线程介绍与创建
Posted 富春山居_ZYY
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了线程介绍与创建相关的知识,希望对你有一定的参考价值。
文章目录
为什么要使用并发编程呢?
并发编程可以提高多核 CPU 的使用效率。
提升访问 I/O 时的 CPU 的利用率,让等待 I/O 的时间能够做一些其他的工作。比如,当某一个进程要在网上下载一些东西的时候,就会处于阻塞状态,使用并发编程, CPU 就不会再给该进程分配时间,其他的进程可以不熟任何影响的获取到 CPU 的时间
多进程编程虽然可以实现并发编程,但是 CPU 是以进程为单位分配资源的,创建进程就需要分配资源,销毁进程就需要释放资源,进程之间进行调度切换时,系统在这些资源中快速切换,这些操作是比较耗时的,当并发的进程数量比较多的时候,效率就会比较低下。
一、线程的出现
通过线程就可以解决上面的问题,线程也叫作“轻量级进程”。一个线程就是一个“执行流”,每个线程都有自己要执行的代码。
打一个不一定恰当但很形象的比方:我听写错了一大堆,老师要我把每个单词都给我抄500遍,为了尽快的把罚抄的单词抄好我准备了两种方案。
- 方案一:我让张三、李四都帮我抄单词,这样就可以提高点效率,让我少抄点了,此时就相当于多进程。但让张三、李四都给我抄单词就非常的费人,人也有自己的事儿要做
- 方案二:我把三只笔并在一起,我一个人同时拿着三只笔抄,也能达到快速完成的效果

此时,抄写单词的人就相当于一个进程,手里的一只笔就相当于一个线程,进程中的线程就相当于抄单词人手里的好几支笔,每只笔都在各自写各自的(当然和抄单词不同,每个线程干的活儿都是比较独立的,各自执行着自己的一段代码)。抄单词的若干支笔之间公用着同一份资源,那就是抄单词的人。
通过多线程也能实现并发编程,和进程不同的是,线程比进程更加的轻量。
- 创建线程比创建进程更快,不需要分配新的资源
- 销毁线程比销毁进程更快,不需要释放旧的资源
- 调度线程比调度进程更快,开销要小于进程
二、进程与线程的概念
线程是包含在进程里的。一个进程里可以有一个线程,也可以有多个线程。每个进程至少有一个线程的存在,即主线程- 进程存在的意义是为了解决
并发编程的问题,但如果频繁创建或者销毁进程,开销较大。相比之下,线程也可以满足并发编程的问题,但线程的创建销毁开销就小很多 - 每个线程都是一个
独立的执行流,各自执行着一段自己的代码 - 进程之间各有各自的虚拟地址空间(独立性),一个进程挂了不会引起其他的进程出现问题。但同一个进程的每一个线程之间,共用同一份资源,如果一个线程挂了,容易影响到其他的线程,甚至影响到整个进程
- 从操作系统的角度看,
进程是资源分配的基本单位,线程是 CPU 调度的基本单位
三、创建线程
在 Java 标准库中,通过 Thread 类来表示线程,每个创建的 Thread 实例和系统中的一个线程是相对应的。
Thread 用法一:
- 创建一个继承自
Thread类的子类 - 重写 Thread 类中的
run方法,在该方法中写入需要线程中执行的代码,当线程被调用了,就会来执行 run 方法中的代码 - 创建自己写的子类的实例,调用其中的
start方法,真正的创建一个线程
代码实例:
class MyThread extends Thread
//继承 Thread 来创建一个线程类
@Override
public void run()
while (true)
System.out.println("This is my Thread");
//线程中执行的代码
try
Thread.sleep(1000);
//让线程进入阻塞状态1000ms,在这段时间内,该线程不会占用 CPU,就不会执行打印操作,防止打印太快
catch (InterruptedException e)
e.printStackTrace();
public class func1
public static void main(String[] args)
//main 方法就是主线程
MyThread myThread = new MyThread();// 创建 MyThread 类的实例
myThread.start();//创建一个新的线程并启动
while (true)
System.out.println("main Thread");
try
Thread.sleep(1000);
catch (InterruptedException e)
e.printStackTrace();
结果:
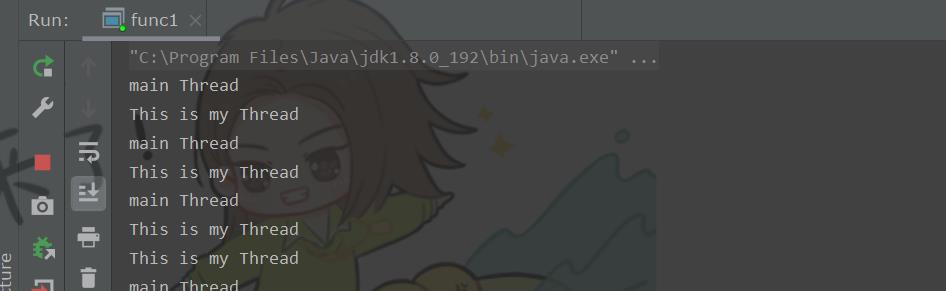
通过结果可以发现两个线程的打印交替进行着,说明main 线程和新创建出来的线程 myThread 是并发执行。但是这里的结果并不是有规律的打印,说明多个线程执行的顺序并不是完全确定的,取决于系统内部调度代码的具体实现。
