制作类似ThinkPHP框架中的PATHINFO模式功能
Posted 那一叶随风
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了制作类似ThinkPHP框架中的PATHINFO模式功能相关的知识,希望对你有一定的参考价值。
距离上一次发布的《制作类似ThinkPHP框架中的PATHINFO模式功能》(文章地址:http://www.cnblogs.com/phpstudy2015-6/p/6242700.html)已经过去好多天了,今晚就将剩下的一些东西扫尾吧。
上一篇文章已经实现了PATHINFO模式的URL,即我们访问MVC模式搭建的站点时,只需要在域名后面加上(/module/controller/action)即可,很智能化。并且通过new Object时的自动触发函数实现类文件的自动载入,因此只要我们搭建好基础的框架就可以不需要担心文件访问路径的问题啦,当然前提是要有合理有规律的命名方式。
一、本文章实现目标
上一篇文章已经实现具体的功能啦,那么我这一次还要写什么呢?还有什么要注意的么?
作为程序猿钻研琢磨精神是必不可少的,所以这一次我就将上一篇文章改造成文件保存版本的,即将$routes里面的正则规则存入文件中去,然后getRoute需要用的时候再将其取出来。然后再通过apache的ab压力测试一下二者的效率问题等。
二、核心知识
这篇文章所涉及的核心知识不多。
1、存与取文件,我这次使用的是file_put_contents()与file_get_contents()。当然还有很所的选择啦。
2、存与取文件之前当然要先序列化与反序列化啦,使用的函数就是:serialize()与unserialize()。
3、apache的ab并发测试。(并发测试这种高深的玩意,刚接触还不太了解,有熟悉这块的哥们,如果允许,请给小弟一些建议)
三、环境说明
Linux虚拟机、php5.3.6、域名www.test2.com
四、代码实例
/Framework/Core/Url2.class.php
1 <?php 2 /* 3 *@制 者:壹叶随风 4 *@博 客 :http://www.cnblogs.com/phpstudy2015-6/ 5 *@时 间 :2017.1.10 6 *@版 本 :文件保存版 7 */ 8 class Url2 9 { 10 //定义正则表达式常量 11 const REGEX_ANY="([^/]+?)"; #非/开头任意个任意字符 12 const REGEx_INT="([0-9]+?)"; #数字 13 const REGEX_ALPHA="([a-zA-Z_-]+?)"; #字母 14 const REGEX_ALPHANUMERIC="([0-9a-zA-Z_-]+?)"; #任意个字母数字_- 15 const REGEX_STATIC="%s"; #占位符 16 const ANY="(/[^/]+?)*"; #任意个非/开头字符 17 18 #保存文件式 19 public function addRoute($route,$int) 20 { 21 if($int==1) 22 { 23 $routes=file_get_contents(\'./routes.txt\'); 24 $routes=unserialize($routes); 25 } 26 $routes[]=$this->_ParseRoute($route); 27 $routes=serialize($routes); 28 file_put_contents(\'./routes.txt\', $routes); 29 } 30 31 32 /*private 33 @input :$route 输入路由规则 34 @output:return 返回路由正则规则 35 */ 36 private function _ParseRoute($route) 37 { 38 39 $parts=explode("/", $route); #分解路由规则 40 $regex="@^"; #开始拼接正则路由规则 41 if(!$parts[0]) 42 { 43 array_shift($parts); #除去第一个空元素 44 } 45 foreach ($parts as $part) 46 { 47 $regex.="/"; 48 $args=explode(":",$part); 49 if(!sizeof($args)==2) 50 { 51 continue; 52 } 53 $type=array_shift($args); 54 $key=array_shift($args); 55 $this->_normalize($key); #使参数标准化,排除其他非法符号 56 $regex.=\'(?P<\'.$key.\'>\'; #为了后面preg_match正则匹配做铺垫 57 switch (strtolower($type)) 58 { 59 case \'int\': #纯数字 60 $regex.=self::REGEX_INT; 61 break; 62 case \'alpha\': #纯字母 63 $regex.=self::REGEX_ALPHA; 64 break; 65 case \'alphanum\': #字母数字 66 $regex.=self::REGEX_ALPHANUMBERIC; 67 break; 68 default: 69 $regex.=$type; #自定义正则表达式 70 break; 71 } 72 $regex.=")"; 73 } 74 $regex.=self::ANY; #其他URL参数 75 $regex.=\'$@u\'; 76 return $regex; 77 } 78 79 /*public,将输入的URL与定义正则表达式进行匹配 80 @input :$request 输入进来的URL 81 @output :return 成功则输出规则数组数据 失败输出false 82 */ 83 public function getRoute($request) 84 { 85 #处理request,进行参数处理,不足M、C、A,则自动补为home、index、index,即构建MVC结构URL 86 $request=rtrim($request,\'/\'); #除去右边多余的斜杠/ 87 $arguments=explode(\'/\',$request); 88 $arguments=array_filter($arguments); #除去数组中的空元素 89 $long=sizeof($arguments); #数组中的个数 90 switch ($long) #判断个数,不足就补够 91 { 92 case \'0\': 93 $request=\'/home/index/index\'; 94 break; 95 case \'1\': 96 $request.