73介绍下 HashMap 的底层数据结构
Posted Hoshea_sun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了73介绍下 HashMap 的底层数据结构相关的知识,希望对你有一定的参考价值。
73、介绍下 HashMap 的底层数据结构
我们现在用的都是 JDK 1.8,底层是由“数组+链表+红黑树”组成,如下图,而在 JDK 1.8 之前是由“数组+链表”组成。
1.Hash
Hash叫做”散列表“,就是把任意长度的输入,通过散列算法,变成固定长度输出,该输出结果是散列值。
其实这种转换是一种压缩映射,散列表的空间通常小于输入的空间,不同的输入可能会散列成相同的输出,所以不能从散列表来唯一的确定输入值。这就出现了Hash冲突。
74、为什么要改成“数组+链表+红黑树”?
主要是为了提升在 hash 冲突严重时(链表过长)的查找性能,使用链表的查找性能是 O(n),而使用红黑树是 O(logn)。
75、那在什么时候用链表?什么时候用红黑树?
对于插入,默认情况下是使用链表节点。当同一个索引位置的节点在新增后超过8个(阈值8):如果此时数组长度大于等于 64,则会触发链表节点转红黑树节点(treeifyBin);而如果数组长度小于64,则不会触发链表转红黑树,而是会进行扩容,因为此时的数据量还比较小。
对于移除,当同一个索引位置的节点在移除后达到 6 个,并且该索引位置的节点为红黑树节点,会触发红黑树节点转链表节点(untreeify)。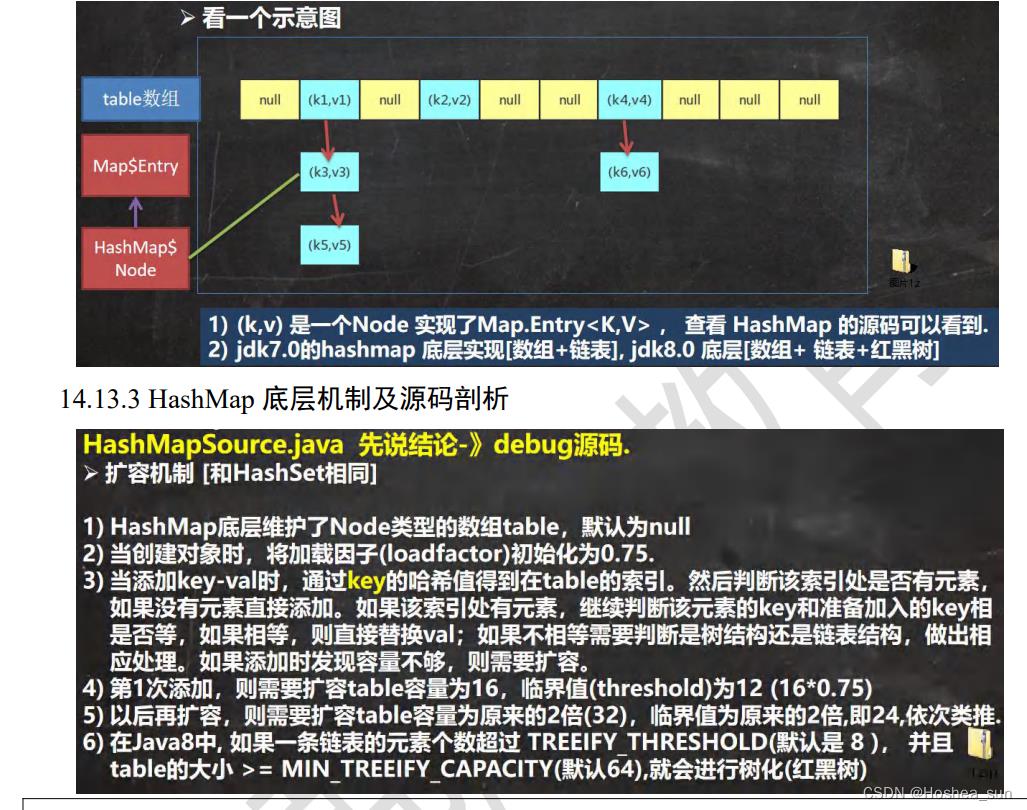
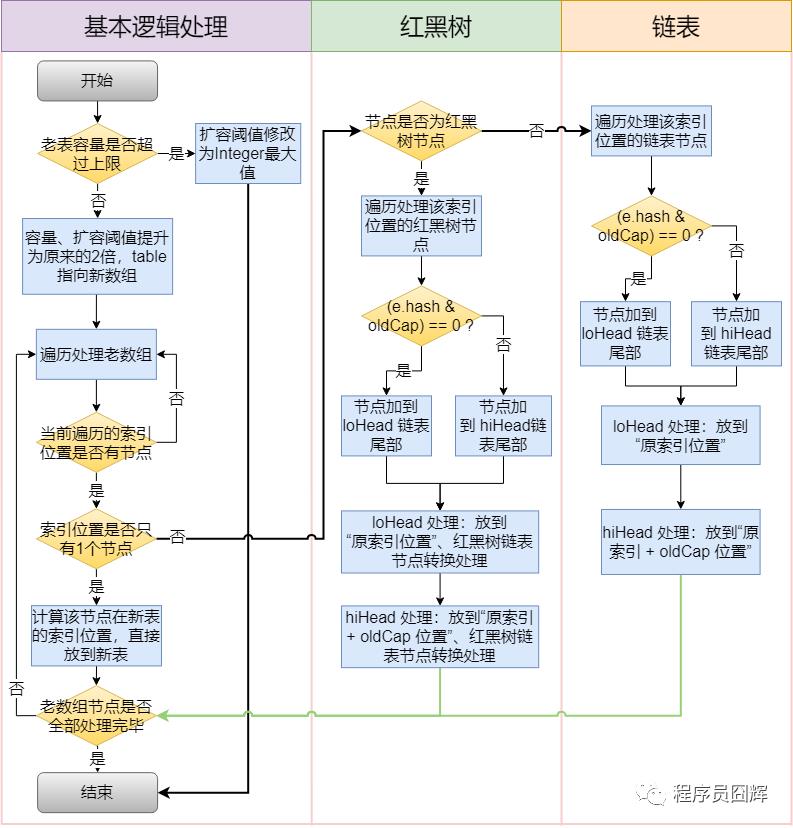
78、HashMap 的扩容(resize)流程是怎么样的?
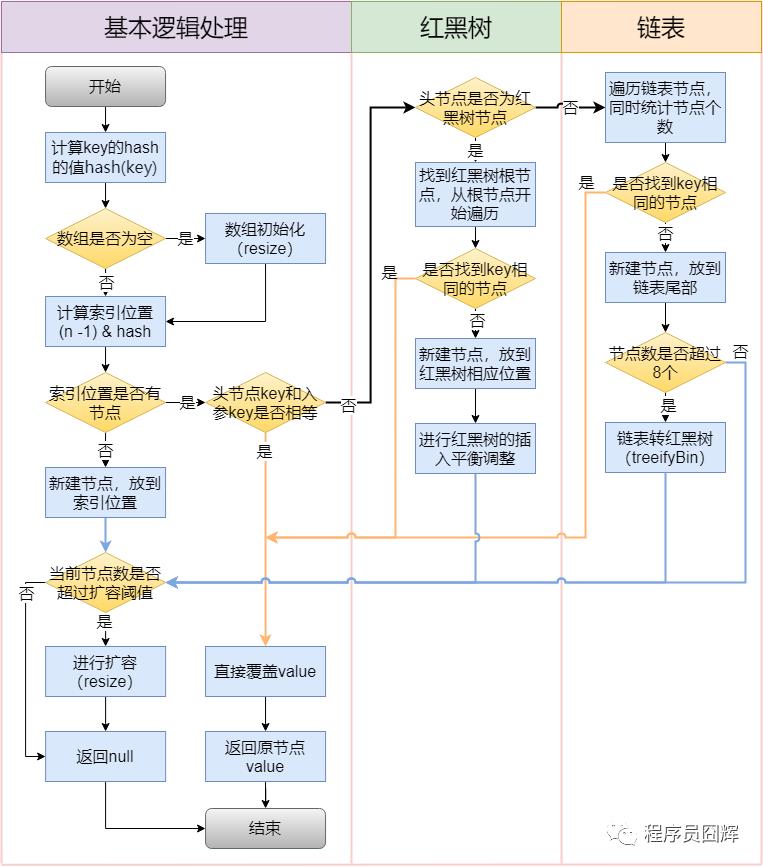
77、HashMap 的插入流程是怎么样的?
