Java开发框架选型对比:ruoyi与yudao框架
Posted 小黑上街
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java开发框架选型对比:ruoyi与yudao框架相关的知识,希望对你有一定的参考价值。
1、基础开发框架
1.1 什么是基础开发框架?
基础框架可以理解为建立一个项目所需的基础框架,这个基础框架为凝聚了之前开发项目的通用、共性的方法、工具、技术等组成的代码包。
现有我们公司有两类基础框架:
(1)基于web应用的基础框架
(2)基于数据迁移场景的基础框架
大家可根据具体的实际场景制定试用自己的基础框架。
1.2 为什么需要基础框架?
做开发的同事可能都知道,每次研究一项新技术含定时任务、权限、文件上传等这类都需要花时间研究与调试。但是只要第一次研究通了,后面开发效率就快了。
若对以往的项目不进行总结:
A写了定时任务相关代码 B 写了文件上传相关代码 C写了权限相关代码
现有D项目需要同时有定时任务、文件上传、权限管理相关功能,如何处理?
传统方式:逐一搜寻A、B、C复制相关代码,此效率极为低下,因此基础框架就有了必要性。
基础框架方式:封装相关代码,形成common层,并搭建模板项目作为基础框架供其他项目调用
1.3 现有基础框架有哪些?
力软、JEECGBOOT、若依、芋道。其中力软为付费产品,JEECGBOOT的码云star为4.1k,若依的码云star为30.9k,芋道的码云star为13.8K。综合可见芋道和若依框架分值相对较高。
2 若依框架
 http://www.ruoyi.vip/
http://www.ruoyi.vip/主要包含:RuoYi RuoYi-Vue RuoYi-Cloud,分别为快速开发版,前后端分离版,微服务版。
生态齐全,并拥有拓展生态含uniapp版本、pgsql版本、mybaitplus版本、国产数据库版本、react、ant desing版本等
2.1前端页面
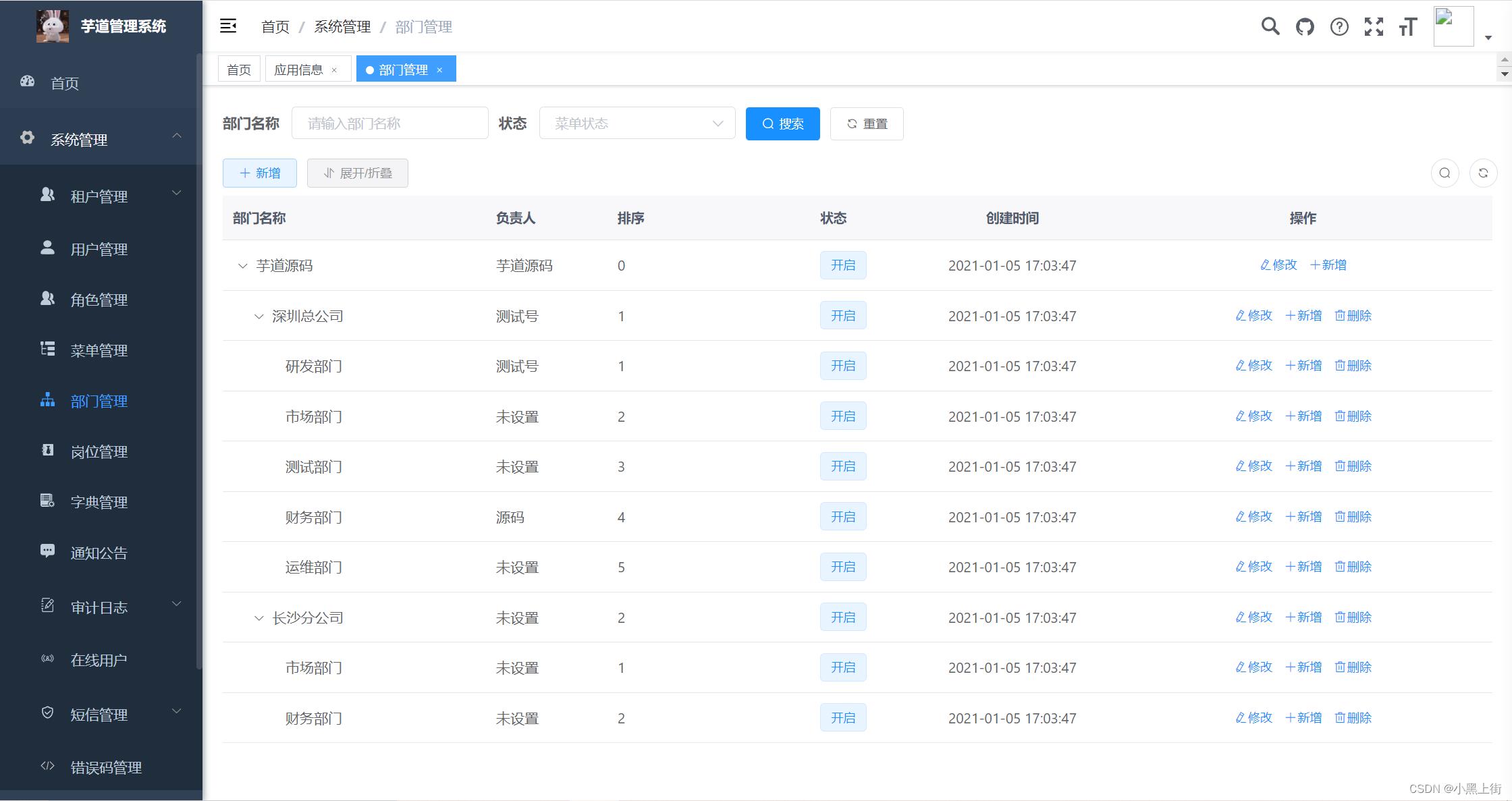
- 用户管理:用户是系统操作者,该功能主要完成系统用户配置。
- 部门管理:配置系统组织机构(公司、部门、小组),树结构展现支持数据权限。
- 岗位管理:配置系统用户所属担任职务。
- 菜单管理:配置系统菜单,操作权限,按钮权限标识等。
- 角色管理:角色菜单权限分配、设置角色按机构进行数据范围权限划分。
- 字典管理:对系统中经常使用的一些较为固定的数据进行维护。
