ZooKeeper基本原理分析
Posted 踩踩踩从踩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ZooKeeper基本原理分析相关的知识,希望对你有一定的参考价值。
前言
ZooKeeper是一个分布式的,开放源码的分布式协调协调服务,shi的Chubby一个的开源实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。 我们在项目实际的应用中,也会考虑 zk这个中间件,他提供了提供了分布式独享锁、选举、队列的接口的代码版本。 随着版本的迭代 ,功能是不断的迭代增加,因此 这篇文章会介绍 其原理 以及功能,zk会话机制 watch机制 引出了 分布式 独享 锁的概念。 以及 java实现 的zk客户端等等。
ZooKeeper简介与安装
Apache ZooKeeper是一种用于分布式应用程序的高性能协调服务。提供一种集中式信息存储服务。 特点:数据存在内存中,类似文件系统的树形结构(文件和目录),高吞吐量和低延迟,集群高可靠。 作用:基于zookeeper可以实现分布式统一配置中心、服务注册中心,分布式锁等功能的实现;
zk的官网:Apache ZooKeeper
也就是处理单台应用处理不过来,就搞成 了 集群,这已经属于比较成熟,并且越来越基础了。
而zk出现的意义就是 为了保证 集群之间 交互 协同 共享资源操作,以及 多服务下面热部署的 问题, 添加节点 删除节点,而不重启 节点,以及配置 的管理。
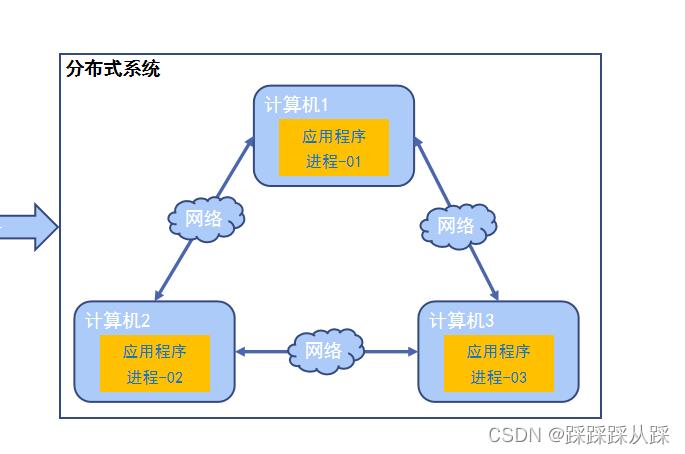
对于复杂的分布式环境下 需要一个 协调管理的中间件 zookeeper出现的含义就是 解决这些问题。
对于现在来说 ,这个中间件越来越趋近基础化,以后包括功能版本的迭代,也会逐渐的功能化。
zk简介与安装
简介:Apache ZooKeeper是一种用于分布式应用程序的高性能协调服务。提供一种集中式信息存储服务。
特点:数据存在内存中,类似文件系统的树形结构(文件和目录),高吞吐量和低延迟,集群高可靠。
作用:基于zookeeper可以实现分布式统一配置中心、服务注册中心,分布式锁等功能的实现;
安装Zookeeper
安装1.6版本以上JDK,配置环境变量
下载: https://archive.apache.org/dist/zookeeper/zookeeper-3.4.13/zookeeper-3.4.13.tar.gz
解压后的conf目录,增加配置文件zoo.cfg
启动服务端 bin/zkServer.sh start 测试,
客户端连接: bin/zkCli.sh -server 127.0.0.1:2181

关键的配置包括心跳等配置
特点
数据结构简单
