浅谈Zookeeper集群选举Leader节点源码
Posted 默辨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅谈Zookeeper集群选举Leader节点源码相关的知识,希望对你有一定的参考价值。
写在前面:
zookeeper源码比较复杂,本文讲解的重点为各个zookeeper服务节点之间的state选举。至于各个节点之间的数据同步,不在文本的侧重讲解范围内。
在没有对zookeeper组件有一个整体架构认识的基础上,不建议直接死磕细节。本文写作的目的也是基于此,阅读本文,希望读者能够对zookeeper集群架构有一个简单的认识。
本文附有整体架构的执行流程图,请一定要跟着代码多走几遍。本文的二-六节会对该流程中的关键点进行讲解
浅谈Zookeeper集群选举Leader节点源码
一、前提共识
1、了解zookeeper集群搭建
不了解如何搭建集群的可以参考网上别人的文章:Zookeeper集群搭建及使用
本文需要了解集群相关的配置为zoo.cfg文件的节点配置信息:
server.1=第一台服务器的主机名:2881:3881
server.2=第二台服务器的主机名:2882:3882
server.3=第三台服务器的主机名:2883:3882
这里针对每一个zookeeper服务,分别含有288x和388x两个端口。第一个端口用来同步节点之间的数据,第二个端口用来进行节点的state选举(对应代码为ServerState枚举类)
在源码中会new很多的Socket通信,一定要区分开不同端口的实例化对象。
2、入口为QuorumPeerMain.main方法
至于为什么直接是这个方法,可以查看对应的脚本文件。大部分使用脚本文件进行执行的,都是同样的方式(如tomcat)。
如果左边的sh文件不方便看,可以看右边的sh文件(毕竟逻辑更简单)

3、整体流程图(重点)
一定要一定要,跟着流程图多走几遍
4、需要有Socket网络编程、多线程相关基础
源代码中出现大量的Socket通信,也包含创建大量的多线程代码。不了解这两部分知识的小伙伴,看起来可能比较吃力
二、基础流程
1、入口main
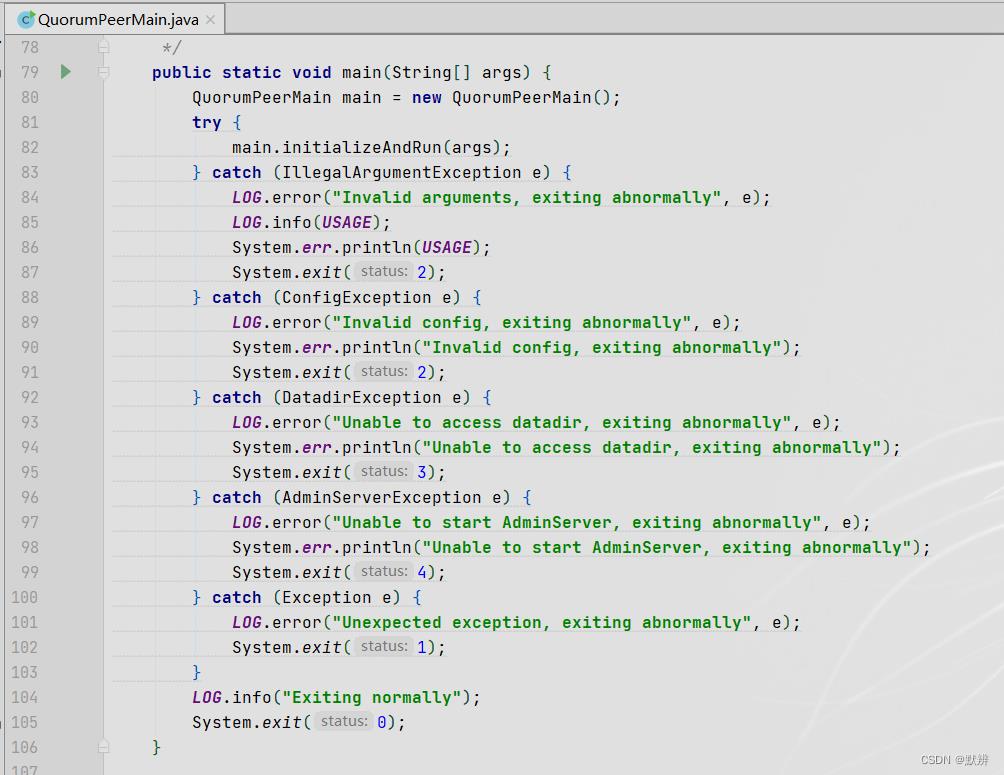
2、流程图
这部分比较简单,主要完成的几件事情可以总结为:
- 解析配置文件的配置信息
- 初始化zookeeper用于接收客户端命令(create、delete、get)的服务端,可选择Netty或者NIO方式,并且完成对应的服务端的启动
- 设置对应的集群leader选举的选举类型(设置为3,未来会在Switch中用到该值)
- 启动一个内嵌的jetty服务器,用来查看未来服务端的信息
- 初始化对应的多级队列架构
- 进行具体的集群leader节点的选举
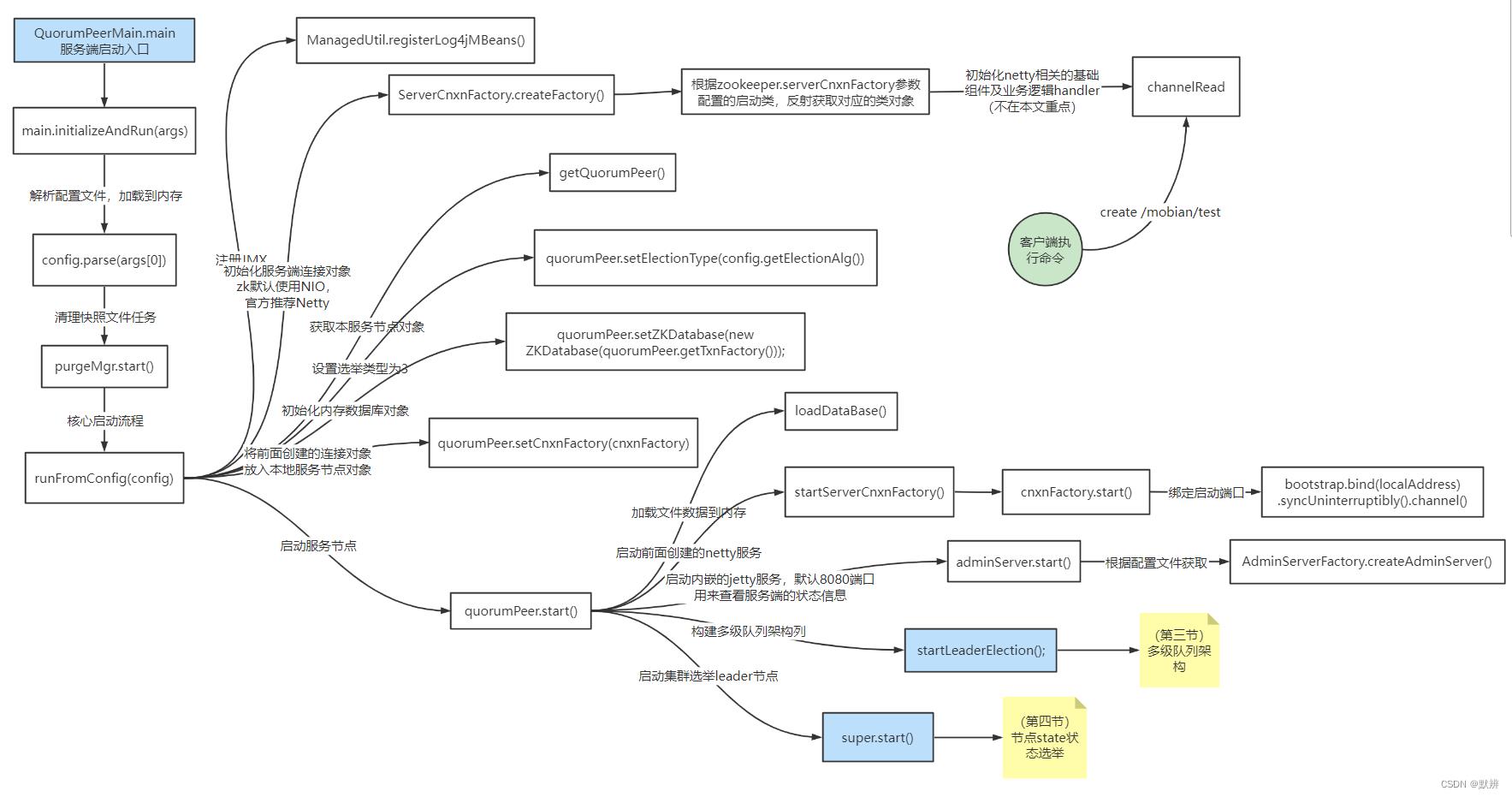
三、多级队列构建流程
1、多级队列架构讲解
看不懂这个图的,建议先把源码跟一遍,再回头看
首先看一下多级队列架构图

