Stable Diffusion 个人推荐的各种模型及设置参数扩展应用等合集(不断更新中)
Posted 暂时先用这个名字
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Stable Diffusion 个人推荐的各种模型及设置参数扩展应用等合集(不断更新中)相关的知识,希望对你有一定的参考价值。
本文主要是把平时使用的模型及其参数进行推荐和整理,相关
- 运用时的问题解决参考:《Windows使用Stable Diffusion时遇到的各种问题整理》;
- 安装时的问题解决参考:《Windows安装Stable Diffusion WebUI及问题解决记录》。
一、说明
|表示或者+表示以上
二、模型
适用风景、房子、车子等漫画类风格



模型的VAE不要用模型附带的,好像就是naifu的官方vae,很老了,用
vae-ft-mse-840000-ema-pruned.ckpt或者是kl-f8-anime2.ckpt;
嵌入模型要下载作者推荐的负面关键词汇总的 EasyNegative,下载后放到embeddings文件夹内,tagEasyNegative才会起效。
参数:
- Checkpoint:
Counterfeit-V2.5.safetensors [bd83b90a2e] - VAE:
vae-ft-mse-840000-ema-pruned.ckpt - Clip skip:
2 - Sampling steps:
20+ - Sampling method:
DPM++ 2M Karras|DPM++ SDE Karras - Prompt:
(masterpiece, best quality, very detailed, Ultra HD: 1.2)|(((masterpiece))), (((best quality))), (((extremely detailed))), Depth of field, illustration, shiny, pastel color,
案例:
(masterpiece, best quality, very detailed, Ultra HD: 1.2)
Negative prompt: EasyNegative, nsfw, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, bad feet,
Seed: 31337, Steps: 32, Sampler: DPM++ SDE Karras, CFG scale: 7
下载:
Checkpoint:https://huggingface.co/gsdf/Counterfeit-V2.5
VAE:https://huggingface.co/Yukihime256/840000/tree/main
