openMp改写的程序比串行还慢
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了openMp改写的程序比串行还慢相关的知识,希望对你有一定的参考价值。
最近刚刚接触OpenMp,写了简单的程序, 发现在4核4线程运行的时间比4核单线程的时候还要多,不知道为什么,希望有人能帮助我发现一下问题。代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <omp.h>
#define length 100
int main(void)
unsigned int seed = (unsigned)time(NULL);
int i,j;
float min,max,avg,sum;
max = avg = sum = 0.0;
min = 10.0;
float A[length], B[length], C[length];
#pragma omp parallel for
for(i=0; i<length; i++)
A[i] = (rand_r(&seed))%10;
B[i] = (rand_r(&seed))%10;
#pragma omp parallel for
for(i=0; i<length; i++)
C[i] = (A[i]+B[i])/2;
#pragma omp parallel for reduction(+:sum) shared(max,min)
for(i=0; i<length; i++)
#pragma omp critical
if(C[i]>max) max = C[i];
if(C[i]<min) min = C[i];
sum += A[i];
avg = sum/length;
printf("The average of array is %f\n", avg);
printf("The smallest element of array is %f\n", min);
printf("The largest element of array is %f\n", max);
return 0;
希望有人能帮忙发现一下问题,现在结果运行正确,而且确实是多线程再跑,可是速度比单线程慢好多。谢谢。
晕,那个sum求和是sum+=C[i];另外我想问一下这个并行的部分存在冲突么?
你换成一亿就能看出差距了。
我没看出来哪有冲突。但是我觉得你上面赋值和算c那这么写也许效率更快。
#pragma omp parallel for
for(i=0; i<length; i++)
A[i] = (rand_r(&seed))%10;
B[i] = (rand_r(&seed))%10;
C[i] = (A[i]+B[i])/2;
还有,你根本没用到头文件time.h啊。你写这个头文件干嘛?是不是想看运行时间啊。追问
嗯,对,我是感觉可能计算量太小了,不过我试着把计算量增大,并且稍微修改了一下,发现加速比还是不好。那个time.h头文件,我之前确实是用来算时间的,后来我用了multi2sim来运行,直接看cycles了,忘记去掉了。。。另外我试着把程序又做了修改,把critical那部分修改了一下,用数组来记录每个线程单独的min和max,最后再把几个线程的min和max进行比较,得到最终结果,实现并行,不过感觉效果还是一般。不知道是怎么回事。
追答这个时间提高多少呢?如果基本没变,你就要看看你是否用到了openmp.h了,因为就算没成功引用到这个头文件,编译器也会把相应的paralle语句忽略而运行的。
追问用到了omp.h,因为用了数组来分存每个线程的max和min,用到了omp_get_thread_num().用windows api测试的结果加速比是2(4线程的情况下)。但是用multi2sim在linux下面结果就很悲催。
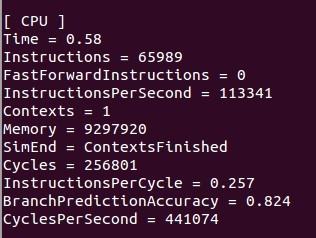
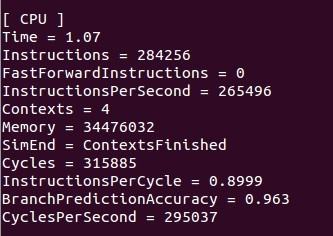
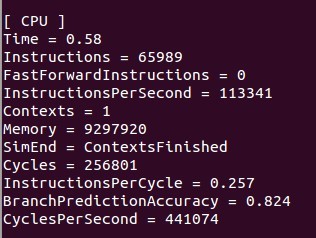
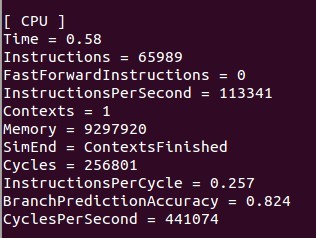
这两个图Contexts是线程数目,这里的时间不是真正意义的运行时间,有价值的是cycles,可以cycles还是增多了,很无语。。。
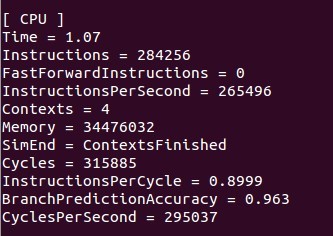
把你改后的代码贴出来让我看看吧。cycles是啥啊?
追问长度抄了。。只能传个截图了,不好意思。。程序如下:

cycles我觉得就是cpu执行了多少个周期吧。可以简单地看成与真实的运行时间相对应。加速比是4的话,cycles应该会变成原来的四分之一。

这个不知道了。我觉得你的代码没有什么问题。
1.但是你看,你顺序执行时instructions 是65989,并行时instructions 是284256.也就是说你并行时居然执行的命令大概是顺序执行时的四倍。正常来说的话不应该是1:1的么?
2.你顺序执行时instructionsPerSecond是113341,并行时是265496,所以说你并行时执行的速度比顺序执行时快两倍多。
我觉得根据上面的2和contxt来说,你确实是并行了。
但是根据1,虽然你的东西并行运算了,但是每次并行都是把1:length都执行了一遍,而不是分成Num_thread个来实现的。
以上只是我的分析,我不确定对不对,因为我总觉得你的代码没有问题。
刚才又想到个问题。你看把运行时间看成和circles成正比了是吧。这个应该是不对的。你看,一共有三个值:cycles per second,cycles,和instructions per cycle。 这一个数和第三个数的乘积应该就是instructionsPerSecond。执行速度应该是和Instructions per second成正比的。所以时间应该是和Instructions per second成反比的(当instructions相同的时候),但是因为你的instructions不一样多,所以比时间就不对了,还是应该比运行速度,也就是Instructions per second。很明显,你并行时运行时的速度比顺序的快很多。但因为并行时你运行了更多的Instructions,所以,并行用的时间却比顺序执行时长。
综上所诉,我觉得最有可能的就是你的i被程序当成是private的了。你尝试把他们定义为公有的试试。
以上是关于openMp改写的程序比串行还慢的主要内容,如果未能解决你的问题,请参考以下文章