CUDA 内存访问
Posted 洪流之源
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CUDA 内存访问相关的知识,希望对你有一定的参考价值。
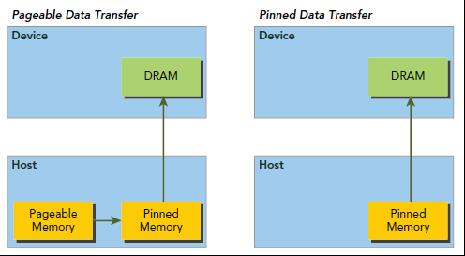
CPU内存,称之为Host Memory,逻辑上可分为Pageable Memory(可分页内存)、Page Lock Memory(页锁定内存),Page Lock Memory又称为Pinned Memory,从字面意思上而言Page Lock Memory是锁定的内存,一旦申请后就专供申请者使用,Pageable Memory则没有锁定特性,申请后可能会被交换。
总结如下:
- pinned memory具有锁定特性,是稳定不会被交换的;
- pageable memory没有锁定特性,对于第三方设备(比如GPU),去访问时,因为无法感知内存是否被交换,可能得不到正确的数据;
- pageable memory的性能比pinned memory差,很可能降低你程序的优先级然后把内存交换给别人用;
- pageable memory策略使用内存假象,实际8GB但是可以使用15GB,可以提高程序运行数量,但运行速度会降低;
- pinned memory太多,会导致操作系统整体性能降低,因为程序运行数量减少了;
- GPU可以直接访问pinned memory而不能访问pageable memory(因为第二条)。
如下是GPU访问Host端内存的示意图:
,GPU内存,称之为Device Memory,类型比较多样,主要如下:
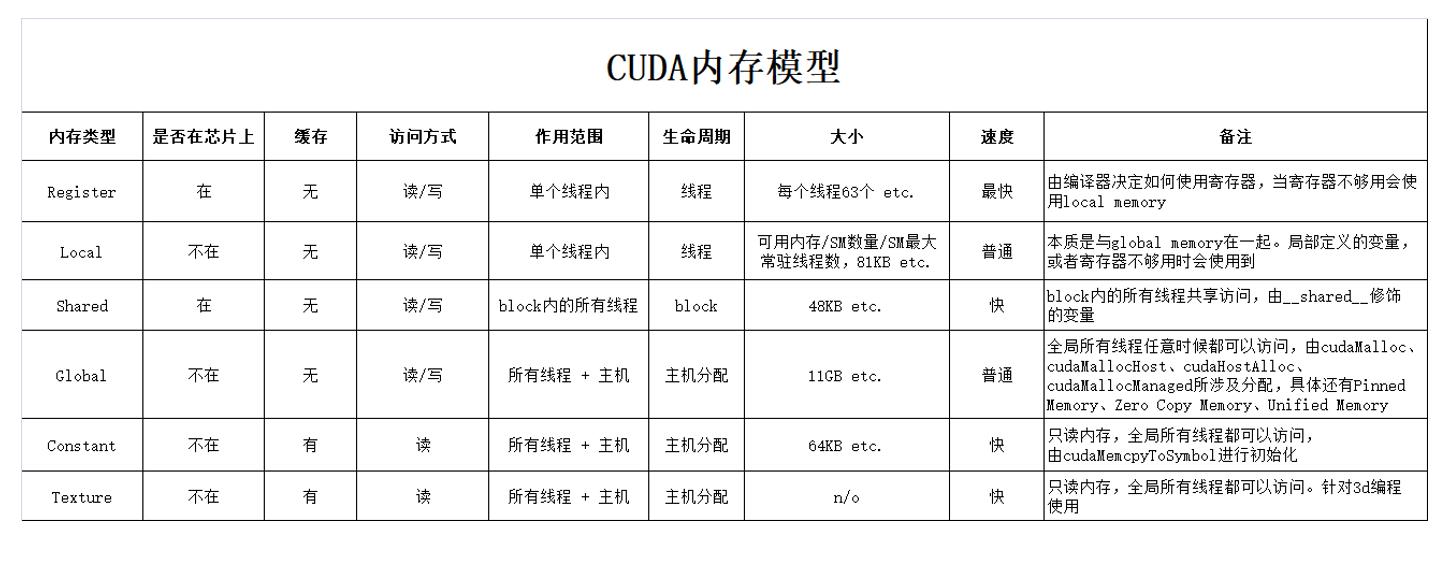
比较常用的GPU内存是Global Memory、Shared Memory。
简单总结一下:
- GPU可以直接访问Pinned Memory,称之为DMA Direct Memory Access;
- 对于GPU访问而言,距离计算单元越近,内存访问效率越高,所以由低到高依次为:Pinned Memory < Global Memory < Shared Memory;
- 由new、malloc分配的,是Pageable Memory,由cudaMallocHost分配的是Pinned Memory,由cudaMalloc分配的是Global Memory;
- 尽量多用Pinned Memory储存host端数据,或者显式处理Host到Device时用PinnedMemory做缓存,都是提高性能的关键。
示例代码:
// CUDA运行时头文件
#include <cuda_runtime.h>
#include <stdio.h>
#include <string.h>
#define checkRuntime(op) __check_cuda_runtime((op), #op, __FILE__, __LINE__)
bool __check_cuda_runtime(cudaError_t code, const char* op, const char* file, int line)
if(code != cudaSuccess)
const char* err_name = cudaGetErrorName(code);
const char* err_message = cudaGetErrorString(code);
printf("runtime error %s:%d %s failed. \\n code = %s, message = %s\\n", file, line, op, err_name, err_message);
return false;
return true;
int main()
int device_id = 0;
checkRuntime(cudaSetDevice(device_id));
float* memory_device = nullptr; // Global Memory
checkRuntime(cudaMalloc(&memory_device, 100 * sizeof(float))); // pointer to device
float* memory_host = new float[100]; // Pageable Memory
memory_host[2] = 520.25;
checkRuntime(cudaMemcpy(memory_device, memory_host, sizeof(float) * 100, cudaMemcpyHostToDevice)); // 返回的地址是开辟的device地址,存放在memory_device
float* memory_page_locked = nullptr; // Pinned Memory
checkRuntime(cudaMallocHost(&memory_page_locked, 100 * sizeof(float))); // 返回的地址是被开辟的pin memory的地址,存放在memory_page_locked
checkRuntime(cudaMemcpy(memory_page_locked, memory_device, sizeof(float) * 100, cudaMemcpyDeviceToHost)); //
printf("%f\\n", memory_page_locked[2]);
checkRuntime(cudaFreeHost(memory_page_locked));
delete [] memory_host;
checkRuntime(cudaFree(memory_device));
return 0;
以上是关于CUDA 内存访问的主要内容,如果未能解决你的问题,请参考以下文章