EasyNegative:https://civitai.com/models/7808/easynegative
来源:
强烈推荐的超细节风格化模型和参数
古风

水彩国画风
参数:
- Checkpoint:
dalcefo_painting - Clip skip:
2 - Sampling steps:
20+ - Sampling method:
DPM++ 2M Karras|DPM++ SDE Karras - Prompt:
<(masterpiece, realistic:1.3), (extremely intricate:1.2)>,
案例:
<(masterpiece, realistic:1.3), (extremely intricate:1.2)>, portrait of a girl, face, close up, pointy ears, dress, half-closed eyes, jewelry, sitting, strapless, strapless dress, breasts, watermark, bare shoulders, tiara, grey dress, cleavage, long hair, braid, grey hair, long eyelashes, solo, profile, solo, elf,
Negative prompt: (worst quality, low quality:1.4), (depth of field, blurry:1.2), (greyscale, monochrome:1.1), 3D face, cropped, lowres, text, jpeg artifacts, signature, watermark, username, blurry, artist name, trademark, watermark, title, multiple view, Reference sheet, curvy, plump, fat, muscular female, strabismus,
Size: 520x680, Seed: 285145899, Model: dalcefo_v3_painting3, Steps: 26, Sampler: DPM++ 2M Karras, CFG mode: Linear Up, CFG scale: 15, Clip skip: 2, Mimic mode: Linear Up, Model hash: 7107c05c1c, Mimic scale: 15, Hires upscale: 1.5, Hires upscaler: Latent (nearest-exact), CFG scale minimum: 0, Denoising strength: 0.5, Mimic scale minimum: 0, Threshold percentile: 100, Dynamic thresholding enabled: True
