[编译原理]词法分析器的分析与实现
Posted 童凌
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[编译原理]词法分析器的分析与实现相关的知识,希望对你有一定的参考价值。
词法分析概述:
编译程序要对高级语言编写的源程序进行分析和合成,生成目标程序。词法分析是对源程序进行的首次分析,实现词法分析的程序成为词法分析程序(或词法分析器),也称扫描器。
像用自然语言书写的文章一样,源程序是由一系列的句子组成的,句子是由单词符号按一定的规则构成的,而单词符号又是由字符按照一定的规则构成。因此,源程序实际上是由满足程序语言规范发字符按照一定的规则组合起来构成的一个字符串。
词法分析的功能是,从左到右逐个地扫描源程序的字符串,按照词法规则,识别出单词符号作为输出,对识别过程中发现的词法错误,输出有关的错误信息。
由词法分析识别出的单词流是语法分析的输入,语法分析据此判断它们是否构成了合法的句子。由词法分析识别出的常数和由用户定义的名字,分别在常数表和符号表中予以登记,在编译的各个阶段都要频繁的使用符号表。
词法分析可以作为单独的一遍,这时词法分析器的输出形成一个输出文件,作为语法分析器的输入文件,词法分析也可以作为语法分析的一个子程序,每当语法分析需要下一个新单词时,就调用词法分析子程序,从输入字符串中识别一个单词后返回。
单词符号的类别:
单词符号是程序语言最基本的语法符号,为了便于语法分析,通常将单词符号分为五类。
1、 标识符
用来命名程序中出现的变量、数组、函数、过程、标号等,通常是一个字母开头的字母数字串,如length,nextch等。
2、 基本字
也可以成为关键字或保留字。如if,while,for,do,goto等。他们具有标识符的形式,但他们不是由用户而是由语言定义的,其意义是约定的。多数语言中规定,他们不能作为标识符或者标识符的前缀,即用户不能使用它们来定义用户使用的名字,故我们称它为保留字,这些语言如Pascal和C等。但也有的语言允许将基本字作为标识符或者标识符的前缀,这类语言如Fortran等。
3、 常数
包括各种类型的常数,如整型、实型、字符型、布尔型等。如:5、3.1415926、’a’、TRUE等都是常数。
4、 运算符
算术运算符+、-、×、÷;关系运算符<,<=,>,>=,==,!=以及逻辑运算符&&,(),||或者!等。
5、 界符
如”,”、”;”等单字界符和/,/,//等双字界符,空白符等。
对于一个程序语言来说,基本字、运算符、界符的数目是确定的,通常在几十个到几百个之间。标识符,常数则由用户定义,如何指定,指定多少,程序语言未加限制,但规定了他们应满足的构词规则。
词法分析器的输出形式
识别出来的单词应该采用某种中间表示形式,以便为编译后续阶段方便地引用。通常一个单词用一个二元式来表示:
(单词类别,单词的属性)
第一元用于区分单词所属的类别,以整数编码表示。第二元用于区分该类别中的哪一个单词符号,即单词符号的值。
单词的编码随类别不同而不同。由于基本字、运算符、界符的数目是确定的,一般每个单词可以定义一个类别码,单词与它的类别码为一一对应的关系,即一字一码。这时它的第二元就没有识别意义了,显然对这类单词的识别很简单。也可以将关系运算符全部归为一类,用第二元的值来区分是哪一个关系运算符,这种分类在一定程度上可以简化以后的语法分析。常数可归为一类,也可按整型,实型,字符型,布尔型等分类,标识符类似处理。在这种情况下,每一类别中的常数或标识符将由第二元单词的属性值来区别。通常将常数在常数表中的位置编号作为常数的属性值,从而将标识符在符号表中的位置编号作为标识符的属性值。
二. 实验要求
词法分析器的设计:
状态转换图,简称转换图,是设计词法分析器的有效工具。状态转换图是有限有向图,图中的结点代表状态,结点间的有向边代表状态之间的转换关系,有向边上标记的字符表示状态转换的条件。
状态的数量是有限的,其中必有一个初始状态,若干个终止状态。大部分终止状态可对应一类单词符号的成功识别,所以也被成为识别状态。在识别状态下,可以给出相应单词的类别编码和属性值。某些终止状态是在多识别了一个字符后才成为识别状态的,对于这种情况,多识别的字符应予以退回,在终态上标以“*”作为区别。
有了状态转换图后,就可以方便地设计和实现词法分析器了。下面以一个简单的程序语言的词法分析器为例作为介绍。表中列出了该语言的所有单词符号及其编码,其中助记符是用于方便书写和记忆的。
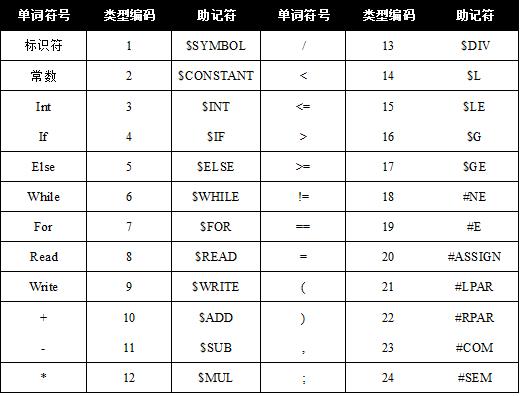
这是一个简单的实例,实际的词法分析器状态转换图也不太复杂。
状态转换图易于编程实现。图中每一个状态对应一段程序,遇到分支可使用if语句实现,如果分支较多,可采用case语句,遇到回路可采用while语句。在编写状态转换图对应程序时,将会用到下面的变量和函数。
1、 Character
全局字符变量,用来存放最新读入的字符。
2、 Token
字符数组,用来存放已读入的字符序列。
3、 Getchar
读入一个字符的函数,从输入字符串中读入一个字符到character中。
4、 Getnbc
读入非空白字符的函数,检查变量character中的字符是否为空白字符,若是,则调用getchar读入下一个字符,直到character中的字符是非空白字符为止。
5、 Concat
连接字符串的函数,把character中的字符连接到token数组的末尾。例如,token的值为”abc”,character的值为’d’,调用concat函数后,token的值为abcd。
6、 Letter
判断字母的函数,若character中的字符是字母,返回true值,否则返回false值。
7、 Digit
判断数字的函数,若character中的字符是数字,返回true值,否则返回false值。
8、 Retract
回退字符的函数,将刚读入的character中的字符回退到输入字符串中,并把character的值置为空白。
9、 Reserve
处理保留字的函数,对存放在token中的字符串查表六字表,若查到,则表示该字符串是一个保留字,则返回该保留字的类型编码,否则返回0.
10、symbol 处理标识符的函数。对token中的字符串查保留字表,若查到,则返回它在符号表中的位置编号,
