七.全文检索ElasticSearch经典入门-聚合查询
Posted 墨家巨子@俏如来
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了七.全文检索ElasticSearch经典入门-聚合查询相关的知识,希望对你有一定的参考价值。
前言
今天我们讲ES的高亮和聚合查询,聚合功能是ES很重要的功能,它基于查询条件来对数据进行分桶和计算。它提供了类似于关系型数据库的SUM,COUNT, AVG , Group By 等功能。聚合也可以嵌套,可以组成复杂的操作。
聚合概述
ES聚合包括:Metrics Aggregations 指标聚合 ;Bucket Aggregations 桶聚合 ;Pipeline Aggregations 管道聚合 ;Matrix Aggregations 矩阵聚合;
- Metrics Aggregations 指标聚合 :提供了类似于关系型数据库的 count,sum,avg,min,max 等统计方式。
- Bucket Aggregations 桶聚合 :桶聚合类似于分组统计 group by , 它执行的是对文档分组的操作,把特性相同的文档分到一个桶里(理解成一个group)。
- Pipeline Aggregations 管道聚合 : 管道聚合主要是把其他聚合的结果再进行聚合
- Matrix Aggregations 矩阵聚合:矩阵聚合,此功能处于技术预览阶段,可能会在未来版本中更改或删除。
下面是聚合语法如下
GET /index/type/_search
"query":
...
,
"aggs":
"指定聚合名字":
"指定聚合方式":
"field":"按那个字段聚合"
注意:本文并不会把ES所有的聚合都讲到,您可以通过官网自行学习其他的聚合如何使用 ,参考文档 ES聚合查询
指标聚合 Metrics Aggregations
指标聚合,它可以对文档数据进行权重统计,比如求:最大值,最小值,求和,求平均等。就如何关系型数据库中的统计函数。
MAX;MIN;SUM;AVG
