苹果地表最强芯只能剪视频?
Posted 人工智能博士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了苹果地表最强芯只能剪视频?相关的知识,希望对你有一定的参考价值。
点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :新智元
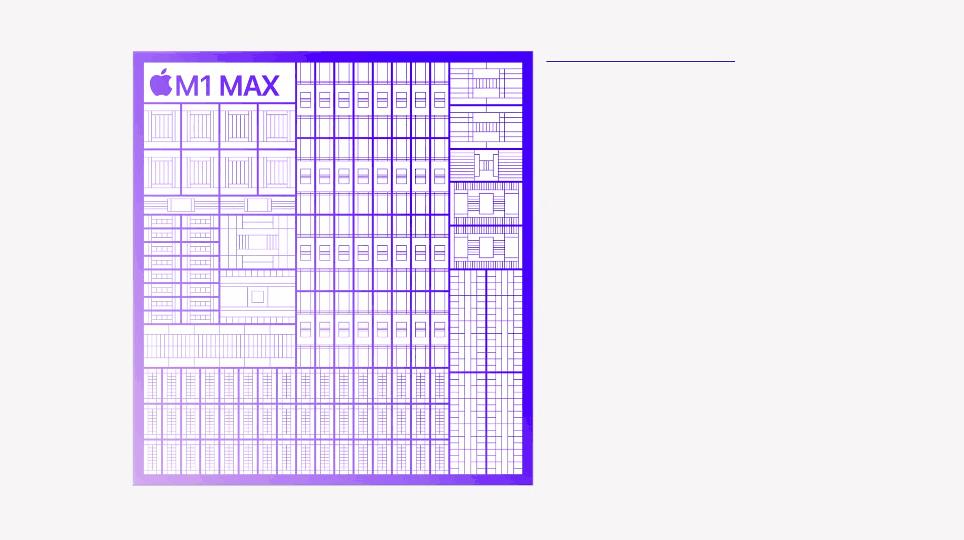
5nm工艺,570亿晶体管,70%CPU性能提升,4倍GPU性能提升。号称史上最强芯片的M1 Max,只能「剪剪视频」?
最近,苹果开了一个芯片新品发布会。
光看参数,M1 Pro和M1 Max两款芯片确实太顶了!
M1 Pro,晶体管面积达到245mm²,内置337亿个晶体管,是M1的2倍多。

而M1 Max更夸张,搭载570亿个晶体管,比Pro还要大70%,芯片面积达到432mm²。

M1 Pro和M1 Max均采用大小核设计,最多10个核心,包括8个高性能内核和2个高效内核,CPU的性能直接比前代M1芯片提升70%。
GPU方面,M1 Pro采用最多16个核心,性能比M1芯片的GPU高出两倍。
而M1 Max一举将GPU的核心数量干到32个,算力可以达到恐怖的10.4TFLOPs,比M1的GPU还要再快4倍!
10TFLOPs,这个数字有点熟悉啊?
对GPU性能敏感的朋友可能联想到了,空气显卡公司Nvidia的RTX 2080给出的GPU参考性能也是这个数字。
M1 | M1 Pro | M1 Pro | M1 Max | M1 Max | |
GPU核心数 | 8 | 14 | 16 | 24 | 32 |
Teraflops | 2.6 | 4.5 | 5.2 | 7.8 | 10.4 |
AMD GPU | RX 560 (2.6TF) | RX 5500M (4.6TF) | RX 5500 (5.2TF) | RX 5700M (7.9TF) | RX Vega 56 (10.5TF) |
Nvidia GPU | GTX 1650 (2.9TF) | GTX 1650 Super (4.4TF) RTX3050-75W(4.4TF | GTX 1660 Ti (5.4TF) | RTX 2070 (7.4TF) | RTX 2080 (10TF) RTX3060-80W(10.94TF) |
现在深度学习这么火,要不让M1系列的芯片和RTX 2080比试比试?
M1 VS 2080Ti
提到深度学习框架无非就是TensorFlow和PyTorch。
然而,这俩一直以来都只支持在NVIDIA的GPU上使用CUDA加速。而苹果用户只能在CPU上慢慢跑。
不过,苹果在2020年11月推出了采用M1芯片的Mac之后,很快,TensorFlow也出了2.4版本更新,支持在M1的GPU上训练神经网络。