Thread 用法二:
- 创建一个实现
Runnable接口的类,并重写其中的 run 方法 - 创建 Thread 类的实例,参数为新创建的实现
Runnable 接口的类的实例
class MyRunnable implements Runnable
@Override
public void run()
while (true)
System.out.println("my Thread");
try
Thread.sleep(1000);
catch (InterruptedException e)
e.printStackTrace();
public class func2
public static void main(String[] args)
Thread thread = new Thread(new MyRunnable());
thread.start();
while (true)
System.out.println("main Thread");
try
Thread.sleep(1000);
catch (InterruptedException e)
e.printStackTrace();
结果和用法一一样,不一样的是写法上的不同,通过 Runnable 的这种方式将需要在线程中执行的任务和 Thread 类进行了分离。
Thread 用法三:
和用法一没有本质区别,只是用了匿名内部类
public class func3
public static void main(String[] args)
//创建一个继承自 Thread 的匿名的子类
Thread thread = new Thread()
@Override
public void run()
while (true)
System.out.println("my Thread");
try
Thread.sleep(1000);
catch (InterruptedException e)
e.printStackTrace();
;
thread.start();
while (true)
System.out.println("main Thread");
try
Thread.sleep(1000);
catch (InterruptedException e)
e.printStackTrace();
Thread 用法四:
和用法二没有本质区别,只是用了匿名内部类
public class func4
public static void main(String[] args)
//创建了一个 Runnable 的匿名内部类并创建出实例,作为 Thread 的参数
Thread thread = new Thread(new Runnable()
@Override
public void run()
while (true)
System.out.println("my Thread");
try
Thread.sleep(1000);
catch (InterruptedException e)
e.printStackTrace();
);
thread.start();
while (true)
System.out.println("main Thread");
try
Thread.sleep(1000);
catch (InterruptedException e)
e.printStackTrace();
Thread 用法五:
用 lambda 表达式代替 Runnable ,显得更加的简洁
public class func5
public static void main(String[] args)
Thread thread = new Thread(() ->
while (true)
System.out.println("my Thread");
try
Thread.sleep(1000);
catch (InterruptedException e)
e.printStackTrace();
);
thread.start();
while (true)
System.out.println("main Thread");
try
Thread.sleep(1000);
catch (InterruptedException e)
e.printStackTrace();
上述的五种用法从根本上来说只有两种方法,一种是直接继承 Thread 类,一种是实现 Runnable 接口。
四、面试题:run方法和 start 方法
在上述代码中用到了 Thread 类中的两个重要的方法:run 方法和 start 方法
上面的写法都是调用的 start 方法,然后引起了 run 方法的执行,反正 run 方法总会要执行,直接调用 run 方法又会怎样呢?和之前的写法有什么不同呢?