可写实的综合体


这个模型融合了多个模型(比如2.2版本融合了f222_v1.ckpt、elldrethSLucidMix_V10.cpkt、hassanBlendAllVersio_hassanBlend14.ckpt、seek_art_mega_v1.ckpt (license)、modelshoot-1.0.ckpt),并且2.2版是在stable diffusion1.5的基础上训练出来的,可以使用明星脸,而2.0以后的版本对明星脸进行了限制。
可以用关键字设置相机角度和人物动作
参数:
- Checkpoint:
Protogen x5.8 Rebuilt (Scifi+Anime) Official Release|Protogen x5.3 (Photorealism) Official Release|Protogen x3.4 (Photorealism) Official Release|Protogen v2.2 (Anime) Official Release - Clip skip:
2 - Sampling steps:
20+ - Sampling method:
DPM++ 2M Karras|DPM++ SDE Karras - Prompt:
(from_above:1.3)|(from_below:1.3)|(from_side:1.3)|(from_behind:1.3)|(hand_on_hip:1.2)|(sitting:1.2) - Trigger Words:
MODELSHOOT STYLE|NOUSR ROBOT
案例:
(sitting:1.2),modelshoot style, (extremely detailed 8k wallpaper),a medium shot photo of a sexy female soldier, American ERDL Lowland CAMO, Intricate, High Detail, dramatic, elite military forces real world, fantastic location, battle environment, rugged harsh situation soldier, action shot, skin pores, very dark lighting, heavy shadows, detailed, detailed face, (vibrant, photo realistic, realistic, dramatic, dark, sharp focus, 8k), (weathered greasy dirty damaged old worn military soldier outfit:1.3),