11、constant
常数存入常数表的函数,将token中的数字串转换成标准的二进制值,存入常数表中,返回它在表中的位置编号。
12、return
返回二元式的函数,其中,num为单词符号的类型编码,val是token中的字符串在符号表中的位置编号,或者是它在常数表中的位置编号,或者无定义。
13、error
出错处理的函数,处理出现的词法错误。有一类词法错误可以在词法分析时发现,如出现字母表以外的非法字符、不合规则的常数、标识符的前缀为保留字等。但还有一类词法错误,例如,把if写成fi,词法分析会将fi当作标识符处理,le ngth中间多了一个空格,词法分析会将le和ngth当作两个标识符处理。这类词法错误往往要推迟到语法分析时才能发现,不属于函数处理的范畴。
/**使用时,先在源文件目录下建立一个input.txt文档,存放需要执行词法分析的程序,执行后,词法分析的结果以及常量表,变量表的结果将输出至当前目录。*/
#include <iostream>
#include <fstream>
#include <math.h>
#include <ctype.h>
#include <cstdlib>
#include <cstring>
using namespace std;
#define Max 655 //最大代码长度
#define WordMaxNum 256 //变量最大个数
#define DigitNum 256 //常量最大个数
#define MaxKeyWord 32 //关键字数量
#define MaxOptANum 8 //运算符最大个数
#define MaxOptBNum 4 //运算符最大个数
#define MaxEndNum 11 //界符最大个数
enum errorType VarExceed = 1,PointError = 2,ConExceed = 3;
typedef struct DisplayTable
int Index; //标识符所在表的下标
int type; //标识符的类型
int line; //标识符所在表的行数
char symbol[20]; //标识符所在表的名称
Table;
int TableNum = 0; //display表的下标
char Word[WordMaxNum][20]; //标识符表
char Digit[WordMaxNum][20]; //数字表
int WordNum = 0; //变量表的下标
int DigNum = 0; //常量表的下标
bool errorFlag = 0; //错误标志
const char* const KeyWord[MaxKeyWord] =
"and", "array", "begin", "case","char" "constant",
"do", "else", "end", "false","for", "if", "input",
"integer", "not", "of", "or", "output","packed",
"procedure", "program", "read", "real","repeat",
"set", "then", "to", "type", "until", "var","while",
"with","prn"
; //关键字
const char OptA[] = '+','-','*','/','=','#','<','>'; // 单目运算
const char *OptB[] = "<=",">=",":=","<>"; //双目运算符
const char End[] =
'(', ')' , ',' , ';' , '.' , '[' ,
']' , ':' , '' , '' , '"'
; // 界符
void error(char str[20],int nLine, int errorType)
cout <<" \\nError : ";
switch(errorType)
case VarExceed:
cout << "第" << nLine-1 <<"行" << str << " 变量的长度超过限制!\\n";
errorFlag = 1;
break;
case PointError:
cout << "第" << nLine-1 <<"行" << str << " 小数点错误!\\n";
errorFlag = 1;
break;
case ConExceed:
cout << "第" << nLine-1 <<"行" << str << " 常量的长度超过限制!\\n";
errorFlag = 1;
break;
//error
void Scanner(char ch[],int chLen,Table table[Max],int nLine)
int chIndex = 0;
while(chIndex < chLen) //对输入的字符扫描
/*处理空格和tab*/
while(ch[chIndex] == ' ' || ch[chIndex] == 9 ) //忽略空格和tab
chIndex ++;
/*处理换行符*/
while(ch[chIndex] == 10) //遇到换行符,行数加1
nLine++;chIndex ++;
/*标识符*/
if( isalpha(ch[chIndex])) //以字母、下划线开头
char str[256];
int strLen = 0;
while(isalpha(ch[chIndex]) || ch[chIndex] == '_' ) //是字母、下划线
str[strLen ++] = ch[chIndex];
chIndex ++;
while(isdigit(ch[chIndex]))//不是第一位,可以为数字
str[strLen ++] = ch[chIndex];
chIndex ++;
str[strLen] = 0; //字符串结束符
if(strlen(str) > 20) //标识符超过规定长度,报错处理
error(str,nLine,1);
else int i;
for(i = 0;i < MaxKeyWord; i++) //与关键字匹配
