一点就分享系列(实践篇5-上篇)[持续更新中!代码已吸收!依旧全网首发] yolov7解析:yolov5的plus扩充 ,仍旧值得学习!一起看V5代码如何变成V7!
Posted 啥都会一点的老程,自在地镜强者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一点就分享系列(实践篇5-上篇)[持续更新中!代码已吸收!依旧全网首发] yolov7解析:yolov5的plus扩充 ,仍旧值得学习!一起看V5代码如何变成V7!相关的知识,希望对你有一定的参考价值。
一点就分享系列(实践篇5-上篇)[持续更新!全网首发]yolov7解析
一点就分享系列(实践篇5-下篇)依旧全网首发—Yolov5项目爆肝升级High-level集结!逐一任务介绍,附赠模型通用修改方法和部署教程。
近期为什么不更新?
因为在做别的方向的探索,比如动捕 、抠图、nerf等任务的学习,所以检测研究会停滞、毕竟这年头不能只搞high-level
新闻版块【实时更新说明和近期计划】---->>项目地址
2022/9/30 项目更新内容移步—>>>>>>>该章节实践篇5-下篇
2022/9/25 更新内容
0. High-levlel 检测、分类、分割、关键点检测功能模块整合完成,移步GIT或者最新博客
1.分割代码结合V5和V7的代码进行了合并DEBUG调试,训练部分待验证,另外注意力层训练过程中,没法收敛或者NAN的情况,排除代码问题,需要在超参文件yaml里,先对学习衰减率从0.1变成0.2 ,比如GAM,因为用了注意力头训练周期加到400EPOCH左右就可以训练。
2.去年的decoupled结构虽然能提点,不过FLOPS增加的太多,目前用V5作者分支的解耦头替换,效果待验证。
3.融合了代码做了部分的优化,这里看了下V7的代码优化较差,后续会集成精简版本的分类、分割、检测、POSE检测的结构,目前已经完成了一部分工作,更新频繁有问题欢迎反馈和提供实验结果。
前言
yolov7来了,话不多说,强行回归,之前提到的一些nanodet/yolox的优化技巧,没想到V7也做了,这样挺好,减少了不少工作量,大体今天上午看了下主要是两部分核心:网络结构和辅助训练分支,从V7仓库适配了下代码,才发现缝合度极度严重,其实就是魔改版的V5,不过仍旧有值得学习的东西,同时想起V6(mt),让我明白一个道理:做事情一定要快!于是下午我就把V7之于V5的区别对比了下,并基于我自己的魔改版V5仓库进行了V7的添加,基本全程没什么大坑,还是比较容易的,分享在我的github上,代码是集成好的。目前V7其实是没有V5一些代码细节更好的,代码和文章持续更新请放心!还是有不少优化的地方,(还是老规矩:有问题留言或者私信,比较急的挂git issue,最近更新频繁,有问题在所难免)
后续打脸~!7月22号了!,每天都要花几个小时调试源码,更新博客会慢很多,还是以GIT上程序为主吧,由于V7本身存在很多BUG也是一直修复,加上我适配V5后有些代码冲突,也是不停在修改,光在这搬砖的,目前大部分的训练各种V7结构的模型BUG都修复了,再就是V7官方就现在还在改BUG呢,所以大家也谅解下,V5作者是不断优化代码,因此我还是以V5的代码优化为基准出发。*
基于最新的YOLOV5定期更新的,为什么要用yolov5修改?
1. 因为v7也是基于某一时间的V5代码上基础改的(因为这个作者的YOLOR当初也是基于V5做的添加),这样更利于快速上手,事实上从代码层面来讲本来也是基于v5的,很多共同的也没必要再复述
2. yolv5不断更新工程代码的规范,优化了不少小BUG和程序的问题
3. 学习进步
4. 同样参考基于yolov5的人体姿态关键点检测的Paper以及开源。
common.py代码比较多,后续会规范整理!此时此刻,我差点想改个名字叫YOLOV5+7 =12? ,V7的yaml结构我放在了这里:
先补充下YoloV7的大致使用:
比如你想训练yolov7的P5-model直接run,注意官方将这个分离成了两部分,更直接一些。
python train.py --cfg models/v7_cfg/training/yolov7.yaml --weights yolov7.pt --data (custom datasets)
P6-modle ,run:
python train.py --cfg models/v7_cfg/training/yolov7w6.yaml --imgsz 1280 --weights 'yolov7-w6_training.pt' --data (custom datasets) --aux_ota_loss --hyp data/hyps/hyp.scratch-v7.custom.yaml
权重我挂在百度云上了!yolov7 预训练权重打包链接:yolov7 预训练权重打包链接 提取码:v7v7
请注意:由于我删除了P6模型里的Reorg操作其实就是Focus(在我看来这个操作是没必要的),所以你需要重新训练或者微调下,如果你想使用V7原始权重,你只需要在YAML里改回去
使用需知:如何重参数化YOLOV7模型
这里以yolov7为例,我们看这段提供的代码,
