,鉴于我不使用这种情况,在这种情况下没有其他人会遇到同样的问题似乎非常不可能有什么不寻常的。因此,一般要求输入或帮助。关于在哪里发布此错误修复的任何意见? 崩溃显示缺少 CUDA 库。是否安装了 CUDA 工具包? CUDA 不是故意安装的,因为我不想让 gpu 参与,直到崩溃被排序。所以现在它正在使用带有 CPU 而不是 GPU 的 tensorflow。警告明确提到如果您对 GPU 不感兴趣,请忽略上述行。 我知道这一点,但 tensorflow 将在 CPU 上运行,请参阅此问题以了解说明:***.com/questions/52624703/… 我尝试使用 tensorflow=2.4.0 而没有 GPU 相同的结果。这不是这里的问题。我已经重新安装了 conda 并尝试使用 nightly 和 2.3 之间的大多数 tf 版本,有和没有 gpu 部件。 还要注意,错误出现在“pip install”中,不只是运行这段代码的时候,这也说明错误不在tensorflow中。或者 tensorflow 的安装方式。 【参考方案1】:为了任何搜索类似问题的人。这最终被解决为 CPU 中的硬件故障。用另一个相同品牌的 CPU 替换 CPU 可以解决此问题。有趣的是,Windows 计算机上不存在此问题。
【讨论】:
以上是关于conda安装与使用--ubuntu20.04的主要内容,如果未能解决你的问题,请参考以下文章