https://machinelearning.apple.com/updates/ml-compute-training-on-mac
「TensorFlow 2.4的tensorflow_macos利用ML Compute,使机器学习库不仅能充分利用CPU,还能充分利用M1和英特尔驱动的Mac中的GPU,大幅提高训练性能。」
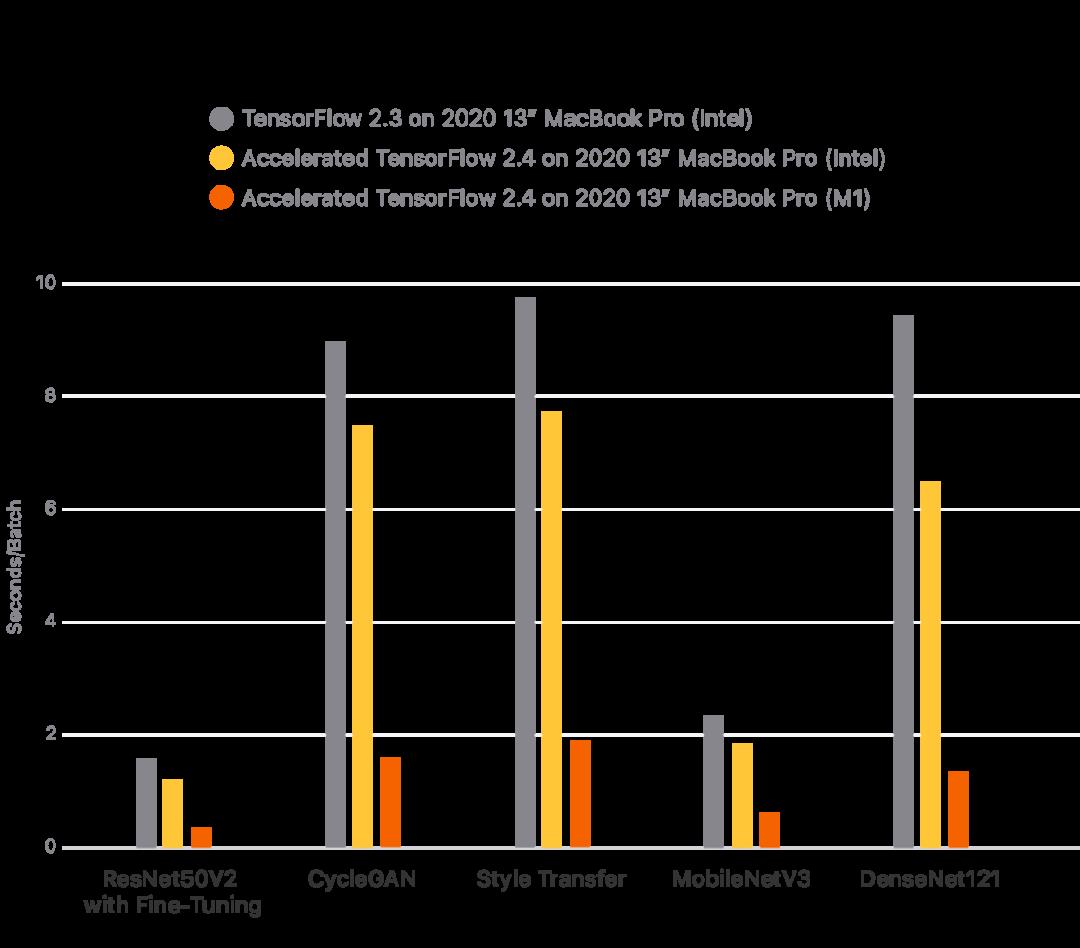
说得这么nice,到底怎么样,还是要实践才知道。
鉴于搭载M1 Pro和M1 Max的最新款Macbook Pro还未开售,就先用他们的小弟M1代替他们出场吧。M1的GPU最高可以跑到2.6TFLOPs,差不多是Nvidia RTX 2080独显的四分之一。
先在fashion-MNIST数据集上,训练一个小的三层全连接网络试试。
#import libraries
import tensorflow as tf
import time
#download fashion mnist dataset
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
train_set_count = len(train_labels)
test_set_count = len(test_labels)
#setup start time
t0 = time.time()
#normalize images
train_images = train_images / 255.0
test_images = test_images / 255.0
#create ML model
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10)
])
#compile ML model
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
#train ML model
model.fit(train_images, train_labels, epochs=10)
#evaluate ML model on test set
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
#setup stop time
t1 = time.time()
total_time = t1-t0
#print results
print('\\n')
print(f'Training set contained train_set_count images')
