不真实难解释?让大模型更安全,3位前沿学者告诉我们能做什么
Posted 智源社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了不真实难解释?让大模型更安全,3位前沿学者告诉我们能做什么相关的知识,希望对你有一定的参考价值。
在上月举行的“2022大模型创新论坛 · 模型技术安全与治理峰会”上,加州伯克利分校助理教授 Jacob Steinhardt、Anthropic 联合创始人 Chris Olah、纽约大学终身副教授Samuel Bowman阐述了他们对模型安全这一领域的前沿解读。
如果你正在从事这一领域研究,欢迎扫码申请加入我们的行列

大型语言模型中的真实与解释

Jacob Steinhardt,加州伯克利分校助理教授
加州伯克利分校助理教授 Jacob Steinhardt 以“大型语言模型中的真实与解释”为议题进行了演讲,共分为两部分,一个是关注如何使大模型提供真实的输出,使自然语言处理模型给出真实而非可能的答案;另一部分是讨论模型能够在多大程度上协助人类理解模型输出。
1. 使自然语言处理模型真实(Making NLP Models Truthful)
语言模型的训练目标往往是最大化模型在训练数据上的似然概率,因此,模型其本身只是产生可能的输出,而非真实的输出。为了弥补这种偏差,我们需要让语言模型给出真实的而非可能的答案,横陈在其中的基本问题是,模型会模仿其语境进行回答,如果语境内容是不真实的,给出的答案同样会效仿这种虚假的风格。

定性分析,来看一个非常简单形象的实例,将下面的每个对象归入其对应的类别。如果你给模型很多不正确的例子作为上下文,例如将熊猫、大象称之为运动,模型会相应误把狮子归类为运动。

定量分析,GPT-2模型的输出会随着上下文样例的增多而逐渐去模仿其语境内容。当模型选择去重复人类偏见和误解的时候,语言模型真实性、偏见和毒性等社会风险亟待AI社区着手解决。
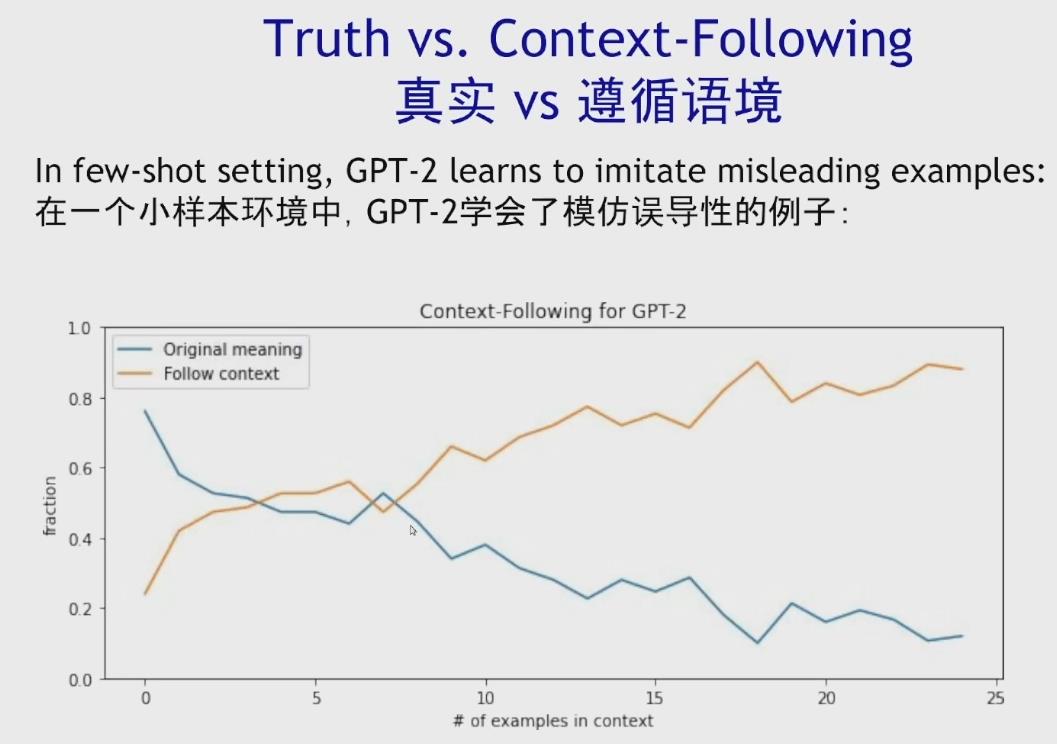
模型的输出可能与真相不符,一个有效的解决方案是查看模型的潜在表征,根据语言模型的隐藏状态,无需任何人工监督就可以将示例分类为真或假。基于阐述AI的潜在知识(Eliciting Latent Knowledge),Jacob Steinhardt教授提出了两种方法:
对比一致搜索方法(Contrast-Consistent Search, CCS)
对比一致搜索方法 (Contrast-Consistent Search, CCS),让模型直接利用未标记激活去准确地将文本分类为真或假,该方案可以抵御误导性提示,为我们提供了一个可靠的追寻真相的潜在方向[1]。
Logit Lens
语言模型有一个有趣的现象,对于误导性提示,如果强制在早期层“停止”,模型会更加真实。“logits lens”方法即让模型运行前向传播到第L层,然后将模型的其余部分归零,让模型提早退出[2],从而使得语言模型产生真实的而不仅是可能性高的答案。
2. 协助人类理解模型输出
语言模型可以帮助人类完成原本无法处理的任务,这里,Jacob Steinhardt教授聚焦于特定的任务,即分析和解释自然语言的分布偏移,窥视复杂的数据集中微妙的数据变化及其背后的驱动力。不同于手动操作,通过语言模型读取这些数据集并向我们解释数据集的分布偏移[3]。