if(strcmp(str, KeyWord[i]) == 0) //是关键字,写入table表中
strcpy(table[TableNum].symbol,str);
table[TableNum].type = 1; //关键字
table[TableNum].line = nLine;
table[TableNum].Index = i;
TableNum ++;
break;
if(i >= MaxKeyWord) //不是关键字
table[TableNum].Index = WordNum;
strcpy(Word[WordNum++],str);
table[TableNum].type = 2; //变量标识符
strcpy(table[TableNum].symbol,str);
table[TableNum].line = nLine;
TableNum ++;
/*常数*/
//else if(isdigit(ch[chIndex])&&ch[chIndex]!='0') //遇到数字
else if(isdigit(ch[chIndex])) //遇到数字
int flag = 0;
char str[256];
int strLen = 0;
while(isdigit(ch[chIndex]) || ch[chIndex] == '.') //数字和小数点
if(ch[chIndex] == '.') //flag表记小数点的个数,0时为整数,1时为小数,2时出错
flag ++;
str[strLen ++] = ch[chIndex];
chIndex ++;
str[strLen] = 0;
if(strlen(str) > 20) //常量标识符超过规定长度20,报错处理
error(str,nLine,3);
if(flag == 0)
table[TableNum].type = 3; //整数
if(flag == 1)
table[TableNum].type = 4; //小数
if(flag > 1)
error(str,nLine,2);
table[TableNum].Index = DigNum;
strcpy(Digit[DigNum ++],str);
strcpy(table[TableNum].symbol,str);
table[TableNum].line = nLine;
TableNum ++;
/*运算符*/
else
int errorFlag; //用来区分是不是无法识别的标识符,0为运算符,1为界符
char str[3];
str[0] = ch[chIndex];
str[1] = ch[chIndex + 1];
str[3] = 0;
int i ;
for(i = 0;i < MaxOptBNum;i++)//MaxOptBNum)
if(strcmp(str,OptB[i]) == 0)
errorFlag = 0;
table[TableNum].type = 6;
strcpy(table[TableNum].symbol,str);
table[TableNum].line = nLine;
table[TableNum].Index = i;
TableNum ++;
chIndex = chIndex + 2;
break;
if(i >= MaxOptBNum)
for( int k = 0;k < MaxOptANum; k++)
if(OptA[k] == ch[chIndex])
errorFlag = 0;
table[TableNum].type = 5;
table[TableNum].symbol[0] = ch[chIndex];
table[TableNum].symbol[1] = 0;
table[TableNum].line = nLine;
table[TableNum].Index = k;
TableNum ++;
chIndex ++;
break;
/*界符*/
for(int j = 0;j < MaxEndNum;j ++)
if(End[j] ==ch[chIndex])
errorFlag = 1;
table[TableNum].line = nLine;
table[TableNum].symbol[0] = ch[chIndex];
table[TableNum].symbol[1] = 0;
table[TableNum].Index = j;
table[TableNum].type = 7;
TableNum ++;
chIndex ++;
/*其他无法识别字符*/
if(errorFlag != 0 && errorFlag != 1) //开头的不是字母、数字、运算符、界符
char str[256];
int strLen = -1;
str[strLen ++] = ch[chIndex];
chIndex ++;
while(*ch != ' ' || *ch != 9 || ch[chIndex] != 10)//
str[strLen ++] = ch[chIndex];
chIndex ++;
str[strLen] = 0;
table[TableNum].type = 8;
strcpy(table[TableNum].symbol,str);
table[TableNum].line = nLine;
table[TableNum].Index = -2;
TableNum ++;
void Trans(double x,int p) //把十进制小数转为16进制
int i=0; //控制保留的有效位数
while(i<p)
if(x==0) //如果小数部分是0
break; //则退出循环
else
int k=int(x*16); //取整数部分
x=x*16-int(k); //得到小数部分
if(k<=9)
cout<<k;
else
cout<<char(k+55);
;
i++;
;
;
int main()
ifstream in;
ofstream out,outVar,outCon;
