python学习——pandas库的使用,仅需要这一篇就足够了
Posted 云晓-
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python学习——pandas库的使用,仅需要这一篇就足够了相关的知识,希望对你有一定的参考价值。
pandas学习目录
- pandas
pandas
- Pandas是基于NumPy的数据分析模块
- Pandas纳入了大量库和一些标准的数据模型,提供了高效操作大型数据集所需的工具
- Pandas提供了大量能使我们快速便捷处理数据的函数和方法
- Pandas的数据结构
- Series:带标签的一维数组,与Numpy中的一维array类似。与列表也很相近。
区别是:列表中的元素可以是不同的数据类型,而array和Series中则只允许存储相同的数据类型,这样可以更有效的使用内存,提高运算效率。 - Time-Series:以时间为索引的Series,特殊的一类Series
- DataFrame:带标签的二维的表格型数据结构,可以将DataFrame理
解为Series的容器 - Panel:带标签的三维的数组,可以理解为DataFrame的容器
- Series:带标签的一维数组,与Numpy中的一维array类似。与列表也很相近。
1 Series(序列)
- Series(序列)是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成
- Series的字符串表现形式为:索引在左边,值在右边。如果没有为数据指定索引,会自动创建一个0到N-1(N为数据的长度)的整数型索引
1.1 基本概念

1.1.1 索引 ser[‘a’]、ser.a、ser[0]、ser.get(‘a’)
from pandas import Series,DataFrame
s=Series([1,2,3,4],index=['a','b','c','d']) #指定索引,显式索引
#索引,获取单个值
s['b']
s.b
s.get('b')
s[1]


s=Series([3,4,5,6],index=['a','a','b','b']) #索引可以重复,但是尽量不要这样做
s

1.1.2 切片
切片不会改变序列数据类型
1.1.2.1 基于标签切片的时候,切片区间全闭

1.1.2.2 基于位置的切片语法 切片区间左闭右开

1.1.3 选择和过滤
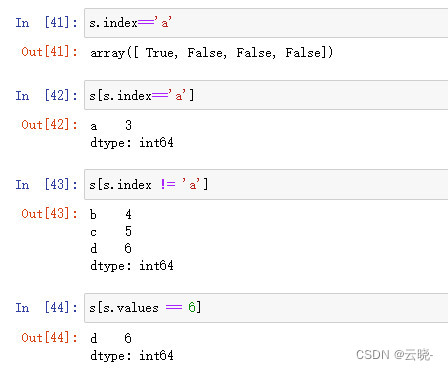
1.1.3.1 直接通过Series进行比较

1.1.3.2 通过Series.index 或者 Series.values进行比较
1.2 序列创建
数据(序列、数组、字典、标量)、索引、名字
1.2.1 列表,元组(一维)

1.2.2 标量
s1=Series(5,index=['a','b','c','d']) #标量,自动重复以匹配索引长度
s1

1.2.3 数组
s1=Series(np.arange(1,5),index=['a','b','c','d']) #数组
s1

1.2.4 字典
dict1='a':1,'b':3,'c':5,'d':8
s1=Series(dict1) #不指定索引,默认以字典的key作为索引,字典值作为值
s1

1.3 序列、索引名字及属性
1.3.1 序列的名字和索引名字

1.3.2 序列的属性
ser2.name #名字
ser2.values #数据
ser2.index #索引
ser2.dtype #series的数据类型

1.4 序列的运算
1.4.1 序列运算保留索引

1.4.2 序列运算,索引自动对齐


2 DataFrame
- DataFrame可以看成是以Series组成的字典。它和Series的区别在于,不但具有行索引,且具有列索引
- DataFrame是二维数据结构,即数据以行和列的表格方式排列
2.1 构建DataFrame
2.1.1 二维列表创建
通过二维列表,二维元组直接创建,默认行列索引
data1=[[1, 2, 3],[4, 5, 6],[7, 8, 9]] #二维列表创建,二维元组
d1=DataFrame(data1) #默认行索引和列索引
d1

创建dataframe后添加行索引和列索引
d1.index=['a','b','c'] #创建dataframe后添加行索引和列索引
d1.columns=['one','two','three']
d1

