ElasticSearch存储
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch存储相关的知识,希望对你有一定的参考价值。
参考技术A 使用ElasticSearch快一年了,自认为相关API使用的还比较6,产品提的一些搜索需求实现起来都从心应手;但是前几天同事的一个问题直接将我打回到小白,同事问了句:“ ElasticSearch的索引是怎么存储的?删除文档和更新文档是怎么实现的? ”,当时我就懵逼了,说了句得查一下,好尴尬......
回想起来发现自己从来都没有深入了解过这些细节,于是便觉得非常有必要对ElasticSearch的文档存储做一次深入的了解,知其然不知其所以然对于我们来说是远远不够的,在ElasticSearch中,文档( Document )存储的介质分为内存和硬盘两种:
同时,ElasticSearch进程自身的运行也需要内存空间,必须保证ElasticSearch进程有充足的运行时内存。为了使ElasticSearch引擎达到最佳性能,必须合理分配有限的内存和硬盘资源。
ElasticSearch引擎把文档数据写入到倒排索引( Inverted Index )的数据结构中,倒排索引建立的是分词( Term )和文档( Document )之间的映射关系,在倒排索引中,数据是面向词( Term )而不是面向文档( Document )的。
举个栗子,假设我们有两个文档,每个文档的content域包含如下内容:
1. The quick brown fox jumped over the lazy dog
2. Quick brown foxes leap over lazy dogs in summer
文档和词之间的关系如下图:
字段值被分析之后,存储在倒排索引中,倒排索引存储的是分词( Term )和文档( Doc )之间的关系,简化版的倒排索引如下图:
从图中可以看出,倒排索引有一个词条的列表,每个分词在列表中是唯一的,记录着词条出现的次数,以及包含词条的文档。实际中ElasticSearch引擎创建的倒排索引比这个复杂得多。
段是倒排索引的组成部分,倒排索引是由段( Segment )组成的,段存储在硬盘( Disk )文件中。 索引段不是实时更新的,这意味着,段在写入硬盘之后,就不再被更新。在删除文档时,ElasticSearch引擎把已删除的文档的信息存储在一个单独的文件中,在搜索数据时,ElasticSearch引擎首先从段中执行查询,再从查询结果中过滤被删除的文档 。这意味着,段中存储着被删除的文档,这使得段中含有”正常文档“的密度降低。
多个段可以通过段合并(Segment Merge)操作把“已删除”的文档将从段中物理删除,把未删除的文档合并到一个新段中,新段中没有”已删除文档“,因此,段合并操作能够提高索引的查找速度 ;但是,段合并是IO密集型操作,需要消耗大量的硬盘IO。
在ElasticSearch中,大多数查询都需要从硬盘文件(索引的段数据存储在硬盘文件中)中获取数据;因此, 在全局配置文件elasticsearch.yml 中,把结点的路径(Path)配置为性能较高的硬盘,能够提高查询性能 。默认情况下,ElasticSearch使用基于安装目录的相对路径来配置结点的路径,安装目录由属性path.home显示,在home path下,ElasticSearch自动创建config,data,logs和plugins目录,一般情况下不需要对结点路径单独配置。结点的文件路径配置项:
path.data:设置ElasticSearch结点的索引数据保存的目录,多个数据文件使用逗号隔开。
例如,path.data: /path/to/data1,/path/to/data2 ;
path.work:设置ElasticSearch的临时文件保存的目录;
映射参数index决定ElasticSearch引擎是否对文本字段执行分析操作,也就是说分析操作把文本分割成一个一个的分词,也就是标记流( Token Stream ),把分词编入索引,使分词能够被搜索到:
1) 当index为analyzed时,该字段是分析字段,ElasticSearch引擎对该字段执行分析操作,把文本分割成分词流,存储在倒排索引中,使其支持全文搜索。
2)当index为not_analyzed时,该字段不会被分析,ElasticSearch引擎把原始文本作为单个分词存储在倒排索引中,不支持全文搜索,但是支持词条级别的搜索;也就是说,字段的原始文本不经过分析而存储在倒排索引中,把原始文本编入索引,在搜索的过程中,查询条件必须全部匹配整个原始文本。
3)当index为no时,该字段不会被存储到倒排索引中,不会被搜索到。
字段的原始值是否被存储到倒排索引,是由映射参数store决定的,默认值是false,也就是,原始值不存储到倒排索引中。
映射参数index和store的区别在于:
store用于获取(Retrieve)字段的原始值,不支持查询,可以使用投影参数fields,对stroe属性为true的字段进行过滤,只获取(Retrieve)特定的字段,减少网络负载;
index用于查询(Search)字段,当index为analyzed时,对字段的分词执行全文查询;当index为not_analyzed时,字段的原始值作为一个分词,只能对字段的原始文本执行词条查询;
如果设置字段的index属性为not_analyzed,原始文本将作为单个分词,其最大长度跟UTF8 编码有关,默认的最大长度是32766Bytes(约32KB),如果字段的文本超过该限制,那么ElasticSearch将跳过( Skip )该文档,并在Response中抛出异常消息:
operation[607]: index returned 400 _index: ebrite _type: events _id: 76860 _version: 0 error: Type: illegal_argument_exception Reason: "Document contains at least one immense term in field="event_raw" (whose UTF8 encoding is longer than the max length 32766), all of which were skipped. Please correct the analyzer to not produce such terms. The prefix of the first immense term is: \'[112, 114,... 115]...\', original message: bytes can be at most 32766 in length; got 35100" CausedBy:Type: max_bytes_length_exceeded_exception Reason: "bytes can be at most 32766 in length; got 35100"
可以在字段中设置ignore_above属性,该属性值指的是字符数量,而不是字节数量;由于一个UTF8字符最多占用3个字节,因此,可以设置
“ignore_above”:10000
这样,超过30000字节之后的字符将会被分析器忽略,单个分词( Term )的最大长度是30000Bytes。
The value for ignore_above is the character count, but Lucene counts bytes. If you use UTF-8 text with many non-ASCII characters, you may want to set the limit to 32766 / 3 = 10922 since UTF-8 characters may occupy at most 3 bytes.