- 参数管理:对系统动态配置常用参数。
- 通知公告:系统通知公告信息发布维护。
- 操作日志:系统正常操作日志记录和查询;系统异常信息日志记录和查询。
- 登录日志:系统登录日志记录查询包含登录异常。
- 在线用户:当前系统中活跃用户状态监控。
- 定时任务:在线(添加、修改、删除)任务调度包含执行结果日志。
- 代码生成:前后端代码的生成(java、html、xml、sql)支持CRUD下载 。
- 系统接口:根据业务代码自动生成相关的api接口文档。
- 服务监控:监视当前系统CPU、内存、磁盘、堆栈等相关信息。
- 缓存监控:对系统的缓存信息查询,命令统计等。
- 在线构建器:拖动表单元素生成相应的Vue代码。
- 连接池监视:监视当期系统数据库连接池状态,可进行分析SQL找出系统性能瓶颈。



2.2系统架构
主要层及架构
1、系统环境
- Java EE 8
- Servlet 3.0
- Apache Maven 3
2、主框架
- Spring Boot 2.2.x
- Spring Framework 5.2.x
- Spring Security 5.2.x
3、持久层
- Apache MyBatis 3.5.x
- Hibernate Validation 6.0.x
- Alibaba Druid 1.2.x
4、视图层
- Vue 2.6.x
- Axios 0.21.x
- Element 2.15.x
主要的工具如下

3、芋道框架
项目地址
 https://gitee.com/zhijiantianya/ruoyi-vue-pro?_from=gitee_search
https://gitee.com/zhijiantianya/ruoyi-vue-pro?_from=gitee_search3.1 前端页面

3.2 功能清单
- 后端采用 Spring Boot、mysql + MyBatis Plus、Redis + Redisson。
- 数据库可使用 MySQL、Oracle、PostgreSQL、SQL Server、MariaDB、国产达梦 DM、TiDB 等
- 权限认证使用 Spring Security & Token & Redis,支持多终端、多种用户的认证系统。
- 支持加载动态权限菜单,按钮级别权限控制,本地缓存提升性能。
- 支持 SaaS 多租户系统,可自定义每个租户的权限,提供透明化的多租户底层封装。