-
Max Aggregation,求最大值。如同于关系型数据库中的 max函数
-
Min Aggregation,求最小值。如同于关系型数据库中的 min 函数
-
Sum Aggregation,求和。如同于关系型数据库中的 sum 函数
-
Avg Aggregation,求平均数。如同于关系型数据库中的 avg函数
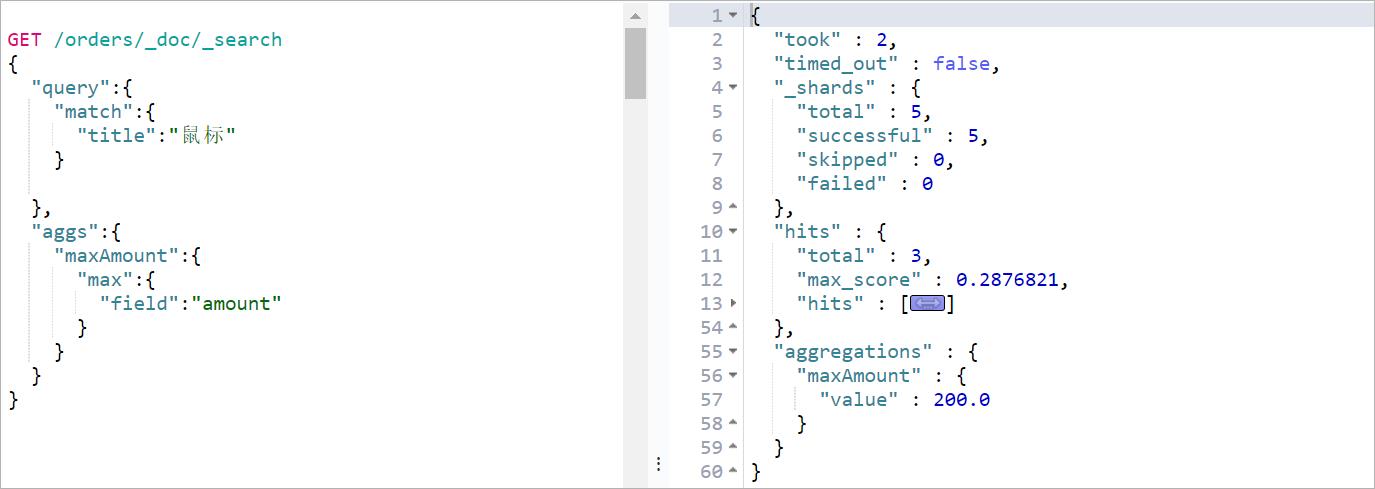
案例:[Max Aggregation] : 查询价格最大值
GET /orders/_doc/_search
"query":
"match":
"title":"鼠标"
,
"aggs": //代表是聚合查询
"maxAmount": //取个名字,任意指定
"max": //使用max聚合方式
"field":"amount" //按照amount字段做max聚合
效果如下
多种聚合一起用

统计聚合: Stats Aggregation
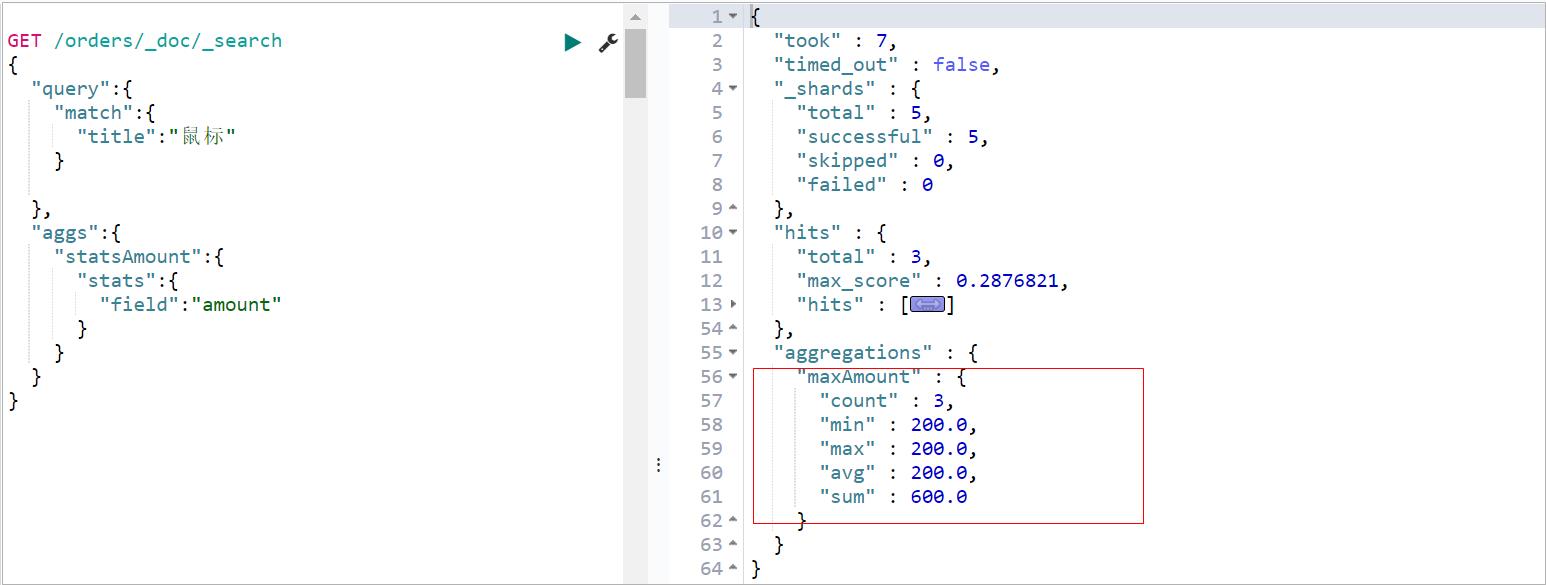
Stats Aggregation,统计聚合可以统计出某个字段的 :min、max、sum、count、avg5个值,案例:求金额的:最小,最大,总和,数量,平均值。
GET /orders/_doc/_search
"query":
"match":
"title":"鼠标"
,
"aggs":
"statsAmount":
"stats":
"field":"amount"
执行效果如下
值计数聚合 Value Count Aggregation
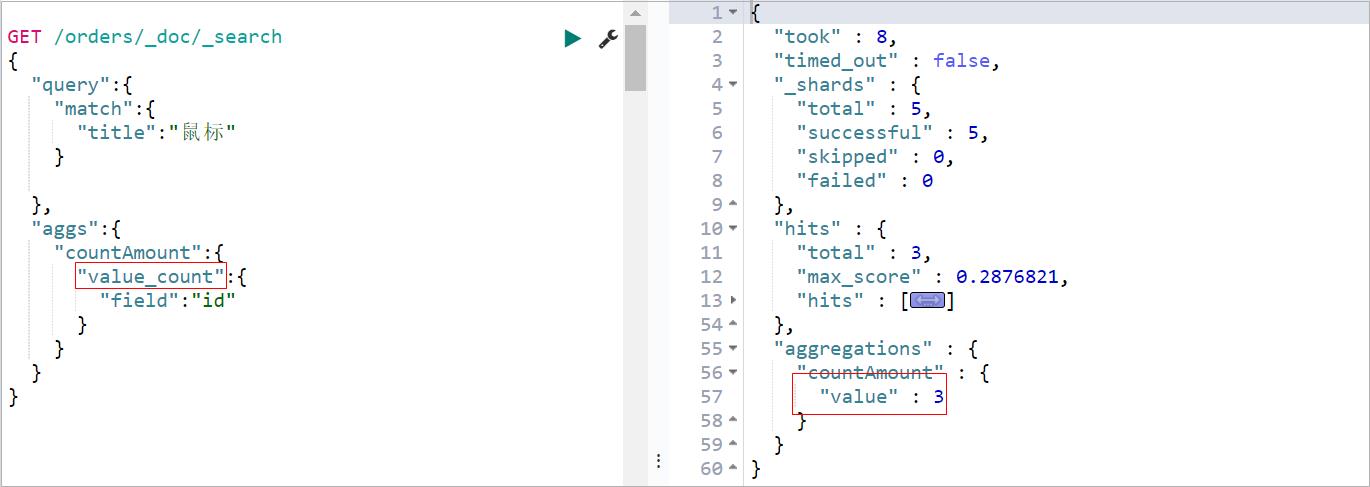
Value Count Aggregation,值计数聚合,可以按照某一个字段进行数量统计,类似于关系型数据库的count(id)的效果,案例:统计订单数量
GET /orders/_doc/_search
"query":
"match":
"title":"鼠标"
,
"aggs":
"countAmount":