Negative prompt: Asian, black and white, close up, cartoon, 3d, denim, (disfigured), (deformed), (poorly drawn), (extra limbs), blurry, boring, sketch, lackluster, signature, letters, watermark, low res , horrific , mutated , artifacts , bad art , gross , b&w , poor quality , low quality , cropped
Seed: 452943117, Steps: 30, Sampler: DPM++ SDE Karras, CFG scale: 7
RPG 游戏人物类


可根据职业(巫师、战士等)、衣物(皮甲、布甲等)进行规划
参数:
- Checkpoint:
rpg_V4 - Clip skip:
2 - Sampling steps:
30+ - Sampling method:
DPM++ 2M Karras|DPM++ SDE Karras
案例:
full body shot photo of the most beautiful artwork in the world featuring a modern female (rogue thief:1.1) wearing multiple layer (leather armor:1.1), sexy, big eyes, urban tokyo futuristic look, neon lights, night, slow motion, reflections, orange raincoat, intricate detail, nostalgia, high boots, heart professional majestic oil painting by Ed Binkley, Atey Ghailan, Studio Ghibli, by Jeremy Mann, Gregory Manchess, Antonio Moro, trending on ArtStation, trending on CGSociety, Intricate, High Detail, Sharp focus, dramatic, photorealistic painting art by midjourney and greg rutkowski,