print(f'Testing set contained test_set_count images')
print(f'Model achieved test_acc:.2f testing accuracy')
print(f'Training and testing took total_time:.2f seconds')测试开始,先在一台搭载Intel i7-9700K,拥有32GB内存,以及一张Nvidia RTX 2080Ti独立显卡的Linux系统电脑上运行上面的代码。
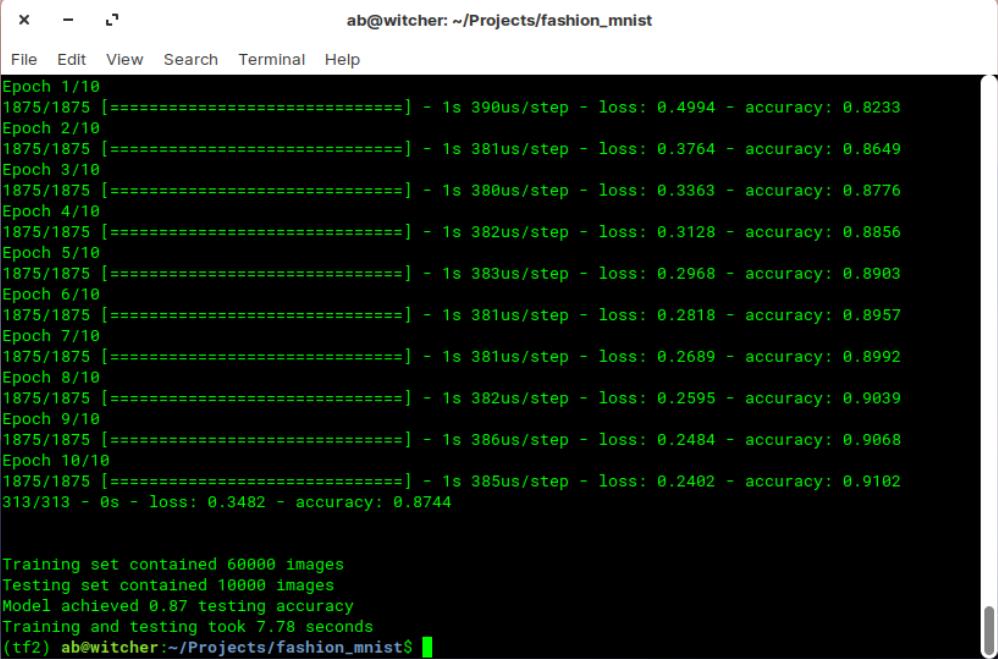
很快,就得到了结果:训练和测试花了7.78秒。
接着,用搭载M1处理器(8个CPU核心,8个GPU核心,16个神经引擎核心)和8GB内存的Mac Mini训练模型。
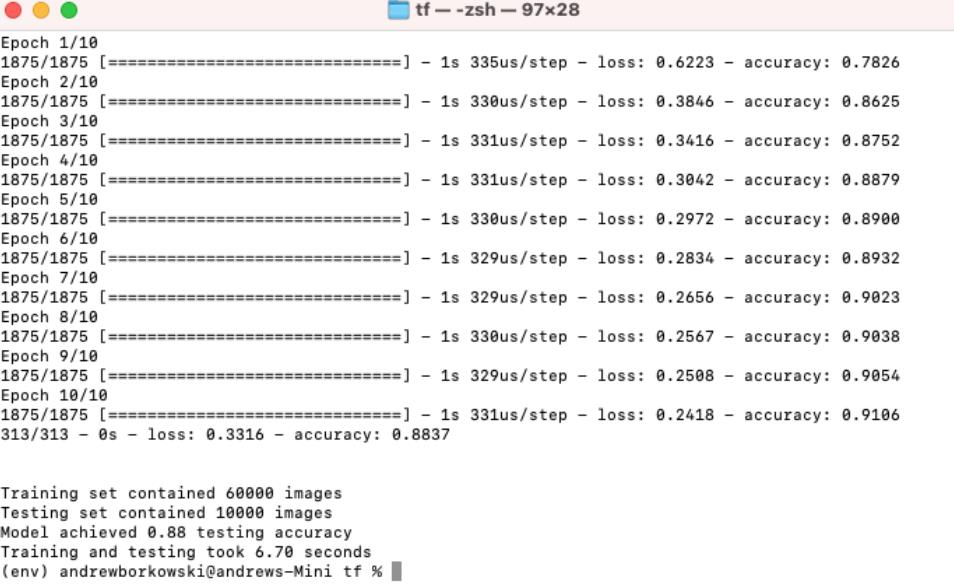
结果非常amazing啊!
训练和测试仅仅耗时6.70秒,比RTX 2080Ti的GPU还要快14%!这就有点厉害了。
但说实话,fashion-MNIST分类这种任务有点过于简单了,如果想在更大的数据集上,训练更强大的模型呢?
所以,得给它们来点更难的任务,分别用M1和RTX 2080Ti在Cifar10数据集上训练一个常用的ResNet50分类模型如何?
#import libraries
import tensorflow as tf
from time import perf_counter
#download cifar10 dataset
cifar10 = tf.keras.datasets.cifar10
(train_images, train_labels), (test_images, test_labels) = cifar10.load_data()
train_set_count = len(train_labels)
test_set_count = len(test_labels)
#setup start time
t1_start = perf_counter()
#normalize images
train_images = train_images / 255.0
test_images = test_images / 255.0
#create ML model using tensorflow provided ResNet50 model, note the [32, 32, 3] shape because that's the shape of cifar
model = tf.keras.applications.ResNet50(
include_top=True, weights=None, input_tensor=None,
input_shape=(32, 32, 3), pooling=None, classes=10
)
# CIFAR 10 labels have one integer for each image (between 0 and 10)
# We want to perform a cross entropy which requires a one hot encoded version e.g: [0.0, 0.0, 1.0, 0.0, 0.0...]
train_labels = tf.one_hot(train_labels.reshape(-1), depth=10, axis=-1)
# Do the same thing for the test labels
test_labels = tf.one_hot(test_labels.reshape(-1), depth=10, axis=-1)
#compile ML model, use non sparse version here because there is no sparse data.
model.compile(optimizer='adam',
loss=tf.keras.losses.CategoricalCrossentropy(),
metrics=['accuracy'])
#train ML model
model.fit(train_images, train_labels, epochs=10)
#evaluate ML model on test set
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
#setup stop time
t1_stop = perf_counter()
total_time = t1_stop-t1_start
#print results
print('\\n')
print(f'Training set contained train_set_count images')
print(f'Testing set contained test_set_count images')
print(f'Model achieved test_acc:.2f testing accuracy')
print(f'Training and testing took total_time:.2f seconds')测试再次开始,在RTX 2080Ti运行新代码,表现非常不错。