"value_count":
"field":"id"
执行效果如下
去重 distinct 聚合
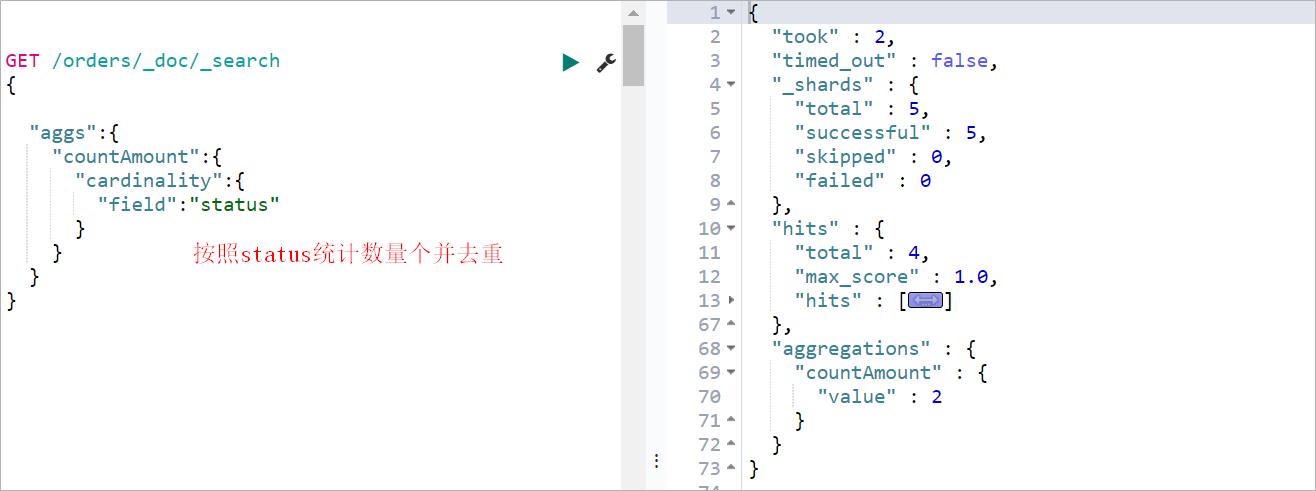
distinct 聚合可以根据某个字段计算文档非重复的个数(去重计数),相当于sql中的distinct。案例:计算出商品数量,标题去重
GET /orders/_doc/_search
"aggs":
"countAmount":
"cardinality":
"field":"status"
查询效果如下
百分比统计Percentiles Aggregation
Percentiles Aggregation,百分比聚合,可以统计出满足某个值的文档在所有文档中的占比,默认返回[ 1, 5, 25, 50, 75, 95, 99 ]分位上的值。案例:
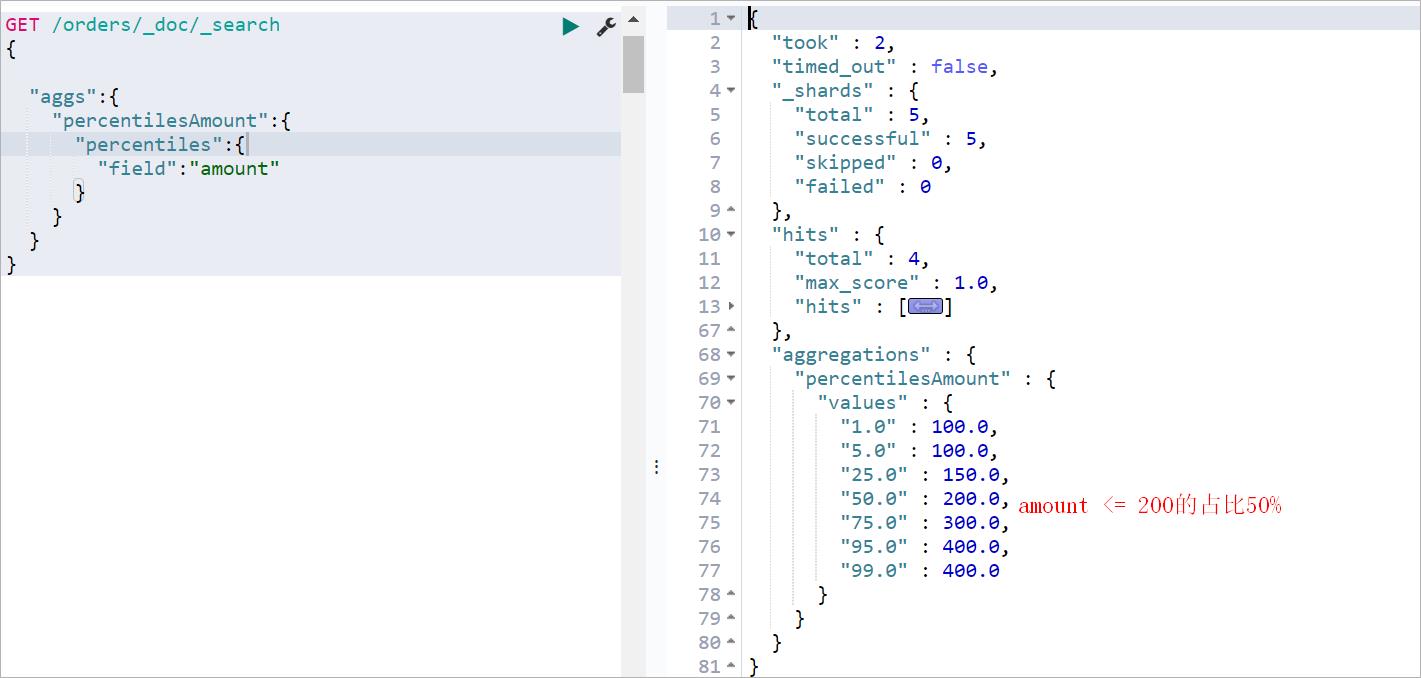 - “1.0”:100.0 :代表金额<=100的文档在所有文档中占比:10%
- “1.0”:100.0 :代表金额<=100的文档在所有文档中占比:10%
百分比排名 Percentile Ranks Aggregation
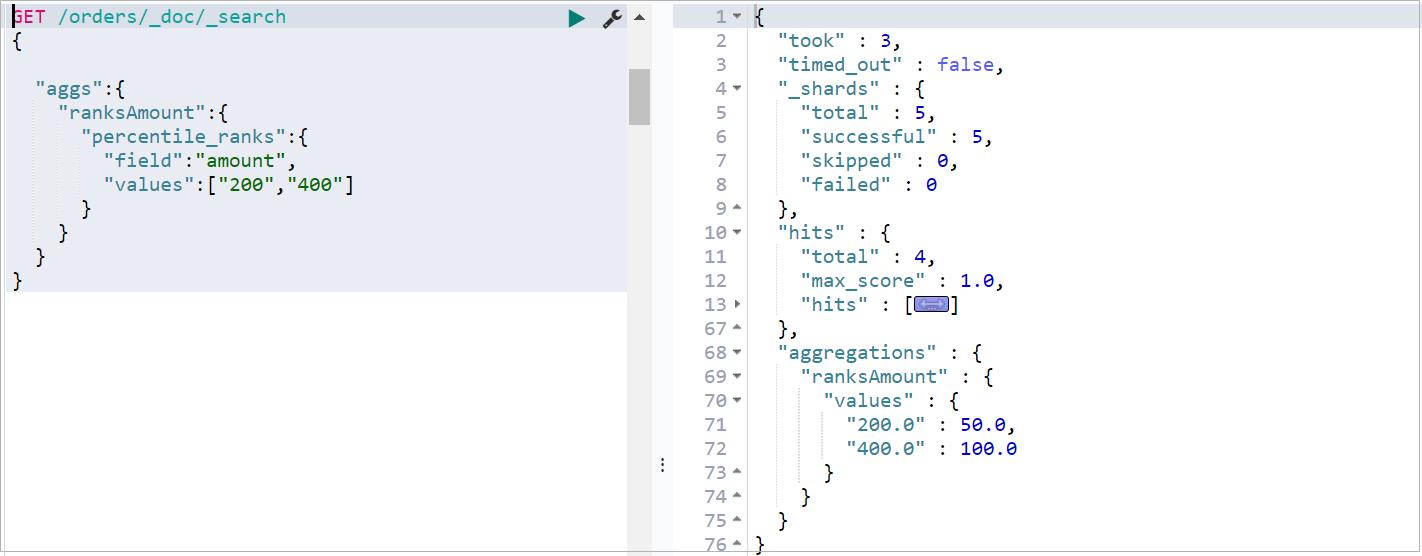
百分比排名 Percentile Ranks Aggregation ,可以统计出满足某个值的文档在所有文档中的占比,案例:统计金额为200 和 400 的占比
GET /orders/_doc/_search
"aggs":
"ranksAmount":
"percentile_ranks":
"field":"amount",
"values":["200","400"]
查询效果如
最高匹配 Tops Hits
Top Hits Aggregation,最高匹配权值聚合。获取到每组前n条数据,相当于sql 中Top(group by 后取出前n条): 案例:统计最前面2条
GET /orders/_doc/_search
"aggs":
"countAmount":