类似Unix文件系统树形结构,每个目录称为Znode节点,但是又不同于文件系统,既可以做目录拥有子节点,又可以做文件存放数据。 总的来说上手比较快, 使用上都比较好上手
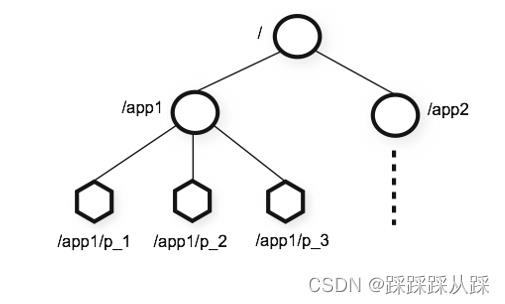
其有自己的约束
同节点下的子节点名称不能相同
命名有规范
绝对路径
存放的数据大小有限制,最大大小在1m。
数据模型
层次名称空间
类似unix文件系统,以 / 为根
区别:节点可以包含与之关联的数据以及子节点 (既是文件也是文件夹)
节点的路径总是表示为规范的、绝对的、斜杠分隔的路径。
znode
名称唯一,命名规范
节点类型:持久、顺序、临时、临时顺序
节点数据构成
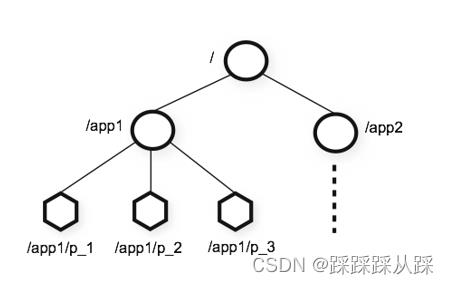
znode—命名规范
- 节点名称除下列限制外,可以使用任何unicode字符:
- null字符(\\u0000)不能作为路径名的一部分;
- 以下字符不能使用,因为它们不能很好地显示,或者以令人困惑的方式呈现: \\u0001 - \\u0019和\\u007F - \\u009F。
- 不允许使用以下字符:\\ud800 - uf8fff, \\uFFF0 - uFFFF。
- “.”字符可以用作另一个名称的一部分,但是“.”和“..”不能单独用于指示路径上的节点,因为ZooKeeper不使用相对路径。下列内容无效: “/a/b/. / c”或“c / a / b / . . /”。
- “zookeeper”是保留节点名。
zk是java开发的,
成熟jar包等等
包括运用示例等等 recipes中 供我们使用
启动是非常简单的,包括 server的启动等。
help 等命名
因为类似 Linux 命令 可以使用 ls 命令
操作指令简单
zk: localhost:2181(CONNECTED) 17] help
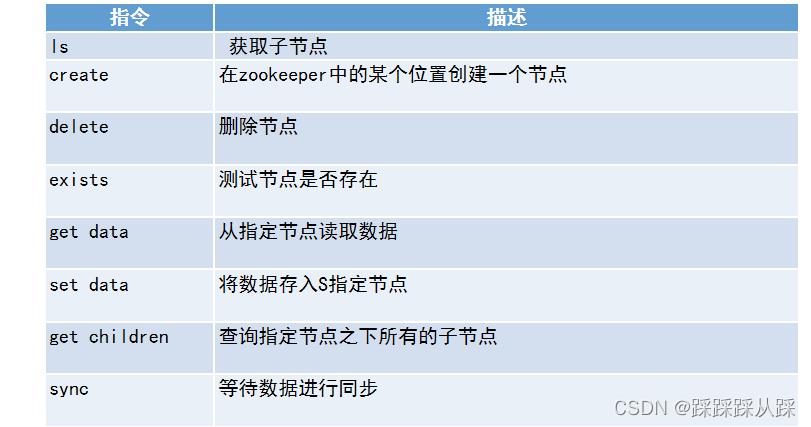
有序
多种方式跟踪时间
Zxid
ZooKeeper中的每次更改操作都对应一个唯一的事务id,称为Zxid,它是一个全局有序的戳记, 如果zxid1小于zxid2,则zxid1发生在zxid2之前。
Version numbers
版本号,对节点的每次更改都会导致该节点的版本号之一增加。这三个版本号是dataVersion (对znode数据的更改次数)、cversion(对znode子节点的更改次数)和aclVersion(对znode ACL的更改次数)。
Ticks
当使用多服务器ZooKeeper时,服务器使用“滴答”来定义事件的时间,如状态上传、会话超时、 对等点之间的连接超时等。滴答时间仅通过最小会话超时(滴答时间的2倍)间接公开;如果客户端请求的会话超时 小于最小会话超时,服务器将告诉客户端会话超时实际上是最小会话超时。
