带你整理面试过程中关于Redis的缓存雪崩,击穿,穿透及缓存和数据库双写一致性问题
Posted 南淮北安
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了带你整理面试过程中关于Redis的缓存雪崩,击穿,穿透及缓存和数据库双写一致性问题相关的知识,希望对你有一定的参考价值。
文章目录
一、缓存雪崩
1. 什么是缓存雪崩
回顾一下我们为什么要用缓存(Redis):
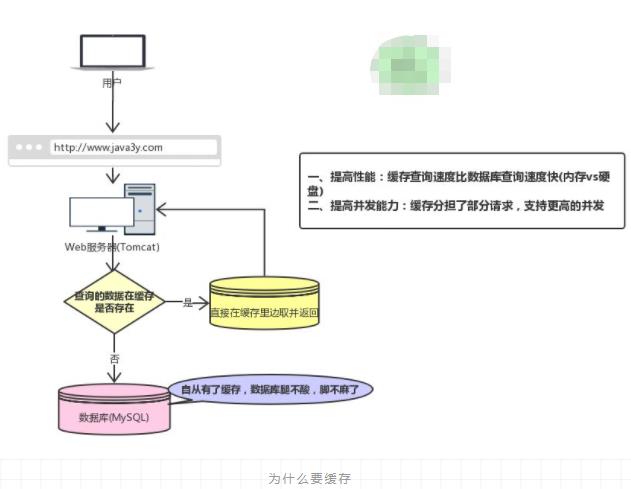
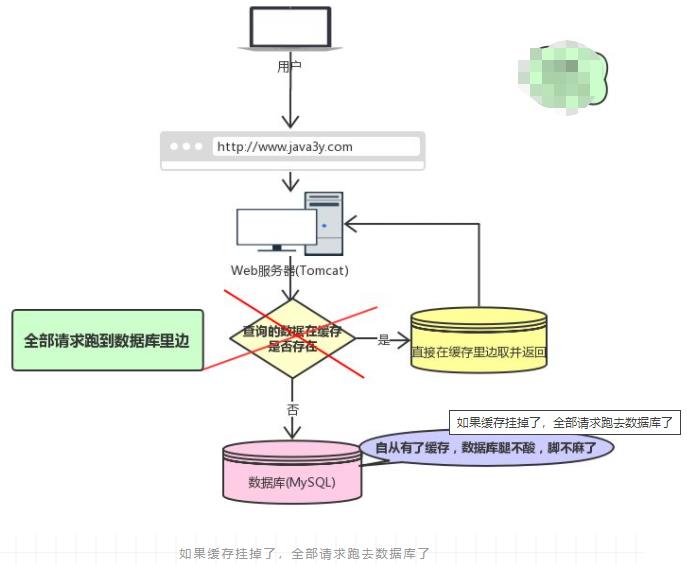
现在有个问题,如果我们的缓存挂掉了,这意味着我们的全部请求都跑去数据库了。
在前面学习我们都知道Redis不可能把所有的数据都缓存起来(内存昂贵且有限),所以Redis需要对数据设置过期时间,并采用的是惰性删除+定期删除两种策略对过期键删除。
如果缓存数据设置的过期时间是相同的,并且Redis恰好将这部分数据全部删光了。这就会导致在这段时间内,这些缓存同时失效,全部请求到数据库中。
这就是缓存雪崩:
(1)Redis 挂掉了,请求全部走数据库。
(2)对缓存数据设置相同的过期时间,导致某段时间内缓存失效,请求全部走数据库。
缓存雪崩如果发生了,很可能就把我们的数据库搞垮,导致整个服务瘫痪!
2. 如何解决缓存雪崩?