- 工作流使用 Flowable,支持动态表单、在线设计流程、会签 / 或签、多种任务分配方式。
- 高效率开发,使用代码生成器可以一键生成前后端代码 + 单元测试 + Swagger 接口文档 + Validator 参数校验。
- 集成微信小程序、微信公众号、企业微信、钉钉等三方登陆,集成支付宝、微信等支付与退款。
- 集成阿里云、腾讯云、云片等短信渠道,集成 MinIO、阿里云、腾讯云、七牛云等云存储服务。
4 框架对比
4.1 若依框架优势
1、功能简洁包含项目需要的最小框架:定时任务、系统参数、字典、通知公告、代码生成,启动项目速度快
2、具备完整的生态,查看其他语言代码方便
4.2 芋道框架优势
1、功能模块多,集成mapstruct、mybaitplus、Oauth2 、短信、错误码,启动速度慢
2、集成特定场景应用:支付、工作流
3、框架复杂,一些场景排查问题较难,有严格的VO 与APP\\ADMIN接口区分,以及业务端和内部接口区分。代码框架接口清晰便捷明显,系统之间相互调用较多。
4、自动编写单元测试,每次打包时会利用的sqlite数据库进行单元测试。
5 框架选型
建议小团队使用若依框架,以下内容为亲自使用总结
(1)开发速度快,问题定位快
(2)可寻找任何语言开源替代(例如vue3的框架可能在IE9下不支持,需要换VUE2或者其他框架),或者项目团队成员只会net或python语言,这些都可以找到替代产品;国产化软件也可以找到相关替代。
建议大团队使用芋道框架
(1)APP端和pc端严格区分;业务API与前端接口严格区分
(2)有较多开源的拓展功能,集成了Hutool工具包,支持包含文件上传、小程序登录三方登录、工作流、短信、多租户、支付等功能。
(3)初始内置多种数据库脚本,可天然支持多种数据库含国产数据库。
6、若依基础框架项目分享
目前用若依的mybaitplus做了两个示例,分别包含单表查询、多表查询的案例。中间使用了代码生成方法。
6.1单表查询
(1)首先新建数据库表
(2)点开代码生成页面,配置列表、查询、搜索字段,对于字典或者时间范围类型等条件可对应进行配置
(3)生成代码,前端拷贝、后端拷贝。
6.2多表联合查询
(1)后端首先以单表模式生成增删改查
(2)在对应controller增加新的查询接口
(3)如果是表格页面,则前端复制页面的vue和api,直接进行修改及编写;表单可借助form-generator进行搭建。
具体若依案例项目含(单表及多表案例)的项目代码见链接.