Real time
ZooKeeper除了在znode创建和修改时将时间戳放入stat结构之外,根本不使用Real time或时钟时间。
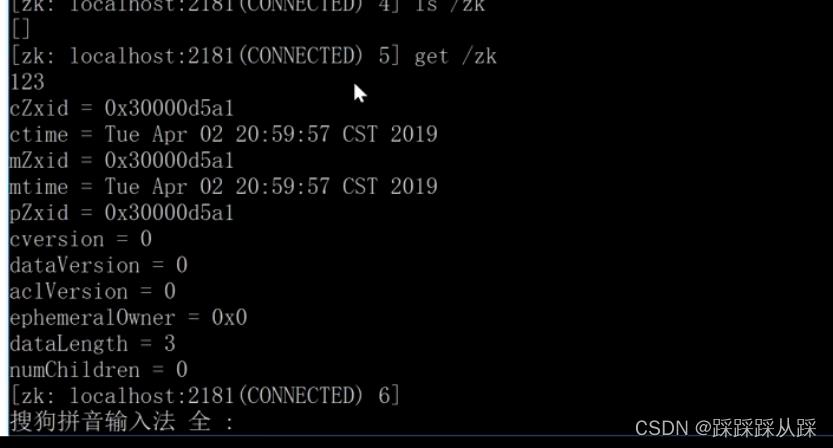
这 在节点 节点上的元数据信息-Stat,
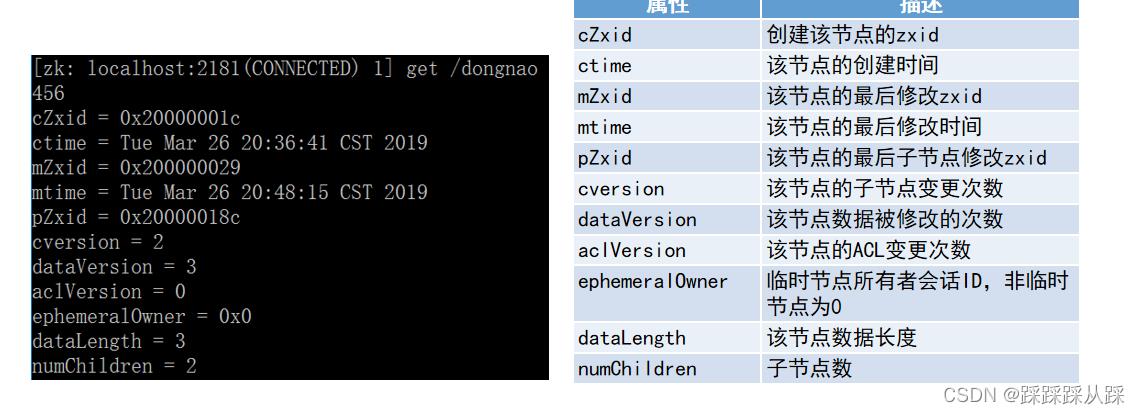
除了ephemeralOwner、dataLength、numChildren,其他属性都体现了顺序
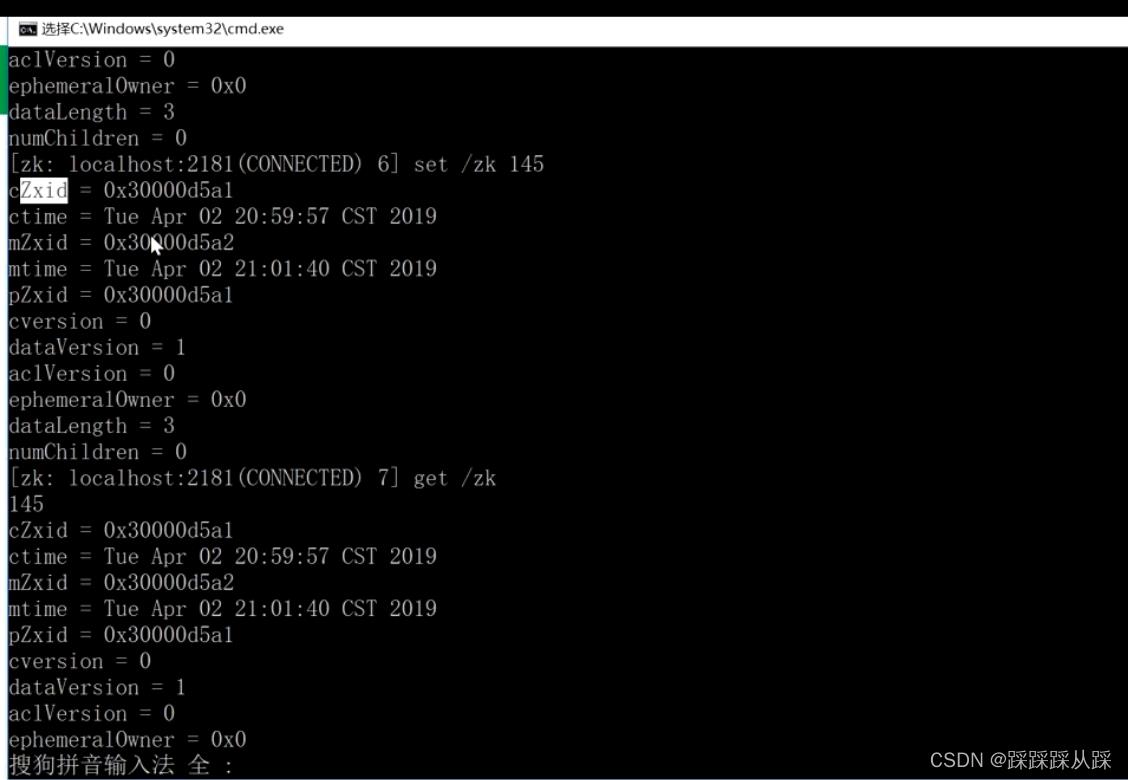
zookeeper 体现有序的地方,也是 这些信息体现出来的。
可复制
可以快速的搭建集群
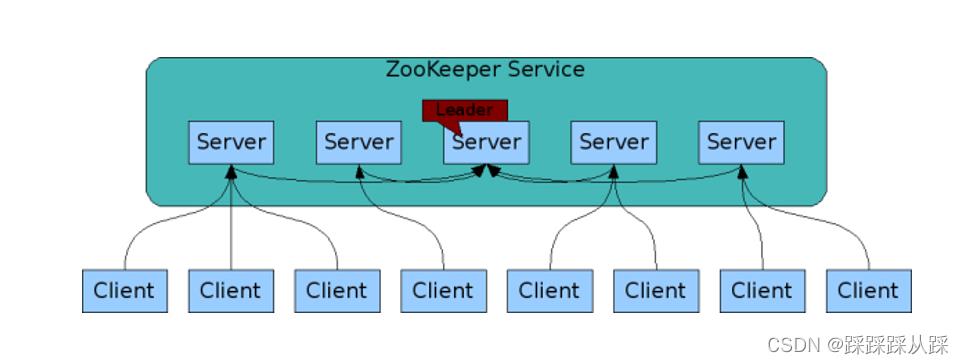
集群特点,保证了服务的可靠性,可靠性使其不会成为单点故障;
相对应的配置 完成,可靠性。
快速
- ZooKeeper数据加载在内存中,这意味着ZooKeeper可以获得高吞吐量和低延迟数。
- 以读取为主的工作负载中,它尤其快。
- 操作的Znode的数据大小限制1M。
ZooKeeper的性能方面意味着它可以用于大型分布式系统
功能 及节点类型
Session 会话
- 一个客户端连接一个会话,由zk分配唯一会话id;
- 客户端以特定的时间间隔发送心跳以保持会话有效; tickTime
- 超过会话超时时间未收到客户端的心跳,则判定客户端死了;(默认2倍tickTime)
- 会话中的请求按FIFO顺序执行。
数据构成
节点数据:存储的协调数据(状态信息、配置、位置信息等)
节点元数据(stat结构)
数据大小上限:1M
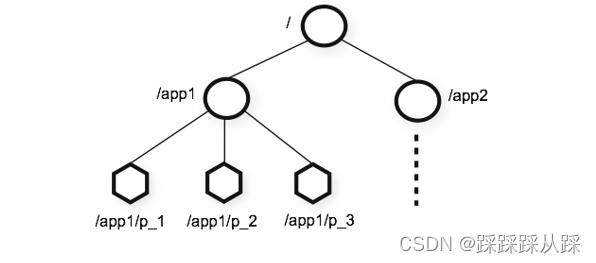
节点类型
持久节点 create /app1 666
临时节点 create -e /app2 888
顺序节点 create -s /app1/cp 888
10位十进制序号 每个父节点一个计数器 计数器是带符号int(4字节)到2147483647之后将溢出(导致名称“<path>-2147483648”)
临时顺序节点 create -e -s /app1/ 888
Watch监听机制
客户端可以在znodes上设置watch ,监听znode的变化。
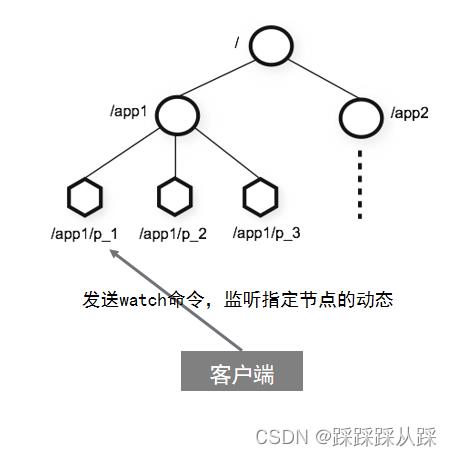
监听子节点 删除和增加 数据变化, 对于 每一个目录 都进行监听的。
两类watch
data watch 监听 数据变更
child watch 监听子节点变化
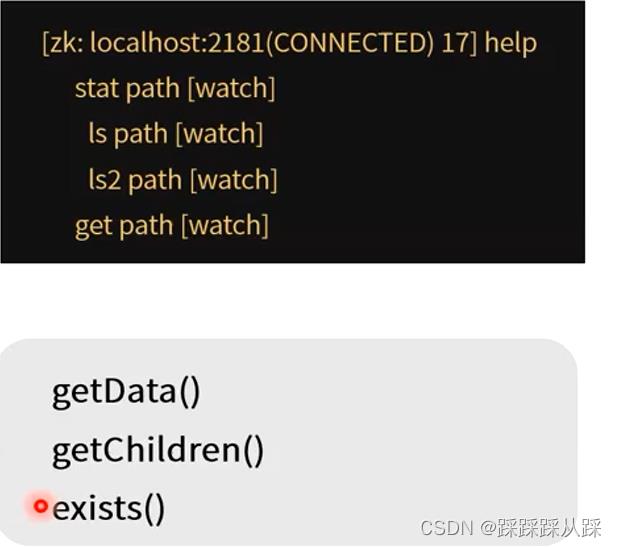
触发watch事件
Created event:
Enabled with a call to exists.
