内核参数调优
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了内核参数调优相关的知识,希望对你有一定的参考价值。
参考技术A net.ipv4.tcp_mem 单位是内存页,一般是4k,三个值分别代表tcp内存使用的水平,低、中、高, 低表示无内存压力,中级表示内存压力状态,高表示内存吃紧,最高峰时系统将会拒绝分配内存。262144 代表1G内存,即(262144x4/1024/1024),其他类推。下面的参数单位都是字节 net.core.wmem_max 和 net.core.wmem_default 会覆盖 net.ipv4.tcp_wmem 的第二第三个值, 同理, net.core.rmem_max 和 net.core.rmem_default 会覆盖 net.ipv4.tcp_rmem 的第二第三个值。稍微提高tcp读写缓冲区的容量,可以增加tcp传输效率,比如上文默认值131072=128k,现有一个1M的文件传输,只需8次传输即可,比较适合图片类传输。但也不是越大越好,比如一个文字页面只有15k,使用128k的内存显然有些浪费。上文tcp压力状态下的容量为2G,对应tcp读写缓冲区128k,可应对的连接数为16384 (2048x1024/128),可满足10k要求。
上面主要是tcp连接行为的伴随的参数,主要是tcp重用,增加队列,减少等待重试频率等等来提升效率。
vm.swappiness = 5 表示物理内存剩余5%时,才考虑使用swap,默认60,这显然非常不合理
vm.dirty_ratio = 40 表示拿出物理内存的40%用于写缓存,而不立即将数据写入硬盘。由于硬盘是众所周知的瓶颈,扩大它可提升写的效率,40%是个比较合适的比例。
vm.min_free_kbytes = 524288 这个用于控制剩余内存的大小,524288=512M,可根据需要调整。如果某些任务临时需要大量内存,可临时将它调大然后调小,回收页面缓存。它比vm.drop_caches 要温和得多,后者更粗暴。
vm.vfs_cache_pressure = 100 ,如果要尽快将脏数据刷进硬盘,提高它,比如150 。
net.core.somaxconn 表示socket的最大连接数,默认128,对于php-fpm使用unix socket情况下,需要调大。
net.netfilter.nf_conntrack_tcp_timeout_established = 3600 默认2天时间,多数情况下,调小这个参数是有益的,如果是tcp长连接,这个参数可能不太合适。
net.core.rps_sock_flow_entries 这个参数启用RPS,自动将网卡中断均匀分配到多个CPU,改进网卡性能和系统负载。