- 训练training/下的yaml结构后,你的初始权重 xxx_training.pt会变成xxx.pt,你需要加载训练好的权重yolov7xxx.pt,具体也可以参考重参数结构的脚本
- 然后使用deploy的模型去加载你训练的权重,改变层索引和结构,这样可以推理并且完成加速。
具体看官方tools/下的reparameterization.ipynb或者我的代码下的reparameterization.Py ,参考使用,后续会优化整理下便于使用。
nc=80
anchors=3
device = select_device('0', batch_size=1)
# model trained by cfg/training/*.yaml
# 注意这里官方给的yolov7.pt,这里会误导一些朋友出现问题,如果你用官方直接的yolov7.py是错误的,因为yolov7.pt是作者重参数的最终推理模型,头部的yoloR的key已经被移除了,你可以使用yolov7_traing.pt或者是你通过traing下的yaml所生成的权重,然后训练后会存为yolov7.pt,这个才是作者想表达的意思。
ckpt = torch.load('yolov7_training.pt', map_location=device)
# reparameterized model in cfg/deploy/*.yaml
model = Model('models/v7_cfg/deploy/yolov7.yaml', ch=3, nc=80).to(device)
#print(model)
# copy intersect weights
state_dict = ckpt['model'].float().state_dict()
exclude = []
intersect_state_dict = k: v for k, v in state_dict.items() if k in model.state_dict() and not any(x in k for x in exclude) and v.shape == model.state_dict()[k].shape
model.load_state_dict(intersect_state_dict, strict=False)
model.names = ckpt['model'].names
model.nc = ckpt['model'].nc
for i in state_dict:
print(i)
#print(intersect_state_dict)
# reparametrized YOLOR 将yolor头部的权重赋值
for i in range((model.nc+5)*anchors):
model.state_dict()['model.105.m.0.weight'].data[i, :, :, :] *= state_dict['model.105.im.0.implicit'].data[:, i, : :].squeeze()
model.state_dict()['model.105.m.1.weight'].data[i, :, :, :] *= state_dict['model.105.im.1.implicit'].data[:, i, : :].squeeze()
model.state_dict()['model.105.m.2.weight'].data[i, :, :, :] *= state_dict['model.105.im.2.implicit'].data[:, i, : :].squeeze()
model.state_dict()['model.105.m.0.bias'].data += state_dict['model.105.m.0.weight'].mul(state_dict['model.105.ia.0.implicit']).sum(1).squeeze()
model.state_dict()['model.105.m.1.bias'].data += state_dict['model.105.m.1.weight'].mul(state_dict['model.105.ia.1.implicit']).sum(1).squeeze()
model.state_dict()['model.105.m.2.bias'].data += state_dict['model.105.m.2.weight'].mul(state_dict['model.105.ia.2.implicit']).sum(1).squeeze()
model.state_dict()['model.105.m.0.bias'].data *= state_dict['model.105.im.0.implicit'].data.squeeze()
model.state_dict()['model.105.m.1.bias'].data *= state_dict['model.105.im.1.implicit'].data.squeeze()
model.state_dict()['model.105.m.2.bias'].data *= state_dict['model.105.im.2.implicit'].data.squeeze()