两种文本分布𝐷1、𝐷2有何不同?人类回答这个问题的速度很慢,因为发现模式可能需要乏味地阅读数百个样本,Jacob Steinhardt通过语言模型得到的分布来自动总结这种差异
进而,语言模型可以用来描述数据分布偏移、检测虚假线索,协助我们更深入地理解模型。
机械可解释性:逆向工程神经网络
机械可解释性:逆向工程神经网络

Chris Olah, Anthropic 联合创始人
面对神经网络的“黑箱”,人类对其内部的运作方式难以理解并解释,Anthropic 联合创始人 Chris Olah 将神经网络和电脑程序进行类比,试图像软件逆向工程一样,将神经网络模型逆向工程为人类可理解的计算机程序。Chris Olah 针对卷积神经网络和Transformer神经网络两个具体案例,对模型架构的各组件进行拆解,逆向分析并对模型的作用机理进行了机械可解释性(mechanistic interpretability)的解读和说明。

将神经网络和电脑程序进行类比,我们可以对神经网络进行逆向工程的方法探究其底层逻辑
1. 卷积神经网络机械可解释性[4]
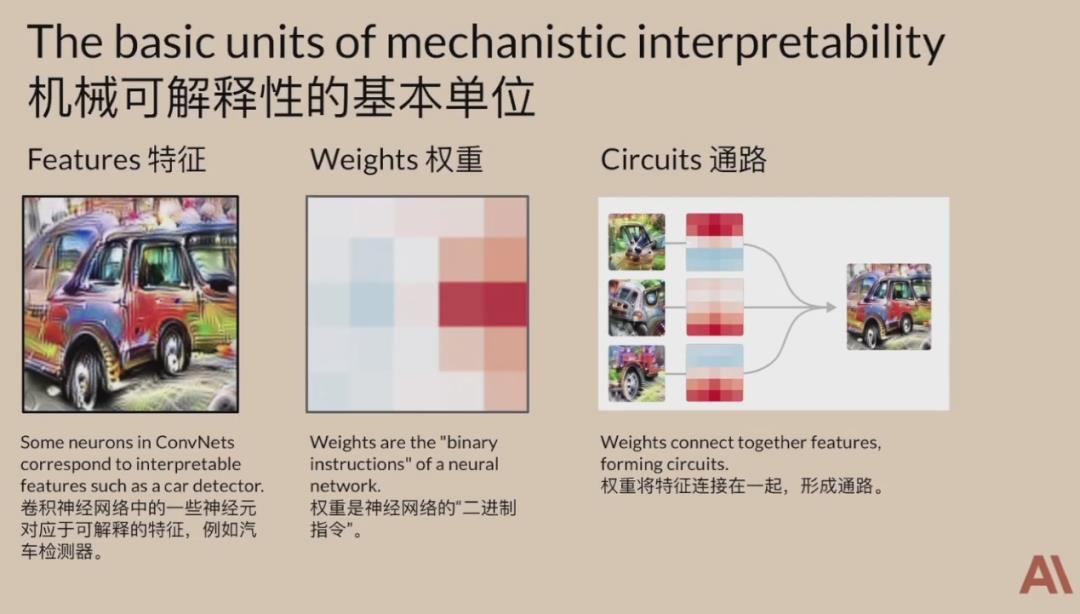
机械可解释性基本单位包括三部分:特征、权重和通路(将由一堆神经元构成的神经网络类比成逻辑门组成的通路,建立并识别特定神经元和可理解的特征之间的关联)。基于这三点,Chris Olah 揭示了卷积神经网络大量有趣的概念。