"top_hits":
"size":"2"
查询效果如下
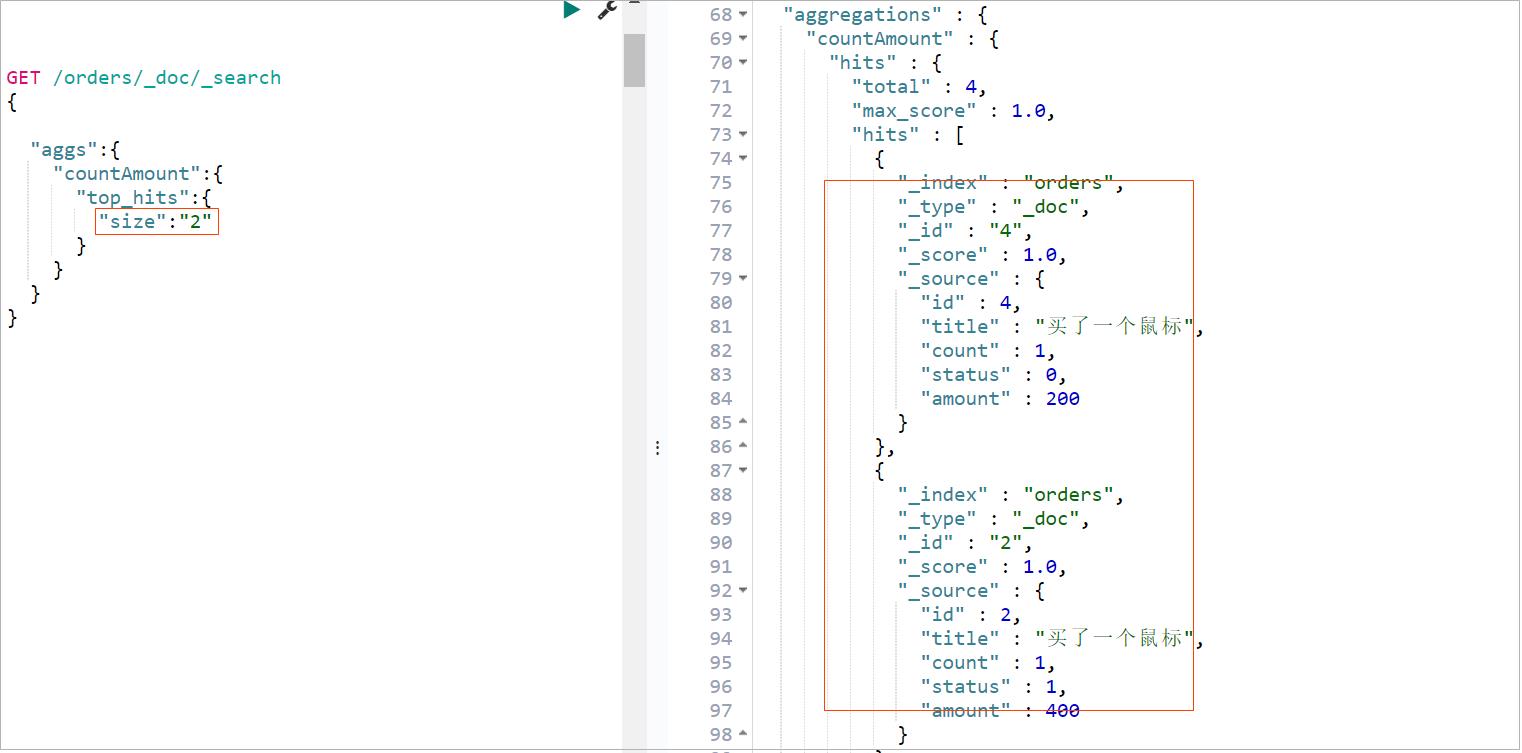
Top Hits 一般作为子聚合使用,以此来聚合每个桶中的最高匹配的文档,较为常用的统计
桶聚合
桶聚合类似于分组统计 group by , 它执行的是对文档分组的操作,把特性相同的文档分到一个桶里(理解成一个group)。
词聚合 Terms Aggregation
Terms Aggregation,词聚合。基于某个字段进行分组统计文档个数。默认返回顺序是按照文档个数多少排序。类似于关系型数据库的 group by 。
案例:按照状态统计每种状态是文档个数
GET /orders/_doc/_search
"aggs":
"statusAggr":
"terms":
"field":"status"
执行效果:
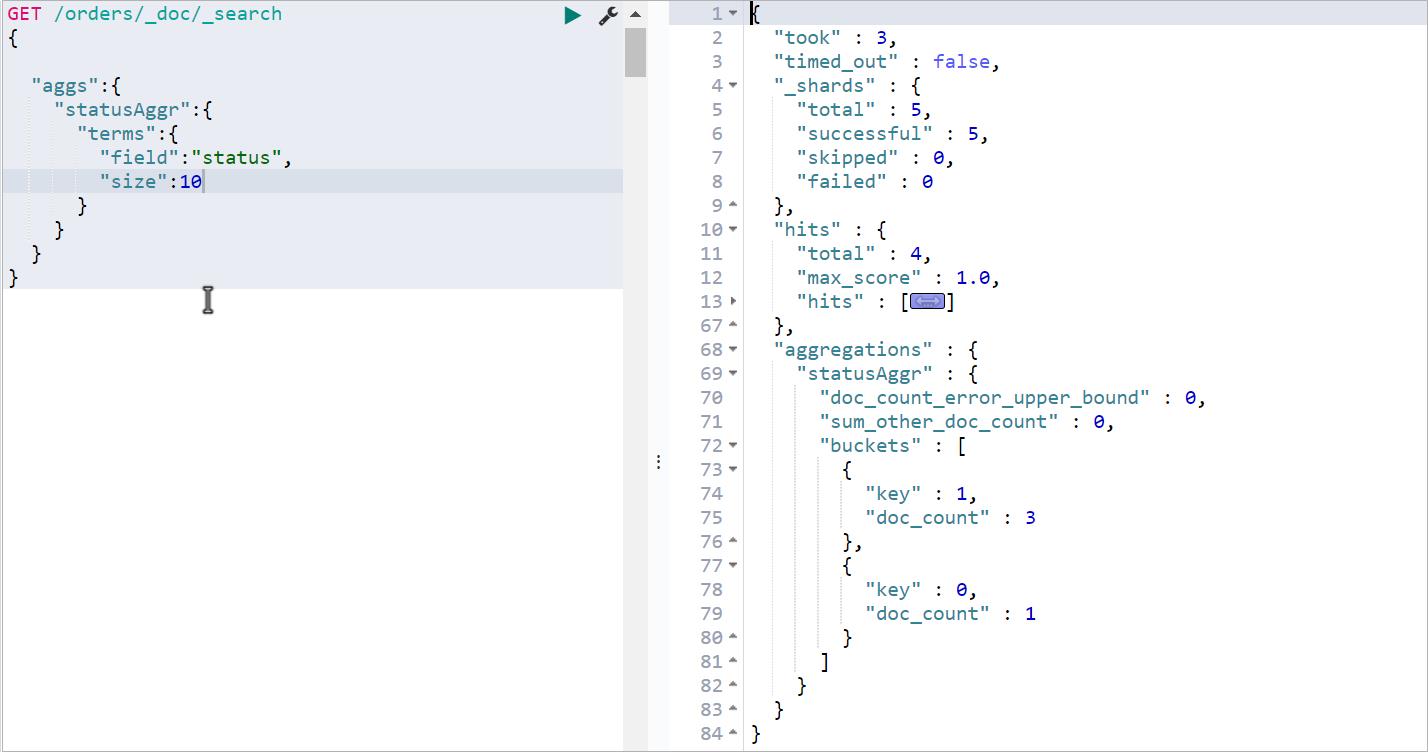
status 为 1的文档数为:3 ,status为0的文档数为 1 ; size是取前面10条。
子聚合使用,统计每种status下的文档数量,以及总金额
GET /orders/doc/_search
"aggs":
"statusAggr":
"terms":
"field":"status",
"size":10
,
"aggs": //子聚合,把上面聚合的结果作为数据源继续做sum聚合
"amountAgg":
"sum":
"field":"amount"
执行效果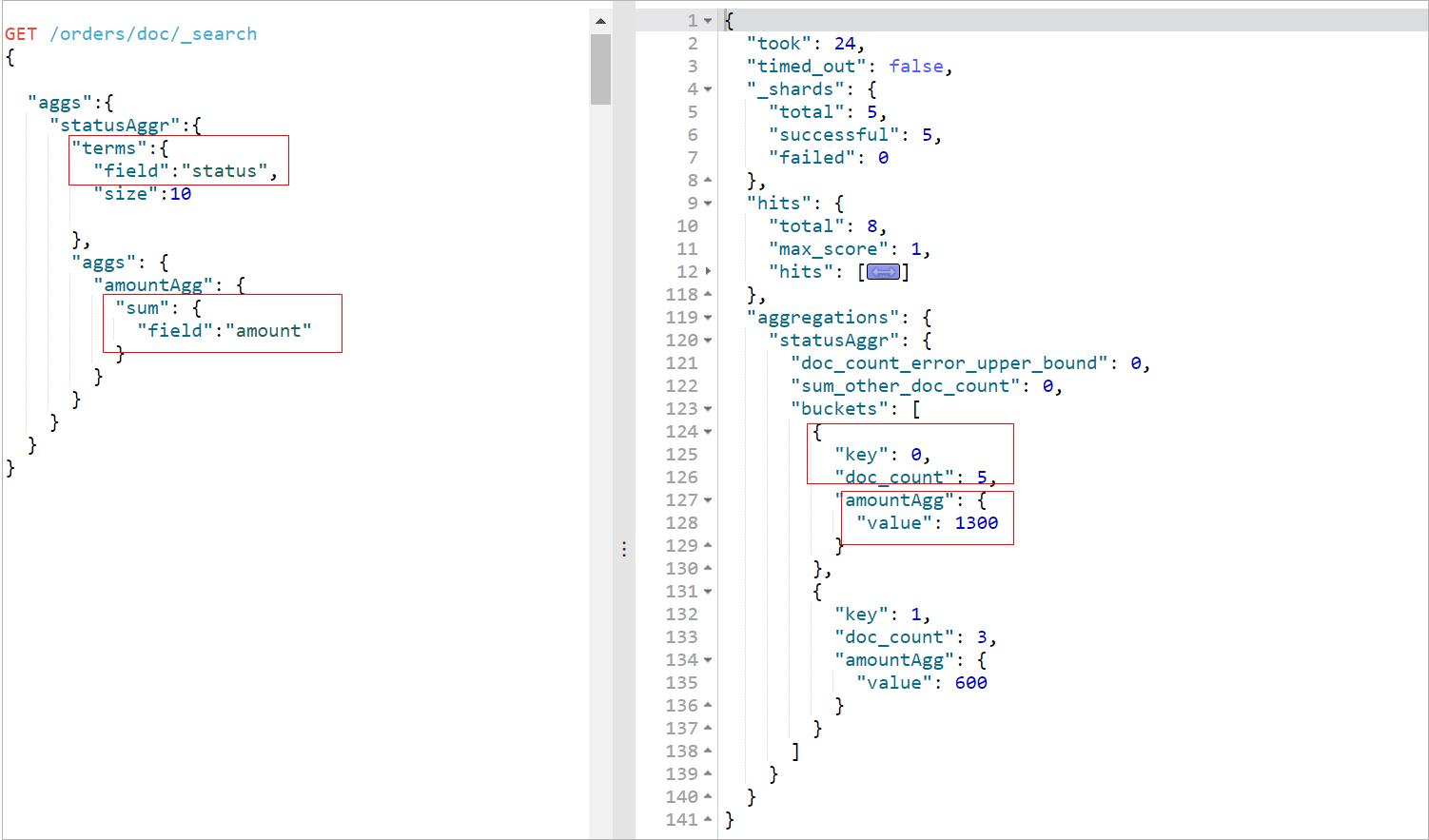
过滤聚合 Filter Aggregation
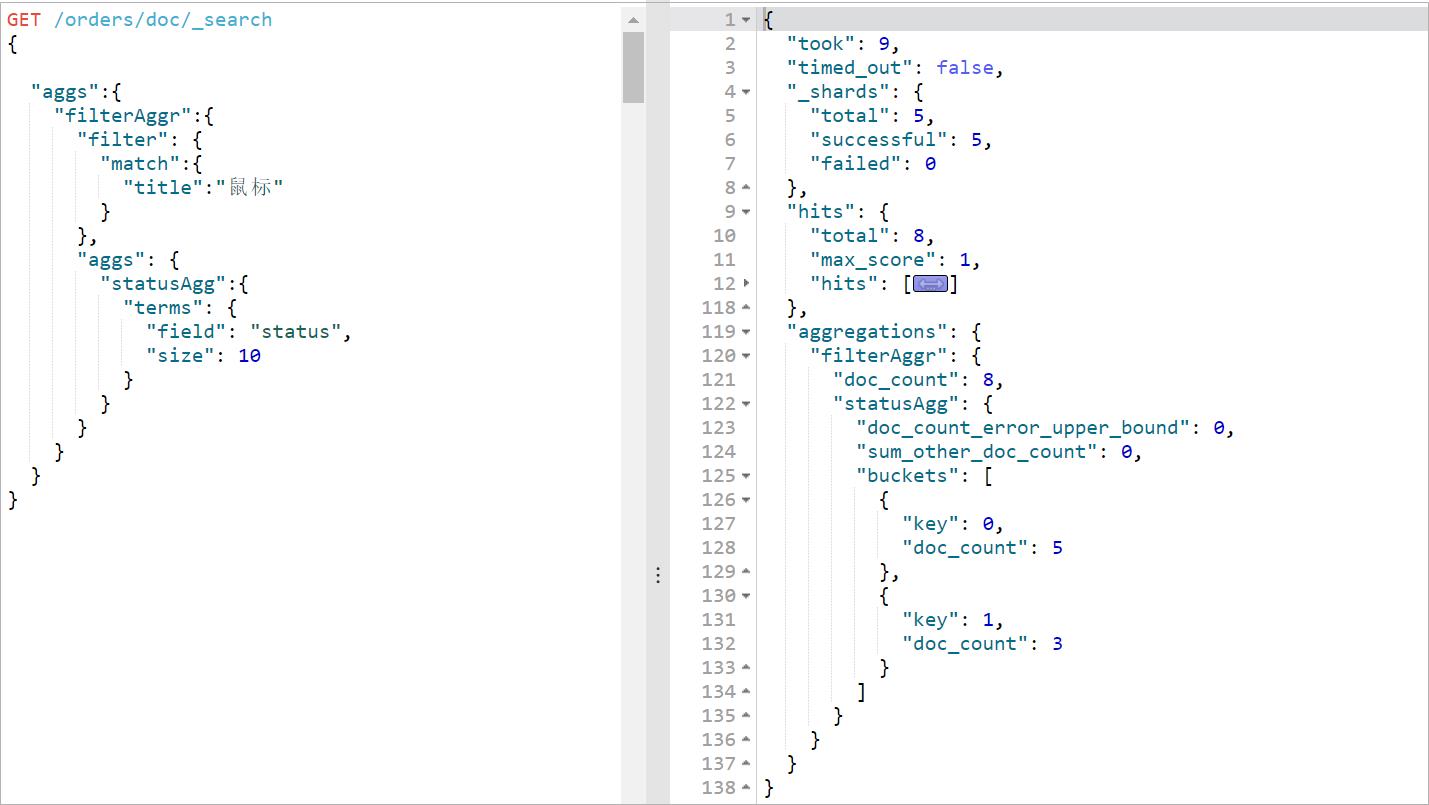
过滤聚合,对文档进行过滤,案例:先过滤title包含“鼠标”的,然后再使用status进行terms统计
GET /orders/doc/_search
"aggs":
"filterAggr":
"filter": //过滤
"match":