训练了10个epoch,训练和测试共耗时418.73秒,GPU的利用率在65%和75%之间波动。
接下来,在M1 Mac Mini上运行新代码。

看上去有点拉胯啊,M1 Mac Mini训练和测试总耗时2286.16秒,是RTX 2080Ti GPU耗时的5.46倍。
理论上讲,M1的GPU性能是RTX 2080Ti GPU的3.84分之一,这么看,其实际性能还是略有欠缺。
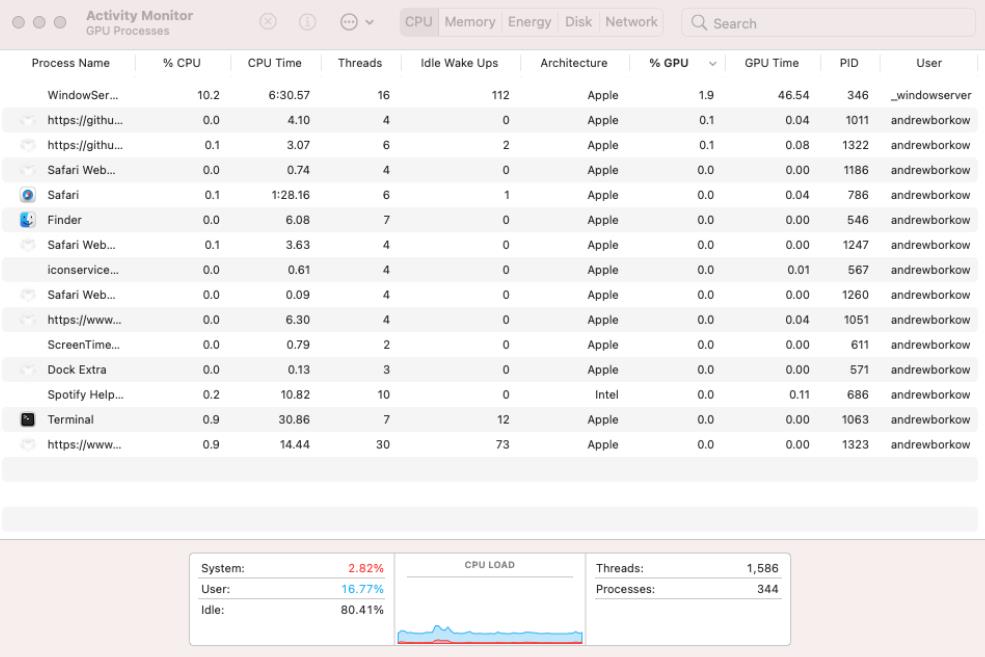
通过Mac的活动监视器也能看到,CPU的使用率确实较低,GPU几乎没有怎么使用,看来还是Tensorflow对M1硬件资源的调度优化得不够好。
不过,最近,Tensorflow放出了对M1 Metal GPU插件支持。
https://developer.apple.com/metal/tensorflow-plugin/
还给出了安装指导教程,感兴趣的朋友可以尝尝鲜(需安装TensorFlow v2.5或v2.6)。

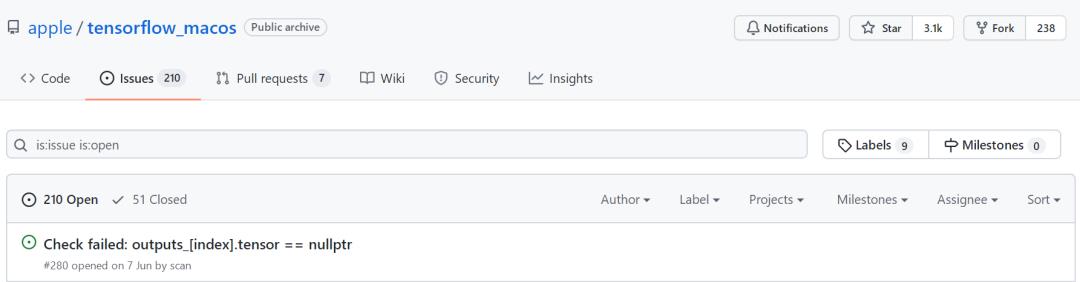
友情提示,先看看TensorFlow_macOS GitHub仓库的issue的数量,劝退不。。。
这么来看,M1确实可以训练深度学习模型,实际性能也勉强能用。
要是换上那个4倍加成的M1 Max没准还真能和RTX 2080Ti GPU碰一碰。
但是还是那个问题:能用不代表好用。
为啥评测只有「剪视频」
M1一直以来都有一个被诟病的地方:生态不行。
推特上有大神留言:「M1确实能用于数据科学,但恐怕你得花一个通宵装配置才能用」。