# model to be saved
ckpt = 'model': deepcopy(model.module if is_parallel(model) else model).half(),
'optimizer': None,
'training_results': None,
'epoch': -1
# save reparameterized model
torch.save(ckpt, 'models/v7_cfg/deploy/yolov7.pt')
(如果代码有BUG 。iussue上留言,今天被MT的V6刺激到黑化,程序是有CI 原则上不会有大问题,后续会完善额外的模型CI)
一点就分享系列(实践篇5-上篇)
- 一点就分享系列(实践篇5-上篇)[持续更新!全网首发]yolov7解析
- 一点就分享系列(实践篇5-下篇)依旧全网首发—Yolov5项目爆肝升级High-level集结!逐一任务介绍,附赠模型通用修改方法和部署教程。
- <font color=#333AAA >新闻版块【实时更新说明和近期计划】---->>[项目地址](https://github.com/positive666/yolov5_research)
- 前言
- 使用需知:如何重参数化YOLOV7模型
- 一句话综述yolov7到底是什么!
- 再次强调注意事项:
- 一、模型结构--->保持性能,提升速度
一句话综述yolov7到底是什么!
千篇一律的东西我不想做,因为能看这个文章的人,基本都看过YOLOV5了,那么为什么我说yolov7只是yolov5的plus?
最直接的就是从git代码上可以看出基本是“”集百家之所长",代码大概是今年5月份yolov5的版本基础上结合了自己的修改(别问我为什么知道,每周维护更新!),那么我很有底气的可以量化来说,同时也为后续大家看yolov7打通整体思路,一句话总结:
yolov7的代码= 5月之前的yolov5工程版本基础上+ v7作者YOLOR的改进(YOLOV4的AB佬)+总结新的重参数网络结构和算子/加入最近才开源的swinv2等算子结构+辅助检测分支/对应的LOSS标签匹配策略+模型结构的增加和解析引起的代码调整,包含初始化权重参数、优化器等
带来了性能的提升以及FLOPS的增加,最终综合来看还是一次进化,一些问题,比如调整NMS等一些参数和Trick在数据集上产生虚高精度,这里不过多讨论,本篇宗旨:抱着学习的态度去积累
通过看代码,可以看出V7还在做实验来验证一些结构,其次其实主体就是这些区别,接下来就是细化yolov7的各个细节,这部分可以慢慢在整理,梳理和总结学习。
yolov7存在过高的flops,但是仍旧具备不错的推理速度,完全依赖于重参数结构,让我们看看模型结构。
再次强调注意事项:
我的GIT加入的YOLOV7也是不断更新的,但是代码并不和V7完全一模一样,因为代码还在不断更新所以我举个例子:
比如V7的P6结构中,REORG我删除了,因为这FOCUS一样,所以我这部分还是使用YOLOV5的[-1, 1, Conv, [64, 6, 2, 2] 去替代Reorg,所以需要自己从新训练下模型。
一、模型结构—>保持性能,提升速度
1. 核心改动一V7的核心结构-RepVgg
设计初衷:结构重参数化,解耦训练和推理的逻辑,提升最终的推理速度和优化内存,先补一下regvgg的背景吧,其实这里也可以看出做轻量化模型设计的最近很火的一个思想就是降低mac!
3x3卷积非常快。在GPU上,3x3卷积的计算密度(理论运算量除以所用时间)可达1x1和5x5卷积的四倍。
单路架构非常快,因为并行度高。同样的计算量,“大而整”的运算效率远超“小而碎”的运算。
单路架构省内存。例如,ResNet的shortcut虽然不占计算量,却增加了一倍的显存占用。
单路架构灵活性更好,容易改变各层的宽度(如剪枝)。
训练时候是多分支,推理时候为单路结构,这样降低mac成本,再结合3X3卷积在GPU上的速度优势,RepVgg的block每层都加了平行的1x1卷积分支和恒等映射分支,这里和resnet不完全一样。
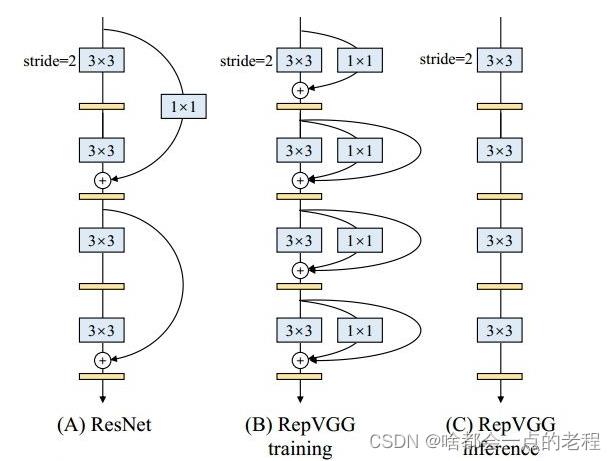
然后核心就是如何从多分支转为单路用于推理部署,来看看REPVGG怎么做的?
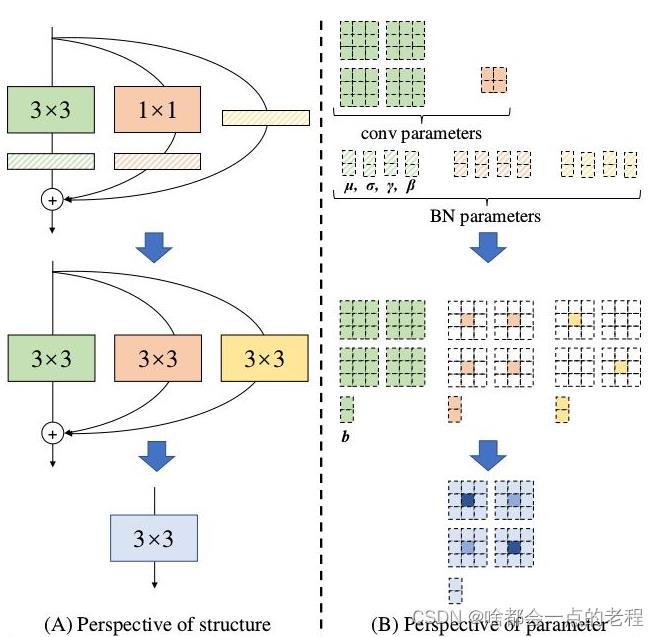
(先声明下,算子融合这部分torch都是有实现的)
- conv和BN融合,这个老生常谈, 融合过程是conv带有bias的,目的就是推理时候进行加速
- 1x1和3x3卷积融合,如何对齐?
以3X3卷积为基准,因为1x1的Conv等价于卷积核多个0的3X3卷积,而indentity相当于单位矩阵的1x1卷积,那么同样等价于3x3卷积.
只需要把1x1的卷积padding成3x3的卷积就行,这样就可以完成single_path - 总体融合
在3x3的卷积形式上对齐后,我们可以进行直接融合即对应相加。激活函数RELU因为涉及到数值精度,应该需要量化,所以没有融合激活函数。 - 检测头融合
yolov7的结构一部分是在yolor的基础上构建的,那么作者最近释放出了yolov7的检测头融合部分。
为了便于大家理解,我们先看下conv和bn的融合代码,