=\'/index/index\'; 97 break; 98 case \'2\': 99 $request.=\'/index\'; 100 break; 101 } 102 $matches=array(); #定义匹配后存贮的数组 103 $temp=array(); #中间缓存数组 104 105 #保存文件式 106 $routes=file_get_contents(\'./routes.txt\'); 107 $routes=unserialize($routes); 108 foreach ($routes as $v) #开始匹配 109 { 110 preg_match($v, $request, $temp); #需要重点理解这个数组 111 $temp?$matches=$temp:\'\'; 112 } 113 if($matches) #判断$matches是否有数据,无返回false 114 { 115 foreach ($matches as $key => $value) #筛选 116 { 117 if(is_int($key)) 118 { 119 unset($matches[$key]); #除去数字key元素,保留关联元素。与上面的preg_match一起理解 120 } 121 } 122 $result=$matches; 123 if($long > sizeof($result)) #URL参数超过后的处理 124 { 125 $i=1; 126 foreach ($arguments as $k => $v) 127 { 128 if($k > sizeof($result)) 129 { 130 if($i==1) 131 { 132 $result[$v]=\'\'; 133 $temp=$v; 134 $i=2; 135 } 136 else 137 { 138 $result[$temp]=$v; 139 $i=1; 140 } 141 } 142 } 143 } 144 return $result; 145 } 146 return false; 147 } 148 #使参数标准化,不能存在符号,只能是a-zA-Z0-9组合 149 private function _normalize(&$param) 150 { 151 $param=preg_replace("/[^a-zA-Z0-9]/", \'\', $param); 152 } 153 } 154 /*使用实例: 155 #1、保存则正 156 载入本类文件 157 include \'./Url.class.php\'; 158 $router=new Url(); 159 $router->addRoute("/alpha:module/alpha:controller/[0-9]+?:a1a",0); #0代表清空文件中所有内容,从新保存 160 $router->addRoute("/alpha:module/alpha:controller/alpha:action",1); #1代表在文件后面添加正则规则 161 $router->addRoute("/alpha:module/alpha:controller/alpha:action/(www[0-9]+?):id",1); 162 #2、注释上面的开始访问 163 include \'./Url.class.php\'; 164 $router=new Url(); 165 $url=$_SERVER[\'REQUEST_URI\']; 166 $urls=$router->getRoute($url); 167 echo "<pre>"; 168 print_r($urls); 169 echo "</pre>";die; 170 */ 171 ?>
以上是更改后的类文件,主要更改有三处地方。
1、将原本定义的$routes(protected $routes=array())去除。因为采用文件保存后,此定义任何意义。
2、方法addRoute()进行大改。如下图:
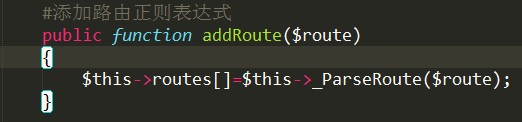
更改为:
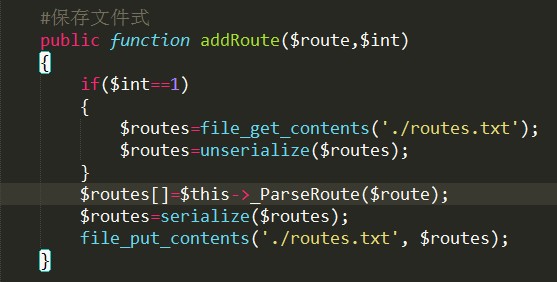
3、getRoute()将正则规则去除的地方
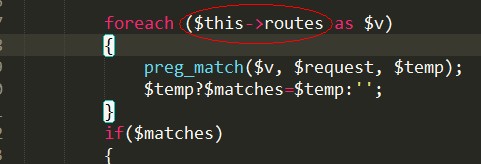
更改为:

开始访问:
1、存规则
index.php
1 <?php 2 include \'./Framework/Core/Core.php\'; 3 #第一步,存正则规则 4 $router=new Url2(); 5 $router->addRoute("/alpha:module/alpha:controller/[0-9]+?:a1a",0); 6 $router->addRoute("/alpha:module/alpha:controller/alpha:action",1); 7 $router->addRoute("/alpha:module/alpha:controller/alpha:action/(www[0-9]+?):id",1);
访问:www.test2.com即可
立即在根目录生成 routes.txt

vi里面是已经序列化的内容

2、正式访问
index.php文件更改如下
1 <?php 2 include \'./Framework/Core/Core.php\'; 3 4 $router=new Url2(); 5 $url=$_SERVER[\'REQUEST_URI\']; 6 $urls=$router->getRoute($url); 7 $_GET[\'urls\']=$urls; 8 $m=$urls[\'module\']; 9 $c=$urls[\'controller\']; 10 $a=$urls[\'action\']; 11 if($m&&$c) 12 { 13 $autoload=new Autoload($m,$c); 14 $autoload->putFile(); 15 } 16 $object=new $c; 17 $object->$a(); 18 19 ?>
访问:http://www.test2.com/Home/Test/action/
结果如下:

更改成功!