RPS还需要脚本配合
Linux上TCP的几个内核参数调优
Linux作为一个强大的操作系统,提供了一系列内核参数供我们进行调优。光TCP的调优参数就有50多个。在和线上问题斗智斗勇的过程中,笔者积累了一些在内网环境应该进行调优的参数。在此分享出来,希望对大家有所帮助。
调优清单
好了,在这里先列出调优清单。请记住,这里只是笔者在内网进行TCP内核参数调优的经验,仅供参考。同时,笔者还会在余下的博客里面详细解释了为什么要进行这些调优!
| 序号 | 内核参数 | 值 | 备注 |
|---|---|---|---|
| 1.1 | /proc/sys/net/ipv4/tcp_max_syn_backlog | 2048 | |
| 1.2 | /proc/sys/net/core/somaxconn | 2048 | |
| 1.3 | /proc/sys/net/ipv4/tcp_abort_on_overflow | 1 | |
| 2.1 | /proc/sys/net/ipv4/tcp_tw_recycle | 0 | NAT环境必须为0 |
| 2.2 | /proc/sys/net/ipv4/tcp_tw_reuse | 1 | |
| 3.1 | /proc/sys/net/ipv4/tcp_syn_retries | 3 | |
| 3.2 | /proc/sys/net/ipv4/tcp_retries2 | 5 | |
| 3.3 | /proc/sys/net/ipv4/tcp_slow_start_after_idle | 0 |
tcp_max_syn_backlog,somaxconn,tcp_abort_on_overflow
tcp_max_syn_backlog,somaxconn,tcp_abort_on_overflow这三个参数是关于 内核TCP连接缓冲队列的设置。如果应用层来不及将已经三次握手建立成功的TCP连接从队列中取出,溢出了这个缓冲队列(全连接队列)之后就会丢弃这个连接。如下图所示: 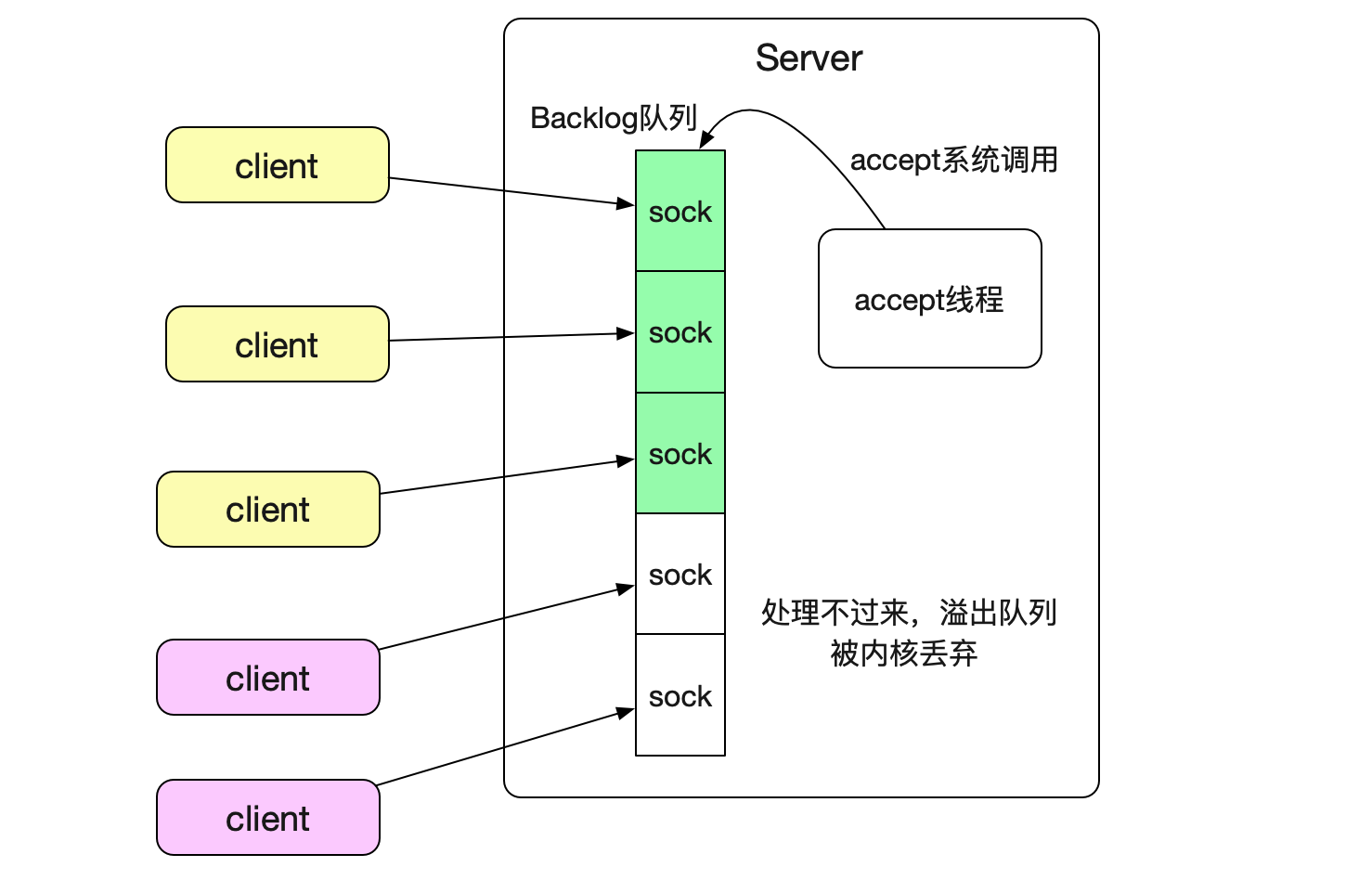
从而产生一些诡异的现象,这个现象诡异之处就在于,是在TCP第三次握手的时候丢弃连接 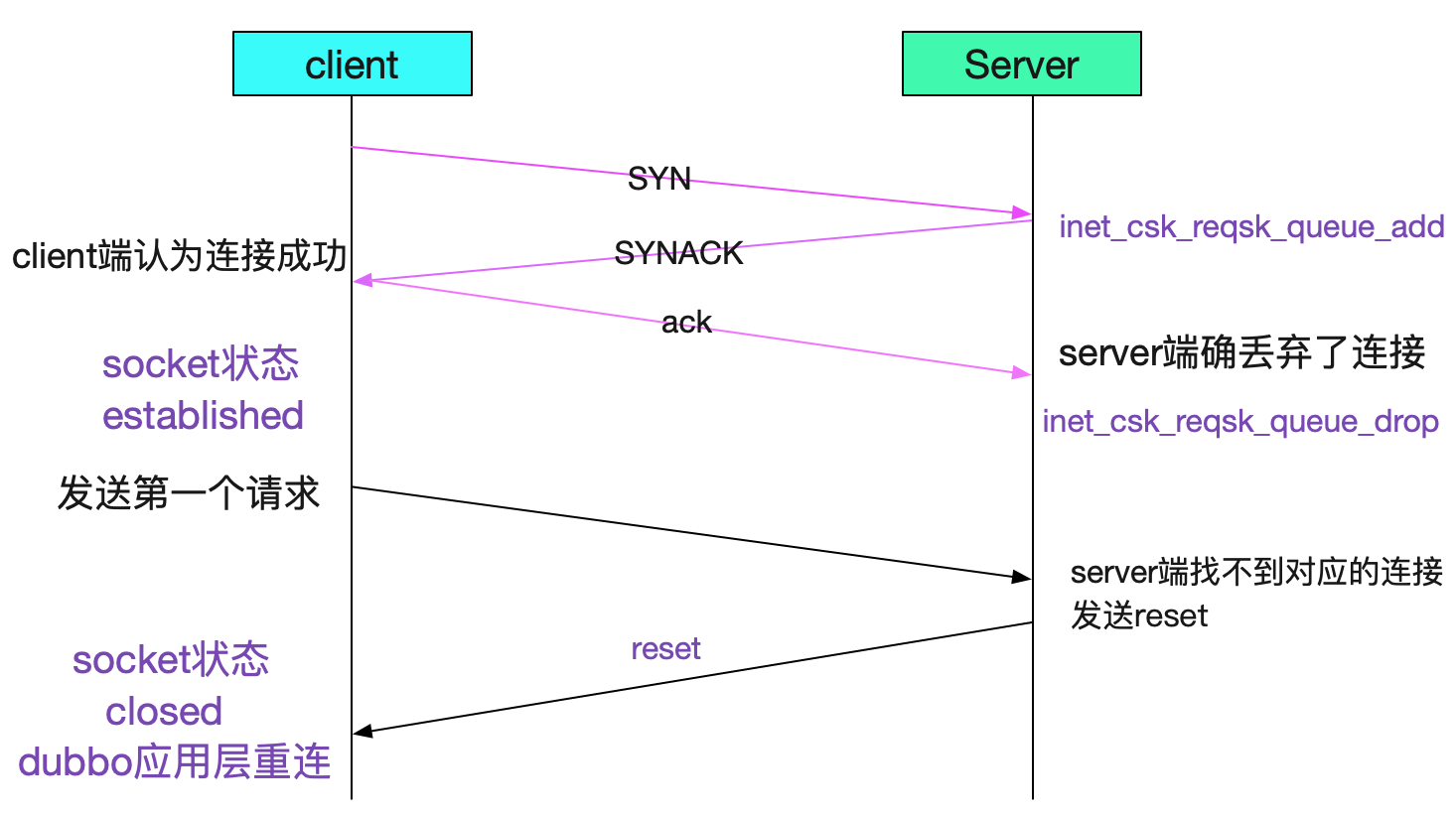
就如图中所示,第二次握手的SYNACK发送给client端了。所以就会出现client端认为连接成功,而Server端确已经丢弃了这个连接的现象!由于无法感知到Server已经丢弃了连接。 所以如果没有心跳的话,只有在发出第一个请求后,Server才会发送一个reset端通知这个连接已经被丢弃了,建立连接后第二天再用,也会报错!所以我们要调大Backlog队列!