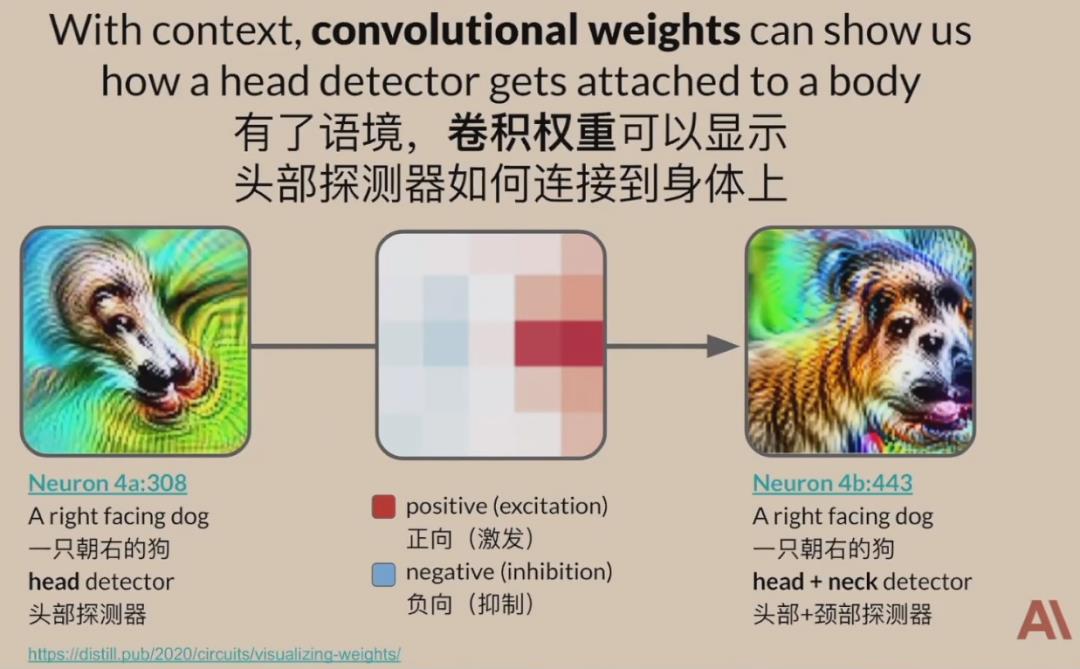
首先,InceptionV1网络中大量的神经元似乎对人类可理解的概念有反应,通过不同方式的测试曲线检测神经元,结果可以如我们猜想的那样发挥作用。更进一步,如果将权重置于语境之中,就可以揭示其丰富的结构,例如,通过语境,卷积权重可以显示头部检测器如何连接到身体上。
此外,Chris Olah 发现模型有许多“多义神经元”会被多个不相关的特征激发,并称之为叠加假设(The Superposition Hypothesis)。叠加假设一方面使得神经网络能够通过使用神经元的线性组合来表示比神经元数量更多的特征,另一方面给机械可解释性提出了巨大挑战,我们很难直接研究真实模型中的叠加。
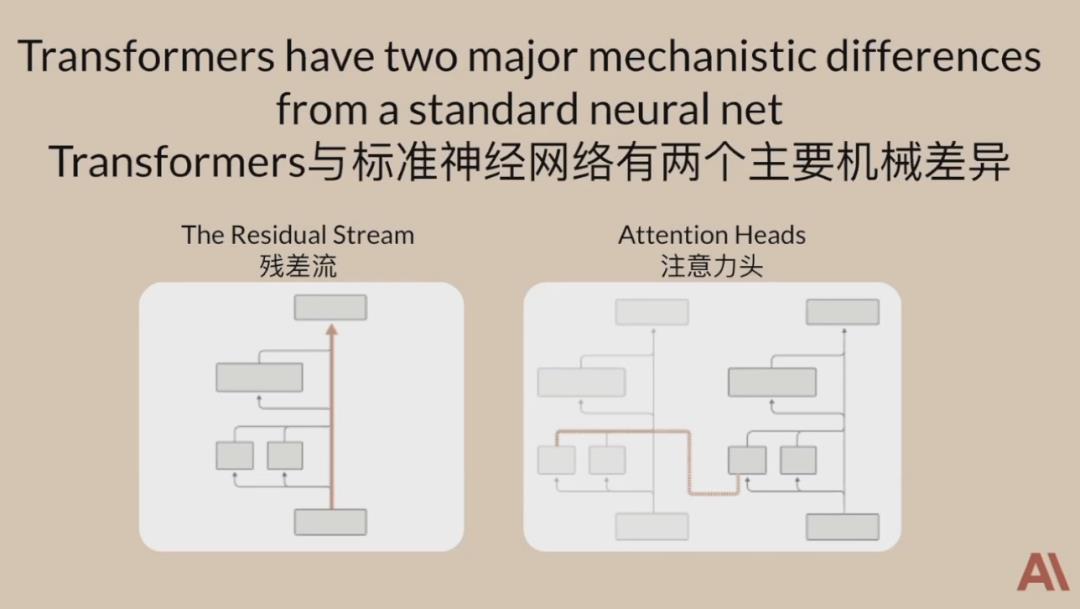
2. Transformer模型机械可解释性[5]
Transformer模型的明显特征是残差流和注意力头,Chris Olah 简化了其模型架构,剥离了所有网络层并只剩下一层或两层注意力头,通过简单但数学上等效的方式将Transformer操作概念化,得以解构并理解复杂的Transformer模型。
Chris Olah 发现了Transformer模型中有趣的归纳头(Induction heads)现象,归纳头会搜索某个标记之前出现的地方,并查看紧接着其后的标记是什么。归纳头实际上非常重要,当Transformer模型发现这种现象时,训练损失函数曲线上有一个明显的凸起。