几种Java常用序列化框架的选型与对比
通用性:通用性是指序列化框架是否支持跨语言、跨平台。
易用性:易用性是指序列化框架是否便于使用、调试,会影响开发效率。
可扩展性:随着业务的发展,传输实体可能会发生变化,但是旧实体有可能还会被使用。这时候就需要考虑所选择的序列化框架是否具有良好的扩展性。
性能:序列化性能主要包括时间开销和空间开销。序列化的数据通常用于持久化或网络传输,所以其大小是一个重要的指标。而编解码时间同样是影响序列化协议选择的重要指标,因为如今的系统都在追求高性能。
Java数据类型和语法支持:不同序列化框架所能够支持的数据类型以及语法结构是不同的。这里我们要对Java的数据类型和语法特性进行测试,来看看不同序列化框架对Java数据类型和语法结构的支持度。
/*** 编码*/public static byte[] encoder(Object ob) throws Exception{//用于缓冲字节数字ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();//序列化对象ObjectOutputStream objectOutputStream = new ObjectOutputStream(byteArrayOutputStream);objectOutputStream.writeObject(ob);byte[] result = byteArrayOutputStream.toByteArray();//关闭流objectOutputStream.close();byteArrayOutputStream.close();return result;}/*** 解码*/public static <T> T decoder(byte[] bytes) throws Exception {ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(bytes);ObjectInputStream objectInputStream = new ObjectInputStream(byteArrayInputStream);T object = (T) objectInputStream.readObject();objectInputStream.close();byteArrayInputStream.close();return object;}
java.io.InvalidClassException: com.yjz.serialization.java.UserInfo; local class incompatible: stream classdesc serialVersionUID = -5548195544707231683, local class serialVersionUID = -5194320341014913710private static final long serialVersionUID = 1L;public class MessageInfo implements Serializable {private String username;private String password;private int age;private HashMap<String,Object> params;...public static MessageInfo buildMessage() {MessageInfo messageInfo = new MessageInfo();messageInfo.setUsername("abcdefg");messageInfo.setPassword("123456789");messageInfo.setAge(27);Map<String,Object> map = new HashMap<>();for(int i = 0; i< 20; i++) {map.put(String.valueOf(i),"a");}return messageInfo;}}
| 1000万序列化耗时(ms) | 1000万反序列化耗时(ms) |
| 38952 | 96508 |
| JDK | |
| 8种基础类型 | 支持 |
| List集合类 | 支持 |
| Set集合类 | 支持 |
| Queue集合类 | 支持 |
| Map映射 | 大部分支持(WeakHashMap不支持) |
| 自定义类类型 | 支持 |
| 枚举类型 | 支持 |
| JDK | |
| 对象为null | 支持 |
| 没有无参构造函数 | 支持 |
| static内部类 | 支持(static内部类需要实现序列化接口) |