我们可以将该多级队列可以分为两层:
第一层:应用层,可以理解为我们上层api队列
代表队列:sendqueue、recvqueue
对应线程名称:WorkerSender、WorkerReceiver
第二层:传输层,可以理解为后台传送数据的队列
代表队列:recvQueue、queueSendMap(map的value为传输层队列)、senderWorkerMap(map的value为SendWorker线程)
对应线程名称:SendWorker、RecvWorker
牢记上面这几个队列、map、线程的名字。否则代码你会看不清楚
处理多级队列流程大致可以描述为
1、首先会初始化对应的ServerSocket端,同时进行accept阻塞监听数据;
2、如果处理leader节点对应的端口接收到数据,那么就会处理该请求。刚开始初始化的时候是不会有数据的,毕竟Socket客户端都还没有开始建立,在第10步才建立的;
3、然后会对信息中的sid进行判断,然后剔除掉不需要的socket连接。因为socket通信是全体连接都发一遍,zk的判定规则为只能由sid大的发给sid小的,所以如果小的发送给了大的,就会关闭连接,并且开启一个反向连接;
4、如果是小的发送给大的,此时就会初始化出我们多级队列的第二级队列传输层队列,以及对应的SendWorker线程任务。然后把这个SendWorker任务放入senderWorkerMap中,未来可以直接取出来直接使用;
5、这里的SendWorker任务,就是真实的把数据通过Socket请求把数据发送给远端的逻辑;
6、接下来开始处理第一级队列应用层队列;
7、即初始化sendqueue和recvqueue这两个上层传输队列;
8、然后就是初始化对应的Socket客户端。当然在初始化客户端的前提是,我们有业务数据放到了第一级的队列中,即第7步中的队列中要有数据;
9、上层业务队列有数据以后,会将业务数据封装为一个ByteBuffer类型的requestBuffer对象,然后把数据直接发送给传输层的队列(queueSendMap中对应sid的value对应的队列);
10、输入发送后,初始化对应的Socket客户端连接,这样就能够把数据发送出去,与此同时,第2步的accept也能接收到数据,最终形成两级队列工作工作的闭环。
第10步使用Socket发送的数据,会与第2步的ServerSocket连接打通。一定要明确这是在集群环境下的通信,明白这一步,很重要
与之对应的recvqueue只是逻辑反一下,首先RecvWorker线程执行会获取到数据,发送给一级队列应用层队列recvqueue,一级队列对应的WQorkRecevier线程任务,就会执行对应的逻辑,然后处理数据。
2、入口startLeaderElection
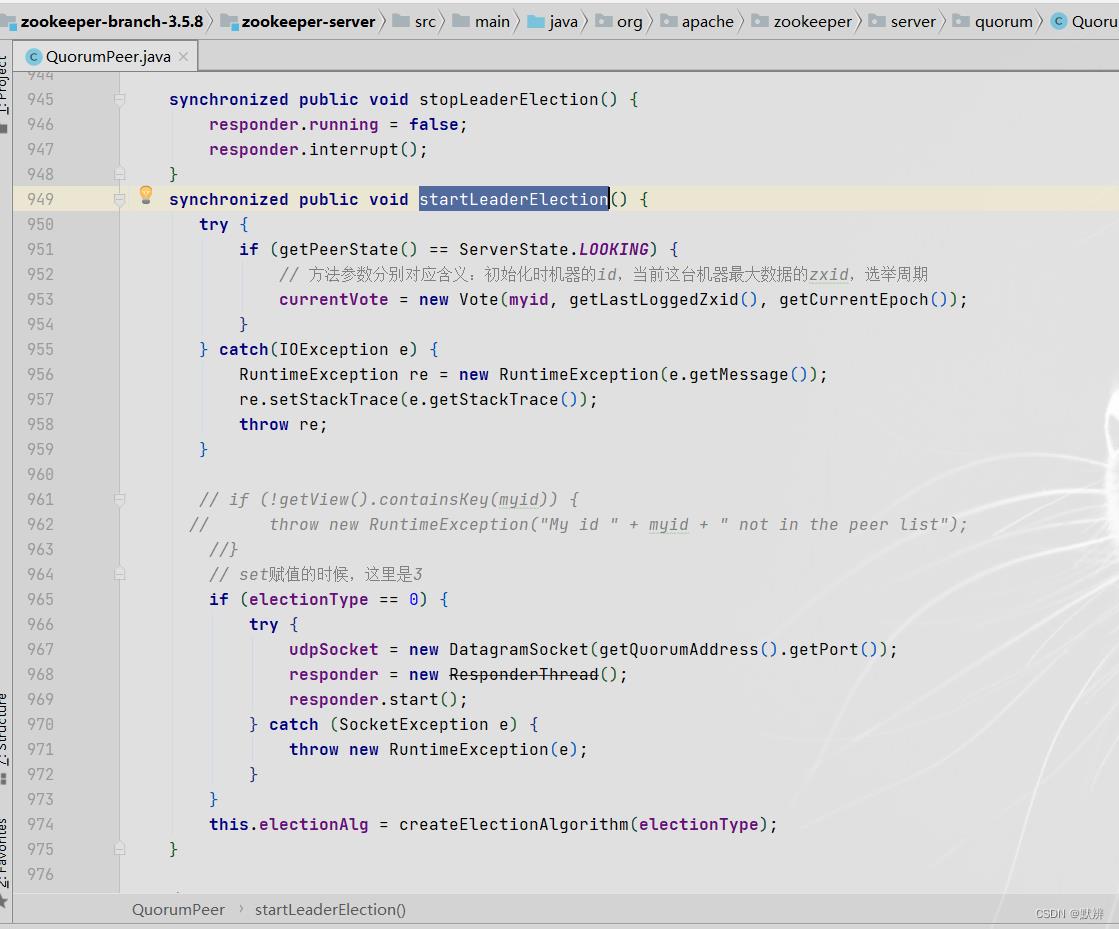
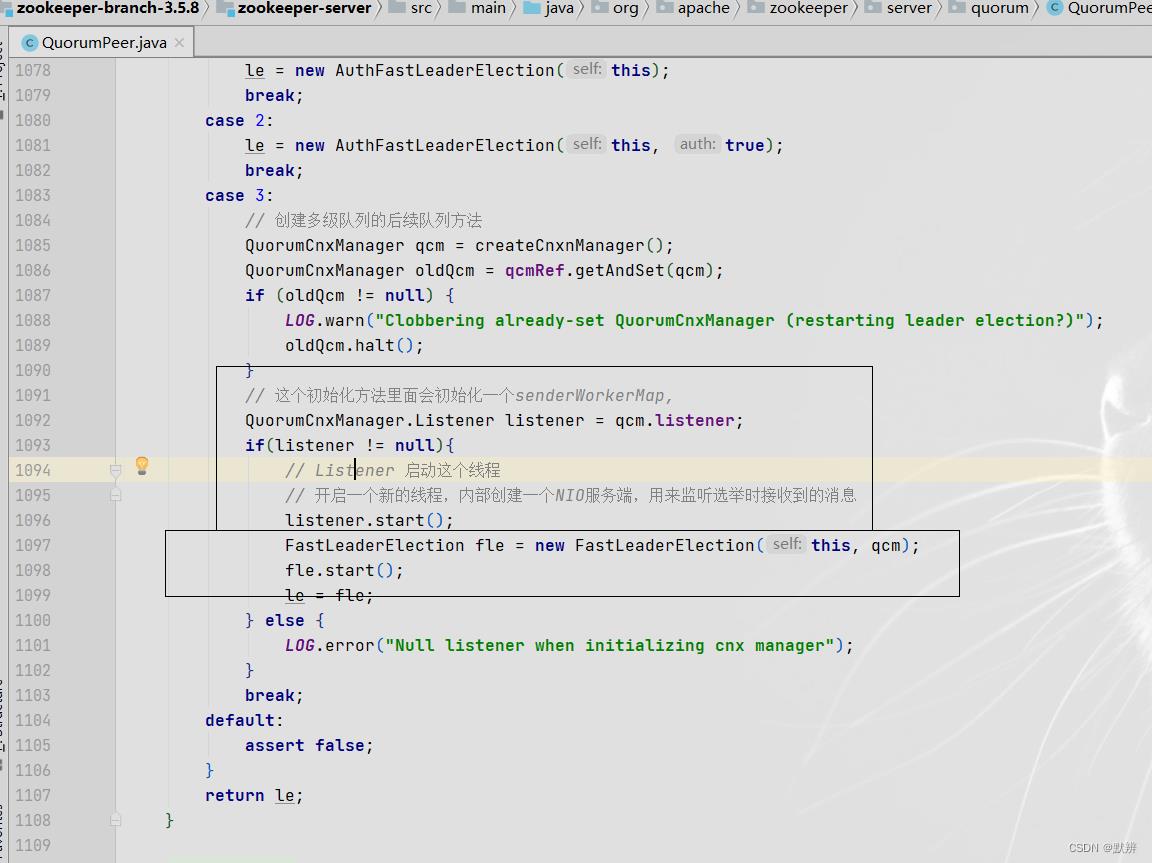
3、初始化二级队列
1)Listener方法内部
- 绑定服务端信息
- accept数据
- 处理数据

