一文入门推荐系统——推荐系统实践读书笔记
Posted 白水baishui
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文入门推荐系统——推荐系统实践读书笔记相关的知识,希望对你有一定的参考价值。
《推荐系统实践》读书笔记
文章目录
1. 推荐系统
1.1. 什么是推荐系统
(1)推荐系统的定义
推荐系统(Recommendation System, RS)是一种自动联系用户和物品的工具,它能够帮助用户在信息过载的环境中发现令他们感兴趣的信息。它通常由前台的展示页面、后台的日志系统、推荐算法系统三个部分组成。
(2)为什么需要推荐系统
随着互联网上的数据越来越多,各大应用及平台坐拥海量信息,但用户却难以找到真正对自己有用的信息,用户面对庞大的数据变得毫无头绪。
目前有三大方法可以解决信息超载的问题:分类目录、搜索引擎和推荐系统:
- 分类目录
分类目录是将信息分门别类,从而方便用户根据类别进行查找。例如:优设导航 、百度更多 等门户网站。但分类目录只适合用在内容少而精的网站上,大多数分类目录网站只能涵盖少数热门信息,应用场景有限。 - 搜索引擎
用户通过在搜索引擎上输入关键字,查找自己需要的信息。例如:搜狗、Bing 等搜索引擎。但是,用户必须主动提供准确的关键词,才可能找到需要的信息。 - 推荐系统
推荐系统通过分析用户的历史行为,对用户的兴趣进行建模,从而主动给用户推荐可能满足他们需求的信息,该方法能够很好的发掘长尾信息。
我们可以看到,推荐系统相对于分类目录和搜索引擎,在某些方面有着不可替代的优势。通常认为,当一个系统满足以下两个条件时,就可以考虑应用推荐系统:
- 存在信息过载(用户难以找到想要的内容);
- 用户大多数时候没有明确的需求。
1.2. 推荐系统评测
一个完整的推荐系统包括三个参与方:
- 用户
- 网站(平台,负责搭载推荐系统)
- 内容提供方
在评测一个推荐系统时,需要考虑上述三方的利益,一个好的推荐系统是能够令三方共赢的系统。
1.2.1. 实验方法
一般来说,一个新的推荐算法最终上线,需要通过3个实验。
- 首先,通过离线实验证明它在很多离线指标上优于现有的算法;
- 其次,通过用户调查确定用户满意度不低于现有的算法;
- 最后,通过在线AB测试确定它在特定的指标上优于现有的算法;
(1)离线实验 Offline Experiment
离线实验的方法的步骤如下:
- 通过日志系统获得用户行为数据,并生成一个标准数据集;
- 将数据集分成训练集和测试集;
- 在训练集上训练用户兴趣模型,在测试集上进行预测;
- 通过事先定义的离线指标,评测算法在测试集上的预测结果。
从以上步骤看出,离线实验的都是在标准数据集上完成的。这意味着,它不需要一个实际的系统作为支撑,只需要有一个模拟环境即可。
离线实验的优缺点:
| 优点 | 缺点 |
|---|---|
| 不需要有对实际系统的控制权 | 无法计算商业上关心的指标 |
| 不需要用户参与实验 | 离线实验的指标和商业指标存在差距 |
| 速度快,可以测试大量算法 |
(2)用户调查 User Study
用户调查由真实的用户在需要测试的推荐系统上完成某些任务。在他们完成这些任务时,观察和记录他们的行为,并让他们回答一些问题。最后通过分析他们的行为和答案,了解推荐系统的性能。
用户调查的优缺点:
| 优点 | 缺点 |
|---|---|
| 可以获得用户主观感受的指标 | 招募测试用户代价较大 |
| 风险低,出错后容易弥补 | 无法组织大规模的测试用户,统计意义不足 |
| 双盲实验设计困难,导致收集的测试指标无法在真实环境下重现 |
(3)在线实验 Online Experiment
在线实验是指将系统上线做AB测试,把它和旧算法进行比较。AB测试通过一定的规则将用户随机分成几组,对不同组的用户采用不同的算法,然后通过统计不同组的评测指标,比较不同算法的好坏。
AB测试的优缺点:
| 优点 | 缺点 |
|---|---|