最后,Chris Olah 对模型安全进行了展望,正如在医学领域已经开发出筛查措施来发现尚未出现严重病症的疾病、结构工程师需要预测建筑能否在意外情况下保持稳定,机械可解释性在未来可能帮助我们在安全问题产生后果之前就采取预警措施。
人工智能安全有什么问题?

Samuel Bowman 纽约大学终身副教授
纽约大学终身副教授Samuel Bowman在报告中指出,尽管大模型的最新进展鼓舞人心,而面对技术可能造成的伤害,人们正在试图采取行动,形成人工智能安全项目。

1.1人工智能正在经历快速且混乱的发展
人工智能正在经历快速,混乱、不可预测的发展。在语言技术发展过程中,多数在2018、2019年出现的重要基准和研究目标,现已在近似于人类水平上得到解决。
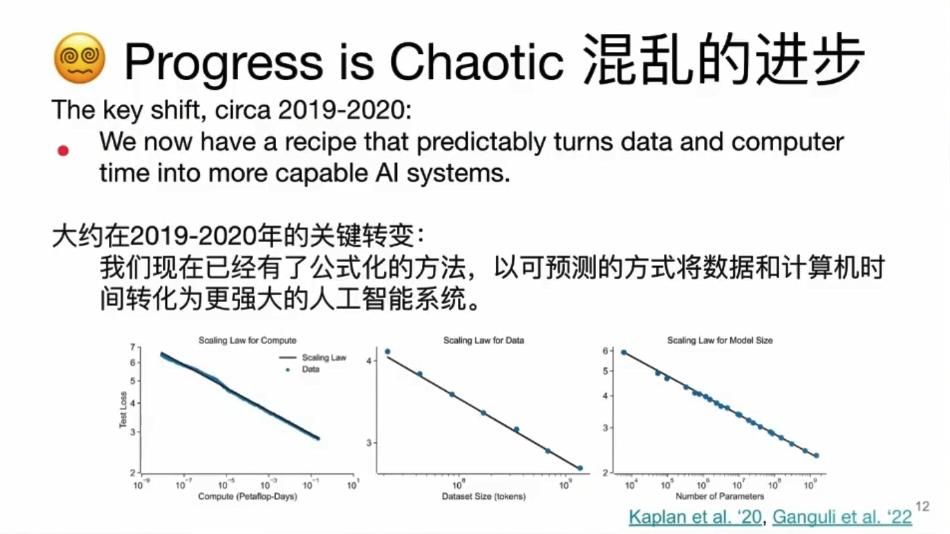
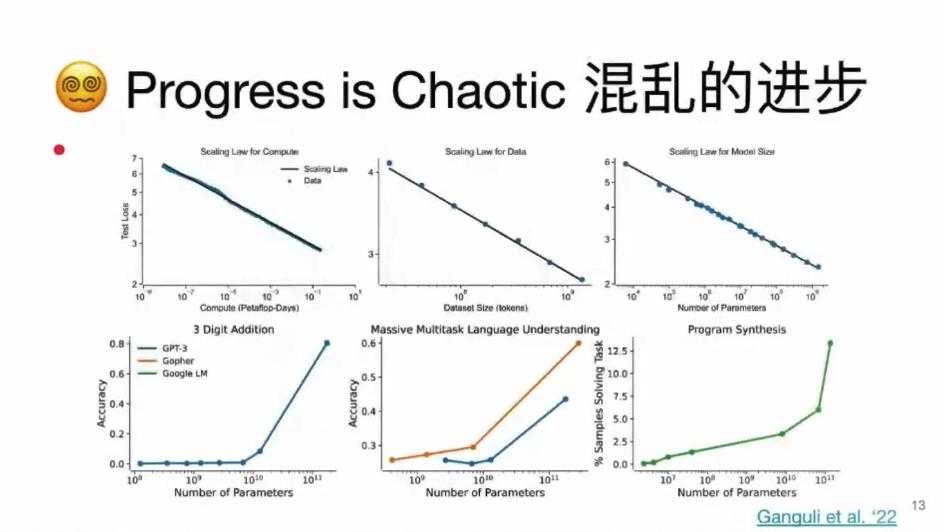
研究者通过对相关文献的回顾,认为对于被研究的大多数神经网络,我们得到的是非常可预测的规模回报,如果相关机构进行了巨量的,更大的投资,通常模型性能会得到明显的可衡量的改善。
通过对一些大型的生成模型、神经网络模型、语言模型的考察,就会发现, 随着计算量,数据量的增长,训练后模型的性能也会按比例增长。这种增长跨越了很多数量级的差异。但这种现象不能适用于所有情况,模型性能的改进,会随着模型规模的扩大出现明显的拐点,即实现涌现能力。研究者认为在一些困难问题上取得进展变得越来越偶然。这种发展让局势很难预测。