char in_file_name[26],out_file_name[26]; //读入文件和写入文件的名称
char ch[Max]; //存放输入代码的缓冲区
int nLine = 1; //初始化行数
Table *table = new Table[Max];
int choice;
cout << "请输入读入方式:1:从文件中读,2:从键盘读(输入结束标志位#):\\n";
cin >> choice;
switch(choice)
int i;
/*从文件读取*/
case 1:
cout<<"Enter the input file name:\\n";
cin>>in_file_name;
in.open(in_file_name);
if(in.fail()) //打开display表读文件失败
cout<<"Inputput file opening failed.\\n";
exit(1);
cout<<"Enter the output file name:\\n";
cin>>out_file_name;
out.open(out_file_name);
outVar.open("变量表.txt");
outCon.open("常量表.txt");
if(out.fail()) //打开display表写文件失败
cout<<"Output file opening failed.\\n";
exit(1);
if(outVar.fail()) //打开变量表写文件失败
cout<<"VarOutput file opening failed.\\n";
exit(1);
if(outCon.fail()) //打开常量表写文件失败
cout<<"ConstOutput file opening failed.\\n";
exit(1);
in.getline(ch,Max,'#');
Scanner(ch, strlen(ch),table,nLine); //调用扫描函数
if(errorFlag == 1) //出错处理
return 0;
/*把结果打印到各个txt文档中*/ out <<"类型"<<" "<<"下标" <<endl;
for( i = 0; i < TableNum;i ++)//打印display
out<< "(" <<hex << table[i].type<< " , "<< "" << hex << table[i].Index<< ")" <<endl; //在文件testout.txt中输出
outCon << "下标" << " " << "常量值" << endl;
for(i = 0;i < TableNum;i++) //打印常量表
if(table[i].type == 3)
long num1;
num1 = atoi(table[i].symbol);
outCon<< "(" <<hex << table[i].Index << " , "<< "" << hex << num1 << ")" <<endl;
if(table[i].type == 4)
double num2;
num2 = atof(table[i].symbol);
outCon<< "(" <<hex << table[i].Index << " , "<< "" << hex << num2<< ")" <<endl;
outVar <<"类型"<<" "<< "变量名称" <<endl;
for( i = 0; i < WordNum;i ++)//打印变量表
outVar<< "(" <<hex << i<< " " << Word[i] << ")" <<endl; //在文件testout.txt中输出
in.close();//关闭文件
out.close();
outVar.close();
outCon.close();
break;
/*从键盘输入的方式,输出到屏幕*/
case 2:
cin.getline(ch,Max,'#');
Scanner(ch, strlen(ch),table,nLine); //调用扫描函数
if(errorFlag == 1)
return 0;
cout << "\\nDisplay表: \\n";
cout <<"类型"<<" "<<"下标" <<endl; //dos界面下
for( i = 0; i < TableNum;i ++)
cout<< "(" <<hex << table[i].type<< " , "<< "" << hex << table[i].Index<< ")" <<endl;
cout << "\\n常量表:\\n" << "下标" << " " << "常量值" << endl;
for(i = 0;i < TableNum;i++) //打印常量表
if(table[i].type == 3)
long num1;
num1 = atoi(table[i].symbol);
cout<< "(" <<hex << table[i].Index << " , "<< "" << hex << num1 << ")" <<endl;
if(table[i].type == 4)
char *num2;
float num,num3;
num = atof(table[i].symbol);
num2 = gcvt(16,strlen(table[i].symbol),table[i].symbol);
num3 = num - floor(num);
cout << "(" << hex << table[i].Index << " , " << num2;
Trans(num3,5) ;
cout << ")" <<endl;
cout <<"\\n变量表:\\n类型"<<" "<< "变量名称" <<endl;
for( i = 0; i < WordNum;i ++)//打印变量表
cout<< "(" <<hex << i<< " " << Word[i] << ")" <<endl; //在文件testout.txt中输出
break;
return 0;
以上是关于[编译原理]词法分析器的分析与实现的主要内容,如果未能解决你的问题,请参考以下文章