echo 2048 > /proc/sys/net/ipv4/tcp_max_syn_backlog
echo 2048 > /proc/sys/net/core/somaxconn
当然了,为了尽量避免第一笔调用失败问题,我们也同时要设置
echo 1 > /proc/sys/net/ipv4/tcp_abort_on_overflow
设置这个值以后,Server端内核就会在这个连接被溢出之后发送一个reset包给client端。 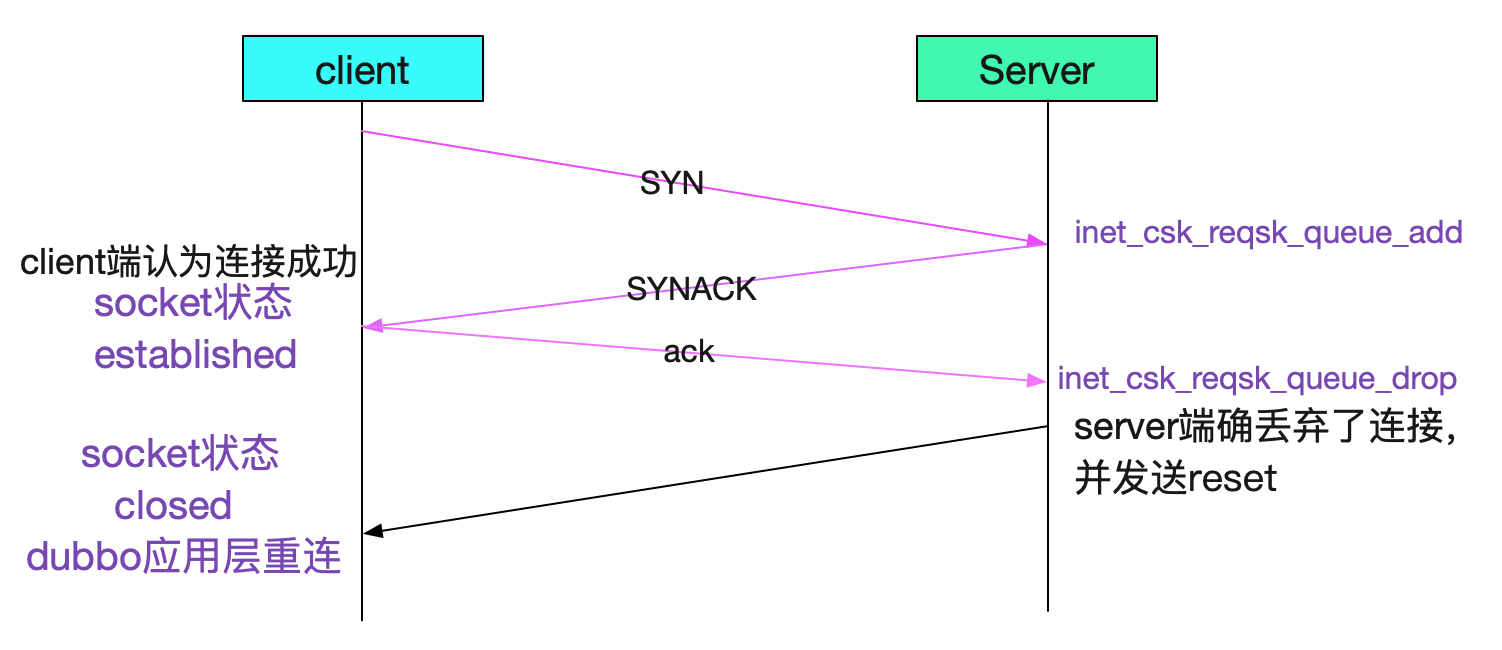
如果我们的client端是NIO的话,就可以收到一个socket close的事件以感知到连接被关闭! 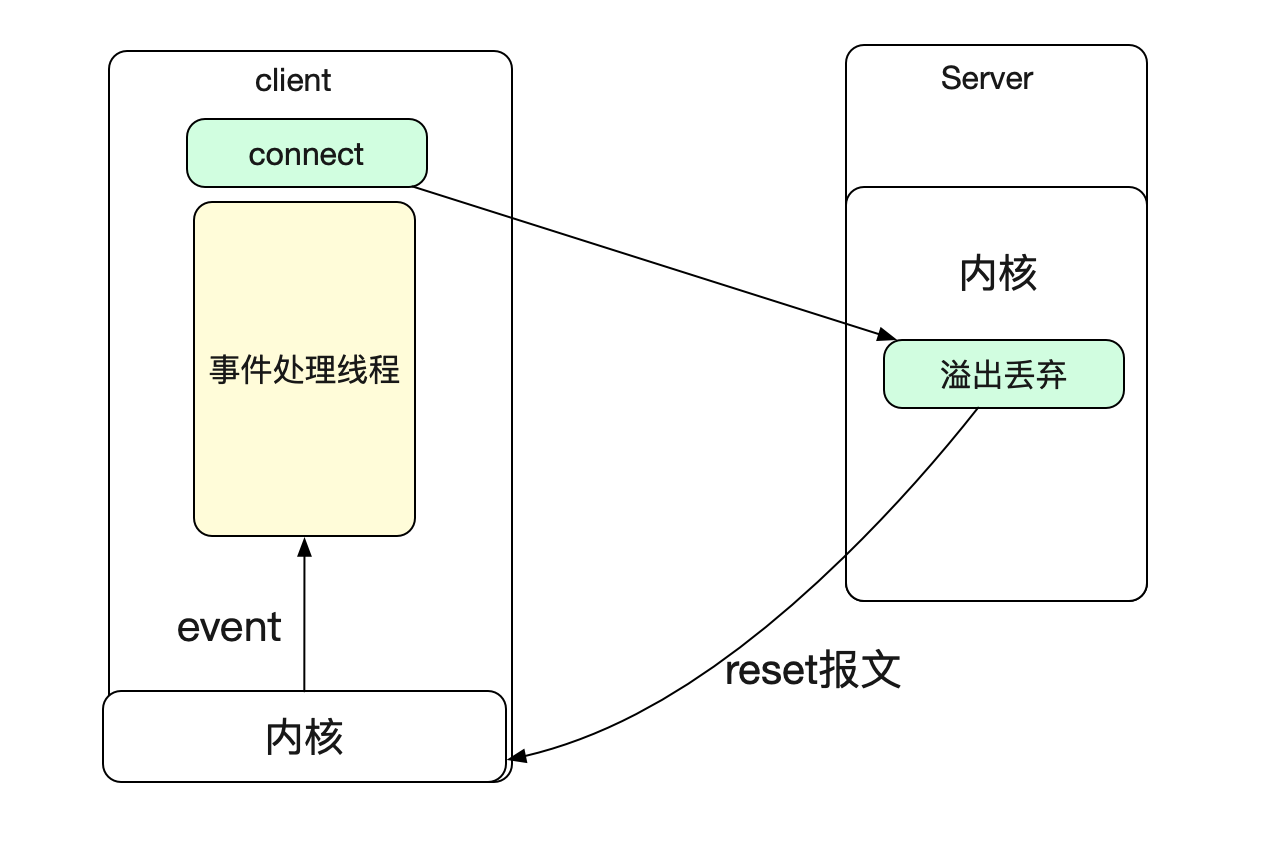
注意Java默认的Backlog是50
这个TCP Backlog的队列大小值是min(tcp_max_syn_backlog,somaxconn,应用层设置的backlog),而Java如果不做额外设置,Backlog默认值仅仅只有50。C语言在使用listen调用的时候需要传进Backlog参数。
tcp_tw_recycle
tcp_tw_recycle这个参数一般是用来抑制TIME_WAIT数量的,但是它有一个副作用。即在tcp_timestamps开启(Linux默认开启),tcp_tw_recycle会经常导致下面这种现象。 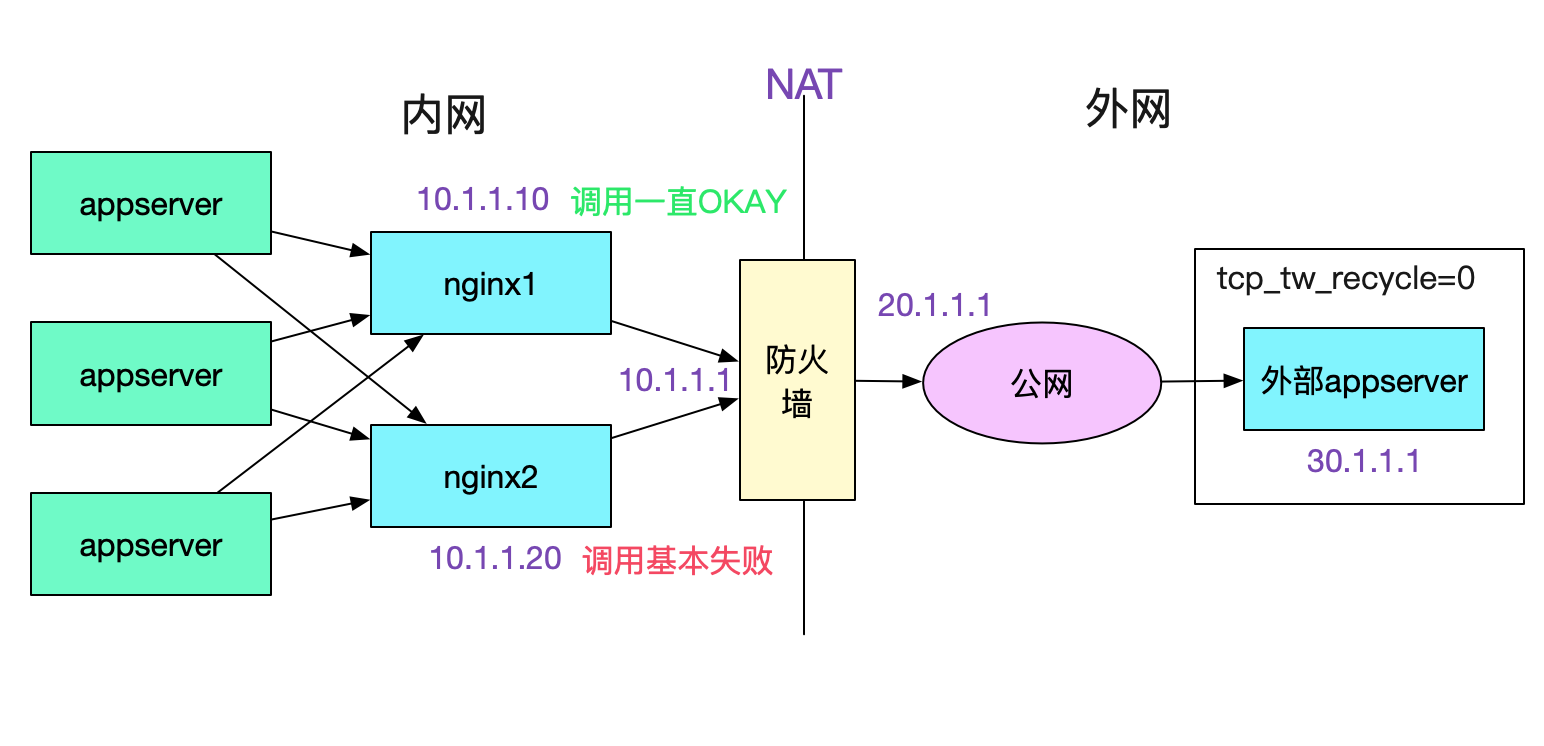