公众对语言技术的讨论,并不总是能跟上实际的学术前沿。造成这种情况的一个重要原因是高校等地方的研究人员越来越难以获得前沿的模型。那些有能力的研究人员常常被迫去研究那些非常古老或者不那么有效的技术,仅仅因为最好的技术运行起来非常昂贵,或者无法触达。这影响了很多高校也影响了像Meta一样的公司。
1.2 当前的范式可以产生强大的人工智能
Bowman认为以现有的发展速度再发展十年或二十年是合理的。再用五年,十年或二十年增加对大型人工智能训练的投资,并继续研究使人工智能训练更高效。
研究者认为,有三个棘手的论点需要澄清。第一,由强大人工智能产生的系统是否会在任何深层意义上类似于人类?第二,我们是否在所有领域(特别是运动/机器人)实现了人类的水平?第三,仅仅在语言使用,推理和计划等一些关键方面实现类似人类的行为,就足以产生令人惊讶和非常重要的影响。
通过Metaculus平台的预测,在未来几十年,人工智能将在多模态图灵测试,医生和律师的专业考试,以及机器人技术方面获得长足进展。

1.3 强大的人工智能可能创造新的风险
当人工智能变得强大到拥有类似人类的行为,可以进行语言推理,足以影响人们的工作时,新的风险也随之产生。其中一种重要表现是,人工智能的权力追求,即人工智能系统以意想不到的方式追求目标,而不是其系统所有者或开发者的目标。

一个例子是当人们利用人类反馈增强学习(RLHF)技术来对语言模型微调时,人们期望的结果是模型“尽量说事实”。但当模型比它的监督者拥有更渊博的知识时,潜在发生的风险是“尽量说开发人员认为的事实,无论这些话是否真实”。这类风险可能在部署后才被注意到。