2)根据接收到的信息的sid情况进行不同的逻辑
- 如果是自己的就发给自己
- 如果不是自己,并且满足zk的sid由大机器发送给小机器的规则,则开启对应的两个用于处理二级队列(传输层队列)的线程任务

3)以SendWorker线程任务为例
- queueSendMap中获取对应sid的队列,然后获取应用层队列中的数据,并将其发送给传输层队列
- 最终调用send方法,完成数据的传输


4、初始化一级队列
1)完成一级队列的初始化
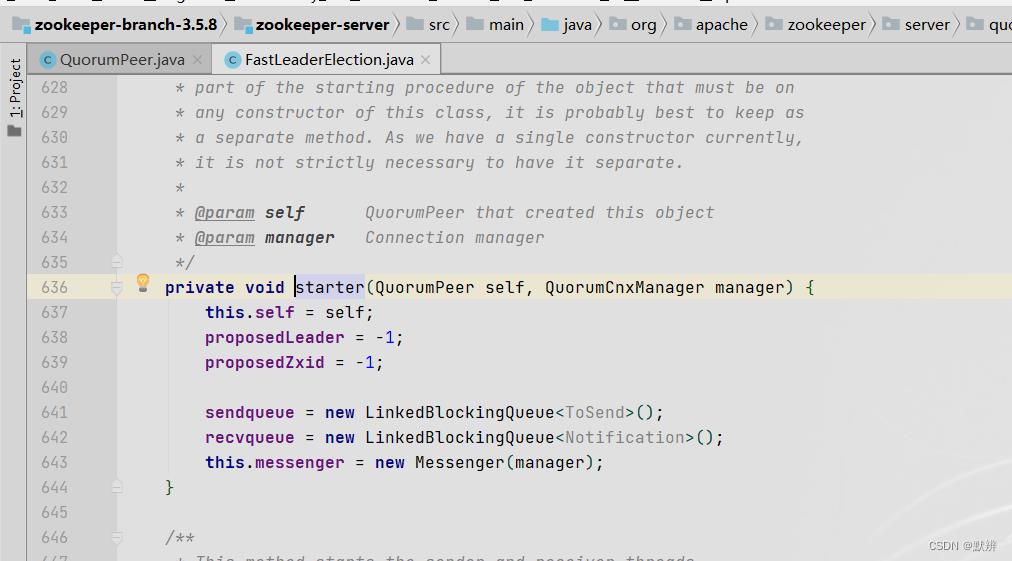
2)完成一级队列对应的线程任务的初始化

3)调用对应线程的run方法,然后调用process方法处理数据
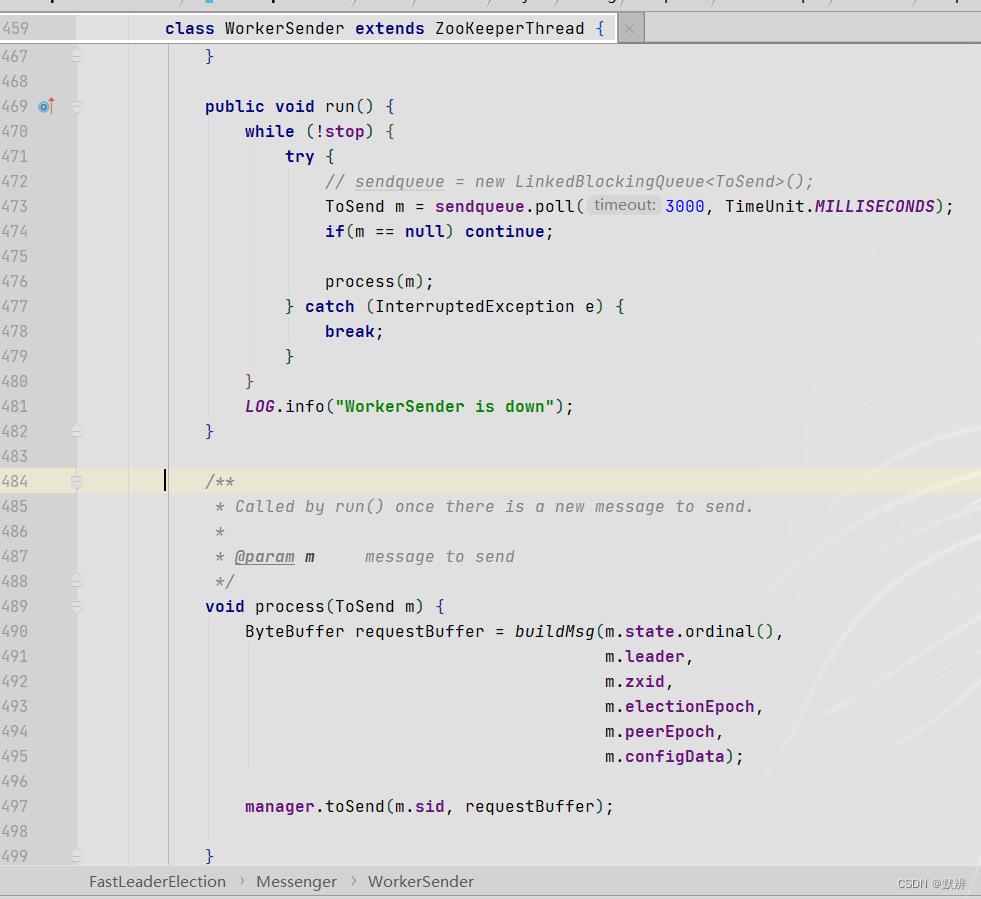
4)把数据发送给运输层队列