Deleted event:
Enabled with a call to exists, getData, and getChildren.
Changed event:
Enabled with a call to exists and getData.
Child event:
Enabled with a call to getChildren.
Watch重要特性
一次性触发:watch触发后即被删除。要持续监控变化,则需要持续设置watch;
有序性:客户端先得到watch通知,后才会看到变化结果
因为有这些特性,才有了后面的一系列的应用。
Watch注意事项
- watch是一次性触发器;如果您获得了一个watch事件,并且希望得到关于未来更改的通知,则必须设置另一个watch。
- 因为watch是一次性触发器,并且在获取事件和发送获取watch的新请求之间存在延迟,所以不能可靠地得到节点发生的每个更改。
- 一个watch对象只会被特定的通知触发一次。如果一个watch对象同时注册了exists、getData,当节点被删除时,删除事件对exists 、getData都有效,但只会调用watch一次。
ZooKeeper特性
- 顺序一致性(Sequential Consistency),保证客户端操作是按顺序生效的;
- 原子性(Atomicity),更新成功或失败。没有部分结果。
- 单个系统映像,无论连接到哪个服务器,客户端都将看到相同的内容
- 可靠性,数据的变更不会丢失,除非被客户端覆盖修改。
- 及时性,保证系统的客户端当时读取到的数据是最新的。
分布式的应用
分布式锁 分布式协调
集群的缓存失效,让一个请求更新缓存即可
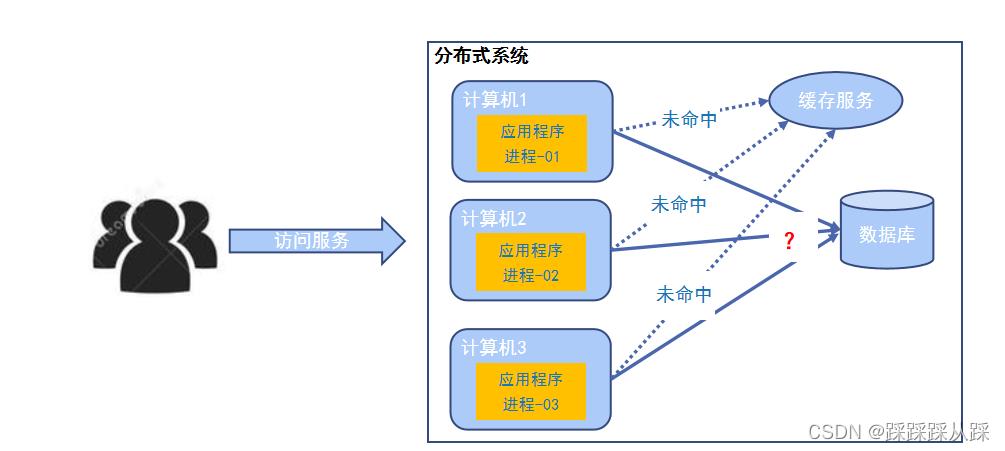
首先一把锁 有的特点,
- 排他性:只有一个线程能获取到
- 阻塞性:其他未抢到的线程阻塞,直到锁释放出来,再抢。
- 可重入性:线程获得锁后,后续是否可重复获取该锁。
具有排他性特点的其他技术
- 文件系统
- 数据库: 主键 唯一约束 for update
- 缓存 redis: setnx
- zookeeper 类似文件系统
其实 只要有排他性的中间件,都可以达到 做锁 分布式的概念。
Zookeeper具有做锁的特点
阻塞性
可以通过JDK栅栏,来实现。
可重入性
通过计数器来实现。
利用zk进行创建锁
创建客户端的核心类: Zookeeper
org.apache.zookeeper
org.apache.zookeeper.data
connect - 连接到ZooKeeper集合
create- 创建znode exists- 检查znode是否存在及其信息
getData - 从特定的znode获取数据
setData - 在特定的znode中设置数据
getChildren - 获取特定znode中的所有子节点
delete - 删除特定的znode及其所有子项
close - 关闭连接
zk的客户端只会提供最基础的功能,但是操作实用性来说 ,并不适用
第三方客户端,Zkclient,使用操作更方便
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.13</version>
</dependency>
<dependency>
<groupId>com.101tec</groupId>
<artifactId>zkclient</artifactId>
<version>0.10</version>
</dependency>/**
* ZkClientDemo
*
*/
public class ZkClientDemo
public static void main(String[] args)
// 创建一个zk客户端
ZkClient client = new ZkClient("localhost:2181");
client.setZkSerializer(new MyZkSerializer());