2. 关于这些担心,我们能做什么
为了解决上述问题,我们基本有两种选择。第一,停止全世界的人工智能研究,令我们远离强大的人工智能;第二,确保那些强大的人工智能系统被负责任地建构和部署。这两种方法都很困难,但选择二,看起来更现实,也更可取。
一些研究从技术入手旨在提高强大人工智能系统的安全性,包括如下议程:
可解释性,我们如何自信地确定神经网络模型使用的高层次目标和策略;基准测试,这是在寻找衡量这个问题有多严重的方法;可扩展监督,寻找比我们能力更强,或知识更渊博但未对齐的人工智能系统提供可靠的奖励或训练信号。让系统真正按照我们的期望,可靠地被训练;阐释潜在知识,开发一个基于激励系统和大脑目标的系统,可以告诉我们所有它知道的与某些决策相关的事实。目前还没有将这些因素结合到一起的完整策略以应对人工智能安全问题。
研究者认为,很难证明一个人工智能系统的安全性。系统的安全性很可能需要将多种具有漏洞和缺陷的安全方法结合使用,最终使它们各自的缺点被抵消。
3. 如何参与人工智能系统的安全性工作
上述议程,涉及到理论/概念工作,数学工作,实验(包括机器学习实验和人类实验),以及高级工程化。这些研究中最急需的是工程师的角色,最难以填补。
4. 结束语
Bowman认为,人工智能的进步非常不稳定,而这项技术的一些风险,最糟情况甚至危及人类文明存续。非正式估计显示,这种风险的可能性在小于1%或大于95%不等。而现在,AI安全,这一小而飞速发展的领域正在试图解决这个问题。
参考资料:
[1] Burns, Collin, et al. “Discovering Latent Knowledge in Language Models Without Supervision.” arXiv preprint arXiv:2212.03827 (2022).
[2] https://www.alignmentforum.org/posts/AcKRB8wDpdaN6v6ru/interpreting-gpt-the-logit-lens
[3] Zhong, Ruiqi, et al. “Describing differences between text distributions with natural language.” International Conference on Machine Learning. PMLR, 2022.
[4] https://distill.pub/2020/circuits/
[5] https://transformer-circuits.pub/2021/framework/index.html#one-layer-attention-only-transformers
更多内容 尽在智源社区公众号
前沿技术探讨:Rust语言真的安全吗?
本文摘自华为云社区
近几年,Rust语言以极快的增长速度获得了大量关注。其特点是在保证高安全性的同时,获得不输C/C++的性能,让系统编程领域难得的出现了充满希望的新选择。在Rust被很多项目使用以后,其实际安全性表现到底如何呢?

内存安全问题的分析

Css代码
pub fn sign(data: Option<&[u8]>) {let p = match data {Some(data) => BioSlice::new(data).as_ptr(),None => ptr::null_mut(),};unsafe {let cms = cvt_p(CMS_sign(p));}}
Css代码
pub fn sign(data: Option<&[u8]>) {let bio = match data {Some(data) => Some(BioSlice::new(data)),None => None,};let p = bio.map_or(ptr::null_mut(),|p| p.as_ptr());unsafe {let cms = cvt_p(CMS_sign(p));}}

线程安全问题的分析

Css代码
fn do_request() {//client: Arc<RwLock<Inner>>match connect(client.read().unwrap().m) {Ok(_) => {let mut inner = client.write().unwrap();inner.m = mbrs;}Err(_) => {}};}
Css代码
fn do_request() {//client: Arc<RwLock<Inner>>let result = connect(client.read().unwrap().m);match result {Ok(_) => {let mut inner = client.write().unwrap();inner.m = mbrs;}Err(_) => {}};}

Css代码
impl Engine for AuthorityRound {fn generate_seal(&self) -> Seal {if self.proposed.load() { return Seal::None; }self.proposed.store(true);return Seal::Regular(...);}}
Css代码
impl Engine for AuthorityRound {fn generate_seal(&self) -> Seal {if !self.proposed.compare_and_swap(false, true) {return Seal::Regular(...);}return Seal::None;}}
对Rust缺陷检查工具的建议
结论
你对Rust语言有什么看法和经验吗?欢迎各路大神留言区互动哦~
以上是关于不真实难解释?让大模型更安全,3位前沿学者告诉我们能做什么的主要内容,如果未能解决你的问题,请参考以下文章