其实,不仅仅是机器学习,很多大型游戏和工业软件目前都不兼容苹果的M1系列芯片。
在知乎上,就有人提出了质疑:为什么在宣传苹果的M1芯片的性能时,总是以视频剪辑为例呢?

排第一的回答就说得很有道理:「他们惊叹M1的强大的时候,自然用自己最顺手的方式来说明M1强大。看起来是清一色的用视频来验证M1的强大,其实只是他们的声音大罢了。」
而且,看完刚才那段用M1跑机器学习的体验,这个问题其实也就不难回答了。
写个文:用不着;
编个程:不会用。
当然,也有非专职博主做过Spring性能的测试,在转译模式下跑Java,性能也很不错。特别是对小内存的优化,以及几乎无敌的不发热和没噪声。
不过对于这一点,有网友表示:「软件开发在Mac上是劣势,在M1上更是劣势中的劣势。」

那这么看来,在「生产力」里面,可能也就只有「视频」既能体现出性能强劲,又方便好做了。
然而,网友吐槽说:「M1也就用来剪点小片子玩玩还行了」。

除此以外也一大堆插件只支持Intel,甚至连Mac都没有。
游戏呢,一直都不是Mac的重点,这次苹果就更直接了,一句都没提。以前好歹还放一个狂野飙车9呢。
既然苹果的态度都这么明显了,何必非要用MAC去自己折磨自己呢。
有网友就表示:「既然我有钱16199买mbp,我自然也有windows主机」。

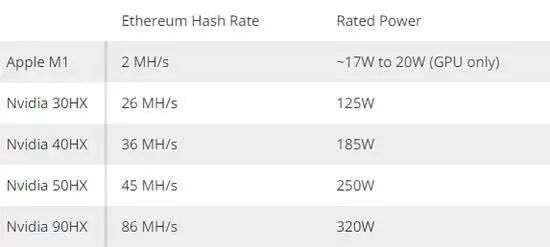
挖矿这事吧,不提倡,而且就M1的表现来说,非常拉垮。不知道M1 Max能不能一雪前耻。
话说回来,最常用的生产力难道不是word、ppt、keynote这些么,买一个M1的MacBook,续航长,屏幕好,速度快还便宜,多香。

参考资料:
文中引用了青空,Hate Letter等人的回答,具体参见:
https://www.zhihu.com/question/460373656
https://www.zhihu.com/question/493188474
https://www.zhihu.com/question/493188575
https://appleinsider.com/articles/21/10/19/m1-pro-and-m1-max-gpu-performance-versus-nvidia-and-amd
https://developer.apple.com/metal/tensorflow-plugin/
https://medium.com/analytics-vidhya/m1-mac-mini-scores-higher-than-my-nvidia-rtx-2080ti-in-tensorflow-speed-test-9f3db2b02d74
https://twitter.com/theshawwn/status/1449930512630525956?s=21
---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


点个在看支持一下吧

以上是关于苹果地表最强芯只能剪视频?的主要内容,如果未能解决你的问题,请参考以下文章
乔布斯当场“复活”,苹果发AirPods 3和地表最强电脑芯片,秀刘海屏Macbook Pro