| 非static内部类 | 支持,但是外部类也需要实现序列化接口 |
| 局部内部类 | 支持 |
| 匿名内部类 | 支持 |
| Lambda表达式 | 修改代码可以支持,看注1 |
| 闭包 | 支持 |
| 异常类 | 支持 |
Runnable runnable = () -> System.out.println("Hello");com.yjz.serialization.SerializerFunctionTest$$Lambda$1/189568618Runnable runnable = (Runnable & Serializable) () -> System.out.println("Hello");private final ThreadLocal<FSTConfiguration> conf = ThreadLocal.withInitial(() -> {FSTConfiguration conf = FSTConfiguration.createDefaultConfiguration();return conf;});public byte[] encoder(Object object) {return conf.get().asByteArray(object);}public <T> T decoder(byte[] bytes) {Object ob = conf.get().asObject(bytes);return (T)ob;}
private String origiField;(1)private String addField;
删除字段将破坏向后兼容性,但是如果我们在原始字段情况下删除字段是能够向后兼容的(没有新增任何字段)。但是如果新增字段后,再删除字段的话就会破坏其兼容性。
Version注解功能不能应用于自己实现的readObject/writeObject情况。
如果自己实现了Serializer,需要自己控制Version。
| 1000万序列化耗时(ms) | 1000万反序列化耗时(ms) |
| 13587 | 19031 |
private static final ThreadLocal<FSTConfiguration> conf = ThreadLocal.withInitial(() -> {FSTConfiguration conf = FSTConfiguration.createDefaultConfiguration();conf.registerClass(UserInfo.class);conf.setShareReferences(false);return conf;});
| 1000万序列化耗时(ms) | 1000万反序列化耗时(ms) |
| 7609 | 17792 |
| FST | |
| 8种基础类型 | 支持 |
| List集合类 | 支持 |
| Set集合类 | 支持 |
| Queue集合类 | 支持 |
| Map映射 | 大部门支持(WeakHashMap不支持) |
| 自定义类类型 | 支持 |
| 枚举类型 | 支持 |
| FST | |
| 对象为null | 支持 |
| 没有无参构造函数 | 支持 |
| static内部类 | 支持(static内部类需要实现序列化接口) |
| 非static内部类 | 支持,但是外部类也需要实现序列化接口 |
| 局部内部类 | 支持 |
| 匿名内部类 | 支持 |
| Lambda表达式 | 修改代码可以支持(同JDK) |
| 闭包 | 支持 |
| 异常类 | 支持 |
private static final ThreadLocal<Kryo> kryoLocal = ThreadLocal.withInitial(() -> {Kryo kryo = new Kryo();kryo.setRegistrationRequired(false);//不需要提前预注册类return kryo;});public static byte[] encoder(Object object) {Output output = new Output();kryoLocal.get().writeObject(output,object);output.flush();return output.toBytes();}public static <T> T decoder(byte[] bytes) {Input input = new Input(bytes);Object ob = kryoLocal.get().readClassAndObject(input);return (T) ob;}
