九十四Spark-SparkSQL(整合Hive)
Posted 托马斯-酷涛
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了九十四Spark-SparkSQL(整合Hive)相关的知识,希望对你有一定的参考价值。
读取本地文件上传至Hive数据仓库
pom.xml
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>$spark.version</version>
</dependency>启动Hive的metastore(RunJar进程)
nohup /home/hive/bin/hive --service metastore &
代码
package org.example.SQL
import org.apache.log4j.Level, Logger
import org.apache.spark.sql.SparkSession
object sql_Hive
def main(args: Array[String]): Unit =
Logger.getLogger("org").setLevel(Level.ERROR)
//增加参数配置 和 HiveSQL语法支持
val spark: SparkSession = SparkSession.builder().appName("test").master("local[*]")
.config("spark.sql.warehouse.dir", "hdfs://192.168.231.105:8020/user/hive/warehouse")//指定Hive数据库在HDFS上的位置
.config("hive.metastore.uris", "thrift://192.168.231.105:9083")//hive 的 RunJar进程
.enableHiveSupport() //开启对hive语法的支持
.getOrCreate()
spark.sql("show databases").show()
spark.sql("show tables").show()
spark.sql("create table person(id int,name string,age int) row format delimited fields terminated by ' '")
spark.sql("load data local inpath 'file:///E:/data/person.txt' into table person") //本地文件
spark.sql("show tables").show()
spark.sql("select * from person").show()
本地文件

打印
+---------+
|namespace|
+---------+
| db|
| default|
+---------++--------+-------------+-----------+
|database| tableName|isTemporary|
+--------+-------------+-----------+
| default| cat| false|
| default| cat4| false|
| default| cat_group| false|
| default| cat_group1| false|
| default| cat_group2| false|
| default| goods| false|
| default|position_hive| false|
| default| tuomasi| false|
+--------+-------------+-----------++--------+-------------+-----------+
|database| tableName|isTemporary|
+--------+-------------+-----------+
| default| cat| false|
| default| cat4| false|
| default| cat_group| false|
| default| cat_group1| false|
| default| cat_group2| false|
| default| goods| false|
| default| person| false|
| default|position_hive| false|
| default| tuomasi| false|
+--------+-------------+-----------++---+--------+---+
| id| name|age|
+---+--------+---+
| 1|zhangsan| 20|
| 2| lisi| 29|
| 3| wangwu| 25|
| 4| zhaoliu| 30|
| 5| tianqi| 35|
| 6| kobe| 40|
+---+--------+---+HDFS查看
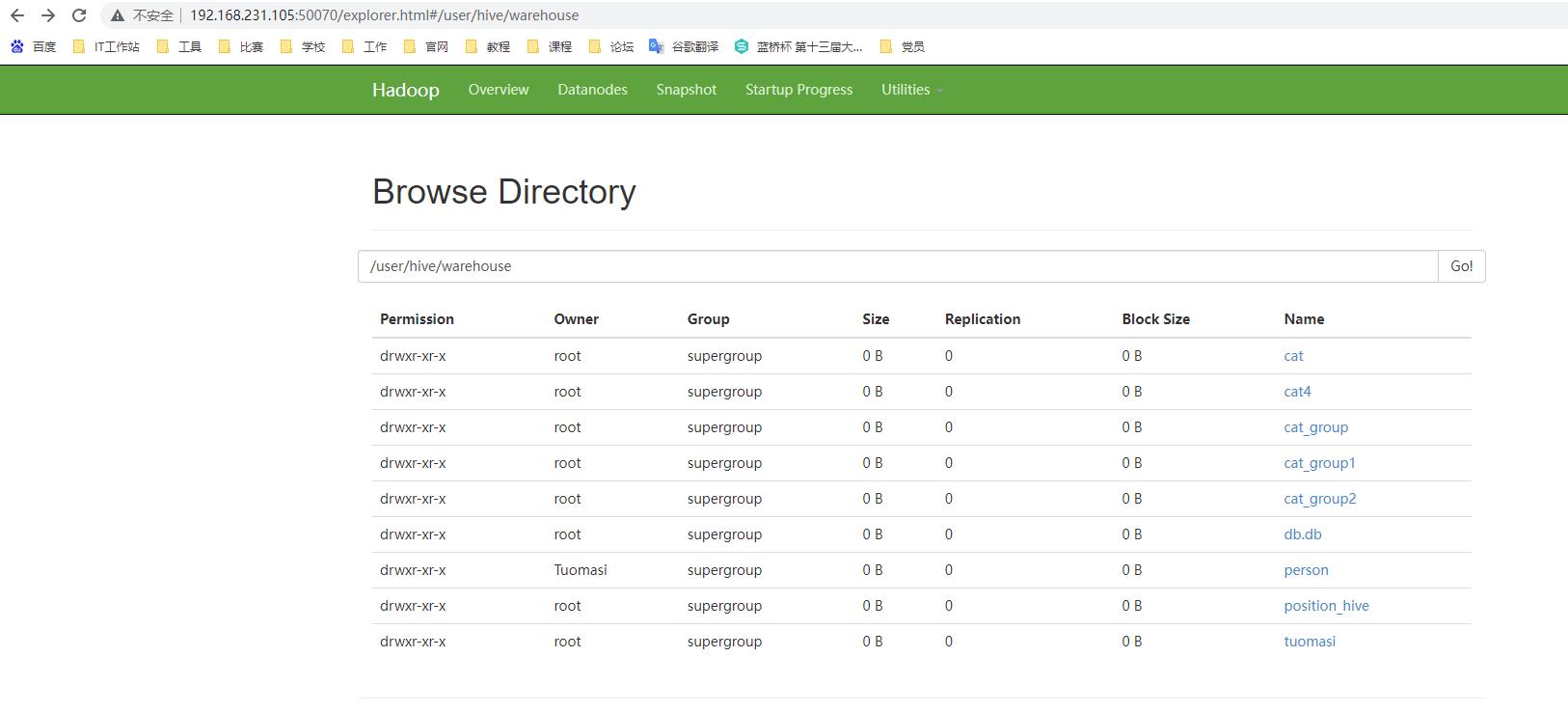
Hive数据仓库查看
hive> show tables;
OK
cat
cat4
cat_group
cat_group1
cat_group2
goods
person
position_hive
tuomasi
Time taken: 0.128 seconds, Fetched: 9 row(s)
hive> select * from person;
OK
1 zhangsan 20
2 lisi 29
3 wangwu 25
4 zhaoliu 30
5 tianqi 35
6 kobe 40
Time taken: 2.889 seconds, Fetched: 6 row(s)
 与50位技术专家面对面
与50位技术专家面对面
 20年技术见证,附赠技术全景图
20年技术见证,附赠技术全景图
以上是关于九十四Spark-SparkSQL(整合Hive)的主要内容,如果未能解决你的问题,请参考以下文章
客快物流大数据项目(九十四):ClickHouse的SummingMergeTree深入了解