Negative prompt: cartoon, 3d, ((disfigured)), ((bad art)), ((deformed)),((extra limbs)),((extra barrel)),((close up)),((b&w)), weird colors, blurry,(((duplicate))), ((morbid)), ((mutilated)), [out of frame], extra fingers, mutated hands, ((poorly drawn hands)), ((poorly drawn face)), (((mutation))), (((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))), ((extra limbs)), cloned face,(((disfigured))), out of frame, ugly, extra limbs, (bad anatomy),gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated hands, (fused fingers), (too many fingers), (((long neck))), (((tripod))), (((tube))), Photoshop, video game, ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, mutation, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, body out of frame, blurry, bad art, bad anatomy, 3d render, (((umbrella))
下载及学习
https://huggingface.co/Anashel/rpg
https://huggingface.co/Anashel/rpg/resolve/main/RPG-V4-Model-Download/RPG-Guide-v4.pdf
AI生成图像竟如此真实了?Stable Diffusion Model本地部署教程

✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。
🍎个人主页:小嗷犬的个人主页
🍊个人网站:小嗷犬的技术小站
🥭个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。
本文目录
图像生成
Stable Diffusion Model 是一个基于扩散模型的图像生成模型。早在模型刚刚兴起的时候,博主就有所关注,尝试过本地部署,但是由于设备硬件配置限制,最终也没有能够真正的在本地跑起来。
考虑到人工智能各个领域的模型都是往着大模型方向发展,所以博主觉得如果当时跑不起来,在不更新硬件的情况下,以后也没有机会再跑了。
当时各个在线 AI 图片生成平台生成的效果往往都不尽人意,并且不支持自己训练模型,博主就很长一段时间没有再关注这个领域了。
前几天偶然发现 AI 生成图片的效果有明显的提升,甚至可以说是有些惊艳了。于是博主在网上恶补了这段时间的相关知识,发现进步似乎比我想象的还要大。