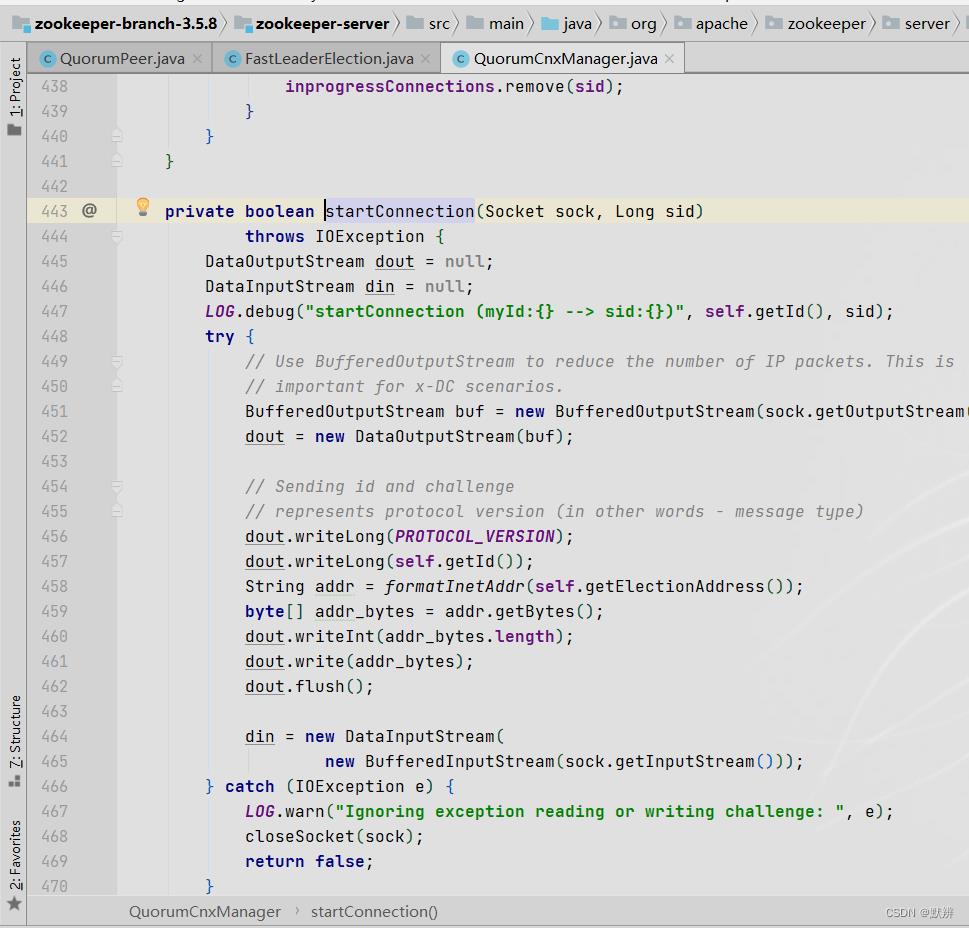
5)建立socket客户端连接
- 首先调用内部的connetOne方法
- 然后把数据封装为一个任务,放进线程池
- 在线程任务中会初始化对应的Socket客户端连接
- 封装数据写入到输出流。此时二级队列初始化出来的阻塞的ServerSocket就能够开始向下执行,处理接收到的数据,形成闭环

将线程任务放进线程池代码

该任务会初始化对应的客户端

封装对应的输出数据,并完成发送
四、LOOKING节点选举流程
1、节点选举基础流程讲解

流程选举大致流程可以描述为:
1、第一轮选票:myid为1和myid为2的两台机器,分别把自己的选票发送出去(vote形式),两台机器会分别对自己收到的选票和自己的选票进行比较。会根据指定的判断规则进行选择(粗略可以理解为,是周期、zxid和机器id几个要素中大的);
2、myid为1的机器收到(2,0),会和自己的选票(1,0)进行比较,发现还是(2,0)大,所以最终它会把(2,0)返回回去。此轮中,两台机器发送的选票都没有超过半数(一共3台服务,配置文件中能获取);
3、第二轮选票:myid为1和myid为2的两台机器,再次发送自己的选票信息。此时由于myid为1的这台机器发送的就是上一轮接收到的(2,0)选票。那么在第二轮投票时myid为1的机器就会投出(2,0),与此同时,myid为2的机器投出的选票也是(2,0);
4、此轮中投出的选票(2,0)超过了半数(2/3)。最终myid为2的这台机器被选为了leader节点;
5、当myid为3的节点进来的时候,虽然它的(3,0)大于(2,0),但是其周期比较小(参与投票的周期次数),所以myid为2的机器依然还是leader节点。
2、LOOKING节点流程
每一个节点进来以后的第一步逻辑就是这个位置

3、投票PK逻辑源码
1)首先会把自己的投票信息发送出去,然后再获取自己的recvqueue队列(传输层队列,具体逻辑在多级队列章节进行过讲解)中的投票信息,只要满足条件,就可以不断的去获取队列中的数据