需要注意的是使用Output.writeXxx时候一定要用对应的Input.readxxx,比如Output.writeClassAndObject()要与Input.readClassAndObject()。
private static final ThreadLocal<Kryo> kryoLocal = ThreadLocal.withInitial(() -> {Kryo kryo = new Kryo();kryo.setRegistrationRequired(false);kryo.setDefaultSerializer(TaggedFieldSerializer.class);return kryo;});
| 1000万序列化时间开销(ms) | 1000万反序列化时间开销(ms) |
| 13550 | 14315 |
| 1000万序列化时间开销(ms) | 1000万反序列化时间开销(ms) |
| 11799 | 11584 |
| Kryo | |
| 8种基础类型 | 支持 |
| List集合类 | 支持 |
| Set集合类 | 支持 |
| Queue集合类 | 部分支持(ArrayBlockingQueue不支持) |
| Map映射 | 支持 |
| 自定义类类型 | 支持 |
| 枚举类型 | 支持 |
| Kryo | |
| 对象为null | 支持 |
| 没有无参构造函数 | 不支持 |
| static内部类 | 支持 |
| 非static内部类 | 不支持 |
| 局部内部类 | 支持 |
| 匿名内部类 | 支持 |
| Lambda表达式 | 不支持 |
| 闭包 | 支持 |
| 异常类 | 不支持(StackOverflowError) |
syntax = "proto3";option java_package = "com.yjz.serialization.protobuf3";message MessageInfo{string username = 1;string password = 2;int32 age = 3;map<string,string> params = 4;}
protoc --java_out=./src/main/java message.proto//编码byte[] bytes = MessageInfo.toByteArray()//解码MessageInfo messageInfo = Message.MessageInfo.parseFrom(bytes);
message userinfo{reserved 3,7; //在保留标签中,添加删除的字段标签reserved "age","sex" //在保留字段中,添加删除的字段}
| 1000万数据序列化耗时(ms) | 1000万数据反序列化耗时(ms) |
| 14235 | 30694 |
| Protobuf | |
| 8种基础类型 | 基本支持(无byte、shot、char) |
| List集合类 | 支持 |
| Set集合类 | 支持 |
| Queue集合类 | 支持 |
| Map映射 | 支持 |
| 自定义类类型 | 支持 |
| 枚举类型 | 支持 |
namespace java com.yjz.serialization.thriftstruct MessageInfo{1: string username;2: string password;3: i32 age;4: map<string,string> params;}
thrift --gen java message.thriftpublic static byte[] encoder(MessageInfo messageInfo) throws Exception{TSerializer serializer = new TSerializer();return serializer.serialize(messageInfo);}public static MessageInfo decoder(byte[] bytes) throws Exception{TDeserializer deserializer = new TDeserializer();MessageInfo messageInfo = new MessageInfo();deserializer.deserialize(messageInfo,bytes);return messageInfo;}
修改字段名称:修改字段名称不影响序列化与反序列化,反序列化数据赋值到更新过的字段上。因为编解码过程利用的是编号对应。