"title":"鼠标"
,
"aggs":
"statusAgg":
"terms":
"field": "status",
"size": 10
执行效果
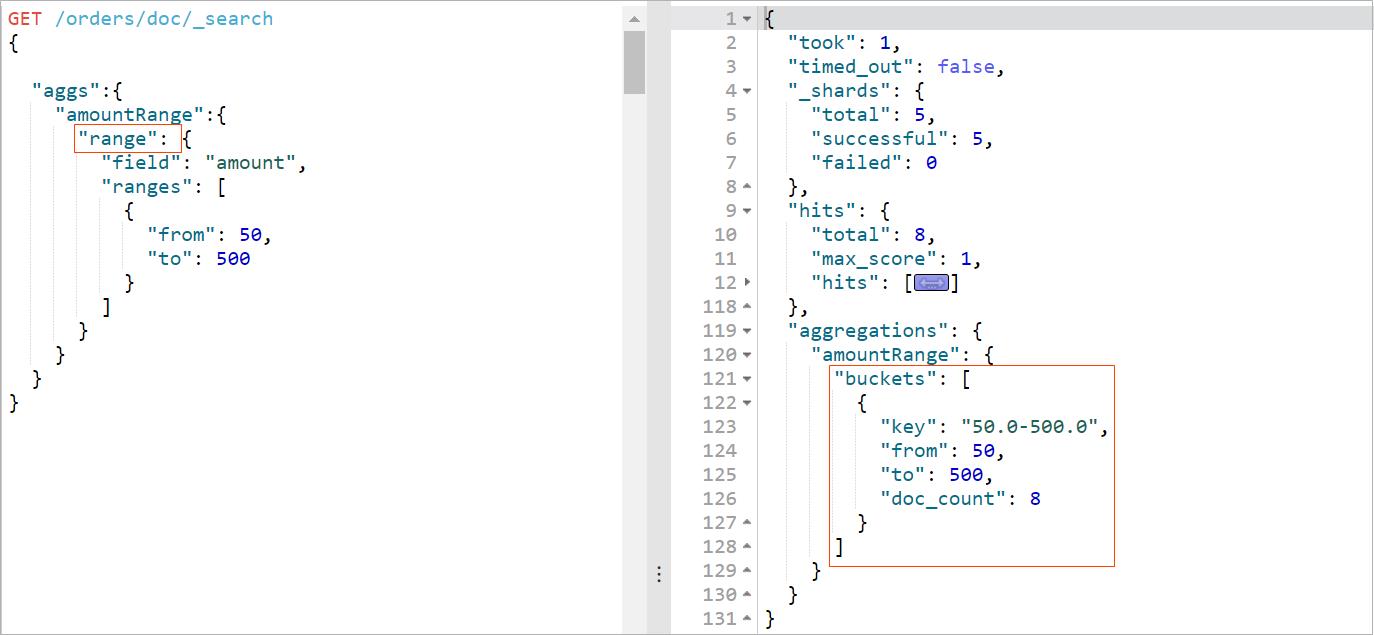
范围聚合 Range Aggregation
Range Aggregation 范围聚合,根据某个字段的范围值来分桶聚合。可以通过from和to来指定范围。案例:统计金额范围在 50到500之间的文档数量。
直方图 Histogram Aggregation
Histogram Aggregation 直方图聚合,根据某个数值型字段进行动态计算分桶,案例:根据金额进行分桶,分桶的的间距为200,如下:
 解释:200到400的有3个文档 ; 600到800的有3个文档
解释:200到400的有3个文档 ; 600到800的有3个文档
聚合实战
该案例在上一 篇案例(DSL查询+高亮) 的基础上加上聚合查询,这里简单演示了3种聚合:sum ; stats ;terms 代码如下:
@Test
public void testSearch()
//查询构建器
NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder();
//设置分页:0开始第一页, 每页10数
builder.withPageable(PageRequest.of(0,10));
//设置排序 : 金额倒排
builder.withSort(SortBuilders.fieldSort("amount").order(SortOrder.DESC));
//构建组合查询
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
//标题包含鼠标
boolQuery.must(QueryBuilders.matchQuery("title","鼠标"))
//状态值查询
//.filter(QueryBuilders.termQuery("status",1))