也即,如果你的Server开启了tcp_tw_recycle,那么别人如果通过NAT之类的调用你的Server的话,NAT后面的机器只有一台机器能正常工作,其它情况大概率失败。具体原因呢由下图所示: 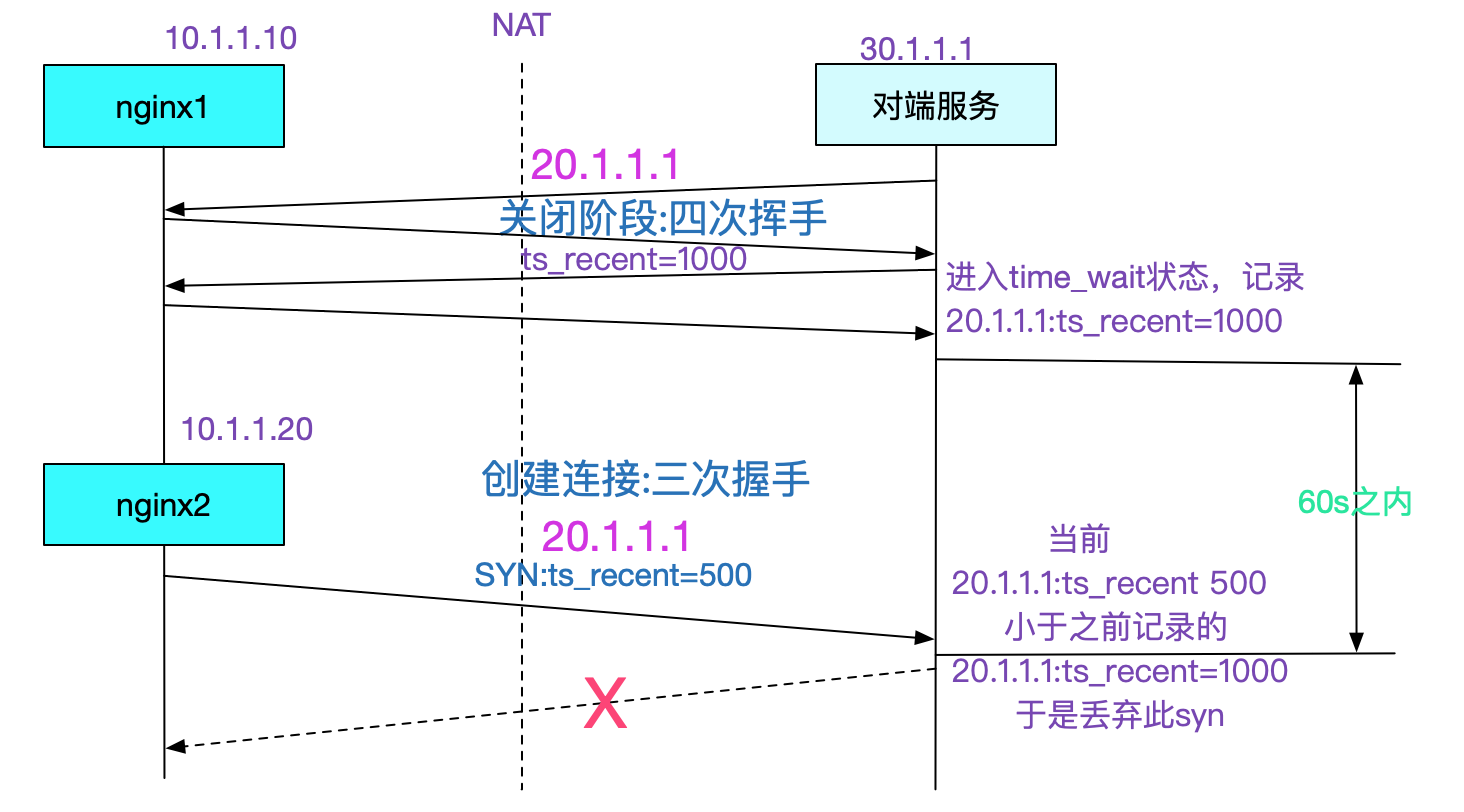
在tcp_tw_recycle=1同时tcp_timestamps(默认开启的情况下),对同一个IP的连接会做这样的限制,也即之前后建立的连接的时间戳必须要大于之前建立连接的最后时间戳,但是经过NAT的一个IP后面是不同的机器,时间戳相差极大,就会导致内核直接丢弃时间戳较低的连接的现象。由于这个参数导致的问题,高版本内核已经去掉了这个参数。如果考虑TIME_WAIT问题,可以考虑设置一下
echo 1 > /proc/sys/net/ipv4/tcp_tw_reuse
tcp_syn_retries
这个参数值得是client发送SYN如果server端不回复的话,重传SYN的次数。对我们的直接影响呢就是connet建立连接时的超时时间。当然Java通过一些C原生系统调用的组合使得我们可以进行超时时间的设置。在Linux里面默认设置是5,下面给出建议值3和默认值5之间的超时时间。
| tcp_syn_retries | timeout |
|---|---|
| 1 | min(so_sndtimeo,3s) |
| 2 | min(so_sndtimeo,7s) |
| 3 | min(so_sndtimeo,15s) |
| 4 | min(so_sndtimeo,31s) |
| 5 | min(so_sndtimeo,63s) |