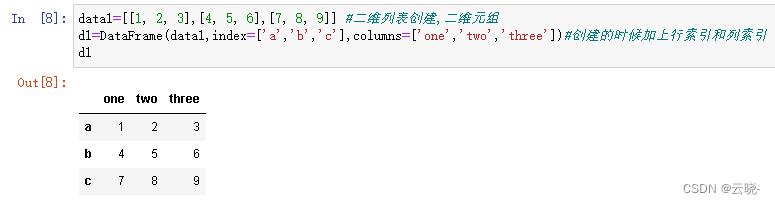
创建dataframe的时候加上行索引和列索引
data1=[[1, 2, 3],[4, 5, 6],[7, 8, 9]] #二维列表创建,二维元组
d1=DataFrame(data1,index=['a','b','c'],columns=['one','two','three'])#创建的时候加上行索引和列索引
d1
2.1.2 二维数组创建
创建dataframe时,默认行列索引
df2=DataFrame(np.arange(16).reshape(4,4)) #数组转换为dataframe
df2

创建dataframe时,添加行列索引名

2.1.3 等长列表、 元组、 数组、 序列组成的字典创建
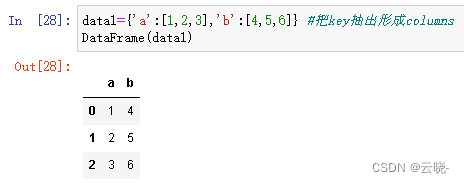
等长列表组成的字典
data1='a':[1,2,3],'b':[4,5,6] #把key抽出形成columns
DataFrame(data1)
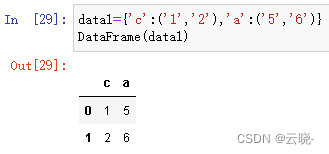
等长元组组成的字典
等长数组组成的字典
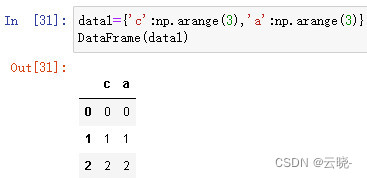
等长序列组成的字典

2.1.4 字典组成的字典创建
dist_dict='shanghai':2015:10,2016:11,2018:12,'beijing':2015:102,2016:103,2017:109
DataFrame(dist_dict) #外层的key形成columns,里层的key成为index

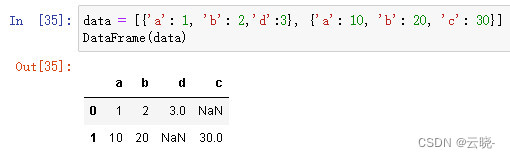
2.1.5 字典的列表创建
data = ['a': 1, 'b': 2,'d':3, 'a': 10, 'b': 20, 'c': 30]
DataFrame(data)
2.1.6 Series 创建DataFrame
data2 = [Series([1, 2],index=['a','b']),Series([1,2],index=['a','c'])]
DataFrame(data2)

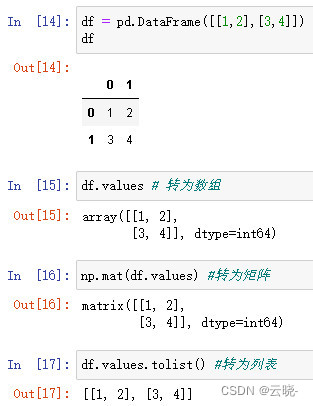
2.2 二维结构数据转换
二维列表、二维数组、矩阵、dataframe之间互相转换
| 二维列表 | 二维数组 | 矩阵 | dataframe | |
|---|---|---|---|---|
| 二维列表 L | - | np.array(L) | np.mat(L) | pd.DataFrame(L) |
| 二维数组 a | a.tolist() | - | np.mat(a) | pd.DataFrame(a) |
| 矩阵 m | m.tolist() | np.array(m) | - | pd.DataFrame(m) |
| dataframe | df.values.tolist() | df.values | np.mat(df.values) | - |
2.2.1 二维列表转其他