修改字段类型:修改字段类型,如果修改的字段为optional类型字段,则返回数据为null或0(数据类型默认值)。如果修改是required类型字段,则会直接抛出异常,提示字段没有找到。
新增字段:如果新增字段是required类型,则需要为其设置默认值,负责在反序列化过程抛出异常。如果为optional类型字段,反序列化过程不会存在该字段(因为optional字段没有赋值的情况,不会参与序列化与反序列化)。如果为缺省类型,则反序列化值为null或0(和数据类型有关)。
删除字段:无论required类型字段还是optional类型字段,都可以删除,不会影响反序列化。
删除后的字段整数标签不要复用,负责会影响反序列化。
| 1000万序列化时间开销(ms) | 1000万反序列化时间开销(ms) |
| 28634 | 20722 |
8中基础数据类型,没有short、char,只能使用double和String代替。
集合类型,支持List、Set、Map,不支持Queue。
自定义类类型(struct类型)。
枚举类型。
字节数组。
public static <T> byte[] encoder2(T obj) throws Exception{ByteArrayOutputStream bos = new ByteArrayOutputStream();Hessian2Output hessian2Output = new Hessian2Output(bos);hessian2Output.writeObject(obj);return bos.toByteArray();}public static <T> T decoder2(byte[] bytes) throws Exception {ByteArrayInputStream bis = new ByteArrayInputStream(bytes);Hessian2Input hessian2Input = new Hessian2Input(bis);Object obj = hessian2Input.readObject();return (T) obj;}
修改字段名称:反序列化后新字段名称为null或0(受类型影响)。
新增字段:反序列化后新增字段为null或0(受类型影响)。
删除字段:能够正常反序列化。
修改字段类型:如果字段类型兼容能够正常反序列化,如果不兼容则直接抛出异常。
| 1000万序列化时间开销(ms) | 1000万反序列化时间开销(ms) | |
| Hessian1.0 | 57648 | 55261 |
| Hessian2.0 | 38823 | 17682 |
{"namespace": "com.yjz.serialization.avro","type": "record","name": "MessageInfo","fields": [{"name": "username","type": "string"},{"name": "password","type": "string"},{"name": "age","type": "int"},{"name": "params","type": {"type": "map","values": "string"}}]}
java -jar avro-tools-1.8.2.jar compile schema src/main/resources/avro/Message.avsc ./src/main/javapublic static byte[] encoder(MessageInfo obj) throws Exception{DatumWriter<MessageInfo> datumWriter = new SpecificDatumWriter<>(MessageInfo.class);ByteArrayOutputStream outputStream = new ByteArrayOutputStream();BinaryEncoder binaryEncoder = EncoderFactory.get().directBinaryEncoder(outputStream,null);datumWriter.write(obj,binaryEncoder);return outputStream.toByteArray();}public static MessageInfo decoder(byte[] bytes) throws Exception{DatumReader<MessageInfo> datumReader = new SpecificDatumReader<>(MessageInfo.class);BinaryDecoder binaryDecoder = DecoderFactory.get().directBinaryDecoder(new ByteArrayInputStream(bytes),null);return datumReader.read(new MessageInfo(),binaryDecoder);}