下图给出了,重传和超时情况的对应图: 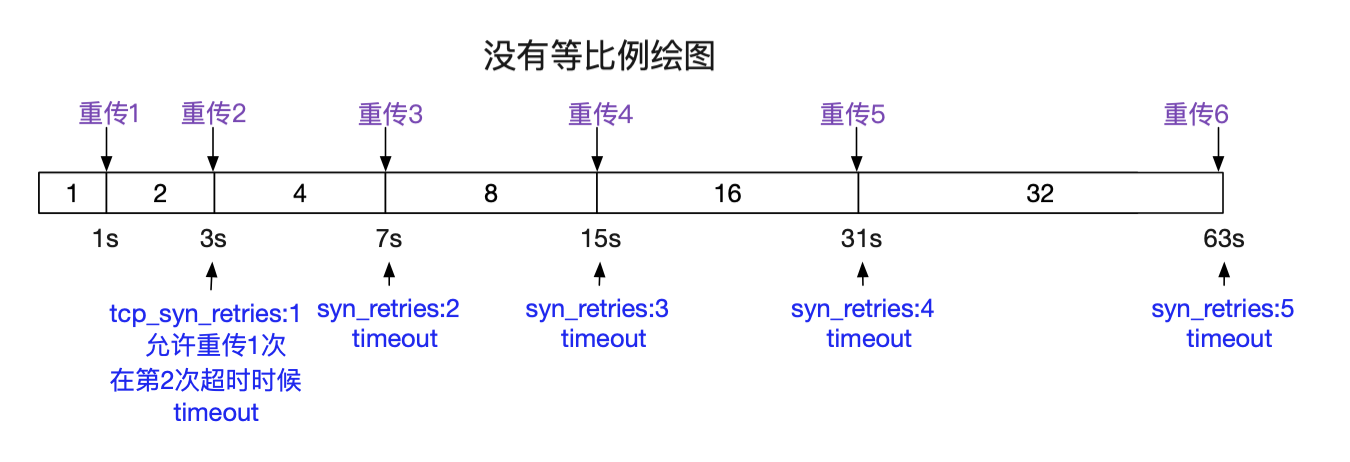
当然了,不同内核版本的超时时间可能不一样,因为初始RTO在内核小版本间都会有细微的变化。所以,有时候在抓包时候可能会出现(3,6,12......)这样的序列。当然Java的API有超时时间:
java:
// 函数调用中携带有超时时间
public void connect(SocketAddress endpoint, int timeout) ;
所以,对于Java而言,这个内核参数的设置没有那么重要。但是,有些代码可能会有忘了设置timeout的情况,例如某个版本的Kafka就是,所以它在我们一些混沌测试的情况下,容灾恢复的时间会达到一分多钟,主要时间就是卡在connect上面-_-!,而这时我们的tcp_syn_retries设置的是5,也即超时时间63s。减少这个恢复时间的手段就是:
echo 3 > /proc/sys/net/ipv4/tcp_syn_retries
tcp_retries2
tcp_retries2这个参数表面意思是在传输过程中tcp的重传次数。但在某个版本之后Linux内核仅仅用这个tcp_retries2来计算超时时间,在这段时间的重传次数纯粹由RTO等环境因素决定,重传超时时间在5/15下的表现为:
| tcp_retries2 | 对端无响应 |
|---|---|
| 5 | 25.6s-51.2s根据动态rto定 |
| 15 | 924.6s-1044.6s根据动态rto定 |
