学习笔记Flink—— Flink Kafka插件
Posted 别呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习笔记Flink—— Flink Kafka插件相关的知识,希望对你有一定的参考价值。
添加依赖& API
在pom.xml添加:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.10.1</version>
</dependency>
代码:
package flink_kafka
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
object MyFlinkKafkaConsumer
def main(args: Array[String]): Unit =
val properties = new Properties()
properties.put("bootstrap.servers", "node110:9092,node111:9092,node112:9092")
properties.put("group.id", "test")
val env = StreamExecutionEnvironment.getExecutionEnvironment
//create kafka source
val kafkaSource = env.addSource(
new FlinkKafkaConsumer[String](
"demo02",//topic
new SimpleStringSchema(),//seriable
properties//kafka cluster configuration
)
)
//Sink
kafkaSource.print()
//execute
env.execute("read from kafka demo02")
运行测试:
① 创建demo02话题,并在demo02写入数据

② 执行代码

Flink作为输出
package flink_kafka
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.connectors.kafka.internals.KeyedSerializationSchemaWrapper
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer, FlinkKafkaProducer
object MyFlinkKafkaConsumerAndProducer
def main(args: Array[String]): Unit =
val properties = new Properties()
properties.put("bootstrap.servers", "node110:9092,node111:9092,node112:9092")
properties.put("group.id", "test")
val env = StreamExecutionEnvironment.getExecutionEnvironment
//create kafka source
val kafkaSource = env.addSource(
new FlinkKafkaConsumer[String](
"demo02",//topic
new SimpleStringSchema(),//seriable
properties//kafka cluster configuration
)
)
//transformation
val processed = kafkaSource
.flatMap(_.split("\\\\w+"))
.map((_,1))
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1)
.filter(_._2>=3)
.map(row => row._1+"->"+row._2)
//kafka Sink
val kafkaProducer = new FlinkKafkaProducer[String](
"demo01",//target topic
new KeyedSerializationSchemaWrapper[String](new SimpleStringSchema()),//seriablization schema
properties,
FlinkKafkaProducer.Semantic.EXACTLY_ONCE
)
processed.addSink(kafkaProducer)
//execute
env.execute("read from kafka demo02 and write to demo01")
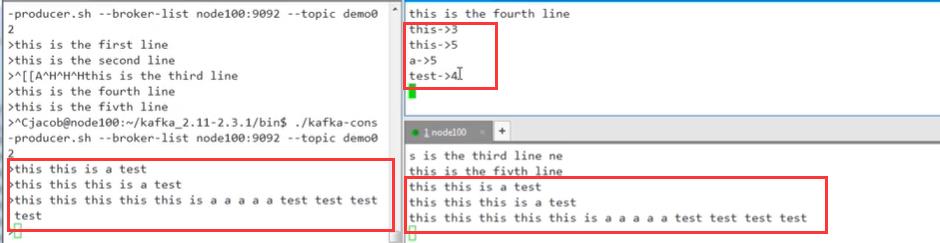
测试:
以上是关于学习笔记Flink—— Flink Kafka插件的主要内容,如果未能解决你的问题,请参考以下文章