| 可以准确地获得不同算法的实际性能指标和商业上关注的指标 | 周期较长,必须进行长期的实验才能得到可靠的结果 |
大型网站做AB测试,可能会因为不同团队同时进行各种测试对结果造成干扰,所以切分流量是AB测试中的关键。不同的测试层以及控制这些层的团队,需要从一个统一的流量入口获得自己AB测试的流量,而不同层之间的流量应该是正交的。关于分层实验和流量正交的知识可以参考这篇博客:黄一能:什么是科学的AB测试?谈谈分层实验和流量正交
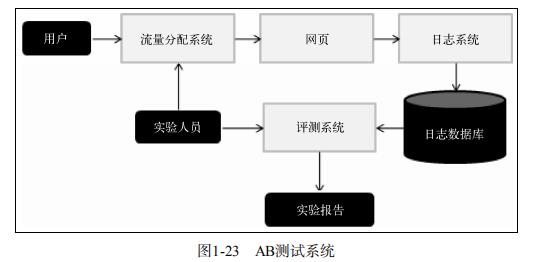
1.2.2. 评判指标
评测指标用于评测推荐系统的性能,有些可以定量计算,如预测准确度、覆盖率、多样性、实时性;有些只能定性描述,如用户满意度、新颖性、惊喜度、信任度、健壮性和商业目标。
有了这些指标,就可以根据需要对推荐系统进行优化,通常的优化目标是在给定覆盖率、多样性、新颖性等限制条件下,尽量提高预测准确度。
| 离线实验 | 问卷调查 | 在线实验 | |
|---|---|---|---|
| 用户满意度 | × | √ | √ |
| 预测准确度 | √ | √ | × |
| 覆盖率 | √ | √ | √ |
| 多样性 | √ | √ | √ |
| 新颖性 | √ | √ | √ |
| 惊喜度 | × | √ | × |
下面我们分别介绍一下这几种评测指标。
以下指标在博客:推荐系统评价指标及代码实现 中有较好的实现以及图表展示。
(1) 用户满意度
用户满意度是评测推荐系统的重要指标,无法离线计算,只能通过用户调查或者在线实验获得。
- 调查问卷的设计需要考虑周全,用户才能针对特定问题给出准确的回答;
- 在线系统中用户的满意度通过统计用户行为得到。一般情况,可以用用户点击率、停留时间、转化率等指标度量用户的满意度。
(2) 预测准确度
预测准确度是度量一个推荐系统或其中推荐算法预测用户行为的能力。 是推荐系统最重要的离线评测指标。大致可从“评分预测”和“Top-N推荐”两个方面进行评测。
评分预测
预测评分的准确度,衡量的是算法预测的评分与用户的实际评分的贴近程度,一般通过以下指标度量:
设测试集 T T T 中有用户 u u u 和物品 i i i,用 r u i r_ui rui 表示用户 u u u 对物品 i i i 的实际评分; r ^ u i \\hatr_ui r^ui 表示推荐算法给出的预测评分。则
- 平均绝对误差(MAE) M A E = ∑ ( u , i ) ∈ T ∣ r u i − r u i ′ ∣ ∣ T ∣ MAE=\\frac\\sum_(u,i)\\in T|r_ui-r_ui'||T| MAE=∣T∣∑(u,i)∈T∣rui−rui′∣
# records[i] = [u,i,rui,pui] # rui是用户u对物品i的实际评分,pui是用户u对物品i的预测评分
def mae(records):
"""计算平均绝对误差"""
return math.sqrt(sum([abs(rui-pui) for u,i,rui,pui in records])/len(records))
- 均方根误差(RMSE) R M S E = ∑ ( u , i ) ∈ T ( r u i − r ^ u i ) 2 ∣ T ∣ RMSE=\\sqrt\\frac\\sum_(u,i)\\in T(r_ui-\\hatr_ui)^2|T| RMSE=∣T∣∑(u,i)∈T(rui−r^ui)2一般而言,RMSE的误差会比MAE小
# records[i] = [u,i,rui,pui] # rui是用户u对物品i的实际评分,pui是用户u对物品i的预测评分
def rmse(records):
"""计算均方根误差"""
return math.sqrt(sum([(rui-pui)*(rui-pui) for u,i,rui,pui in records])/len(records))
Top-N推荐
如果推荐服务会给用户提供个性化的推荐列表,那么这种推荐就叫做Top-N推荐。
Top-N推荐的预测准确率,一般通过3个指标度量:
设 R ( u ) R(u) R(u) 是根据用户在训练集上的行为提供给用户的推荐列表, T ( u ) T(u) T(u) 是用户在测试集上的实际行为列表。
- 命中率 (Hits Ratio) H R = 1 ∣ U ∣ ∑ u ∈ U h i t s ( u ) HR=\\frac1|U|\\sum_u\\in Uhits(u) HR=∣U∣1u∈U∑hits(u)其中, h i t s ( i ) hits(i) hits(i)表示第 i i i个用户访问的值是否在推荐列表中,是则为1,否则为0; N N N表示用户的总数量。
- 准确率(Precision) P r e c i s i o n = ∑ u ∈ U ∣ R ( u ) ∩ T ( u ) ∣ ∑ u ∈ U ∣ R ( u ) ∣ Precision=\\frac\\sum_u\\in U|R(u)\\cap T(u)|\\sum_u\\in U|R(u)| Precision=∑u∈U∣R(u)∣∑u∈U∣R(u)∩T(u)∣
- 召回率(Recall) R e c a l l = ∑ u ∈ U ∣ R ( u ) ∩ T ( u ) ∣ ∑ u ∈ U ∣ T ( u ) ∣ Recall=\\frac\\sum_u\\in U|R(u)\\cap T(u)|\\sum_u\\in U|T(u)| Recall=∑u∈U∣T(u)∣∑u∈U∣R(u)∩T(u)∣
def HR_precision_recall(test, N):
"""
计算命中率、准确率和召回率,这里是包括了推荐和计算HR、precision、recall两个步骤,注意取舍
test: 测试集
N: 推荐列表长度
"""
hit = 0
n_recall = 0
n_precision = 0
n_user = 0
for user, items in test.items():
rank = Recommend(user, N) # 进行推荐
hit += len(rank & itmes) # 计算hit数,即HR
n_user += 1
n_precision += N # 计算precision
n_recall += len(items) # 计算recall
return [hit/(1.*n_use), hit/(1.*n_precision, hit/(1.*n_recall))]
Top-N推荐由于其个性化特性突出,因此相对于评分预测更符合实际的应用需求。
(3) 覆盖率
覆盖率(Coverage)是描述一个推荐系统对物品长尾的发掘能力。覆盖率最简单的定义是:推荐系统能够推荐出来的物品占总物品集合的比例。
假设系统的用户集合为 U U U,总物品集合为 I I I,推荐系统给每个用户推荐一个长度为 N N N 的物品推荐列表 R ( u ) R(u) R(u),覆盖率公式表达为: C o v e r a g e = ⋃ u ∈ U R ( u ) ∣ I ∣ Coverage=\\frac\\bigcup_u\\in UR(u)|I| Coverage=∣I∣⋃u∈UR(u)
覆盖率是内容提供者关心的指标,覆盖率为100%的推荐系统可以将每个物品都至少推荐给一个用户。
除了利用推荐物品的占比来定义覆盖率,还可以通过研究物品在推荐列表中出现的次数分布来描述推荐系统的挖掘长尾的能力。如果分布比较平,说明推荐系统的覆盖率很高;如果分布陡峭,说明分布系统的覆盖率较低。
信息论和经济学中有两个著名指标,可以定义覆盖率:
- 信息熵 H = − ∑ i = 1 n p ( i ) log p ( i ) H=-\\sum_i=1^np(i)\\log p(i) H=−i=1∑np(i)logp(i)其中 p ( i ) p(i) p(i)是物品 i i i的流行度除以所有物品流行度之和;
- 基尼系数(Gini Index)
G
=
1
n
以上是关于一文入门推荐系统——推荐系统实践读书笔记的主要内容,如果未能解决你的问题,请参考以下文章