2.2.2 二维数组转其他

2.2.3 矩阵转其他

2.2.4 dataframe转其他
2.3 数据的读写
filepath_or_buffer: 文件,
sep=',', 数据分隔符
delimiter=None, 同上
header='infer', 表头/列名 ,默认,用数据的第一行作为列名. None就是不用数据列名
names=None, 列名
index_col=None, 用哪一列作为行索引
2.3.1 读写csv文件
csv文件轻量化的文件格式,非常小,读写的时候速度都比较快
data1=[[1, 2, 3],[4, 5, 6],[7, 8, 9]] #二维列表创建,二维元组
d1=DataFrame(data1,index=['a','b','c'],columns=['one','two','three']) #创建的时候加上行索引和列索引
d1
#写
d1.to_csv('d1.csv',sep=',', header=True) #写入csv,带header,sep指定分割符,一般使用','
#读
pd.read_csv('d1.csv',index_col=0) #将第0列设置为索引
-----------------------------------------------------------------------
#写
d1.to_csv('d2.csv',sep=',', header=False) #写入csv,不带header
#读
pd.read_csv('d2.csv',index_col=0,names=['one','two','three']) #names参数增加列名(在读的时候列名用names)
2.3.2 读写excel文件
#写到excel中的某个表格
d1.to_excel('d1.xlsx',sheet_name='d1_sheet')
#读取excel中的某个表格
pd.read_excel('d1.xlsx',sheet_name='d1_sheet',index_col=0)
#写到多个表格,上下文管理语句
with pd.ExcelWriter('output.xlsx') as writer:
d1.to_excel(writer, sheet_name='d1')
d2.to_excel(writer, sheet_name='iris')
2.3.3 读html文件
df1=pd.read_html('http://www网址')
2.3.4 读粘贴板数据
pd.read_clipboard() #从粘贴板读取数据
2.4 数据的查看
df.head() #默认前5行,想查看前几行,括号中写几
df.tail() #默认尾部5行,想查看尾部几行,括号中写几
df.sample(n = 4) #随机的抽取,n = 4随机抽取4行
df.sample(frac=0.2, replace=True, weights=df1.列名, random_state=0) #抽取20%的数据;可放回;权重(有多少条数据就应该有多少个数进行对应);随机数种子
df.shape #形状
查看数据框的形状,得到一个元组,元组中的值表示数据框的行数和列数
df.dtypes #查看数据类型
df.isnull() #缺失值
df.info() #详细信息
详细信息,包括数据类型以及缺失值
注意字符串字段类型Dtype 显示 object而不是str
因为存储的地址(有固定位宽),而不是数据本身;
str类型的值长度并不固定,不知道应该赋予多少位宽,所以显示的类型是object
df.index 行索引
df.columns 列名
2.5 索引和切片
2.5.1 行的选择
隐式索引,默认的索引选择行
df[:1] #选择第一行,默认的索引选择行


显示索引,选取索引名


2.5.2 列的选择
df['列名'] #选出的是序列
df.列名 #选出的是序列
df[['列名']] #选择一列,dataframe
df[['列名1','列名2']] #选择多列


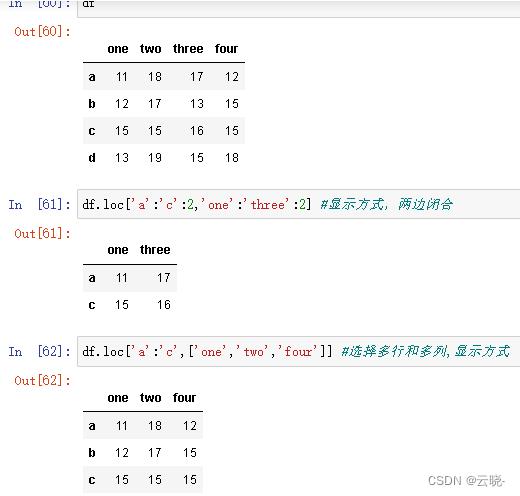
2.5.3 行,列的选择:loc方式 显式
用的是数据框中能看到的行索引和列索引,左闭右闭
df.loc[ 行标签信息,列标签信息 ]#行列标签注意带有引号
#如果只对列有要求,行信息不可以省略,用冒号表示全部都要

2.5.4 行,列的选择:iloc方式 隐式
用的是数据在表中的位置索引,左闭右开
df.iloc[行位置信息,列位置信息]
df1.iloc[1:3,0:2] #两部分参数,对行的需求和对列的需求
df1.iloc[1:3]#如果只对行有要求,列信息可以省略
df1.iloc[:,[2,4]] #如果只对列有要求,行信息不可以省略,用冒号表示全部都要