对照融合后的计算公式和代码,本质上还是卷积的线性计算,所以同理这个模型里的操作都可以转化。
def fuse_conv_and_bn(conv, bn):
# Fuse Conv2d() and BatchNorm2d() layers https://tehnokv.com/posts/fusing-batchnorm-and-conv/
fusedconv = nn.Conv2d(conv.in_channels,
conv.out_channels,
kernel_size=conv.kernel_size,
stride=conv.stride,
padding=conv.padding,
groups=conv.groups,
bias=True).requires_grad_(False).to(conv.weight.device)
# Prepare filters
w_conv = conv.weight.clone().view(conv.out_channels, -1)
w_bn = torch.diag(bn.weight.div(torch.sqrt(bn.eps + bn.running_var))) # 得到融合计算的第一项权重项
fusedconv.weight.copy_(torch.mm(w_bn, w_conv).view(fusedconv.weight.shape))# #压缩维度拷贝权重
# Prepare spatial bias# 得到融合计算的第二项权重项
b_conv = torch.zeros(conv.weight.size(0), device=conv.weight.device) if conv.bias is None else conv.bias #判断有无bias初始化
b_bn = bn.bias - bn.weight.mul(bn.running_mean).div(torch.sqrt(bn.running_var + bn.eps))# 得到融合计算的第二项偏置项
fusedconv.bias.copy_(torch.mm(w_bn, b_conv.reshape(-1, 1)).reshape(-1) + b_bn) ## 得到融合计算的组合权重和偏置项=融合的计算公式
return fusedconv
那么同理,我们可以类比其他的融合思路和形式。
其实以上思路就是跟tensorrt的网络加速优化有类似的地方,只不过trt做了更多的变换,包含激活函数的融合,垂直和水平融合,包含取消一些没必要的层比如concat。
总结repvgg,等效结构变换带来推理速度的质变,值得学习,参考TRT的融合或许可以做的更好。
yolov7的论文中对这个结构进行了再一次的调整,为了缓解dense网络的性能下降问题,如图:
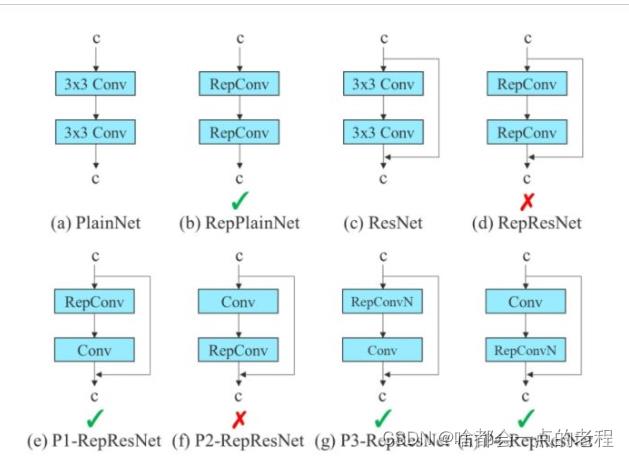
使用(b)中的RepConv的Block,没有并行分支,作者团队发现有的identity 连接是不需要,并且不需要在conv和repconv直接进行indentity,这也算贡献吧,然后我们以yolov7中的几个yaml来熟悉下其结构,因为网络结构是IDetect ,是有yolor的结构
这里再概述下:YOLOV7的深层p6版本最后头部选用了基于yolor和aux辅助检测层的变体,来提升性能,【代码的话比较长!到现在了,我相信这种基础的模块代码大家都能看得明白,至于其中的SPPCSPC等结构的卷积、池化计算大家直接看源码】,直接上仓库的代码链接:common.py算子块,现在请大家仔细看下这个"训练版本"yaml的结构!
# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# anchors
anchors:
- [12,16, 19,36, 40,28] # P3/8
- [36,75, 76,55, 72,146] # P4/16
- [142,110, 192,243, 459,401] # P5/32
# yolov7 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [32, 3, 1]], # 0
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [128, 3, 2]], # 3-P2/4
[-1, 1, Conv, [64, 1, 1]],
[-2, 1, Conv, [64, 1, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 11
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 16-P3/8
[-1, 1, Conv, [128, 1, 1]],
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]], # 24
[-1, 1, MP, []],
[-1, 1, Conv, [256, 1, 1]],
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 29-P4/16
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [1024, 1, 1]], # 37
[-1, 1, MP, []],
[-1, 1, Conv, [512, 1, 1]],
[-3, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [512, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 42-P5/32
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [1024, 1, 1]], # 50
]
# yolov7 head
head:
[[-1, 1, SPPCSPC, [512]], # 51
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[37, 1, Conv, [256, 1, 1]], # route backbone P4
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 63
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[24, 1, Conv, [128, 1, 1]], # route backbone P3
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1]],
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
简介:本篇是微服务高可用最佳实践系列分享的开篇,系列内容持续更新中,期待大家的关注。
作者:三辰|阿里云云原生微服务基础架构团队技术专家,负责 MSE 引擎高可用架构
本篇是微服务高可用最佳实践系列分享的开篇,系列内容持续更新中,期待大家的关注。
引言
在开始正式内容之前,先给大家分享一个真实的案例。
某客户在阿里云上使用 K8s 集群部署了许多自己的微服务,但是某一天,其中一台节点的网卡发生了异常,最终导致服务不可用,无法调用下游,业务受损。
我们来看一下这个问题链是如何形成的?
- ECS 故障节点上运行着 K8s 集群的核心基础组件 CoreDNS 的所有 Pod,它没有打散,导致集群 DNS 解析出现问题。
- 该客户的服务发现使用了有缺陷的客户端版本(nacos-client 的 1.4.1 版本),这个版本的缺陷就是跟 DNS 有关——心跳请求在域名解析失败后,会导致进程后续不会再续约心跳,只有重启才能恢复。
- 这个缺陷版本实际上是已知问题,阿里云在 5 月份推送了 nacos-client 1.4.1 存在严重 bug 的公告,但客户研发未收到通知,进而在生产环境中使用了这个版本。