代码:
public class func6
public static void main(String[] args)
Thread thread = new Thread(() ->
while (true)
System.out.println("my Thread");
try
Thread.sleep(1000);
catch (InterruptedException e)
e.printStackTrace();
);
thread.run();//直接执行 run 方法
while (true)
System.out.println("main Thread");
try
Thread.sleep(1000);
catch (InterruptedException e)
e.printStackTrace();
结果:
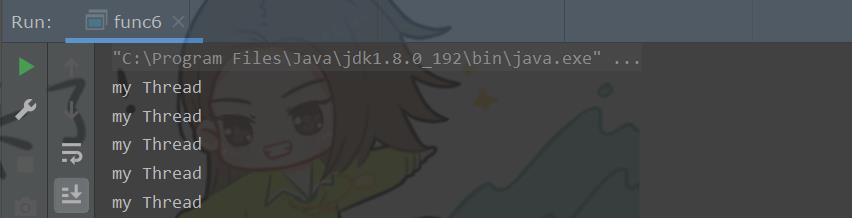
此时,结果只执行 my Thread 的打印。说明此时此刻, run 方法只是一个普通的方法的调用,并没有创建新的线程,当前进程中只有 main 线程一个,需要 main 线程先执行完第一个循环,方能执行后面的,但是由于循环是死循环就没有办法执行到第二个循环。
总结:
调用 start 方法,会真正的创建一个线程并启动,使线程进入就绪状态,当分配到时间片后就可以开始运行。 start 方法会执行线程的相应准备工作,然后自动执行 run 方法的内容,实现真正的多线程。直接执行 run 方法,会将
run 方法当成一个 main 线程下的普通方法去调用执行,并不会在其他某个线程中执行它,这并不是多线程。
总而言之: 调用 start 方法才可新建启动线程并使线程进入就绪状态,而 run 方法只是作为 thread 的一个普通方法调用,还是在 main 线程里执行
五、多线程并发编程的优势
并发编程最明显的优势就是提高效率
代码案例:
parallel()方法实现在一个线程中将变量 a 和变量 b 进行循环自增,用通过 currentTimeMillis 可以记录当前的系统时间戳,从而记录自增完后一共所花费的时间
concurrence() 方法实现在两个线程 t1 和 t2 中分别将变量 a 和变量 b 分别进行循环自增。需要注意的是concurrence() 方法和 t1、t2 是并发执行的,因此要调用 join() 方法等两个线程执行完毕在记录线程执行完的时间。
public class test
public static void parallel()
long began = System.currentTimeMillis();
long a = 0;
for(long i = 0;i < 10_0000_0000;i ++)
a ++;
long b = 0;
for (long i = 0;i < 10_0000_0000;i ++)
b ++;
long end = System.currentTimeMillis();
System.out.println("单线程耗时:" + (end-began)+"ms");
public static void concurrence() throws InterruptedException
long began = System.currentTimeMillis();
Thread t1 = new Thread(() ->
long a = 0;
for (int i = 0;i < 10_0000_0000;i ++)
a ++;
);
t1.start();
Thread t2 = new Thread(() ->
long b = 0;
for (int i = 0;i < 10_0000_0000;i++)
b ++;
);
t2.start();
t1.join();
t2.join();//需要等待t1 和 t2 都执行完了才开执行下面的内容
long end = System.currentTimeMillis();
System.out.println("多线程耗时:" + (end-began)+"ms");
public static void main(String[] args) throws InterruptedException
parallel();
//concurrence();
结果:
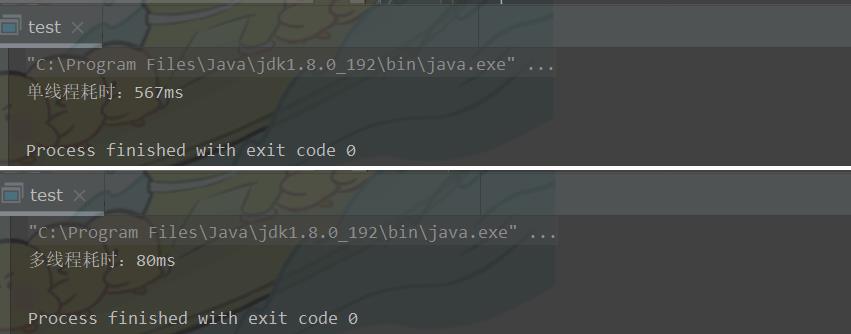
效果显著,体现多线程并发编程的优势~
完!
以上是关于线程介绍与创建的主要内容,如果未能解决你的问题,请参考以下文章