2.5.5 过滤
选择满足条件的行

选择满足条件的列

选择满足条件的行和列

2.5.6 索引设置
将某列设置为索引:set_index

恢复默认索引:reset_index
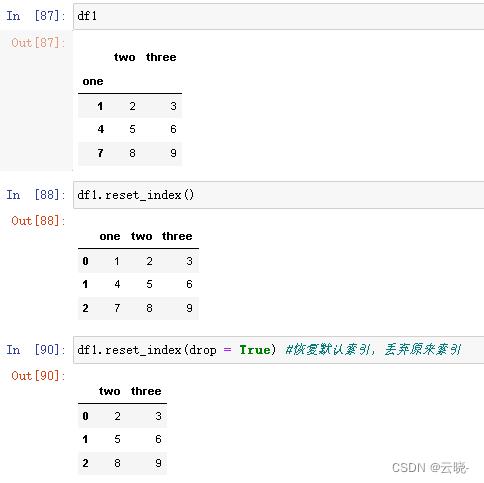
创建一个适应新索引的新对象:reindex
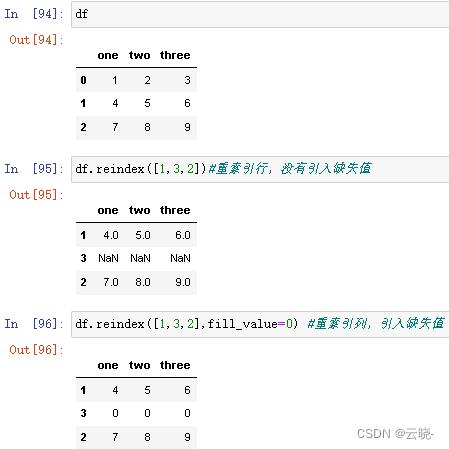
2.5.7 修改索引/列名
参数:
index:修改行索引
columns:修改列索引
也可以支持函数,或者是字典映射

2.6 dataframe的增加和删除
2.6.1 新增行
df.loc['index名'] = 数据 #数据长度要一致

2.6.2 新增列
df['列名'] = 数据
df.insert(序号,'列名',数据)


2.6.3 删除行或列
#删除 要不是index 就是columns
df.drop('index名',axis=0) #删除行,默认情况,axis=0,新生成操作
df.drop('列名',axis=1) #删除列
drop #删除列/行
df.drop(index=[1,2]) #删除行
df.drop(columns=["列名"]) #删除列
del df['列名'] #直接在原数据中删除该列
df.pop("列名") #弹出删除列
df.drop(‘index名’,axis=0) #删除行,默认情况,axis=0,新生成操作
df.drop(‘列名’,axis=1) #删除列

 df.drop(index=[1,2]) #删除行
df.drop(index=[1,2]) #删除行
df.drop(columns=[“列名”]) #删除列

del df[‘列名’] #直接在原数据中删除该列

df.pop(“列名”) #弹出删除列

2.7 算术运算和对齐
2.7.1 dataframe之间相加
#dataframe的运算,索引自动对齐,行索引对齐,列索引对齐,不足的部分引入缺失值
df1 = DataFrame([
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]],
index=['a','c','b'],columns=['one','two','three'])
df2 = DataFrame(np.arange(0,16).reshape(4,4),
index=['a','b','c','d'],columns=['one','two','three','four'])
df1+df2 #直接相加

df1.add(df2,fill_value=0) #调用方法,对有缺失的数据进行填充,填充完再进行相加
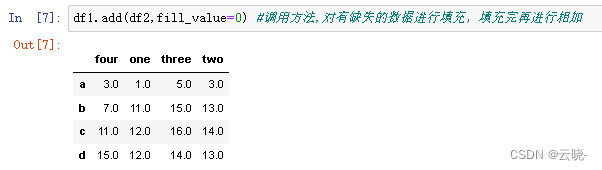
2.7.2 dataframe和数相加,每一个元素都进行操作

2.7.3 映射:apply,map,applymap
apply:针对行和列操作,可以对dataframe,可以对序列
map:对序列中的单个元素进行操作
applymap:对dataframe中的单个元素进行操作
2.7.3.1 apply:针对行和列操作,可以对dataframe,可以对序列
- apply对dataframe