如果我们在应用层设置的Socket所有ReadTimeout都很小的话(例如3s),这个内核参数调整是没有必要的。但是,笔者经常发现有的系统,因为一两个慢的接口或者SQL,所以将ReadTimeout设的很大的情况。 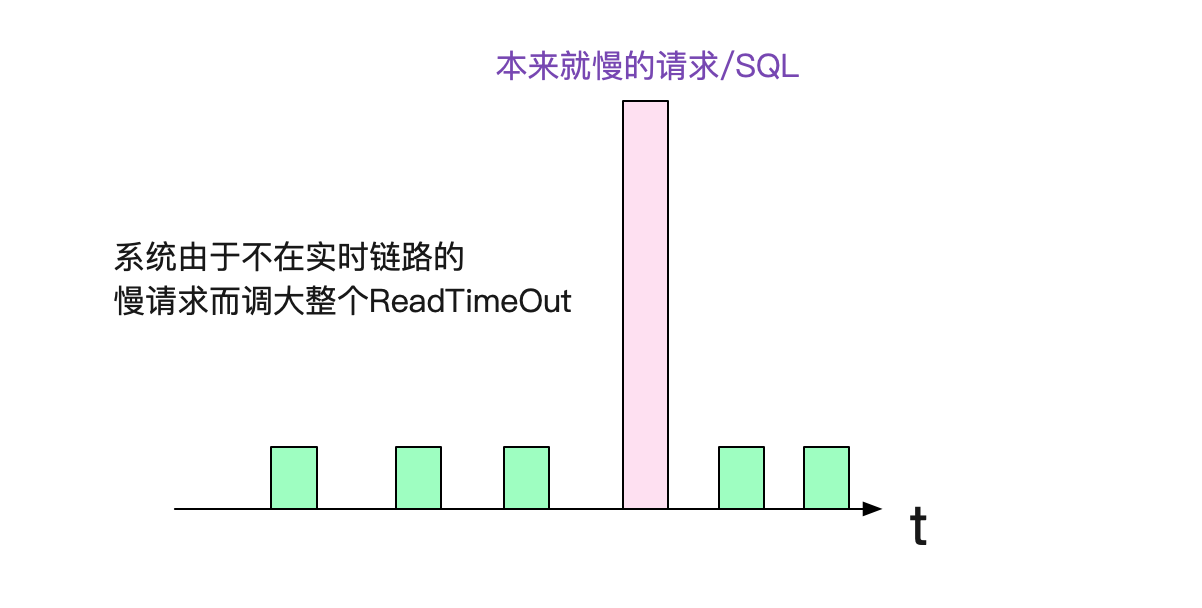
平常这种情况是没有问题的,因为慢请求频率很低,不会对系统造成什么风险。但是,物理机突然宕机时候的情况就不一样了,由于ReadTimeOut设置的过大,导致所有落到这台宕机的机器都会在min(ReadTimeOut,(924.6s-1044.6s)(Linux默认tcp_retries2是15))后才能从read系统调用返回。假设ReadTimeout设置了个5min,系统总线程数是200,那么只要5min内有200个请求落到宕机的server就会使A系统失去响应! 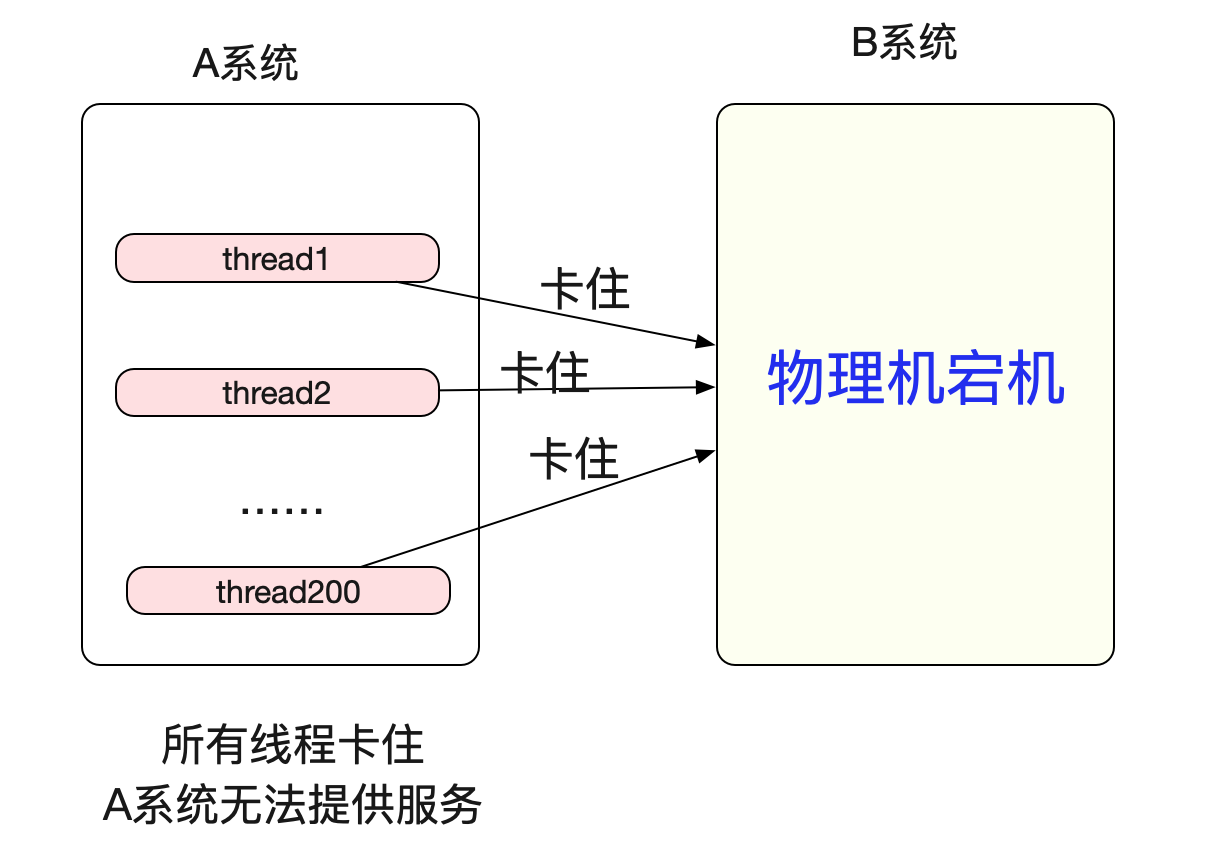
但如果将tcp_retries2设置为5,那么超时返回时间即为min(ReadTimeOut 5min,25.6-51.2s),也就是30s左右,极大的缓解了这一情况。
echo 5 > /proc/sys/net/ipv4/tcp_retries2
但是针对这种现象,最好要做资源上的隔离,例如线程上的隔离或者机器级的隔离。 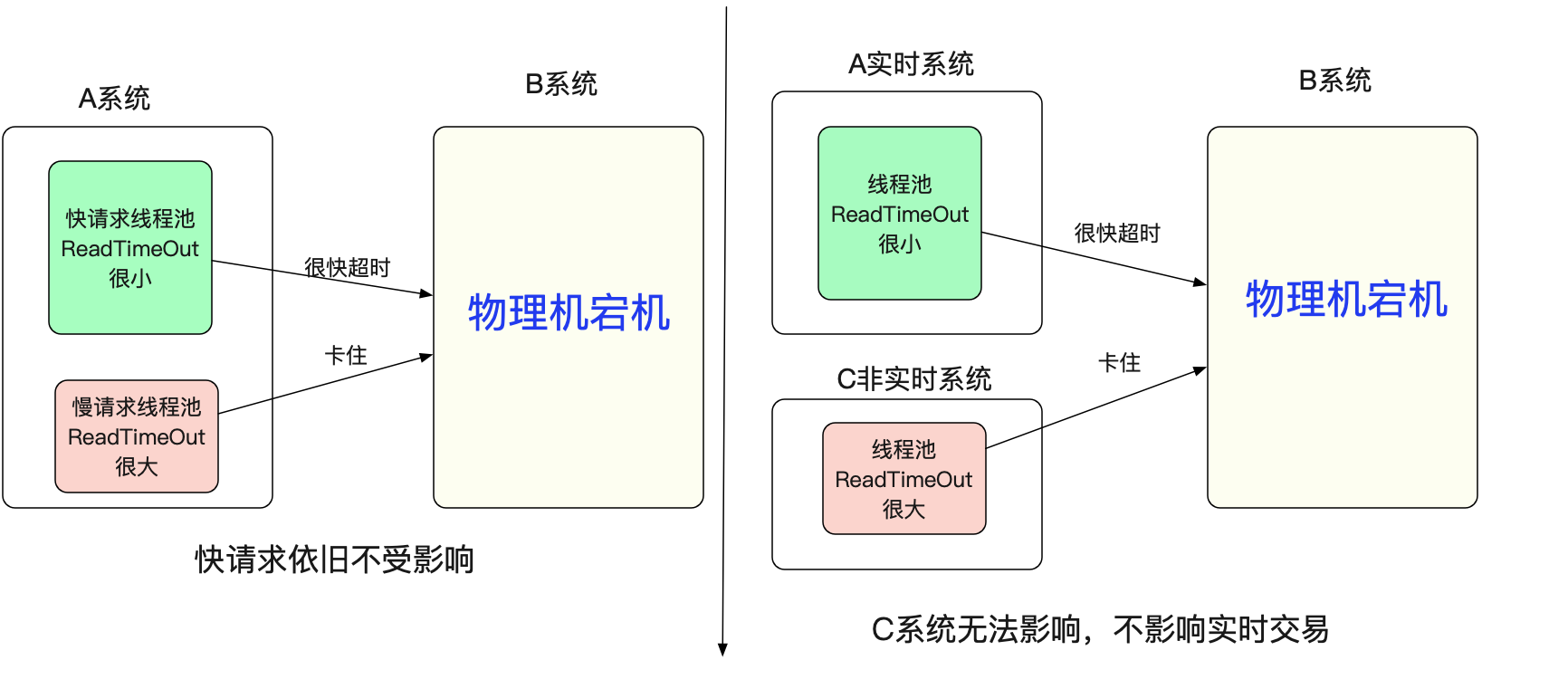