//金额范围查询
.filter(QueryBuilders.rangeQuery("amount").gte(10).lte(2000));
//添加查询条件
builder.withQuery(boolQuery);
//设置高亮=========================================================================================================
HighlightBuilder.Field highlightField = new HighlightBuilder.Field("title")
.preTags("<span style='color:red'>")
.postTags("</span>");
builder.withHighlightFields(highlightField);
//聚合查询=============================================================================================================
//对amount使用sum聚合
SumAggregationBuilder sumAggregationBuilder = AggregationBuilders.sum("amountSumAgg").field("amount");
//stats聚合,包括:sum,avg,min,max,count
StatsAggregationBuilder statsAggregationBuilder = AggregationBuilders.stats("amountStatsAgg").field("amount");
//对status使用terms桶聚合
TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders.terms("statusTermsAgg").field("status");
//把聚合添加到builder
builder.addAggregation(sumAggregationBuilder).addAggregation(statsAggregationBuilder).addAggregation(termsAggregationBuilder);
//执行搜索=============================================================================================================
//Page<OrderDoc> page = orderRepository.search(builder.build());
AggregatedPage<OrderDoc> page = template.queryForPage(builder.build(), OrderDoc.class, highlightResultMapper);
//获取条数
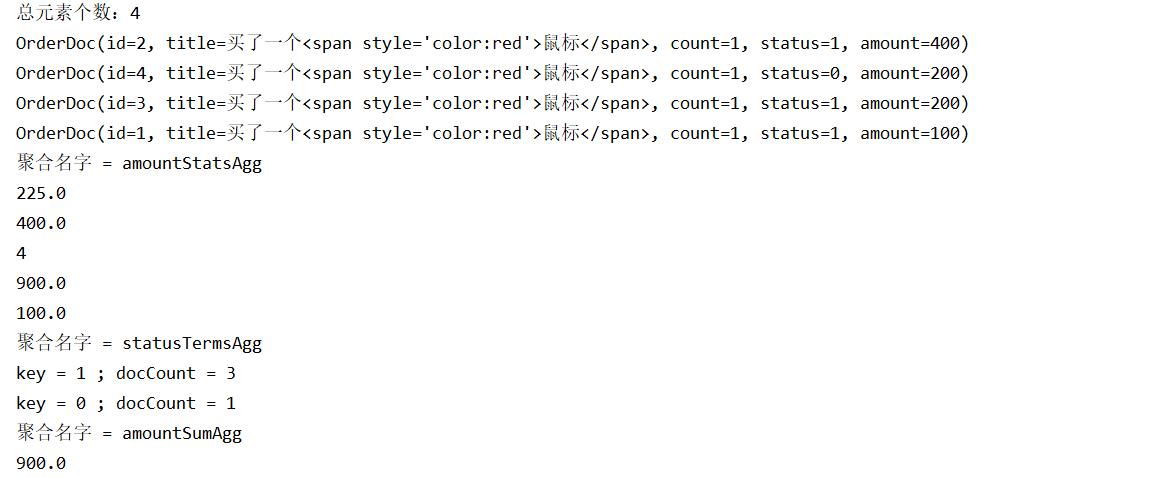
System.out.println("总元素个数:"+page.getTotalElements());
//打印列表
page.getContent().forEach(System.out::println);
//聚合结果=============================================================================================================
Map<String, Aggregation> aggregationMap = page.getAggregations().getAsMap();
aggregationMap.entrySet().forEach(aggregationEntry ->
//聚合名字
String aggName = aggregationEntry.getKey();