对于“对缓存数据设置相同的过期时间,导致某段时间内缓存失效,请求全部走数据库。”这种情况,非常好解决:
解决方法:在缓存的时候给过期时间加上一个随机值,这样就会大幅度的减少缓存在同一时间过期。
setRedis(Key,value,time + Math.random() * 10000);
对于“Redis挂掉了,请求全部走数据库”这种情况,我们可以有以下的思路:
事发前:实现Redis的高可用(主从架构+Sentinel 或者Redis Cluster 集群),尽量避免Redis挂掉这种情况发生。
事发中:万一Redis真的挂了,我们可以设置本地缓存(ehcache)+限流(hystrix),尽量避免我们的数据库被干掉(起码能保证我们的服务还是能正常工作的)
事发后:redis持久化,重启后自动从磁盘上加载数据,快速恢复缓存数据。
二、缓存击穿
什么是缓存穿透:
缓存在某个时间点过期的时候,恰好在这个时间点对这个 Key 有大量的并发请求过来,导致此时数据库的压力激增,有可能就崩了
所以缓存击穿类似缓存雪崩,只不过雪崩是很多的key同时过期,而缓存穿透是某一个key过期
解决方案:
(1)互斥锁:在缓存失效后,通过互斥锁或者队列来控制读数据写缓存的线程数量,利用互斥锁,缓存失效的时候,先去获得锁,得到锁了,再去请求数据库。没得到锁,则休眠一段时间重试。这种方式会阻塞其他的线程,此时系统的吞吐量会下降
(2)热点数据缓存永远不过期。
物理不过期:针对热点key不设置过期时间
逻辑过期,把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建(因为如果不过期就变成静态的了)
三、缓存穿透
1. 什么是缓存穿透
比如,我们有一张数据库表,ID都是从1开始的(正数):

但是可能有黑客想把我的数据库搞垮,每次请求的ID都是负数。这会导致我的缓存就没用了,请求全部都找数据库去了,但数据库也没有这个值啊,所以每次都返回空出去。
缓存穿透是指查询一个一定不存在的数据。由于缓存不命中,并且出于容错考虑,如果从数据库查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,失去了缓存的意义。
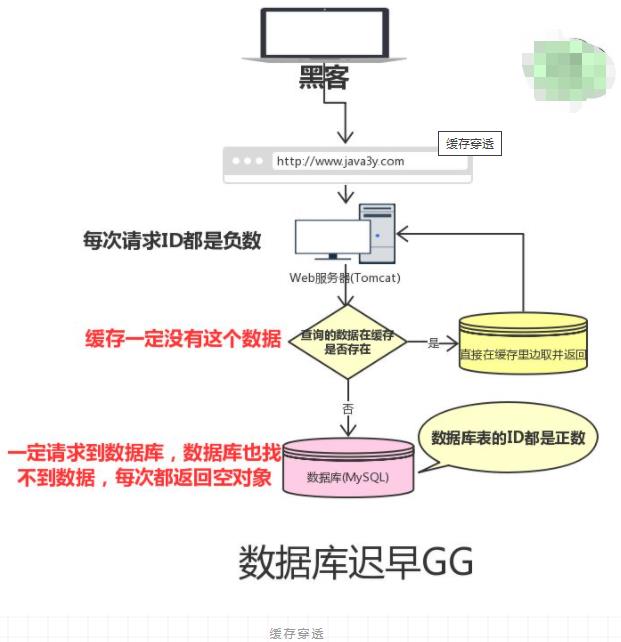
这就是缓存穿透:请求的数据在缓存大量不命中,导致请求走数据库。
缓存穿透如果发生了,也可能把我们的数据库搞垮,导致整个服务瘫痪!
2. 如何解决缓存穿透?
(1)提供一个能迅速判断请求是否有效的拦截机制,比如,利用布隆过滤器,内部维护一系列合法有效的 Key。迅速判断出,请求所携带的 Key 是否合法有效。如果不合法,则直接返回。
布隆过滤器(Bloom Filter)详解:布隆过滤器可以用于检索一个元素是否在一个集合中
(2)当我们从数据库找不到的时候,我们也将这个空对象设置到缓存里边去。下次再请求的时候,就可以从缓存里边获取了。
这种情况我们一般会将空对象设置一个较短的过期时间。
(3)采用异步更新策略,无论 Key 是否取到值,都直接返回。Value 值中维护一个缓存失效时间,缓存如果过期,异步起一个线程去读数据库,更新缓存。需要做缓存预热(项目启动前,先加载缓存)操作。
四、缓存与数据库双写一致
1. 读操作,流程
上面讲缓存穿透的时候也提到了:如果从数据库查不到数据则不写入缓存。
一般我们对读操作的时候有这么一个固定的套路:
- 如果我们的数据在缓存里边有,那么就直接取缓存的。
- 如果缓存里没有我们想要的数据,我们会先去查询数据库,然后将数据库查出来的数据写到缓存中。
- 最后将数据返回给请求
2. 什么是缓存与数据库双写一致问题?