golang的goroutine调度模型就可以很好的解决线程资源不够的问题,但缺点是goroutine里面不能有阻塞的系统调用,不然也会和上面一样,但仅仅对于系统之间互相调用而言,都是非阻塞IO,所以golang做微服务还是非常Nice的。当然了我大Java用纯IO事件触发编写代码也不会有问题,就是对心智负担太高-_-!
物理机突然宕机和进程宕不一样
值得注意的是,物理机宕机和进程宕但内核还存在表现完全不一样。 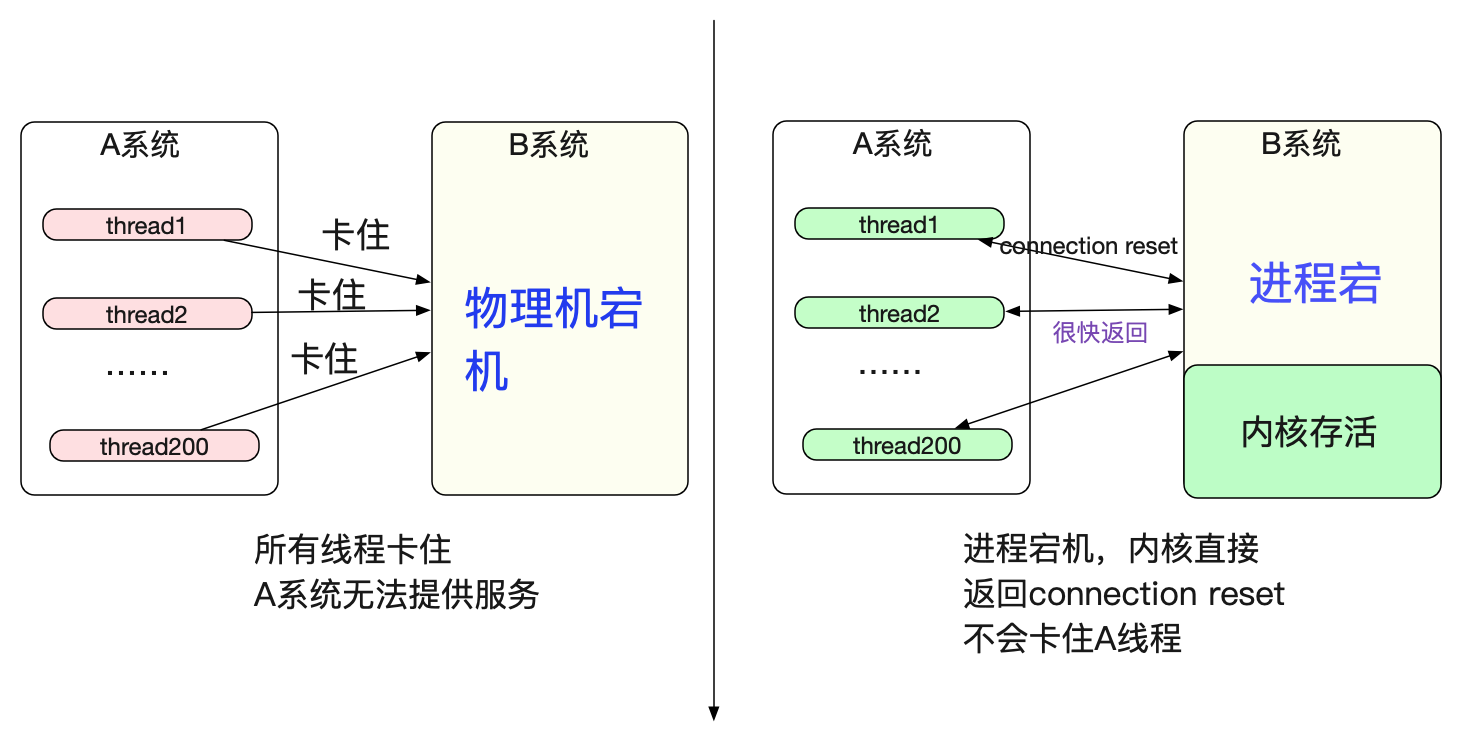
仅仅进程宕而内核存活,那么内核会立马发送reset给对端,从而不会卡住A系统的线程资源。
tcp_slow_start_after_idle
还有一个可能需要调整的参数是tcp_slow_start_after_idle,Linux默认是1,即开启状态。开启这个参数后,我们的TCP拥塞窗口会在一个RTO时间空闲之后重置为初始拥塞窗口(CWND)大小,这无疑大幅的减少了长连接的优势。对应Linux源码为:
static void tcp_event_data_sent(struct tcp_sock *tp,
struct sk_buff *skb, struct sock *sk){
// 如果开启了start_after_idle,而且这次发送的时间-上次发送的时间>一个rto,就重置tcp拥塞窗口
if (sysctl_tcp_slow_start_after_idle &&
(!tp->packets_out && (s32)(now - tp->lsndtime) > icsk->icsk_rto))
tcp_cwnd_restart(sk, __sk_dst_get(sk));