给所有field定义default值。如果某field没有default值,以后将不能删除该field。
如果要新增field,必须定义default值。
不能修改field type。
不能修改field name,不过可以通过增加alias解决。
| 1000万序列化时间开销(ms) | 1000万序反列化时间开销(ms) | |
| 生成Java代码 | 26565 | 45383 |
| 序列化框架 | 通用性 |
| JDK Serializer | 只适用于Java |
| FST | 只适用于Java |
| Kryo | 主要适用于Java(可复杂支持跨语言) |
| Protocol buffer | 支持多种语言 |
| Thrift | 支持多种语言 |
| Hessian | 支持多种语言 |
| Avro | 支持多种语言 |
| 序列化框架 | 易用性 |
| JDK Serializer | 使用语法过于生硬 |
| FST | 使用简洁,FSTConfiguration提供了序列化与反序列化的方法 |
| Kryo | 使用简洁,Input/Output封装了几乎所有能有需要的流方法 |
| Protocol buffer | 稍微复杂。需要编写所需序列化类的proto文件,然后编译生成Java代码。但是自动生成Java类,包含了序列化与反序列化方法 |
| Thrift | 稍微复杂。需要编写所需的序列化类的thrift文件,然后编译生成Java代码。然后通过TSerializer和TDserializer进行序列化与反序列化 |
| Hessian | 使用简单,在跨语言的基础上不需要使用IDL |
| Avro | 使用较复杂。相较于Protobuf和Thrift来说,对于一些静态语言无序生成代码。但是对于Java来一般还需要生成代码,并且Avro提供的API不是很友好 |
| 序列化框架 | 可扩展性 |
| JDK Serializer | 自定义serialVersionUID,保证序列化前后VUID一致即可 |
| FST | 通过@Version控制版本,新增字段需要修改Version版本 |
| Kryo | 默认序列化器不支持字段扩展,需要修改默认序列化器或自己实现序列化器 |
| Protocol buffer | 支持字段扩展,只要保证新增id标识没有使用过即可 |
| Thrift | 支持字段扩展。新增字段为required类型时,需要设置默认值 |
| Hessian | 支持字段扩展 |
| Avro | 支持字段扩展。注意需要为字段设置默认值 |
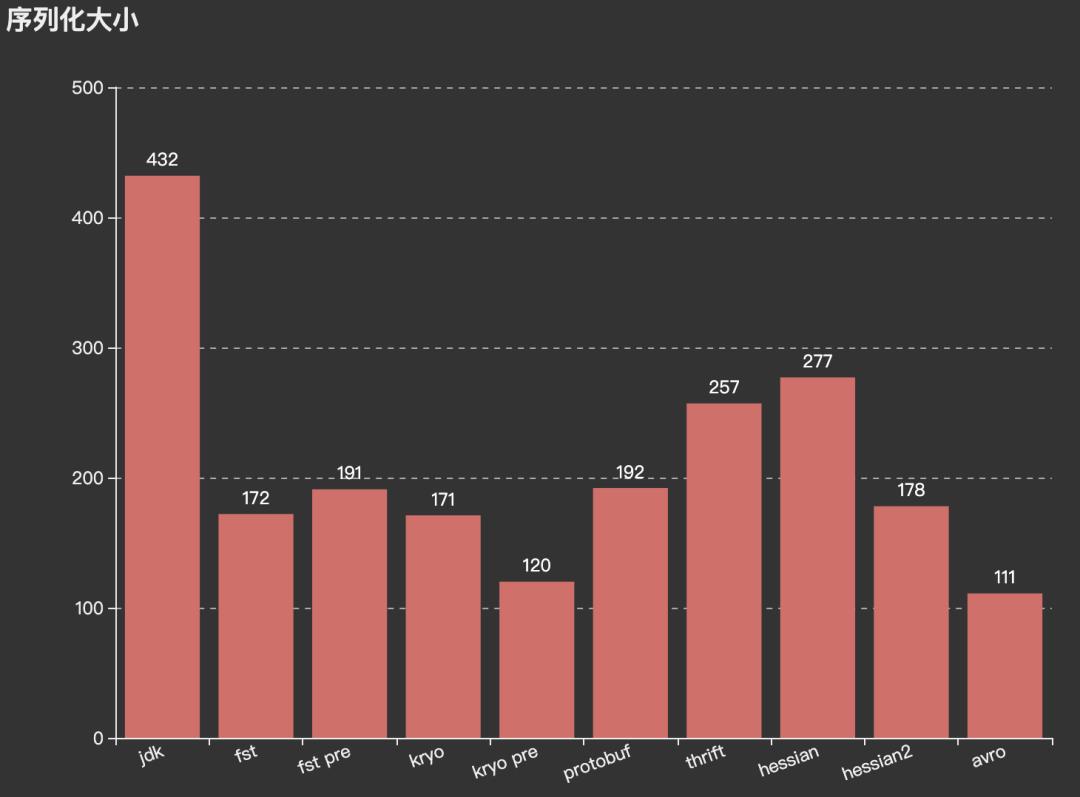
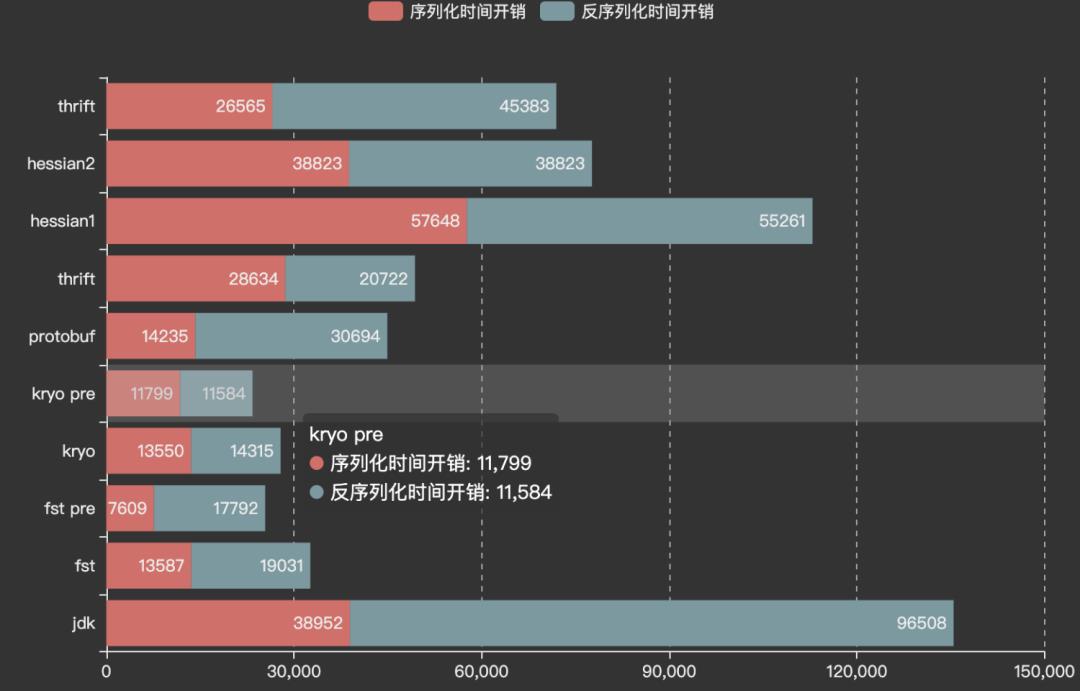
List测试内容:ArrayList、LinkedList、Stack、CopyOnWriteArrayList、Vector。
Set测试内容:HashSet、LinkedHashSet、TreeSet、CopyOnWriteArraySet。
Map测试内容:HashMap、LinkedHashMap、TreeMap、WeakHashMap、ConcurrentHashMap、Hashtable。
Queue测试内容:PriorityQueue、ArrayBlockingQueue、LinkedBlockingQueue、ConcurrentLinkedQueue、SynchronousQueue、ArrayDeque、LinkedBlockingDeque和ConcurrentLinkedDeque。
注1:static内部类需要实现序列化接口。
注2:外部类需要实现序列化接口。
注3:需要在Lambda表达式前添加(IXxx & Serializable)。
由于Protobuf、Thrift是IDL定义类文件,然后使用各自的编译器生成Java代码。IDL没有提供定义staic内部类、非static内部类等语法,所以这些功能无法测试。
阿里云开发者社区
世界读书日,来读书吧
4月23日是第26个世界读书日,阿里云开发者社区推出“记录阅读之路,影响同行之人”活动,6位阿里技术人为同学们分享他们看过的好书,开发者藏经阁也推出了最受大家欢迎的电子书。
点击“阅读原文”,推荐曾经影响你的书,来一起读书吧~
以上是关于Java开发框架选型对比:ruoyi与yudao框架的主要内容,如果未能解决你的问题,请参考以下文章