如果仅仅查询的话,缓存的数据和数据库的数据是没问题的。但是,当我们要更新时候呢?各种情况很可能就造成数据库和缓存的数据不一致了。
这里不一致指的是:数据库的数据跟缓存的数据不一致
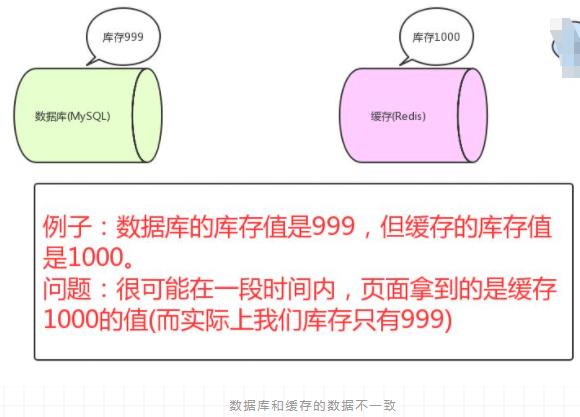
总的来说就是同时更新数据库和缓存的原子性无法得到满足,不论是先更新数据库还是redis缓存都有可能失败,并且在高并发下还随时伴有顺序未知的读取操作。
从理论上说,只要我们设置了键的过期时间,我们就能保证缓存和数据库的数据最终是一致的。因为只要缓存数据过期了,就会被删除。随后读的时候,因为缓存里没有,就可以查数据库的数据,然后将数据库查出来的数据写入到缓存中。
除了设置过期时间,我们还需要做更多的措施来尽量避免数据库与缓存处于不一致的情况发生。
3. 对于更新操作
一般来说,执行更新操作时,我们会有两种选择:
(1)先操作数据库,再操作缓存
(2)先操作缓存,再操作数据库
首先,要明确的是,无论我们选择哪个,我们都希望这两个操作要么同时成功,要么同时失败。所以,这会演变成一个 分布式事务 的问题。
所以,如果原子性被破坏了,可能会有以下的情况:
操作数据库成功了,操作缓存失败了。
操作缓存成功了,操作数据库失败了。
如果第一步已经失败了,我们直接返回Exception出去就好了,第二步根本不会执行。
(1)操作缓存
操作缓存也有两种方案:更新缓存;删除缓存
一般我们都是采取删除缓存缓存策略的,原因如下:
a. 高并发环境下,无论是先操作数据库还是后操作数据库而言,如果加上更新缓存,那就更加容易导致数据库与缓存数据不一致问题。(删除缓存直接和简单很多)
b. 如果每次更新了数据库,都要更新缓存【这里指的是频繁更新的场景,这会耗费一定的性能】,倒不如直接删除掉。等再次读取时,缓存里没有,那我到数据库找,在数据库找到再写到缓存里边(体现懒加载)
(2)先更新数据库,再删除缓存
正常的情况是这样的:先操作数据库,成功;再删除缓存,也成功;
如果原子性被破坏了:
第一步成功(操作数据库),第二步失败(删除缓存),会导致数据库里是新数据,而缓存里是旧数据。
如果第一步(操作数据库)就失败了,我们可以直接返回错误(Exception),不会出现数据不一致。

对于这种策略,其实是一种设计模式:Cache Aside Pattern:
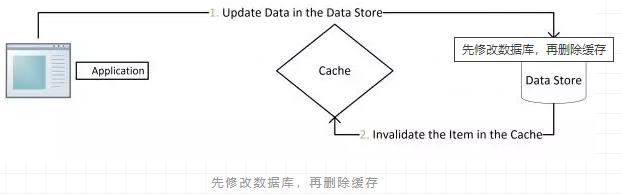
删除缓存失败的解决思路:
将需要删除的key发送到消息队列中;自己消费消息,获得需要删除的key;不断重试删除操作,直到成功
(3)先删除缓存,再更新数据库
正常情况是这样的:先删除缓存,成功;再更新数据库,也成功
如果原子性被破坏了:
第一步成功(删除缓存),第二步失败(更新数据库),数据库和缓存的数据还是一致的。
如果第一步(删除缓存)就失败了,我们可以直接返回错误(Exception),数据库和缓存的数据还是一致的。

并发下解决数据库与缓存不一致的思路:
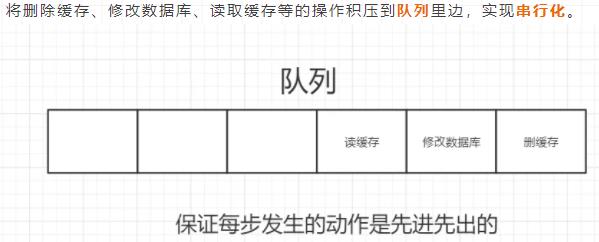
(4)对比两种策略
先更新数据库,再删除缓存(Cache Aside Pattern设计模式)
在高并发下表现优异(数据库和缓存数据不一致性概率特别低),在原子性被破坏时表现不如意
先删除缓存,再更新数据库
在高并发下表现不如意,在原子性被破坏时表现优异
【参考】
以上是关于带你整理面试过程中关于Redis的缓存雪崩,击穿,穿透及缓存和数据库双写一致性问题的主要内容,如果未能解决你的问题,请参考以下文章
阿里面试Redis最常问的三个问题:缓存雪崩击穿穿透(带答案)