client.create("/zk/app6", "123", CreateMode.PERSISTENT);
client.subscribeChildChanges("/zk/app6", new IZkChildListener()
@Override
public void handleChildChange(String parentPath, List<String> currentChilds) throws Exception
System.out.println(parentPath+"子节点发生变化:"+currentChilds);
);
client.subscribeDataChanges("/zk/app6", new IZkDataListener()
@Override
public void handleDataDeleted(String dataPath) throws Exception
System.out.println(dataPath+"节点被删除");
@Override
public void handleDataChange(String dataPath, Object data) throws Exception
System.out.println(dataPath+"发生变化:"+data);
);
try
Thread.currentThread().join();
catch (InterruptedException e)
e.printStackTrace();
public class MyZkSerializer implements ZkSerializer
@Override
public byte[] serialize(Object data) throws ZkMarshallingError
String d = (String) data;
try
return d.getBytes("UTF-8");
catch (UnsupportedEncodingException e)
e.printStackTrace();
return null;
@Override
public Object deserialize(byte[] bytes) throws ZkMarshallingError
try
return new String(bytes, "UTF-8");
catch (UnsupportedEncodingException e)
e.printStackTrace();
return null;
设置编码的格式 并且创建节点 进行监听 子节点 数据节点的监控,
包括下面的原生的状态 监听等等。
第三方客户端,Curator,功能更加丰富
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.2.0</version>
</dependency>
Curator Apache 的开源项目
解决Watch注册一次就会失效的问题
提供的 API 更加简单易用
提供更多解决方案并且实现简单,例如:分布式锁 提供常用的ZooKeeper工具类 编程风格更舒服

实现分布式锁
利用同一个节点下面名称不能重复,并且使用临时节点 , 去创建 判断是否获得 锁的应用
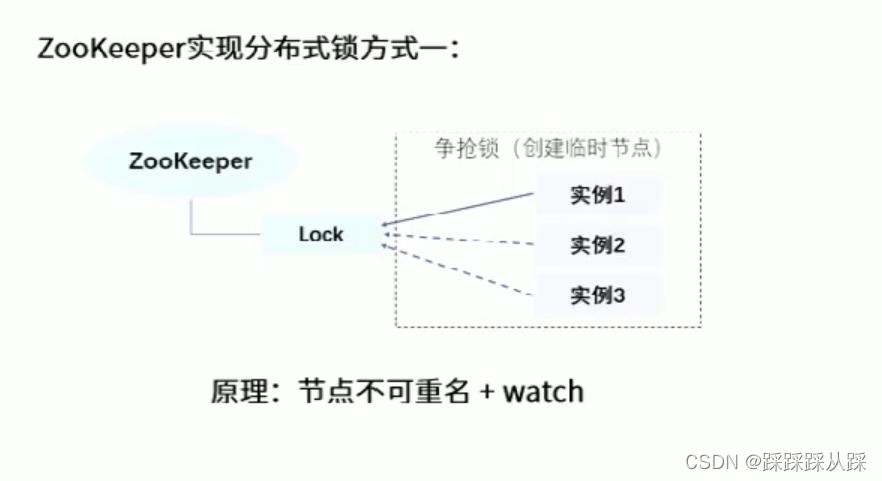
主要实现方案 ,需要实现 lock接口
然后 讲需要的 zkclient 和 lockPath ,可以由外面出入,当然 我们 spring强调的是, 由配置进行注入
首先 实现trylock方法
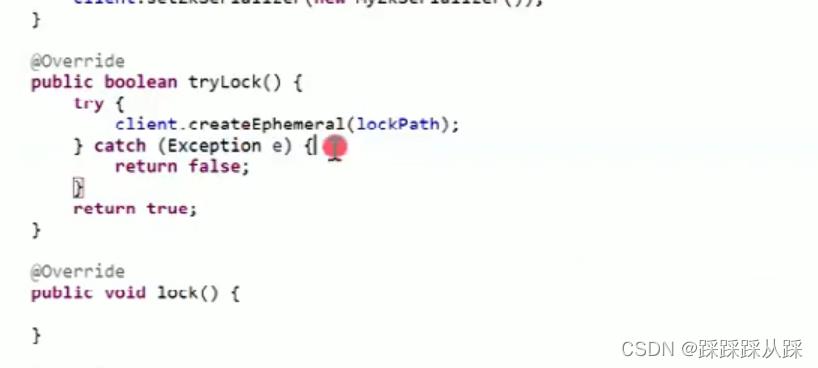
在lock中尝试加锁
使用 watch机制 判断 数据是否改变。
这里还是 比较简单的, 栅栏 进行等待。 实现方式还是比较简单的。 最终 的实现一个简单的锁。
public class ZkDistributeLock implements Lock
private String lockPath;
private ZkClient client;