2)紧接着对接收到的选票进行逻辑判断。根据其不同的state走不同的逻辑,最终根据判断逻辑再次把消息发送出去

3)这是很重要的一个判断规则,根据指定的要素进行判定两个选票的规则
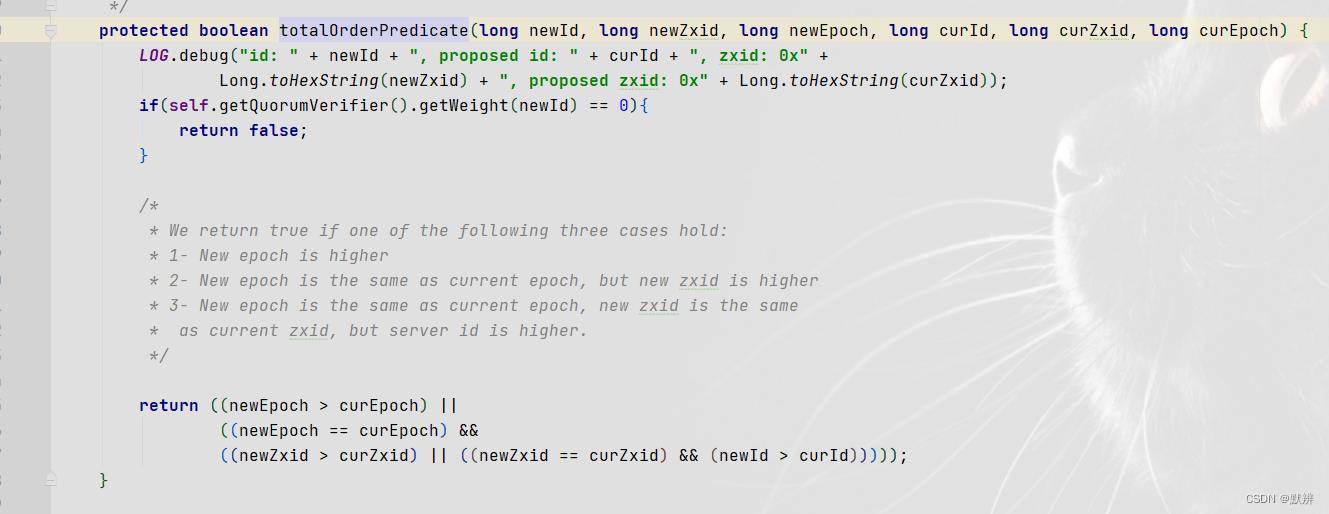
4)会调用该方法,最终走到其半数判定的条件。最终返回选择出来的leader节点,即endVote对象,如果没有选择到leader节点,则返回null