Aggregation aggregation = aggregationEntry.getValue();
System.out.println("聚合名字 = "+aggName);
if(aggregation instanceof ParsedLongTerms)
//对应terms聚合
ParsedLongTerms agg = (ParsedLongTerms) aggregation;
agg.getBuckets().forEach(bucket->
String key = bucket.getKeyAsString();
long docCount = bucket.getDocCount();
System.out.println("key = "+key +" ; docCount = "+docCount);
);
if(aggregation instanceof ParsedStats)
//对应stats聚合
ParsedStats agg = (ParsedStats) aggregation;
System.out.println(agg.getAvg());
System.out.println(agg.getMax());
System.out.println(agg.getCount());
System.out.println(agg.getSum());
System.out.println(agg.getMin());
if(aggregation instanceof ParsedSum)
//对应sum聚合
ParsedSum agg = (ParsedSum) aggregation;
System.out.println(agg.getValue());
);
你可以编写一个结果对象对文档列表数据和聚合数据进行封装,然后返回给前端页面。这里打印的效果如下
文章结束,希望对你有所帮助,喜欢的话请给个好评,评论过百,我就是秃头也出下章。
以上是关于七.全文检索ElasticSearch经典入门-聚合查询的主要内容,如果未能解决你的问题,请参考以下文章