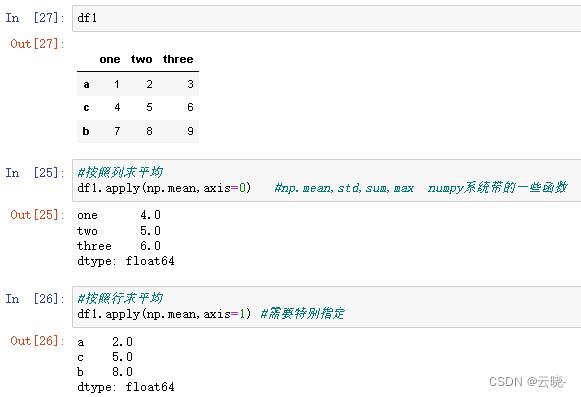
2.apply对序列

2.7.3.2 map:对序列中的单个元素进行操作
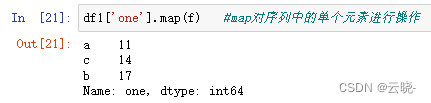
2.7.3.3 applymap:对dataframe中的单个元素进行操作

Python Pandas库的学习
今天我们来继续讲解Python中的Pandas库的基本用法
那么我们如何使用pandas对数据进行排序操作呢?
food.sort_values("Sodium_(mg)",inplace= True) print(food["Sodium_(mg)"]) food.sort_values("Sodium_(mg)",inplace=True,ascending= False) print(food["Sodium_(mg)"])
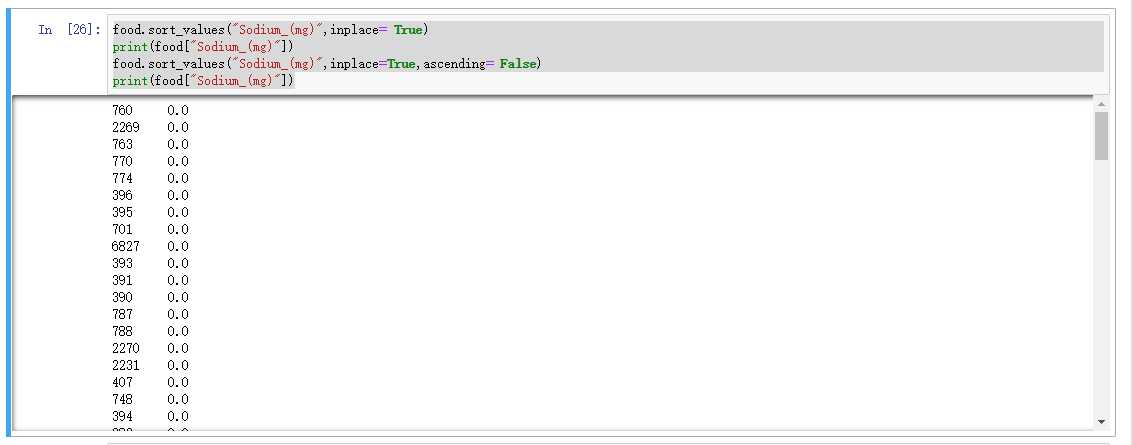
我们对food,进行sort_values方法,会自动帮我们排序,第一个参数"Sodium_(mg)"是我们数据中的列名
意思是说,你要对哪一列数据进行排序,inplace 参数的意思是,你需要生成一个新的数据,还是在原来的基础上进行,可以通过该参数指定
而sort_values排序的时候,就默认从小到大进行排序。
那么我们想做一个从大到小的排序如何做呢?
ascending这个参数,是指定一个排序升降序。在这里指定,默认该参数为True,也就是从小到大
那么我们在上面的代码中可以看到,ascending参数设置为Flase以后,即是从大到小