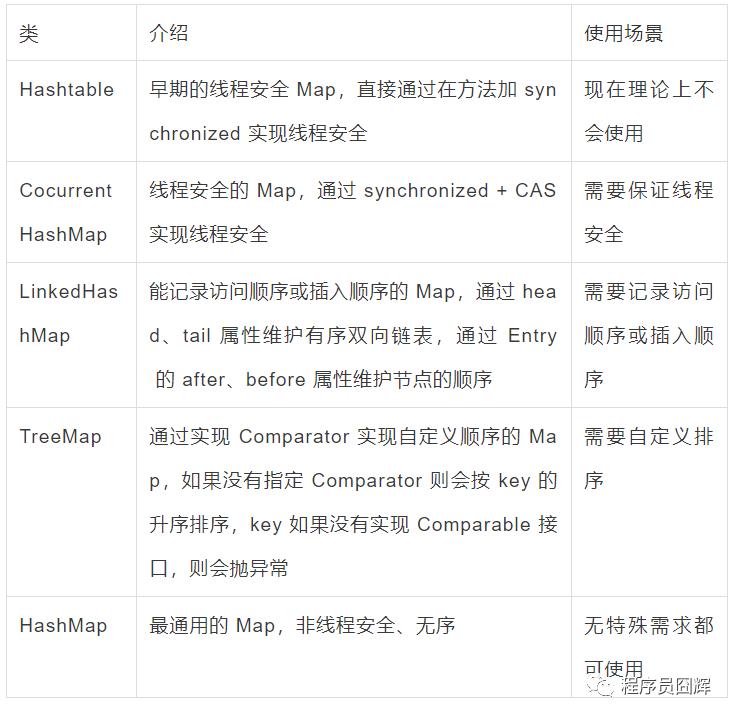
79、除了 HashMap,还用过哪些 Map,在使用时怎么选择?
90、Java 内存结构(运行时数据区)
程序计数器:线程私有。一块较小的内存空间,可以看作当前线程所执行的字节码的行号指示器。如果线程正在执行的是一个Java方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址;如果正在执行的是Native方法,这个计数器值则为空。
Java虚拟机栈:线程私有。它的生命周期与线程相同。虚拟机栈描述的是Java方法执行的内存模型:每个方法在执行的同时都会创建一个栈帧用于存储局部变量表、操作数栈、动态链接、方法出口等信息。每一个方法从调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中入栈到出栈的过程。
本地方法栈:线程私有。本地方法栈与虚拟机栈所发挥的作用是非常相似的,它们之间的区别不过是虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而本地方法栈则为虚拟机使用到的Native方法服务。
Java堆:线程共享。对大多数应用来说,Java堆是Java虚拟机所管理的内存中最大的一块。Java堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配内存。
方法区:与Java堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息(构造方法、接口定义)、常量、静态变量、即时编译器编译后的代码(字节码)等数据。方法区是JVM规范中定义的一个概念,具体放在哪里,不同的实现可以放在不同的地方。
运行时常量池:运行时常量池是方法区的一部分。Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池,用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后进入方法区的运行时常量池中存放。
String str = new String("hello");
上面的语句中变量 str 放在栈上,用 new 创建出来的字符串对象放在堆上,而"hello"这个字面量是放在堆中。
93、类加载的过程
类加载的过程包括:加载、验证、准备、解析、初始化,其中验证、准备、解析统称为连接。
加载:通过一个类的全限定名来获取定义此类的二进制字节流,在内存中生成一个代表这个类的java.lang.Class对象。
验证:确保Class文件的字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身的安全。
准备:为静态变量分配内存并设置静态变量初始值,这里所说的初始值“通常情况”下是数据类型的零值。
解析:将常量池内的符号引用替换为直接引用。
初始化:到了初始化阶段,才真正开始执行类中定义的 Java 初始化程序代码。主要是静态变量赋值动作和静态语句块(static)中的语句。
String,StringBuffer,StringBuilder区别

问题提出
StringBuffer的源代码中将其定义为final类型,为什么StringBuffer的值仍可改变?