风险环环相扣,缺一不可。
最终导致故障的原因是服务无法调用下游,可用性降低,业务受损。下图示意的是客户端缺陷导致问题的根因:

- Provider 客户端在心跳续约时发生 DNS 异常;
- 心跳线程正确地处理这个 DNS 异常,导致线程意外退出了;
- 注册中心的正常机制是,心跳不续约,30 秒后自动下线。由于 CoreDNS 影响的是整个 K8s 集群的 DNS 解析,所以 Provider 的所有实例都遇到相同的问题,整个服务所有实例都被下线;
- 在 Consumer 这一侧,收到推送的空列表后,无法找到下游,那么调用它的上游(比如网关)就会发生异常。
回顾整个案例,每一环每个风险看起来发生概率都很小,但是一旦发生就会造成恶劣的影响。
所以,本篇文章就来探讨,微服务领域的高可用方案怎么设计,细化到服务发现和配置管理领域,都有哪些具体的方案。
微服务高可用方案
首先,有一个事实不容改变:没有任何系统是百分百没有问题的,所以高可用架构方案就是面对失败(风险)设计的。
风险是无处不在的,尽管有很多发生概率很小很小,却都无法完全避免。
在微服务系统中,都有哪些风险的可能?

这只是其中一部分,但是在阿里巴巴内部十几年的微服务实践过程中,这些问题全部都遇到过,而且有些还不止一次。
虽然看起来坑很多,但我们依然能够很好地保障双十一大促的稳定,背后靠的就是成熟稳健的高可用体系建设。
我们不能完全避免风险的发生,但我们可以控制它(的影响),这就是做高可用的本质。
控制风险有哪些策略?
注册配置中心在微服务体系的核心链路上,牵一发动全身,任何一个抖动都可能会较大范围地影响整个系统的稳定性。
策略一:缩小风险影响范围
集群高可用
多副本:不少于 3 个节点进行实例部署。多可用区(同城容灾):将集群的不同节点部署在不同可用区(AZ)中。当节点或可用区发生的故障时,影响范围只是集群其中的一部分,如果能够做到迅速切换,并将故障节点自动离群,就能尽可能减少影响。
减少上下游依赖
系统设计上应该尽可能地减少上下游依赖,越多的依赖,可能会在被依赖系统发生问题时,让整体服务不可用(一般是一个功能块的不可用)。如果有必要的依赖,也必须要求是高可用的架构。
变更可灰度
新版本迭代发布,应该从最小范围开始灰度,按用户、按 Region 分级,逐步扩大变更范围。一旦出现问题,也只是在灰度范围内造成影响,缩小问题爆炸半径。
服务可降级、限流、熔断
- 注册中心异常负载的情况下,降级心跳续约时间、降级一些非核心功能等
- 针对异常流量进行限流,将流量限制在容量范围内,保护部分流量是可用的
- 客户端侧,异常时降级到使用本地缓存(推空保护也是一种降级方案),暂时牺牲列表更新的一致性,以保证可用性

如图,微服务引擎 MSE 的同城双活三节点的架构,经过精简的上下游依赖,每一个都保证高可用架构。多节点的 MSE 实例,通过底层的调度能力,会自动分配到不同的可用区上,组成多副本集群。
策略二:缩短风险发生持续时间
核心思路就是:尽早识别、尽快处理
识别 —— 可观测
例如,基于 Prometheus 对实例进行监控和报警能力建设。

进一步地,在产品层面上做更强的观测能力:包括大盘、告警收敛/分级(识别问题)、针对大客户的保障、以及服务等级的建设。
MSE注册配置中心目前提供的服务等级是 99.95%,并且正在向 4 个 9(99.99%)迈进。
快速处理 —— 应急响应
应急响应的机制要建立,快速有效地通知到正确的人员范围,快速执行预案的能力(意识到白屏与黑屏的效率差异),常态化地进行故障应急的演练。
预案是指不管熟不熟悉你的系统的人,都可以放心执行,这背后需要一套沉淀好有含金量的技术支撑(技术厚度)。
策略三:减少触碰风险的次数
减少不必要的发布,例如:增加迭代效率,不随意发布;重要事件、大促期间进行封网。
从概率角度来看,无论风险概率有多低,不断尝试,风险发生的联合概率就会无限趋近于 1。
策略四:降低风险发生概率
架构升级,改进设计
Nacos2.0,不仅是性能做了提升,也做了架构上的升级:
- 升级数据存储结构,Service 级粒度提升到到 Instance 级分区容错(绕开了 Service 级数据不一致造成的服务挂的问题);
- 升级连接模型(长连接),减少对线程、连接、DNS 的依赖。
提前发现风险
- 这个「提前」是指在设计、研发、测试阶段尽可能地暴露潜在风险;
- 提前通过容量评估预知容量风险水位是在哪里;
- 通过定期的故障演练提前发现上下游环境风险,验证系统健壮性。