五、二者压力测试
使用apache的ab对二者进行压力测试。(我使用window本机的apache的ab进行测试)
ab中参数有很多,这里主要使用 -c 与 -n
-c:一次产生的请求个数
-n:在测试会话中所执行的请求个数
ab性能指标:
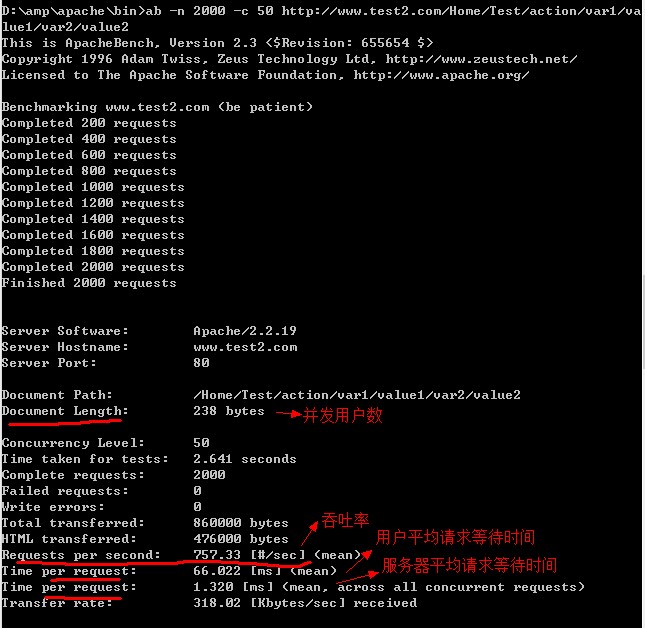
1、吞吐率(Requests per second)
服务器并发处理能力的量化描述,单位是reqs/s,指的是在某个并发用户数下单位时间内处理的请求数。某个并发用户数下单位时间内能处理的最大请求数,称之为最大吞吐率。吞吐率是基于并发用户数的,因此不同并发用户下,吞吐率一般不一样。
计算公式:总请求数/处理完成这些请求所花费的时间,即 Request per second=Complete requests/Time taken for tests
注意:此值代表当前机器的整体性能,值越大越好。
2、并发用户数(Concurrency Level)
3、用户平均请求等待时间(Time per request)
计算公式:处理完成所有请求数所花费的时间/(总请求数/并发用户数),即:Time per request=Time taken for tests/(Complete requests/Concurrency Level)
4、服务器平均请求等待时间(Time per request:across all concurrent requests)
计算公式:处理完成所有请求数所花费的时间/总请求数,即:Time taken for/testsComplete requests
测试路径:http://www.test2.com/Home/Test/action/var1/vaule1/var2/value2
-n 2000 -50
执行2000个请求,最快使用50个并发连接
一、先对第一个(非文件版本)进行测试:
结果如下图所示:
二、对第二个版本(文件存贮)进行测试:
结果如下图所示:
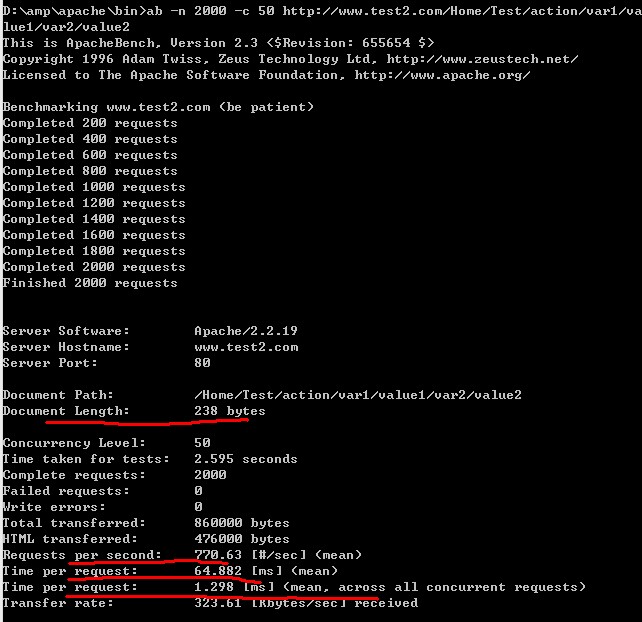
以上两个测试数据比较,结果显示,各个数据都很接近。
本人更改-n、-c已经var/value等参数,进行多次的压力测试,最终结果表明,这两个类文件的吞吐率、并发用户数、用户平均请求等待时间、服务器平均请求等待时间等等数据几乎差不多,即两个类文件效率性能差不多。
(以上是自己的一些见解,若有不足或者错误的地方请各位指出)
作者:那一叶随风
声明:本博客文章为原创,只代表本人在工作学习中某一时间内总结的观点或结论。转载时请在文章页面明显位置给出原文链接。
以上是关于制作类似ThinkPHP框架中的PATHINFO模式功能的主要内容,如果未能解决你的问题,请参考以下文章
nginx 配置https(可支持thinkphp的pathinfo模式)