下面我们讲个点单的例子,泰坦尼克号小案例
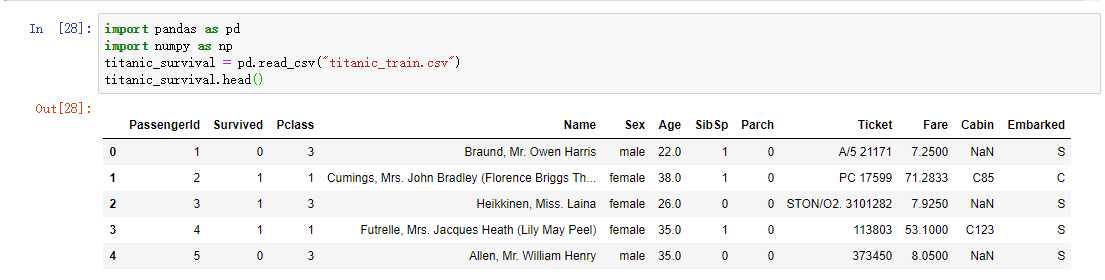
import pandas as pd import numpy as np titanic_survival = pd.read_csv("titanic_train.csv") titanic_survival.head()
我现在有一下一些数据,每个值都代表不同的含义,实际是一个船人员信息表,有价格,有年龄,有名字,有座位编号,等等一些数据
下面我们将年龄这一列进行数据处理,看看能得到什么结果,我们先查看了一下,前十个人的年龄如下
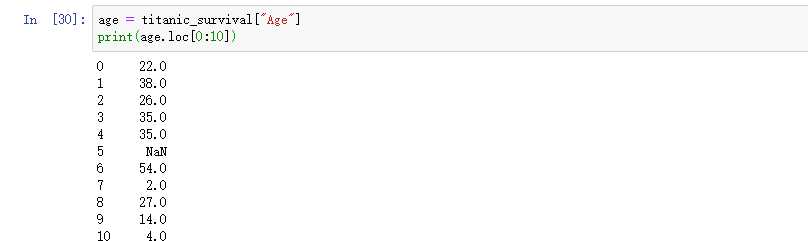
发现在5号人,的年龄为NAN,也就是说,这个数据为空,或者数据丢失。我们来对这个缺失值进处理
我们通过isnull方法,对数据进行判断,判断值是否为空。可以看到为True的说明数据丢失了
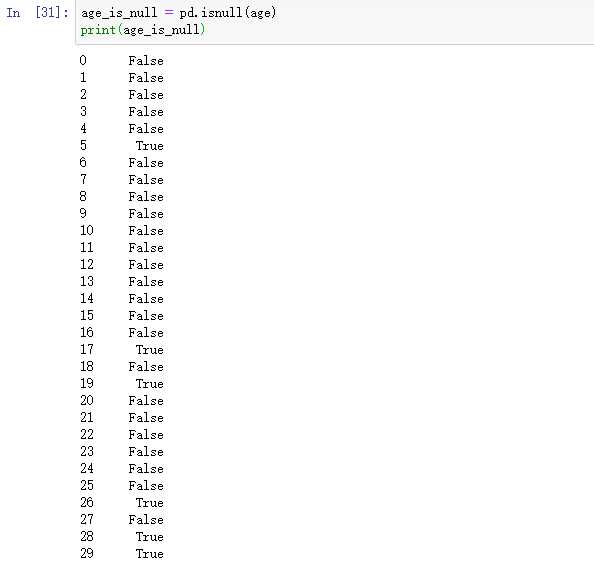
然后我们将这个为空的数据作为索引,可以找到全部数据中,数据丢失的值
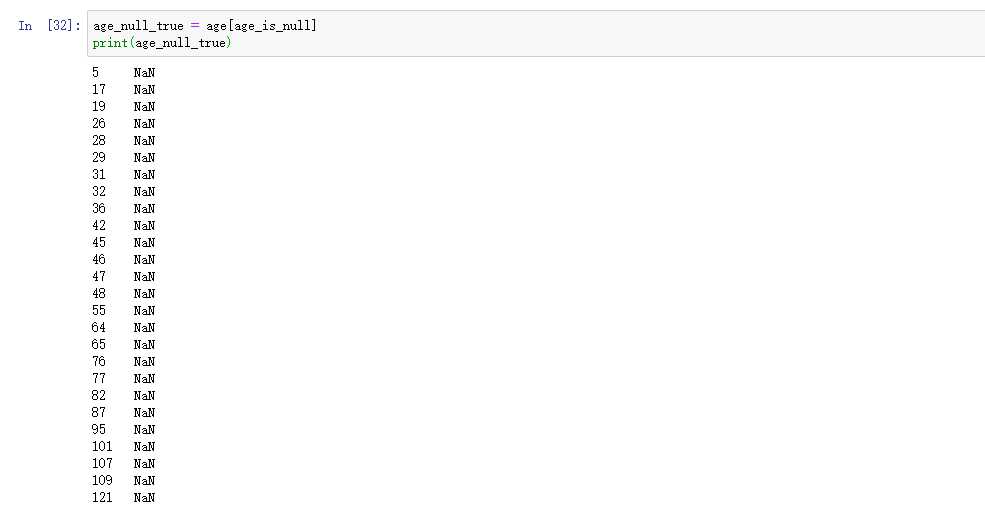
那我们现在统计一下,有多少个数据丢失了,可以用len方法。统计数据为空的值,为177就可以得到177个数据为空的值