如图,阿里巴巴大促高可用体系,不断做压测演练、验证系统健壮性和弹性、观测追踪系统问题、验证限流、降级等预案的可执行性。
服务发现高可用方案
服务发现包含服务消费者(Consumer)和服务提供者(Provider)。
Consumer 端高可用
通过推空保护、服务降级等手段,达到 Consumer 端的容灾目的。
推空保护
可以应对开头讲的案例,服务空列表推送自动降级到缓存数据。
服务消费者(Consumer)会从注册中心上订阅服务提供者(Provider)的实例列表。
当遇到突发情况(例如,可用区断网,Provider端无法上报心跳) 或 注册中心(变配、重启、升降级)出现非预期异常时,都有可能导致订阅异常,影响服务消费者(Consumer)的可用性。

无推空保护
- Provider 端注册失败(比如网络、SDKbug 等原因)
- 注册中心判断 Provider 心跳过期
- Consumer 订阅到空列表,业务中断报错
开启推空保护
- 同上
- Consumer 订阅到空列表,推空保护生效,丢弃变更,保障业务服务可用
开启方式
开启方式比较简单
开源的客户端 nacos-client 1.4.2 以上版本支持
配置项
- SpingCloudAlibaba 在 spring 配置项里增加:
spring.cloud.nacos.discovery.namingPushEmptyProtection=true - Dubbo 加上 registryUrl 的参数:
namingPushEmptyProtection=true
提空保护依赖缓存,所以需要持久化缓存目录,避免重启后丢失,路径为:$user.home/nacos/naming/$namespaceId
服务降级
Consumer 端可以根据不同的策略选择是否将某个调用接口降级,起到对业务请求流程的保护(将宝贵的下游 Provider 资源保留给重要的业务 Consumer 使用),保护重要业务的可用性。

服务降级的具体策略,包含返回 Null 值、返回 Exception 异常、返回自定义 JSON 数据和自定义回调。
MSE 微服务治理中心中默认就具备该项高可用能力。
Provider 端高可用
Provider 侧通过注册中心和服务治理提供的容灾保护、离群摘除、无损下线等方案提升可用性。
容灾保护
容灾保护主要用于避免集群在异常流量下出现雪崩的场景。
下面我们来具体看一下:

无容灾保护(默认阈值 =0)
- 突发请求量增加,容量水位较高时,个别 Provider 发生故障;
- 注册中心将故障节点摘除,全量流量会给剩余节点;
- 剩余节点负载变高,大概率也会故障;
- 最后所有节点故障,100% 无法提供服务。
开启容灾保护(阈值=0.6)
- 同上;
- 故障节点数达到保护阈值,流量平摊给所有机器;
- 最终保障 50% 节点能够提供服务。
容灾保护能力,在紧急情况下,能够保存服务可用性在一定的水平之上,可以说是整体系统的兜底了。
这套方案曾经救过不少业务系统。
离群实例摘除
心跳续约是注册中心感知实例可用性的基本途径。
但是在特定情况下,心跳存续并不能完全等同于服务可用。
因为仍然存在心跳正常,但服务不可用的情况,例如:
- Request 处理的线程池满
- 依赖的 RDS 连接异常或慢 SQL
微服务治理中心提供离群实例摘除
- 基于异常检测的摘除策略:包含网络异常和网络异常 + 业务异常(HTTP 5xx)
- 设置异常阈值、QPS 下限、摘除比例下限
离群实例摘除的能力是一个补充,根据特定接口的调用异常特征,来衡量服务的可用性。
无损下线
无损下线,又叫优雅下线、或者平滑下线,都是一个意思。首先看什么是有损下线:
Provider 实例进行升级过程中,下线后心跳在注册中心存约以及变更生效都有一定的时间,在这个期间 Consumer 端订阅列表仍然没有更新到下线后的版本,如果鲁莽地将 Provider 停止服务,会造成一部分的流量损失。
无损下线有很多不同的解决方案,但侵入性最低的还是服务治理中心默认提供的能力,无感地整合到发布流程中,完成自动执行。免去繁琐的运维脚本逻辑的维护。
配置管理高可用方案
配置管理主要包含配置订阅和配置发布两类操作。
配置管理解决什么问题?
多环境、多机器的配置发布、配置动态实时推送。
基于配置管理做服务高可用
微服务如何基于配置管理做高可用方案?
发布环境管理
一次管理上百台机器、多套环境,如何正确无误地推送、误操作或出现线上问题如何快速回滚,发布过程如何灰度。
业务开关动态推送
功能、活动页面等开关。
容灾降级预案的推送
预置的方案通过推送开启,实时调整流控阈值等。

上图是大促期间配置管理整体高可用解决方案。比如降级非核心业务、功能降级、日志降级、禁用高风险操作。
客户端高可用
配置管理客户端侧同样有容灾方案。
本地目录分为两级,高优先级是容灾目录、低优先级是缓存目录。
缓存目录:每次客户端和配置中心进行数据交互后,会保存最新的配置内容至本地缓存目录中,当服务端不可用状态下,会使用本地缓存目录中内容。
容灾目录:当服务端不可用状态下,可以在本地的容灾目录中手动更新配置内容,客户端会优先加载容灾目录下的内容,模拟服务端变更推送的效果。

