机器学习正则化(L1正则化L2正则化)
Posted 小葵花幼儿园园长
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习正则化(L1正则化L2正则化)相关的知识,希望对你有一定的参考价值。
正则化
正则化
1. 正则化介绍
正则化 (Regularization)
正则化是什么?
- 正则化(Regularization)是一类通过限制模型复杂度,从而避免过拟合,提高泛化能力的方法
PS(
传统的机器学习中,提高泛化能力的方法主要是限制模型复杂度,比如采用ℓ1 和ℓ2 正则化等方式.
在训练深度神经网络时,特别是在过度参数化(Over-Parameterization)时,ℓ1 和ℓ2 正则化的效果往往不如浅层机器学习模型中显著.
过度参数化是指模型参数的数量远远大于训练数据的数量.因此训练深度学习模型时,往往还会使用其他的正则化方法,比如数据增强、提前停止、丢弃法、集成法等.
)
正则化干什么用?
- 要让AI模型不过于信赖样本数据
- 是的函数更加平滑,防止模型过拟合
小结:
为什么要正则化:让模型不要过于依赖样本数据
正则化主要思想:降低模型的复杂度
正则化主要目的:防止模型过拟合
正则化实现思路:最小化损失Loss+ 最小复杂度
正则化终极目标:提升模型泛化Generalization的能力
2. 常见正则化方法
正则化有不同的策略,目前来讲主要有参数正则化、经验正则化
参数正则的L2/L1 Regularization 范数正则化目前用的是最多的
正则化目的:对损失函数加上一个约束(也叫惩罚项),减小其解的范围
2.1 0范数
概念: L0范数是指向量中非0的元素的个数。
2.2 L1范数
概念: L1范数是指向量中各个元素绝对值之和。
对于向量:
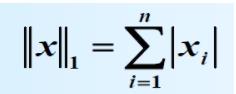
对于矩阵:

特点:
- ℓ1 范数.ℓ1 范数的引入通常会使得参数有一定稀疏性
- 缺点:优化的慢
2.3 L2范数
概念: L2范数是指向量各元素的平方和然后求平方根。
对于向量:
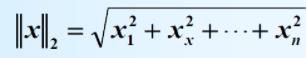
对于矩阵:

特点:
- 相对于L1正则化,L2正则化收敛的更加快一点。
- L2 正则化能够得到比较小的参数,小到可以被忽略,但是无法小到0,也就不具有稀疏性
2.4 q-范数
概念: 向量元素绝对值的q次幂的累加和再1/q次幂
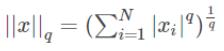
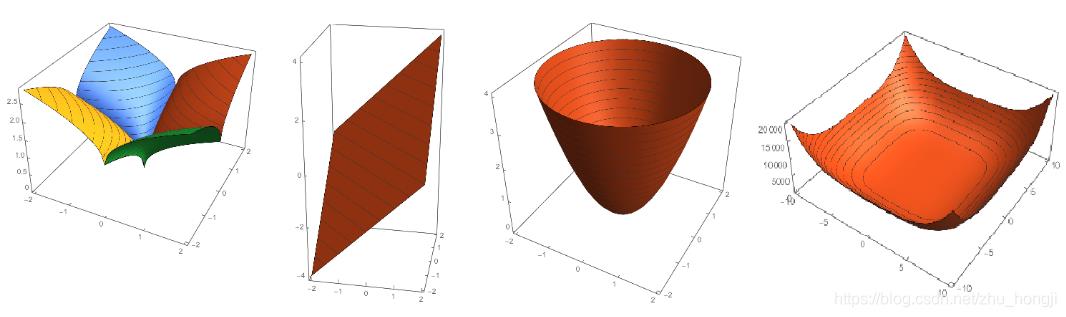
小结
不同范数q对应的曲线 :

对应三维图:
以上是关于机器学习正则化(L1正则化L2正则化)的主要内容,如果未能解决你的问题,请参考以下文章