我们得到了缺失值后,要对缺失值进行处理
那么我先对数据没有做缺失值处理的情况下,进行一个求平均值的操作

我们可以看到,算出来的值是nan,说明有问题!所以我们不能把带有缺失值得也计算在里面
接下来我们对数据进行处理
一个基本的想法是这样的,就是说,当前数据中,有值的,我们就拿出来进行平均计算,没有值的,就不取出来进行运算

通过这样的计算,我们可以得到,平均年龄为29.6岁
这种方法可能有些麻烦,那么Pandas中有没有什么好的方法可以直接帮我们处理呢? 答案是有的

我们用这样一个简单的方法,一步就可以帮我们取出年龄的平均值。
那我们继续说些难一点的。我们在数据中,分了船舱有1, 2 ,3个等级,我们想计算一下,每个等级下的平均价格是多少
如何计算呢?

这段代码的意思是,我先用for循环,在数据中找到,哪些人是一等舱的人,哪些人是二等舱的人,哪些人是三等舱的人
我们先讲这些人的数据拿到手,拿到之后,我们进行列的定位,定位到价格这列,然后进行平均值,这样就可以得到一个平均价格
分别为以上三个,但是这种做法很麻烦,那么pandas中有没有一个更简单的方法帮我们处理数据呢?看下面的代码
我们有个需求,想算一下,3个舱位每个舱位的平均获救人数的值

可以看到我们在pivot_table中,有三个参数,第一个参数为index,就是说我们要对哪列数据进行统计
values则是说,你要在统计参数一的基础上和哪个数据有关系,作为统计。
第三个参数是aggfunc,就是说你要统计前面两个参数的什么值,我们这边统计平均值。既可以获得以上平均数据
那么我们在计算一下,每个舱位的平均年龄是多少

我们可以直接按照这种方式进行计算,既可以得到每个舱的平均年龄,这里可以看到我们没有添加第三个参数因为如果不加参数3,那么系统会默认帮我们取平均值
那我们又有了新的需求。我们现在想看看。一个量之间,与其他量的关系

我们将index设置为登船地点,那么values是船票的价格,和获救与否,最后一个参数是计算总值。
这里我们想得到的数据就是,分别在C、Q、S这三个码头登船的人的获救总数
这个数据我们可以看到,C码头卖出了1万多块的票价,获救人数是93人。以此类推
那么我们先继续看
因为数据中有些缺失值,那么我们想把这些缺失值都丢掉应该怎么做呢?

dropna的意思就是说,丢弃当前的缺失值。我们 想去掉Age Sex中有缺失值的数据,需要将这两列数据dropna方法中即可
我们继续
那么我想对数据,定位到具体的某个值,我们怎么办呢?
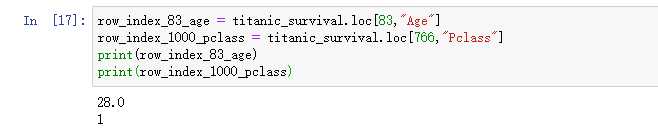
我们可以看到,我们想找第83个样本的年龄,那么我们只需要在参数中添加样本编号,以及需要取到的数据对应的列名。
今天就先讲到这里,感谢大家的阅读。谢谢!!
更多好文章:https://www.yuanrenxue.com/
以上是关于python学习——pandas库的使用,仅需要这一篇就足够了的主要内容,如果未能解决你的问题,请参考以下文章