public ZkDistributeLock(String lockPath)
if(lockPath ==null || lockPath.trim().equals(""))
throw new IllegalArgumentException("patch不能为空字符串");
this.lockPath = lockPath;
client = new ZkClient("localhost:2181");
client.setZkSerializer(new MyZkSerializer());
@Override
public boolean tryLock() // 不会阻塞
// 创建节点
try
client.createEphemeral(lockPath);
catch (ZkNodeExistsException e)
return false;
return true;
@Override
public void unlock()
client.delete(lockPath);
@Override
public void lock() // 如果获取不到锁,阻塞等待
if (!tryLock())
// 没获得锁,阻塞自己
waitForLock();
// 再次尝试
lock();
private void waitForLock()
CountDownLatch cdl = new CountDownLatch(1);
IZkDataListener listener = new IZkDataListener()
@Override
public void handleDataDeleted(String dataPath) throws Exception
System.out.println("----收到节点被删除了-------------");
cdl.countDown();
@Override
public void handleDataChange(String dataPath, Object data)
throws Exception
;
client.subscribeDataChanges(lockPath, listener);
// 阻塞自己
if (this.client.exists(lockPath))
try
cdl.await();
catch (InterruptedException e)
e.printStackTrace();
// 取消注册
client.unsubscribeDataChanges(lockPath, listener);
@Override
public void lockInterruptibly() throws InterruptedException
// TODO Auto-generated method stub
@Override
public boolean tryLock(long time, TimeUnit unit)
throws InterruptedException
// TODO Auto-generated method stub
return false;
@Override
public Condition newCondition()
// TODO Auto-generated method stub
return null;
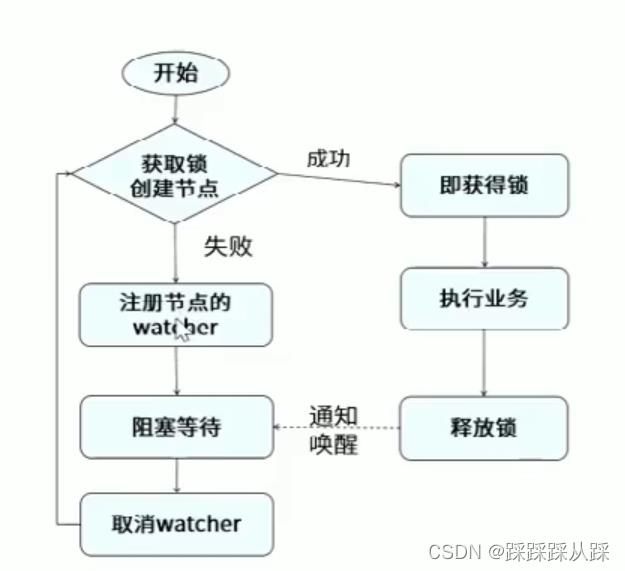
但是这把锁有个 缺点 就是 惊群效应,一旦 有人释放了锁 ,就会导致 所有应用都去抢锁。
公平锁
利用zk可以创建 顺序节点, 可以达到顺序锁,逻辑 上 创建顺序节点, 得到 节点 进行 watch
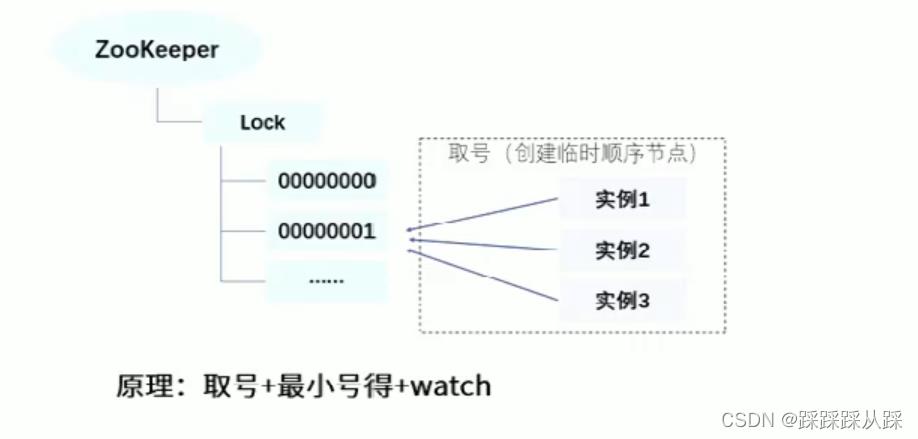
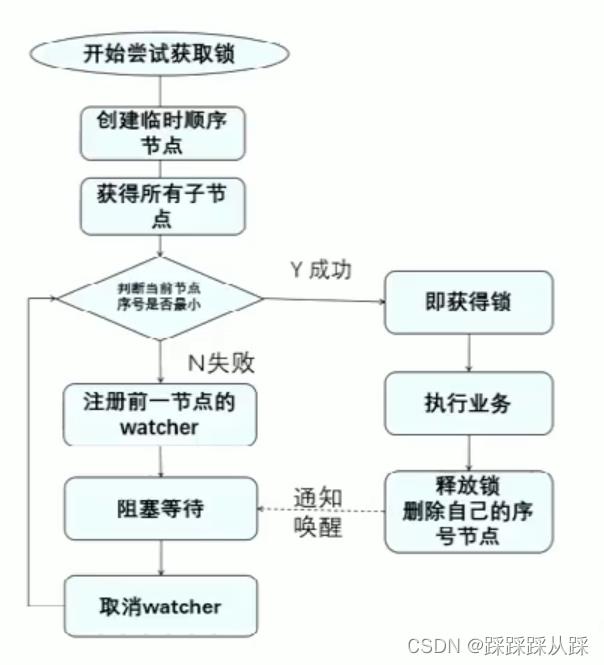
实现方式
父节点 创建临时的有序节点, 这里 创建 临时顺序子节点 时,我要监听 前面的节点, 并且 需要 当前的临时序号。