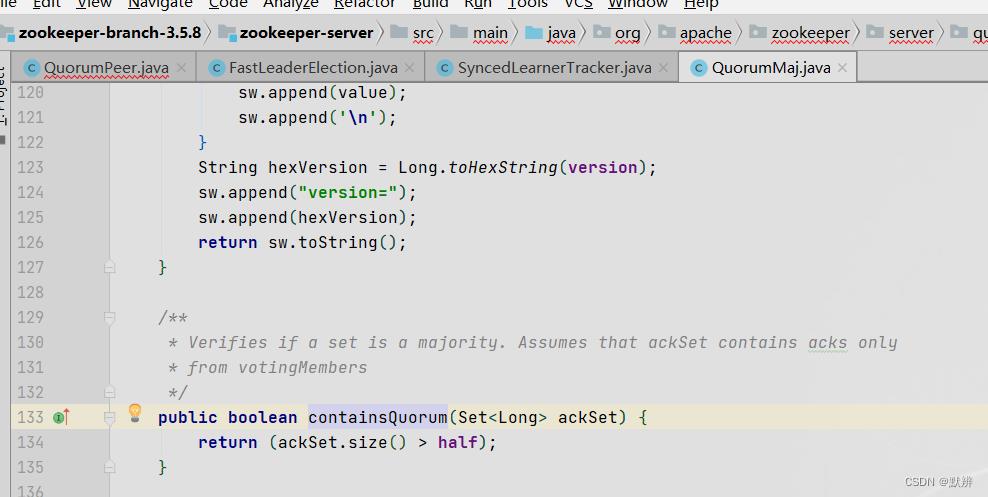
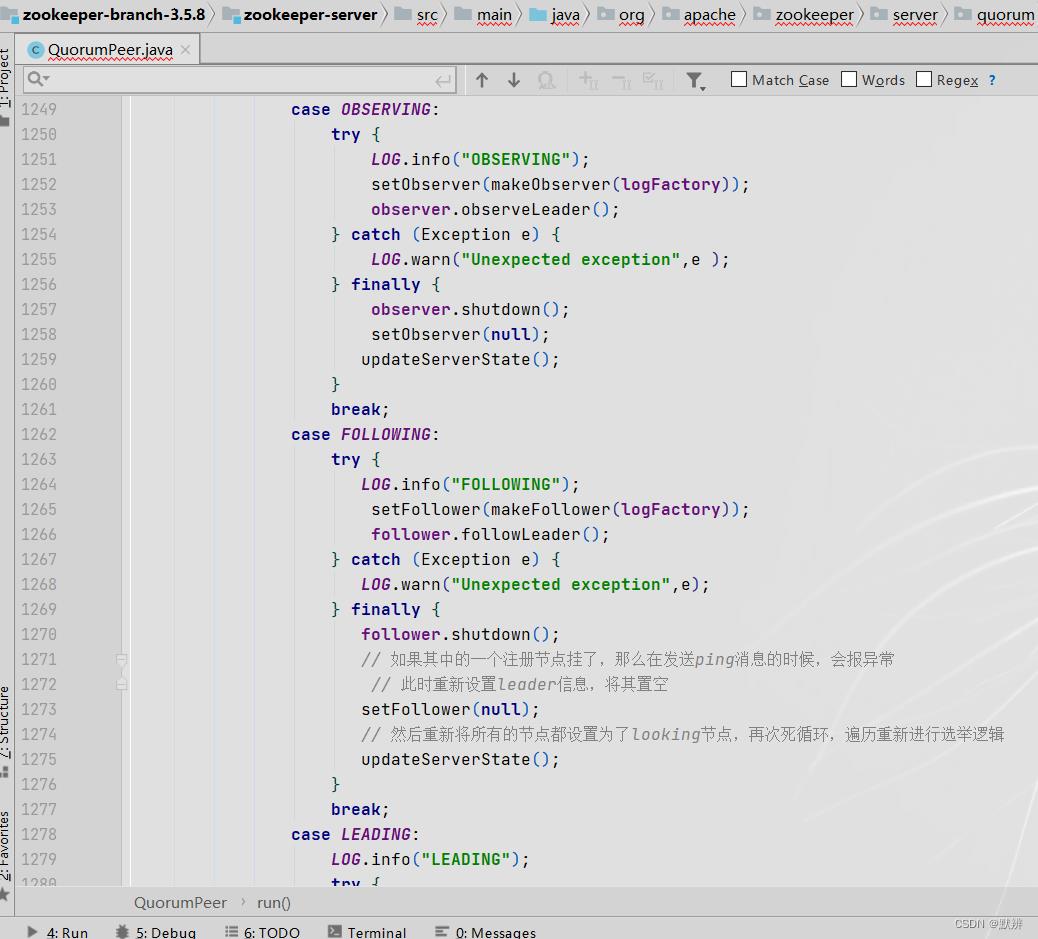
4、其余节点
LOOKING节点的流程为主要逻辑,在第一轮的while循环过后,就能够明确每种节点对应的类型是什么,第二次while循环的时候,就会走到对应的节点方法中去。详细的执行逻辑可请参考开头的那张流程图
五、Zookeeper之间数据同步
这里就回到了第一节中的,第一个共识。