简单来说,当配置中心不可用时,优先查看容灾目录的配置,否则使用之前拉取到的缓存。
容灾目录的设计,是因为有时候不一定会有缓存过的配置,或者业务需要紧急覆盖使用新的内容开启一些必要的预案和配置。
整体思路就是,无法发生什么问题,无论如何,都要能够使客户端能够读取到正确的配置,保证微服务的可用性。
服务端高可用
在配置中心侧,主要是针对读、写的限流。
限制连接数、限制写:
- 限连接:单机最大连接限流,单客户端 IP 的连接限流
- 限写接口:发布操作&特定配置的秒级分钟级数量限流
控制操作风险
控制人员做配置发布的风险。
配置发布的操作是可灰度、可追溯、可回滚的。
配置灰度

发布历史&回滚

变更对比

动手实践
最后我们一起来做一个实践。
场景取自前面提到的一个高可用方案,在服务提供者所有机器发生注册异常的情况下,看服务消费者在推空保护打开的情况下的表现。
实验架构和思路

上图是本次实践的架构,右侧是一个简单的调用场景,外部流量通过网关接入,这里选择了 MSE 产品矩阵中的云原生网关,依靠它提供的可观测能力,方便我们观察服务调用情况。
网关的下游有 A、B、C 三个应用,支持使用配置管理的方式动态地将调用关系连接起来,后面我们会实践到。
基本思路:
- 部署服务,调整调用关系是网关->A->B->C,查看网关调用成功率。
- 通过模拟网络问题,将应用B与注册中心的心跳链路断开,模拟注册异常的发生。
- 再次查看网关调用成功率,期望服务 A->B 的链路不受注册异常的影响。
为了方便对照,应用 A 会部署两种版本,一种是开启推空保护的,一种是没有开启的情况。
最终期望的结果是,推空保护开关开启后,能够帮助应用 A 在发生异常的情况下,继续能够寻址到应用B。
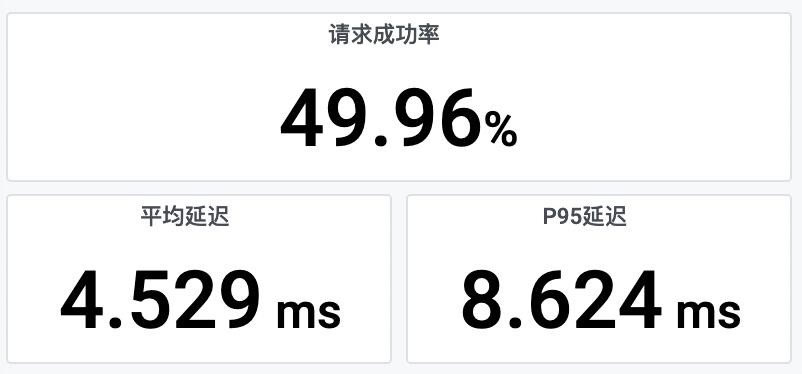
网关的流量打到应用 A 之后,可以观察到,接口的成功率应该正好在 50%。
开始
接下来开始动手实践吧。这里我选用阿里云 MSE+ACK 组合做完整的方案。
环境准备
首先,购买好一套 MSE 注册配置中心专业版,和一套 MSE 云原生网关。这边不介绍具体的购买流程。
在应用部署前,提前准备好配置。这边我们可以先配置 A 的下游是 C,B 的下游也是 C。

