如何在ubuntu中将hadoop的hdfs进行格式化?我用hdfs namenode -format命令提示没有hdfs该命令。
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何在ubuntu中将hadoop的hdfs进行格式化?我用hdfs namenode -format命令提示没有hdfs该命令。相关的知识,希望对你有一定的参考价值。
参考技术A 命令启动hadoop集群,死活不见namenode节点。在解决这个问题的时候,又不断的引出了很多新的问题。 虽然这些问题在以前学习hadoop时都解决过。但,正因为以前解决过,现在遇到这些问题就更不想重复解决了。想要以最快的速度启动集群。最后想了一个馊主意。直接格式化namenode吧。 进入正题: hadoop中重新格式化namenode 因为之前正常启动过hadoop集群。所以在hadoop的对应data目录中,已经有很多相关文件夹了。我们在格式化之前得先删除相关文件夹才行。 一、对于master主节点进行操作 一、删除data、name、namesecondary三个文件夹。 二、删除mrlocal目录中的四个文件夹 三、删除logs文件夹中的所有文件 二、对于node节点进行操作 一、删除hdfs/data中的所有文件 二、删除mrlocal中的所有文件 三、删除logs中所有文件 基本删除完成后。开始重新格式化namenode 三、格式化namenode [hadoop@master hadoop]$ bin/hadoop namenode -forma 格式化成功后。重新启动集群 四、重新启动集群 [hadoop@master hadoop]$ bin/start-all.sh 五、查看集群启动情况 [hadoop@master hadoop]$ jps 三吧5一 Jps 三漆四四 TaskTracker 三陆二二 JobTracker 三二漆9 NameNode 三5三三 SecondaryNameNode 三三95 DataNode 如看到 [hadoop@master hadoop]$ jps 三吧5一 Jps 三漆四四 TaskTracker 三陆二二 JobTracker 三二漆9 NameNode 三5三三 SecondaryNameNode 三三95 DataNode 则代表启动成功hadoop学习记录--hdfs文件上传过程源码解析
本节并不大算为大家讲接什么是hadoop,或者hadoop的基础知识因为这些知识在网上有很多详细的介绍,在这里想说的是关于hdfs的相关内容。或许大家都知道hdfs是hadoop底层存储模块,专门用于存放数据,那么在进行文件上传的时候hdfs是如何进行的呢?我们按照宏观和微观来进行相关解析工作。
首先需要向大家解释如下几个概念:
(1) secondaryNamenode: 其实起初我对SN的理解也和大部分人相同,认为SN是NN(nameNode)的一个实时热备份实现HA,并且在一次笔试的过程中还写错了,尴尬,后台经过查看相关的书籍发现其实并不是这么一回事,SN主要是完成的Edits和fsImage的合并工作,以减少NN的工作压力。对于错误的理解其实并不是没有道理,现在版本的hadoop支持进行HA的实时备份。后面的章节后说。
(2) fsImage和edits: 虽然说不希望在这讲一些概念,但是该说的还是得说。简单的解释: fsimage包含Hadoop文件系统中的所有目录和文件idnode的序列化信息,其中对于文件包含了文件的修改时间、访问时间、块大小和组成一个文件块信息等。对于文件夹而言包含的信息主要有修改时间、访问控制权限等信息。而Edits文件主要是进行客户端对文件操作的记录,比如上传新文件等。并且edits文件会定期与fsimage文件进行合并操作。
宏观的写入过程:
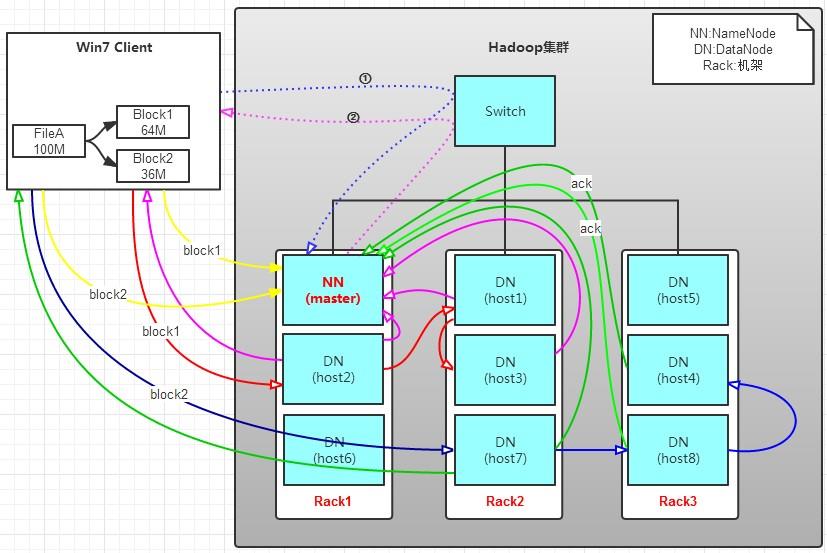
具体的流程如下:
1.首先是客户端将文件进行分块,分块的大小标准按照配置文件中给定的大小。
2.然后客户端通知namenode即将上传文件,namenode创建制定目录,并根据配置文件中指定的备份数量及机架感知原理进行文件分配,比如备份数量3由机架感知将3分文件分别存储在机架1的host2,机架2的host1和host3中。
3. 客户端与指定的datanode建立流传输通道,并向机架1中的host2进行文件传输,传输完成之后host2向机架2中的host1进行文件备份。host2备份完成之后将数据块拷贝到同一个机架的host3中。
4.3台机器都完成这个过程之后host2,host1,host3分别向namenode发起通知说文件已经存储完成。同时host2向客户端发起通知。
5.客户端收到host2返回的请求之后向namenode发起通知---已经完成数据写入。则整个流程运行完成。
以上是关于如何在ubuntu中将hadoop的hdfs进行格式化?我用hdfs namenode -format命令提示没有hdfs该命令。的主要内容,如果未能解决你的问题,请参考以下文章
将 csv 日志文件从 windows 服务器转储到 ubuntu VirtualBox/hadoop/hdfs
改造Hadoop 的HDFS的NN,DN进程,日志输出为json格(转)