即配置集群的时候是有两个端口,最后面的端口,是用于集群节点的选举,倒数第二个端口则是用于同步Zookeeper节点之间的数据。
既然出现了新的端口通信,那么就会初始化新的服务端
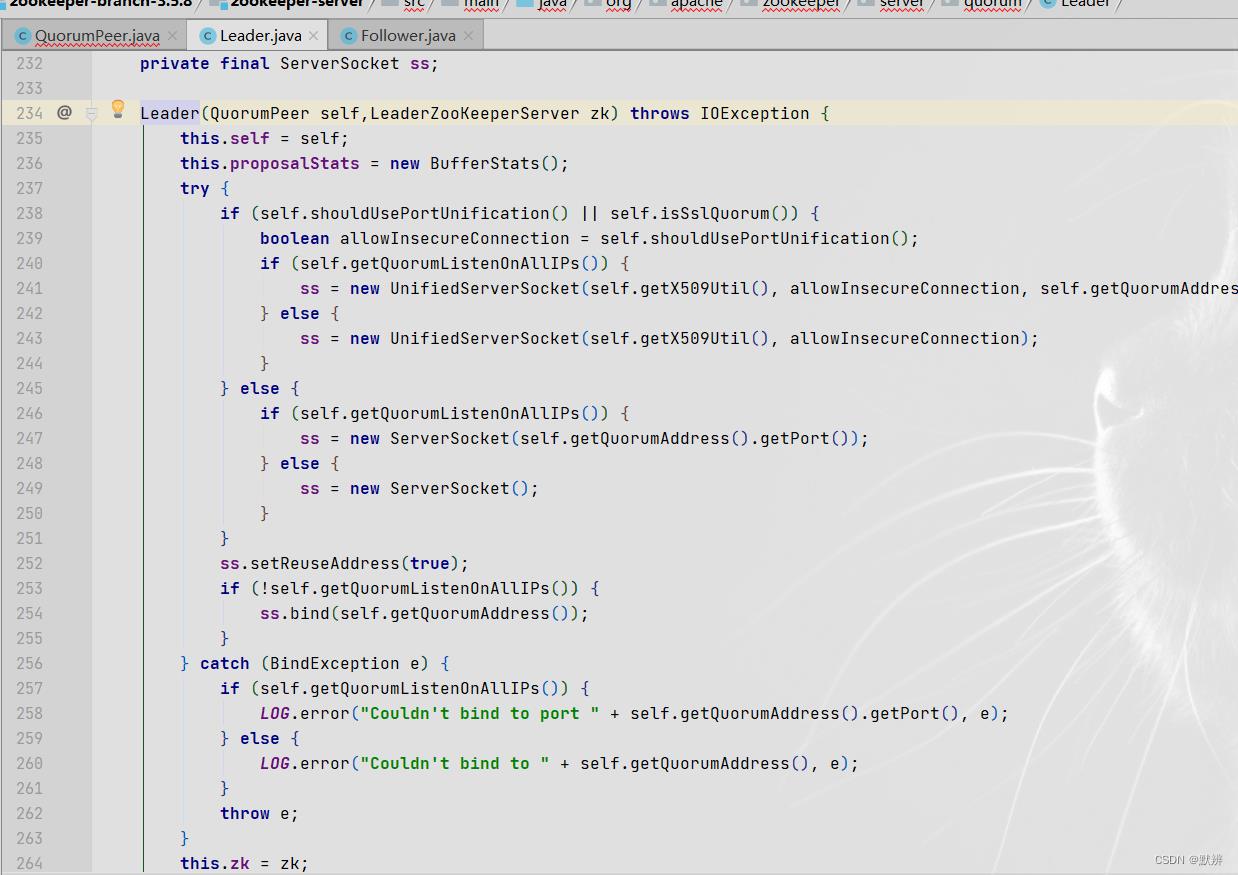
1、初始化LEADING节点

2、初始化新端口的服务端
这里就会根据新的配置,初始化新的服务端,用来接收zookeeper客户端之间的命令
六、LEADING节点挂之后流程
1、LEADING节点会不断发送PING命令
1)如果是leader节点则会走这段逻辑