部署应用
接下来我们基于 ACK 部署三个应用。可以从下面的配置看到,应用 A 这个版本 spring-cloud-a-b,推空保护开关已经打开。

这里 demo 选用的 nacos 客户端版本是 1.4.2,因为推空保护在这个版本之后才支持。
配置示意(无法直接使用):
# A 应用 base 版本
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: spring-cloud-a
name: spring-cloud-a-b
spec:
replicas: 2
selector:
matchLabels:
app: spring-cloud-a
template:
metadata:
annotations:
msePilotCreateAppName: spring-cloud-a
labels:
app: spring-cloud-a
spec:
containers:
- env:
- name: LANG
value: C.UTF-8
- name: spring.cloud.nacos.discovery.server-addr
value: mse-xxx-nacos-ans.mse.aliyuncs.com:8848
- name: spring.cloud.nacos.config.server-addr
value: mse-xxx-nacos-ans.mse.aliyuncs.com:8848
- name: spring.cloud.nacos.discovery.metadata.version
value: base
- name: spring.application.name
value: sc-A
- name: spring.cloud.nacos.discovery.namingPushEmptyProtection
value: "true"
image: mse-demo/demo:1.4.2
imagePullPolicy: Always
name: spring-cloud-a
ports:
- containerPort: 8080
protocol: TCP
resources:
requests:
cpu: 250m
memory: 512Mi
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: spring-cloud-a
name: spring-cloud-a
spec:
replicas: 2
selector:
matchLabels:
app: spring-cloud-a
template:
metadata:
annotations:
msePilotCreateAppName: spring-cloud-a
labels:
app: spring-cloud-a
spec:
containers:
- env:
- name: LANG
value: C.UTF-8
- name: spring.cloud.nacos.discovery.server-addr
value: mse-xxx-nacos-ans.mse.aliyuncs.com:8848
- name: spring.cloud.nacos.config.server-addr
value: mse-xxx-nacos-ans.mse.aliyuncs.com:8848
- name: spring.cloud.nacos.discovery.metadata.version
value: base
- name: spring.application.name
value: sc-A
image: mse-demo/demo:1.4.2
imagePullPolicy: Always
name: spring-cloud-a
ports:
- containerPort: 8080
protocol: TCP
resources:
requests:
cpu: 250m
memory: 512Mi
# B 应用 base 版本
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: spring-cloud-b
name: spring-cloud-b
spec:
replicas: 2
selector:
matchLabels:
app: spring-cloud-b
strategy:
template:
metadata:
annotations:
msePilotCreateAppName: spring-cloud-b
labels:
app: spring-cloud-b
spec:
containers:
- env:
- name: LANG
value: C.UTF-8
- name: spring.cloud.nacos.discovery.server-addr
value: mse-xxx-nacos-ans.mse.aliyuncs.com:8848
- name: spring.cloud.nacos.config.server-addr
value: mse-xxx-nacos-ans.mse.aliyuncs.com:8848
- name: spring.application.name
value: sc-B
image: mse-demo/demo:1.4.2
imagePullPolicy: Always
name: spring-cloud-b
ports:
- containerPort: 8080
protocol: TCP
resources:
requests:
cpu: 250m
memory: 512Mi
# C 应用 base 版本
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: spring-cloud-c
name: spring-cloud-c
spec:
replicas: 2
selector:
matchLabels:
app: spring-cloud-c
template:
metadata:
annotations:
msePilotCreateAppName: spring-cloud-c
labels:
app: spring-cloud-c
spec:
containers:
- env:
- name: LANG
value: C.UTF-8
- name: spring.cloud.nacos.discovery.server-addr
value: mse-xxx-nacos-ans.mse.aliyuncs.com:8848
- name: spring.cloud.nacos.config.server-addr
value: mse-xxx-nacos-ans.mse.aliyuncs.com:8848
- name: spring.application.name
value: sc-C
image: mse-demo/demo:1.4.2
imagePullPolicy: Always
name: spring-cloud-c
ports:
- containerPort: 8080
protocol: TCP
resources:
requests:
cpu: 250m
memory: 512Mi
部署应用:
在网关注册服务
应用部署好之后,在 MSE 云原生网关中,关联上 MSE 的注册中心,并将服务注册进来。

我们设计的是网关只调用 A,所以只需要将 A 放进来注册进来即可。

验证和调整链路
基于 curl 命令验证一下链路:
$ curl http://$网关IP/ip
sc-A[192.168.1.194] --> sc-C[192.168.1.195]
验证一下链路。 可以看到这时候 A 调用的是 C,我们将配置做一下变更,实时地将 A 的下游改为 B。

再看一下,这时三个应用的调用关系是 ABC,符合我们之前的计划。
$ curl http://$网关IP/ip
sc-A[192.168.1.194] --> sc-B[192.168.1.191] --> sc-C[192.168.1.180]
接下来,我们通过一段命令,连续地调用接口,模拟真实场景下不间断的业务流量。
$ while true; do sleep .1 ; curl -so /dev/null http://$网关IP/ip ;done
观测调用
通过网关监控大盘,可以观察到成功率。



注入故障
一切正常,现在我们可以开始注入故障。
这里我们可以使用 K8s 的 NetworkPolicy 的机制,模拟出口网络异常。
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: block-registry-from-b
spec:
podSelector:
matchLabels:
app: spring-cloud-b
ingress:
-
egress:
- to:
- ipBlock:
cidr: 0.0.0.0/0
ports:
- protocol: TCP
port: 8080
这个 8080 端口的意思是,不影响内网调用下游的应用端口,只禁用其它出口流量(比如到达注册中心的 8848 端口就被禁用了)。这里 B 的下游是 C。
网络切断后,注册中心的心跳续约不上,过一会儿(30 秒后)就会将应用 B 的所有 IP 摘除。
再次观测
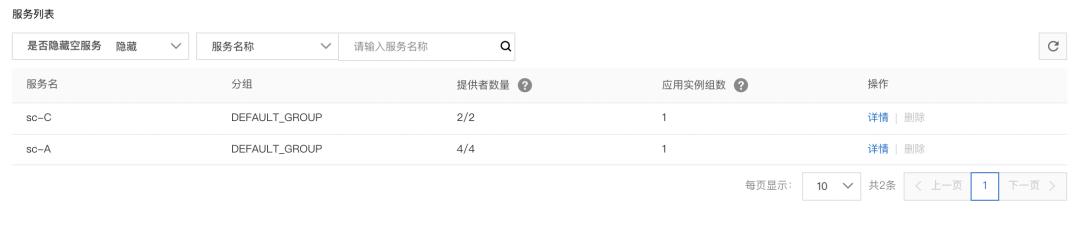
再观察大盘数据库,成功率开始下降,这时候,在控制台上已经看不到应用 B 的 IP 了。
回到大盘,成功率在 50% 附近不再波动。

小结
通过实践,我们模拟了一次真实的风险发生的场景,并且通过客户端的高可用方案(推空保护),成功实现了对风险的控制,防止服务调用的发生异常。
本文为阿里云原创内容,未经允许不得转载。