}
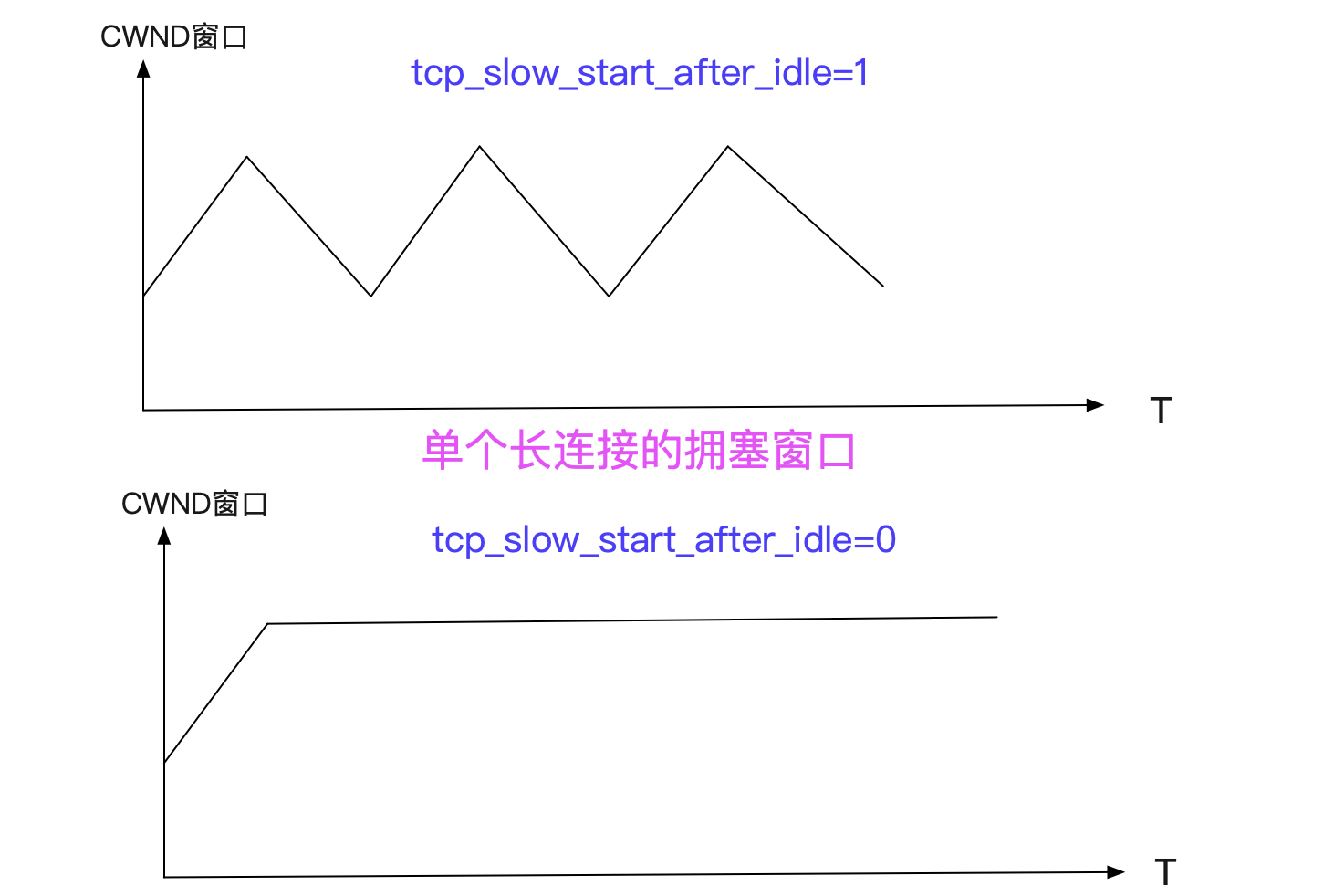
关闭这个参数后,无疑会提高某些请求的传输速度(在带宽够的情况下)。
echo 0 > /proc/sys/net/ipv4/tcp_slow_start_after_idle
当然了,Linux启用这个参数也是有理由的,如果我们的网络情况是时刻在变化的,例如拿个手机到处移动,那么将拥塞窗口重置确实是个不错的选项。但是就我们内网系统间调用而言,是不太必要的了。
初始CWND大小
毫无疑问,新建连接之后的初始TCP拥塞窗口大小也直接影响到我们的请求速率。在Linux2.6.32源码中,其初始拥塞窗口是(2-4个)mss大小,对应于内网估计也就是(2.8-5.6K)(MTU 1500),这个大小对于某些大请求可能有点捉襟见肘。
在Linux 2.6.39以上或者某些RedHat维护的小版本中已经把CWND 增大到RFC 6928所规定的的10段,也就是在内网里面估计14K左右(MTU 1500)。
Linux 新版本
/* TCP initial congestion window */
#define TCP_INIT_CWND 10
公众号
关注笔者公众号,获取更多干货文章
总结
Linux提供了一大堆内参参数供我们进行调优,其默认设置的参数在很多情况下并不是最佳实践,所以我们需要潜心研究,找到最适合当前环境的组合。
推荐:长尾关键词
以上是关于内核参数调优的主要内容,如果未能解决你的问题,请参考以下文章
(转)linux IO 内核参数调优 之 参数调节和场景分析