stable-diffusion-webui
stable-diffusion-webui 是 AUTOMATIC1111 大佬在 Github 上开源的一个专用于图片生成模型的 WebUI,可以在本地部署,支持导入模型和自己训练。
重要的是,该项目的部署方式非常简单,不需要任何的编程基础,环境也会帮你自动配置好;GUI 的操作也非常简单,所见即所得。

你所做的只是要安装 git,下载项目,然后点击运行脚本,就可以了,部署和使用门槛大大降低。
Stable Diffusion Model
除了 stable-diffusion-webui 外,我们还需要一个图片生成模型才能生成图片。
模型可以自己训练,但我推荐第一次还是直接下载别人训练好的模型,这样可以直接体验。各种的 Stable Diffusion 模型可以在 Civitai 上找到。
现在的各种模型对硬件要求各不相同,有的模型不仅效果好于从前,而且硬件要求也比原来更低了。
博主使用的显卡为 NVIDIA GeForce RTX 3050 Ti Laptop GPU,只有 4G 显存。以前的模型连生成 128x128 的图片都会爆显存,现在的模型却可以生成 512x768 的图片。
硬件门槛也没有以前那么高了。
本地部署
本教程的设备要求:
- 显卡为 NVIDIA 显卡,显存大于 4G
- 硬盘空间足够
- Windows 系统
安装 git
首先,我们需要安装 git,如果你已经安装了 git,可以跳过这一步。
git 是一个开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目。
git 的安装非常简单,只需要在 git 官网 下载安装包,然后正常安装就可以了。
stable-diffusion-webui 需要使用它来自动配置环境。
项目下载
点击以下链接下载项目 release:
stable-diffusion-webui
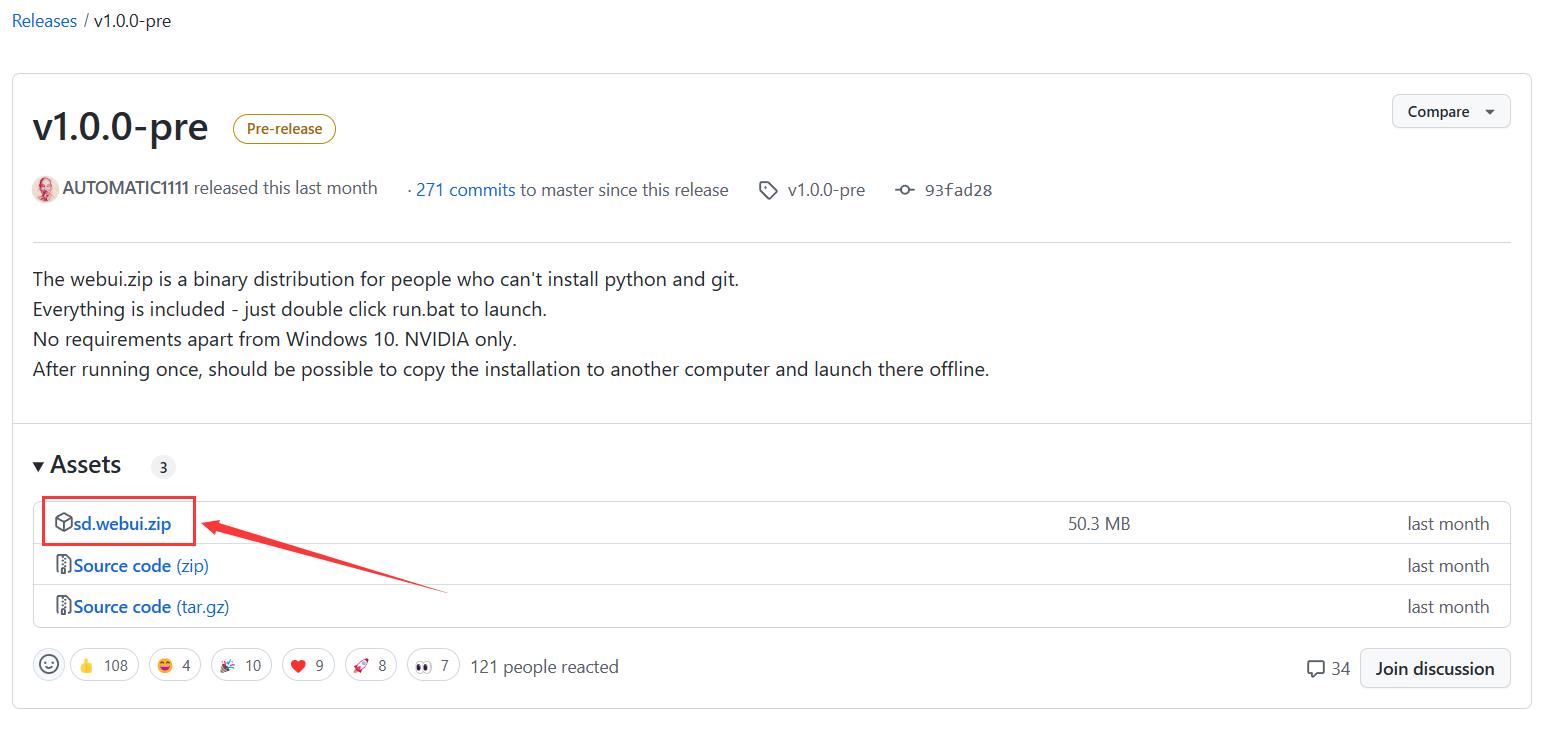
项目部署
下载完成后,解压到任意目录,然后双击运行 update.bat,更新项目为最新版本。
当出现以下信息时,说明项目已经是最新的:
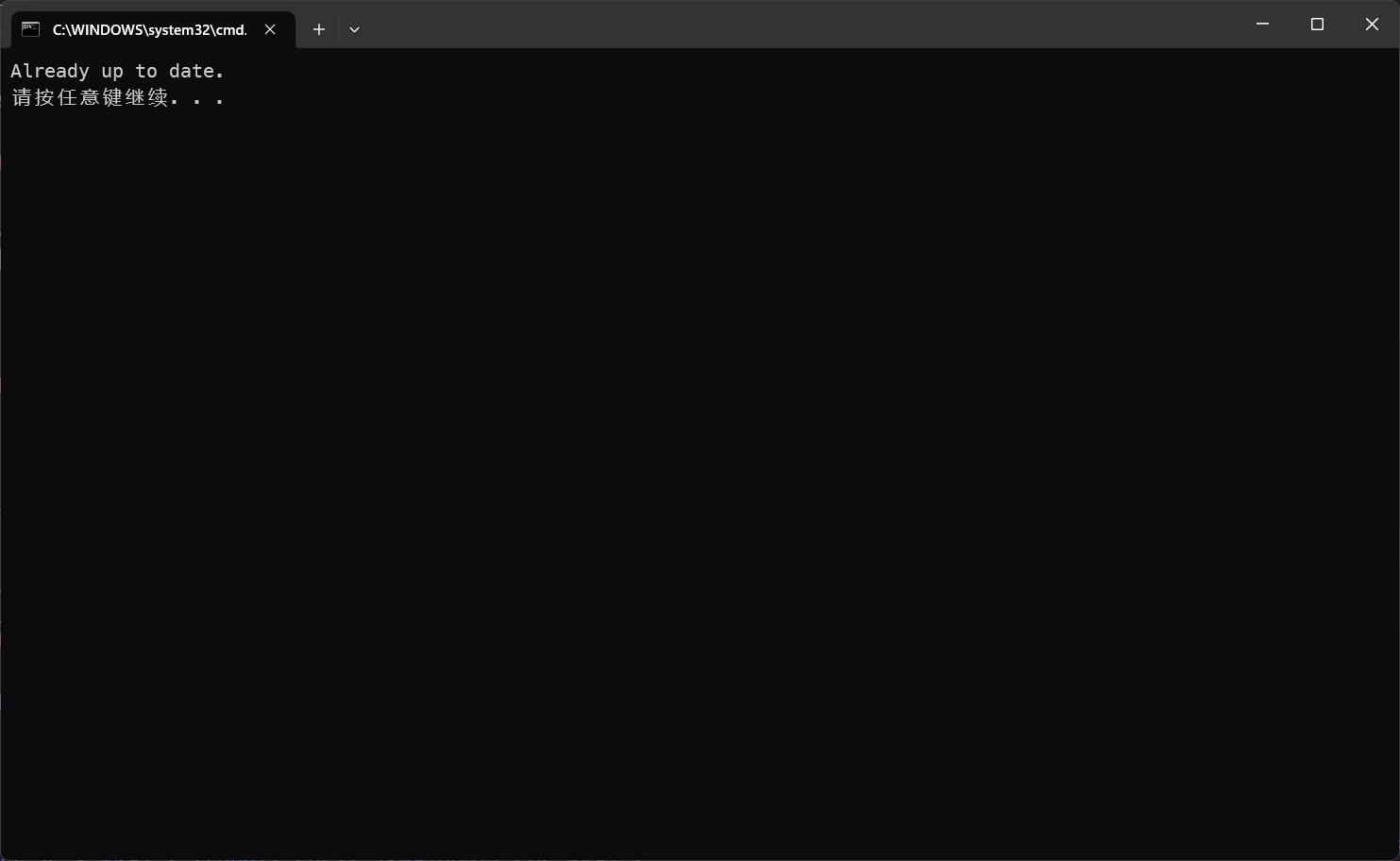
然后双击运行 run.bat,运行项目。首次运行会安装环境,所以需要等待一段时间。环境安装时出现错误通常属于 GitHub 的连接问题,可以自行设置代理。
安装的环境是 Pytorch 和 CUDA 以及一些 Python 第三方库和 Github 上的项目,安装过程中会自动下载。stable-diffusion-webui 自带 Python,所以不需要自己安装 Python 环境。
当出现以下信息时,说明 WebUI 已经运行在本地了:

在浏览器中访问 local URL,即可打开 WebUI。
模型导入