记录下来 临时的顺序节点,其实 所有 父类下面的节点 是不是 已经最小的节点。 或者 将前面个的节点 给存储起来
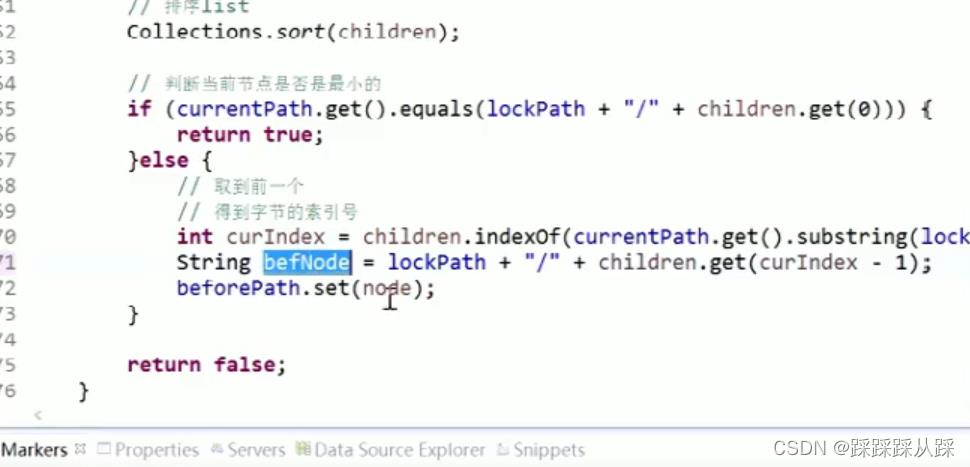
这里 就要判断 前面个节点 的状态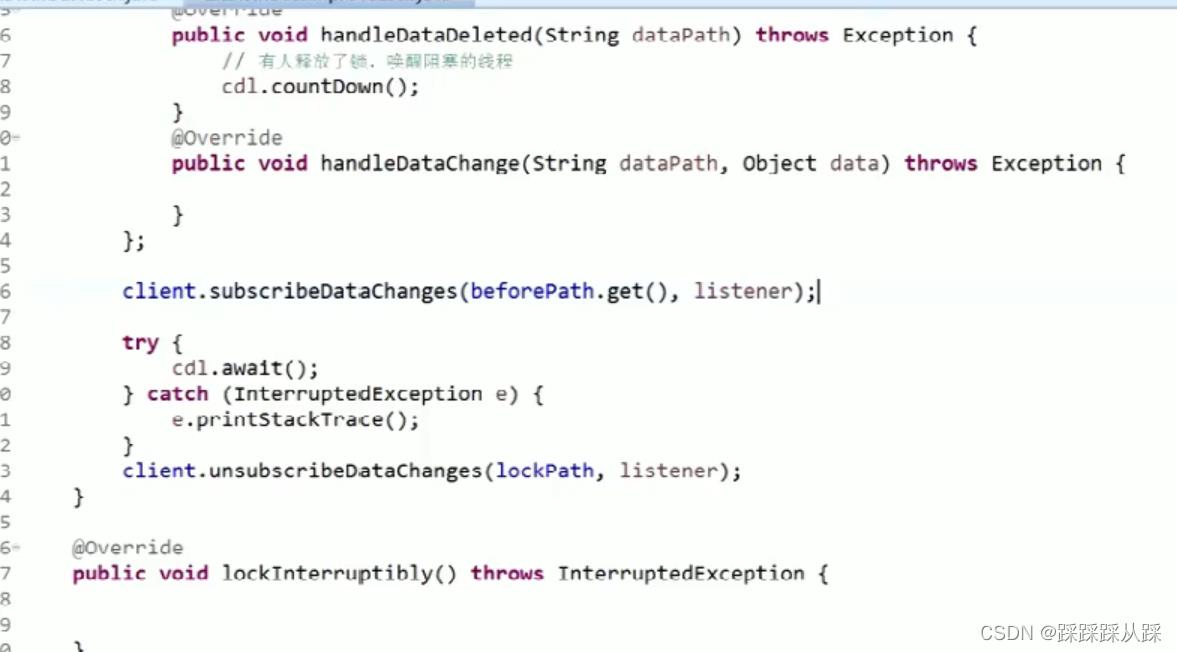
这里 还是很简单的。
如果还想设置为可重入的话, 另外加一个 容器来存储 计数器。
// 锁重入计数器
private ThreadLocal<Integer> reenterCount = ThreadLocal.withInitial(()->0);整体的功能
利用临时顺序节点来实现分布式锁获取锁:取排队号(创建自己的临时顺序节点),然后判断自己是否是最小号,如是,则获得锁;不是,则注册前一节点的watcher,阻塞等待释放锁:删除自己创建的临时顺序节点
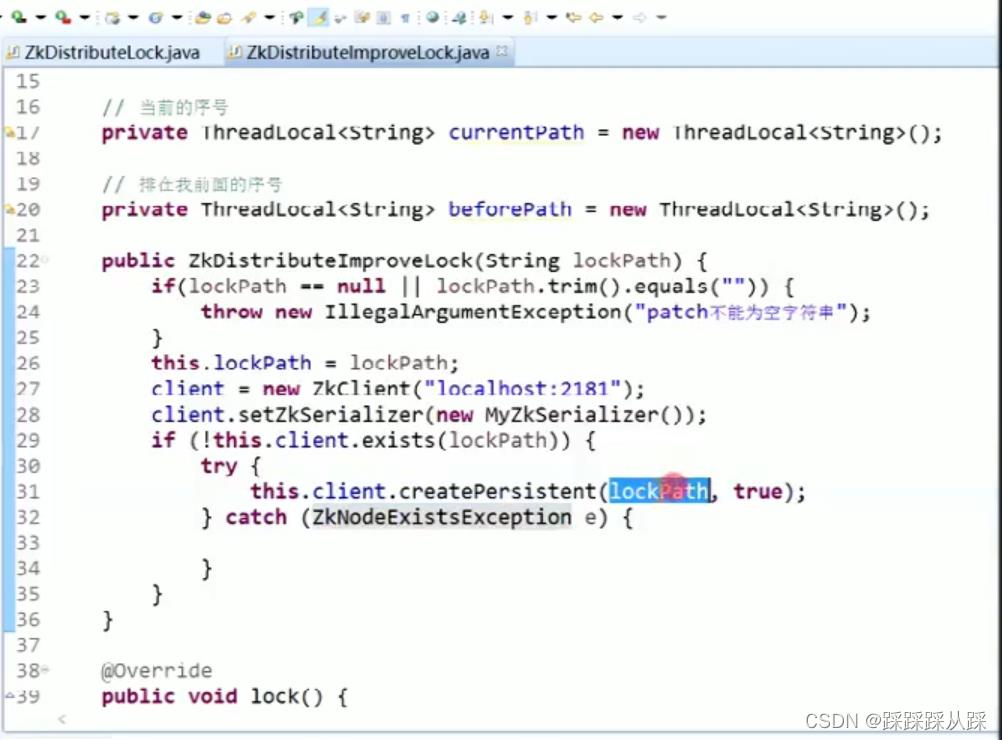
public class ZkDistributeImproveLock implements Lock
private String lockPath;
private ZkClient client;
private ThreadLocal<String> currentPath = new ThreadLocal<String>();
private ThreadLocal<String> beforePath = new ThreadLocal<String>();
// 锁重入计数器
private ThreadLocal<Integer> reenterCount = ThreadLocal.withInitial(()->0);
public ZkDistributeImproveLock(String lockPath)
if(lockPath == null || lockPath.trim().equals(""))
throw new IllegalArgumentException("patch不能为空字符串");
this.lockPath = lockPath;
client = new ZkClient("localhost:2181");
client.setZkSerializer(new MyZkSerializer());
if (!this.client.exists(lockPath))
try
this.client.createPersistent(lockPath, true);
catch (ZkNodeExistsException e)
@Override
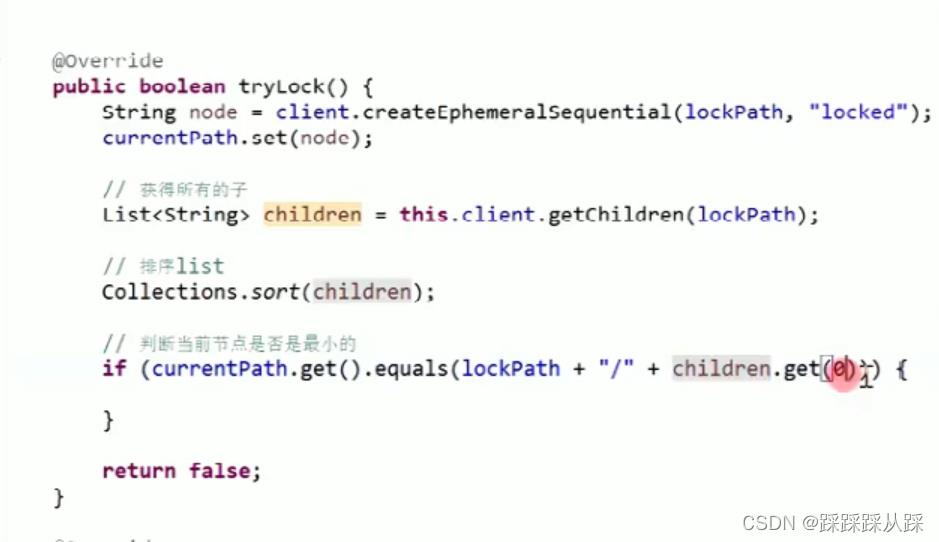
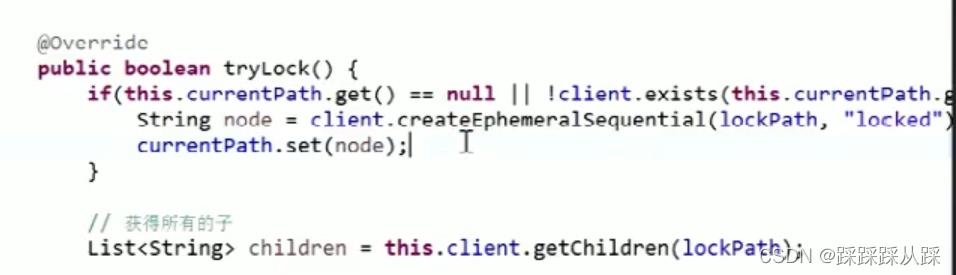
public boolean tryLock()
System.out.println(Thread.currentThread().getName() + "-----尝试获取分布式锁");
if (this.currentPath.get() == null || !client.exists(this.currentPath.get()))
String node = this.client.createEphemeralSequential(lockPath + "/", "locked");
currentPath.set(node);
reenterCount.set(0);
// 获得所有的子
List<String> children = this.client.getChildren(lockPath);
// 排序list
Collections.sort(children);
// 判断当前节点是否是最小的
if (currentPath.get().equals(lockPath + "/" + children.get(0)))
// 锁重入计数
reenterCount.set(reenterCount.get() + 1);