public final class StringBuffer
extends AbstractStringBuilder
implements java.io.Serializable, Comparable<StringBuffer>, CharSequence
问题解决
**
final修饰的成员变量为基本数据类型时,赋值后无法改变。
当final修饰的为引用变量时,在赋值后其指向地址无法改变,但对象内容可以改变。**

在使用 StringBuffer 类时,每次都会对 StringBuffer 对象本身进行操作,而不是生成新的对象,所以如果需要对字符串进行修改推荐使用 StringBuffer。
StringBuilder 类在 Java 5 中被提出,它和 StringBuffer 之间的最大不同在于 StringBuilder 的方法不是线程安全的(不能同步访问)。
由于 StringBuilder 相较于 StringBuffer 有速度优势,所以多数情况下建议使用 StringBuilder 类。
HashMap集合底层的数据结构以及HashMap集合的存储键值对数据的过程
HashMap集合底层的数据结构以及HashMap集合的存储键值对数据的过程
HashMap底层数据结构
HashMap底层数据结构是哈希表。
在JDK1.8之前HashMap由数组+链表数据结构组成的。
在JDK1.8及之后HashMap由数组+链表+红黑树数据结构组成的。
HashMap<String,Integer> hm=new HashMap<>();
当创建HashMap集合对象的时候,在jdk8前,构造方法中创建一个长度是16的Entry[] table,用来存储键值对数据
在jdk8以后不是在HashMap的构造方法底层创建数组了,是在第一次调用put方法时创建的数据,Node[] table如下图:
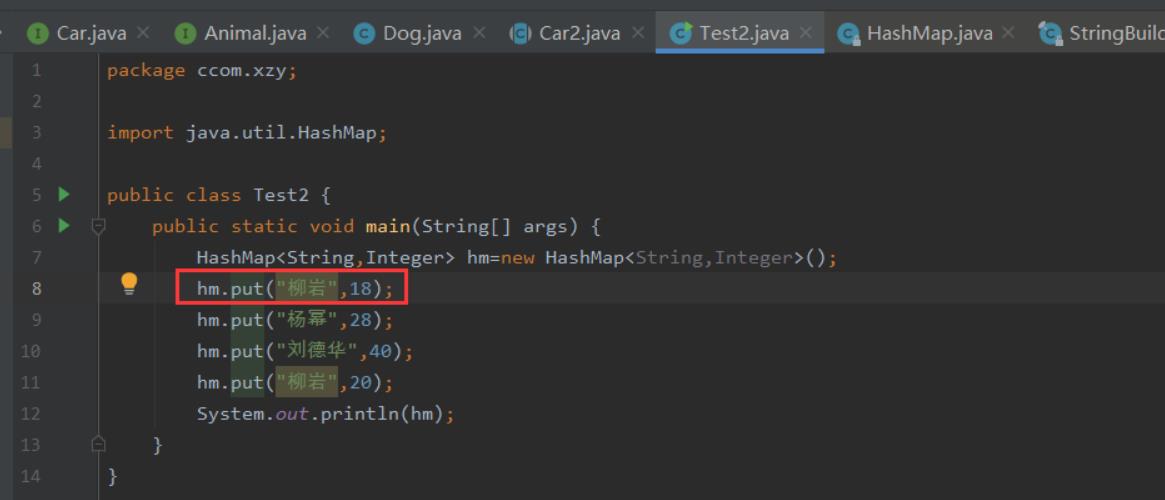
点击put方法的底层可以发现有一个Node[]数组,如下图:
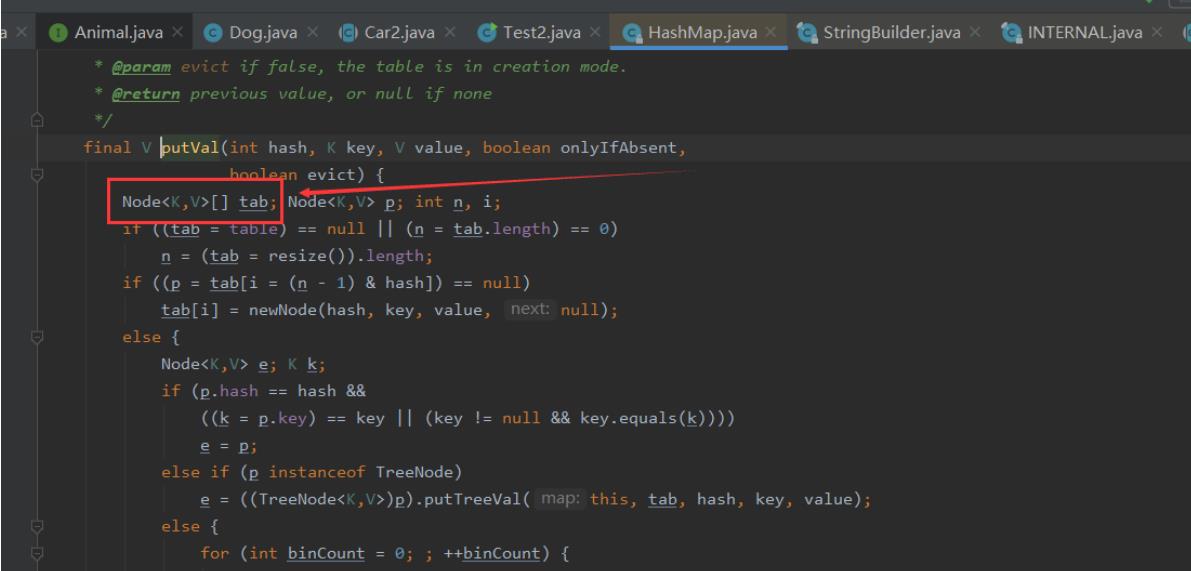
HashMap集合中是怎样存储数据的?