2)在一个while死循环内部,会周期性的给learner发送ping数据

3)封装对应的PING数据包
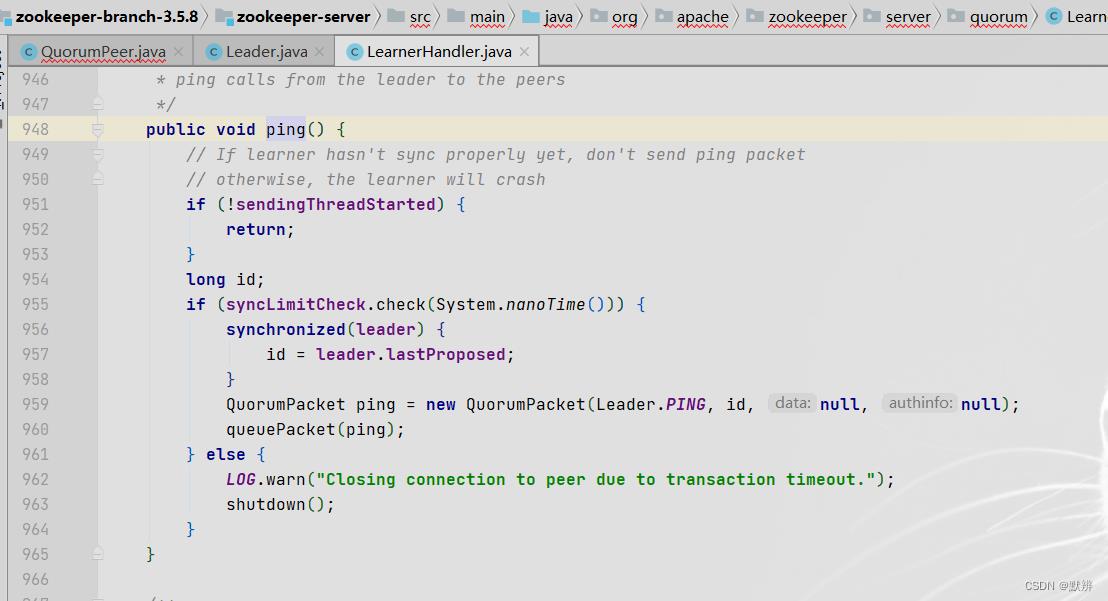
2、FOLLOWING节点不断接收命令
1)只要机器还运行着,就会轮循该方法,节点是FOLLOWING的机器就会调用follwLeader方法
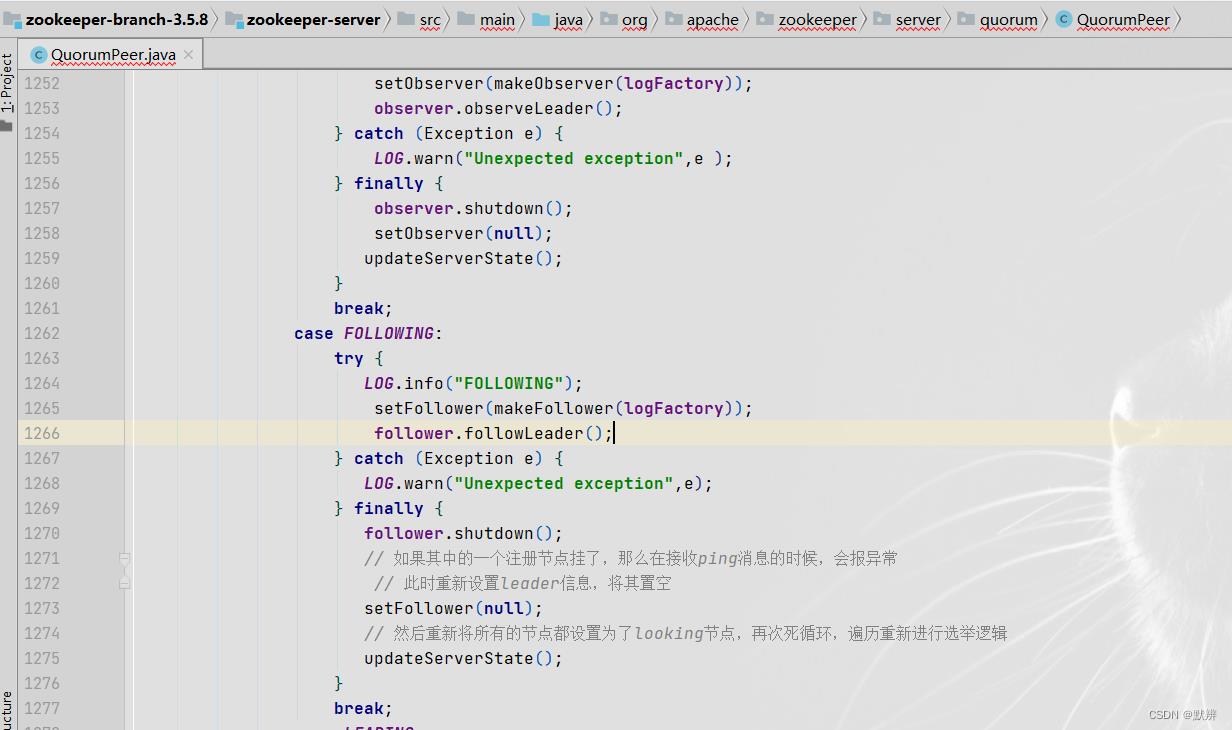
2)该方法中会调用readPacket方法,去接收数据。后面的processPacket方法会对接受到的数据进行处理。在这过程中就会出现获取不到数据,然后抛异常。那么就会跳转到上一步,在updateServerState()方法中,就会根据逻辑,把自己的FOLLWING节点设置为LOOKING节点,继而触发后续的再次选举流程

至此Zookeeper中Leader节点选取的流程就告一段落。开头那张整体的流程图,一定要多跟着源码多走几遍。
 创作打卡挑战赛
创作打卡挑战赛
 赢取流量/现金/CSDN周边激励大奖
赢取流量/现金/CSDN周边激励大奖
以上是关于浅谈Zookeeper集群选举Leader节点源码的主要内容,如果未能解决你的问题,请参考以下文章