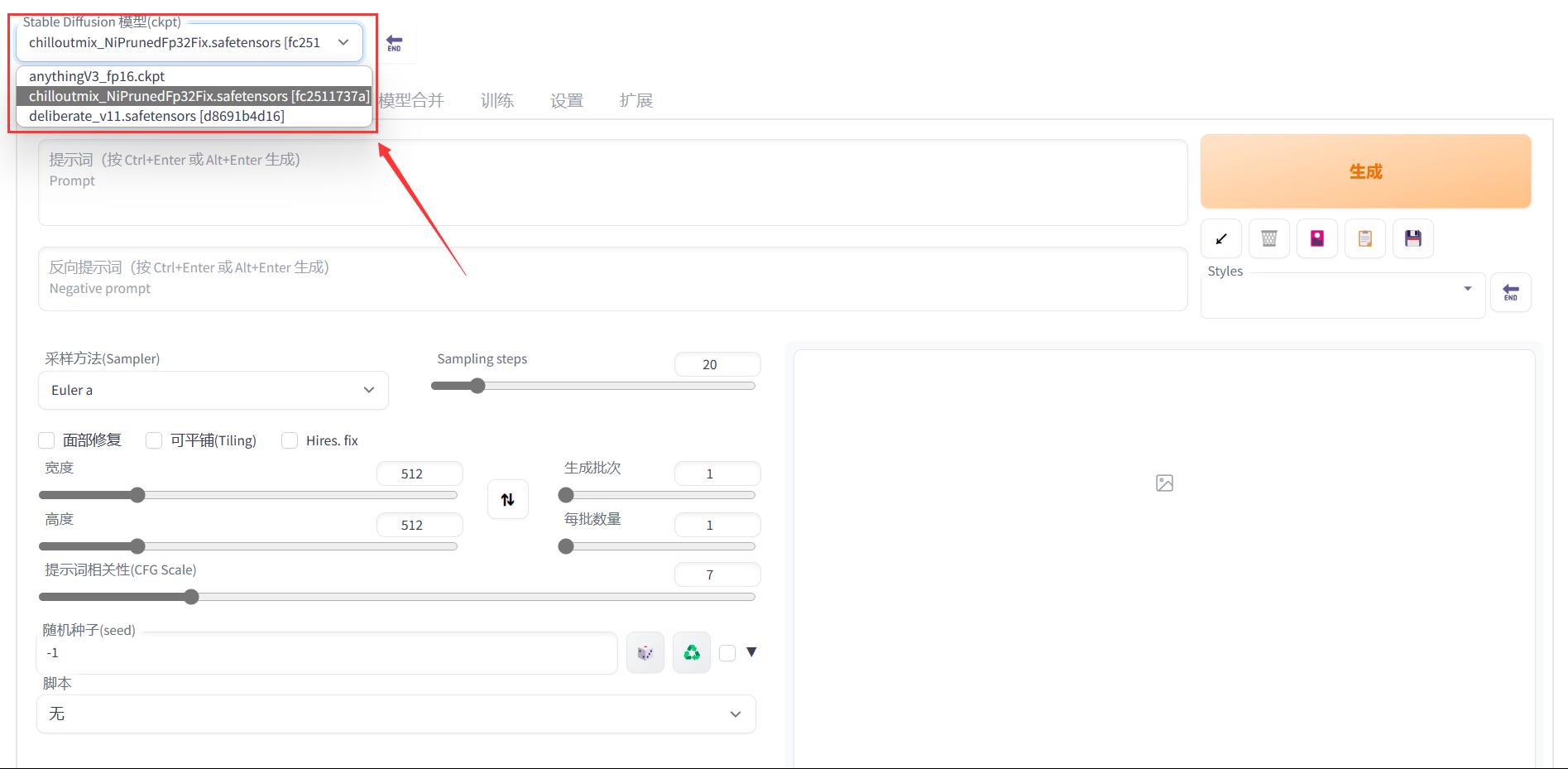
将 .safetensors 或 .ckpt 后缀的模型文件放入以下目录下,然后重启 WebUI 即可。
sd.webui/webui/models/Stable-diffusion/
多个模型之间还可以通过 WebUI 切换。
中文支持
在 WebUI 的 Extentions 中,选择 install from URL,输入以下 URL,点击 install:
https://github.com/dtlnor/stable-diffusion-webui-localization-zh_CN

安装完成之后,在 Settings 的 User interface 中,选择 Localization (requires restart),选择 zh-CN。
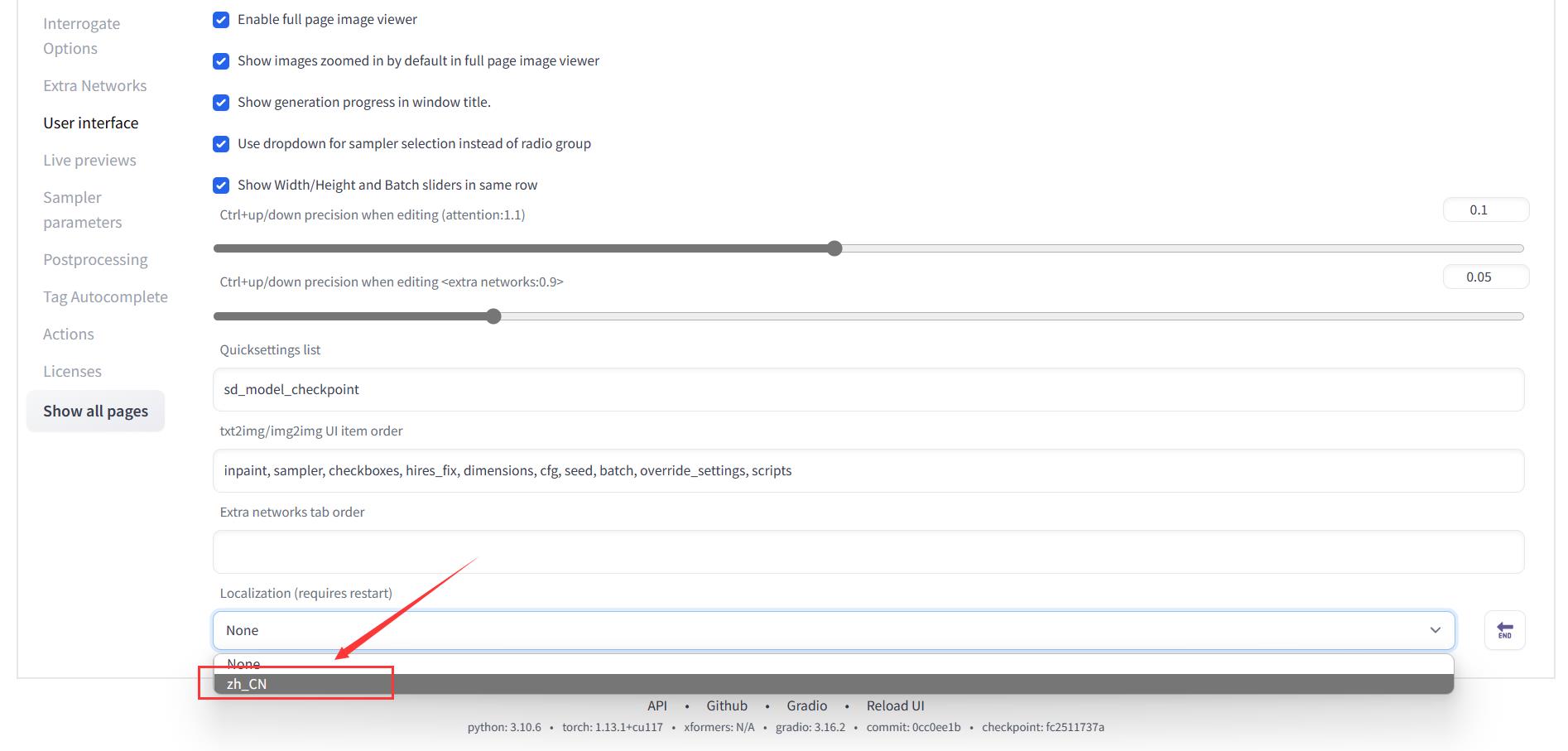
回到 Settings 最上面点击 Apply settings,然后点击 Reload UI。

UI汉化效果:

其他内容的安装
- Lora 文件可以放在
sd.webui/webui/models/Lora/下,通过 Prompt 输入 Lora 指令使用 - VAE 文件可以放在
sd.webui/webui/models/VAE/下,在设置的 Stable Diffusion 版面设置模型的 VAE - extensions 文件可以放在
sd.webui/webui/extensions/下,通过 WebUI 的 Extentions 版面启用 - textual inversion 文件可以放在
sd.webui/webui/embeddings/下,通过 Prompt 输入关键词使用
相关资源都可以在 Civitai 上找到,可以自行下载、安装、体验。
一些生成图片的展示
以下图片来自相同模型,使用同一 Prompt 进行随机生成:
图片被判定违规,图片效果请见:小嗷犬的技术小站 - AI生成图像竟如此真实了?Stable Diffusion Model本地部署教程
不同采样方法之间的比较
同一模型可以选择不同的采样方式进行采样,生成的图片也会有所不同。
以下图片都来自相同模型、相同 Prompt、相同 Seed 的生成结果,只是采样方法不同,其他参数完全一致。
图片被判定违规,对比图片效果请见:小嗷犬的技术小站 - AI生成图像竟如此真实了?Stable Diffusion Model本地部署教程
以上是关于Stable Diffusion 个人推荐的各种模型及设置参数扩展应用等合集(不断更新中)的主要内容,如果未能解决你的问题,请参考以下文章
AI绘画如何使用Google Colab安装Stable Diffusion
由浅入深理解latent diffusion/stable diffusion:一步一步搭建自己的stable diffusion models