System.out.println(Thread.currentThread().getName() + "-----获得分布式锁");
return true;
else
// 取到前一个
// 得到字节的索引号
int curIndex = children.indexOf(currentPath.get().substring(lockPath.length() + 1));
String node = lockPath + "/" + children.get(curIndex - 1);
beforePath.set(node);
return false;
@Override
public void lock()
if (!tryLock())
// 阻塞等待
waitForLock();
// 再次尝试加锁
lock();
private void waitForLock()
CountDownLatch cdl = new CountDownLatch(1);
// 注册watcher
IZkDataListener listener = new IZkDataListener()
@Override
public void handleDataDeleted(String dataPath) throws Exception
System.out.println(Thread.currentThread().getName() + "-----监听到节点被删除,分布式锁被释放");
cdl.countDown();
@Override
public void handleDataChange(String dataPath, Object data) throws Exception
;
client.subscribeDataChanges(this.beforePath.get(), listener);
// 怎么让自己阻塞
if (this.client.exists(this.beforePath.get()))
try
System.out.println(Thread.currentThread().getName() + "-----分布式锁没抢到,进入阻塞状态");
cdl.await();
System.out.println(Thread.currentThread().getName() + "-----释放分布式锁,被唤醒");
catch (InterruptedException e)
e.printStackTrace();
// 醒来后,取消watcher
client.unsubscribeDataChanges(this.beforePath.get(), listener);
@Override
public void unlock()
System.out.println(Thread.currentThread().getName() + "-----释放分布式锁");
if(reenterCount.get() > 1)
// 重入次数减1,释放锁
reenterCount.set(reenterCount.get() - 1);
return;
// 删除节点
if(this.currentPath.get() != null)
this.client.delete(this.currentPath.get());
this.currentPath.set(null);
this.reenterCount.set(0);
@Override
public void lockInterruptibly() throws InterruptedException
@Override
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException
return false;
@Override
public Condition newCondition()
return null;
以上是关于ZooKeeper基本原理分析的主要内容,如果未能解决你的问题,请参考以下文章