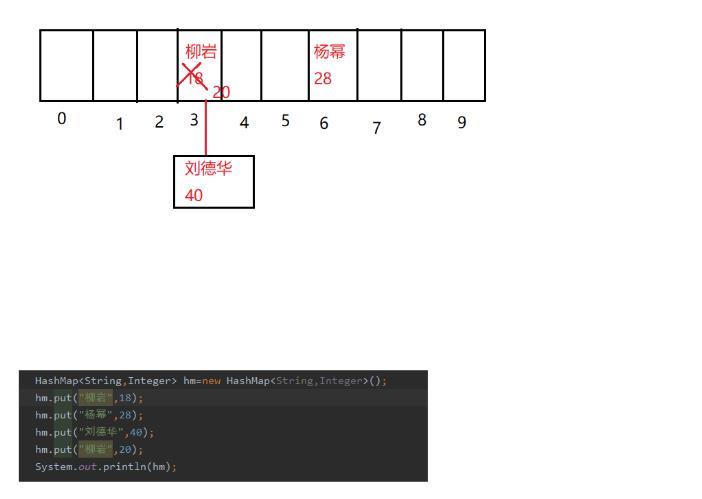
HashMap集合中是怎样存储数据的呢?如下图:
存储数据过程的介绍:
1.HashMap<String,Integer> hm=new HashMap<String,Integer>();
当创建HashMap集合对象的时候,在jdk8前,在构造方法中创建一个长度是16的Entry[] table数组用来存储数据。在jdk8及以后,就不是在HashMap的构造方法底层创建数组了,是在第一次调用put方法的时候创建数组,这个时候创建的是Node[] table数组用来存储键值对数据。
2.当向HashMap中存储键值对柳岩-18的时候,会先根据key代表的对象的hashCode()方法计算出hashCode值,然后结合Node[]数组的长度,根据某种算法计算出哈希值,其实也就是计算出数据在Node数组中存储的索引地址。如果此时计算出的索引地址在Node[]数组中没有存储数据,那么就把柳岩-18直接存储到数组中。举例:假设把柳岩-18存储到hashMap集合中的时候,计算出的索引地址是3.
3.向HashMap中存储键值对杨幂-28,假设此时计算出的索引值是6,发现Node[]数组索引是6的空间处没有存储数据,那么就把键值对杨幂-28直接存储在Node[]数组索引是6的地方。
4.接着向HashMap中存储键值对刘德华-40,这个时候假设key代表的对象刘德华的hashCode()计算出的值结合Node[]数组的长度计算出的索引值也是3,那么这个时候会让"刘德华"的hashCode值和"柳岩"的hashCode值比较,这里它们两个的hashCode值是不一致的,所以会在Node[]数组中索引值为3的空间处划出一个节点,用来存储刘德华-40,这种方法叫做拉链法。
5.最后向HashMap中存储柳岩-20,调用"柳岩"对象的hashCode方法结合Node[]数组长度计算出的索引值也是3,这个时候会让"柳岩"对象的hashCode值和Node[]数组中索引为3的所有的元素的hashCode值进行比较,如果都不相等,那么会在Node[]数组索引为3的空间处划出一个新的节点,用来存储柳岩-20;但是这里柳岩-20键值对中的"柳岩"的hashCode和柳岩-18中的"柳岩"的hashCode值是相同的,这个时候就会发生hash碰撞,然后会调用key代表的对象的equals方法比较这两个对象的内容是否相同,如果内容相同的话则会用新的value代替旧的value,如果内容不相同,那么柳岩-20会继续和索引值为3的其它元素比较hashCode值是否相同,如果都不相同则划出一个节点用来存储柳岩-20,如果相同则会根据equals方法比较二者内容是否相同,一直重复…
6.如果节点长度即链表长度大于阈值8并且数组长度大于64,则将链表变为红黑树。
以上是关于73介绍下 HashMap 的底层数据结构的主要内容,如果未能解决你的问题,请参考以下文章