默认情况下,大多数字段被索引之后,能够被搜索到。 倒排索引是由一个有序的词条列表构成的,每一个词条在列表中都是唯一存在的,通过这种数据存储模式,你可以很快查找到包含某一个词条的文档列表 。
但是,排序和聚合操作采用相反的数据访问模式,这两种操作不是查找词条以发现文档,而是查找文档,以发现字段中包含的词条。ElasticSearch使用列式存储实现排序和聚合查询。
文档值( doc_values )是存储在硬盘上的数据结构,在索引时( index time )根据文档的原始值创建,文档值是一个列式存储风格的数据结构,非常适合执行存储和聚合操作,除了字符类型的分析字段之外,其他字段类型都支持文档值存储。默认情况下,字段的文档值存储是启用的,除了字符类型的分析字段之外。如果不需要对字段执行排序或聚合操作,可以禁用字段的文档值,以节省硬盘空间。
字符类型的分析字段,不支持文档值(doc_values),但支持fielddata数据结构。fielddata数据结构存储在JVM的堆内存中。相比文档值(数据存储在硬盘上),fielddata字段(数据存储在内存中)的查询性能更高。默认情况下,ElasticSearch引擎在第一次对字段执行聚合或排序查询时(query-time),创建fielddata数据结构;在后续的查询请求中,ElasticSearch引擎使用fielddata数据结构以提高聚合和排序的查询性能。
在ElasticSearch中,倒排索引的各个段( segment )的数据存储在硬盘文件上,从整个倒排索引的段中读取字段数据之后,ElasticSearch引擎首先反转词条和文档之间的关系,创建文档和词条之间的关系,即创建顺排索引,然后把顺排索引存储在JVM的堆内存中。把倒排索引加载到fielddata结构是一个非常消耗硬盘IO资源的过程。因此,数据一旦被加载到内存,最好保持在内存中,直到索引段( segment )的生命周期结束。
默认情况下,倒排索引的每个段( segment ),都会创建相应的fielddata结构,以存储字符类型的分析字段值,但是,需要注意的是,分配的JVM堆内存是有限的,Fileddata把数据存储在内存中,会占用过多的JVM堆内存,甚至耗尽JVM赖以正常运行的内存空间,反而会降低ElasticSearch引擎的查询性能。
fielddata会消耗大量的JVM内存,因此,尽量为JVM设置大的内存,不要为不必要的字段启用fielddata存储。通过format参数控制是否启用字段的fielddata特性,字符类型的分析字段,fielddata的默认值是paged_bytes,这就意味着,默认情况下,字符类型的分析字段启用fielddata存储。一旦禁用fielddata存储,那么字符类型的分析字段将不再支持排序和聚合查询。
loading属性控制fielddata加载到内存的时机,可能的值是lazy,eager和eager_global_ordinals,默认值是lazy。
lazy:fielddata只在需要时加载到内存,默认情况下,在第一次搜索时,fielddata被加载到内存中;但是,如果查询一个非常大的索引段(Segment),lazy加载方式会产生较大的时间延迟。
eager:在倒排索引的段可用之前,其数据就被加载到内存,eager加载方式能够减少查询的时间延迟,但是,有些数据可能非常冷,以至于没有请求来查询这些数据,但是冷数据依然被加载到内存中,占用紧缺的内存资源。
eager_global_ordinals:按照global ordinals积极把fielddata加载到内存。
ElasticSearch使用 JAVA_OPTS 环境变量( Environment Variable )启动JVM进程,在 JAVA_OPTS 中,最重要的配置是: -Xmx参数控制分配给JVM进程的最大内存,-Xms参数控制分配给JVM进程的最小内存 。(在ElasticSearch启动命令后面可以通过参数方式配置,如: /usr/local/elasticsearch/bin/elasticsearch -d --Xmx=10g --Xms=10g )通常情况下,使用默认的配置就能满足工程需要。
ES_HEAP_SIZE 环境变量控制分配给JVM进程的堆内存( Heap Memory )大小,顺排索引( fielddata )的数据存储在堆内存( Heap Memory )中。
大多数应用程序尝试使用尽可能多的内存,并尽可能把未使用的内存换出,但是,内存换出会影响ElasticSearch引擎的查询性能,推荐启用内存锁定,禁用ElasticSearch内存的换进换出。
在全局配置文档 elasticsearch.yml 中,设置 bootstrap.memory_lock 为ture,这将锁定ElasticSearch进程的内存地址空间,阻止ElasticSearch内存被OS换出( Swap out )。
通过学习,算是对ElasticSearch索引存储及更新有了一个较深的了解,至少能让我从容去面对同事的提问,但与此同时给我敲响了警钟,在使用一门技术的同时,更应该去了解它具体的原理,而不仅仅是停留在使用级别;在学习的路上,我们仍需要更加努力......
Elasticsearch Elasticsearch中数据是如何存储的

1.概述
转载:https://elasticsearch.cn/article/6178
转载防丢失
前言
很多使用Elasticsearch的同学会关心数据存储在ES中的存储容量,会有这样的疑问:xxTB的数据入到ES会使用多少存储空间。这个问题其实很难直接回答的,只有数据写入ES后,才能观察到实际的存储空间。比如同样是1TB的数据,写入ES的存储空间可能差距会非常大,可能小到只有300~400GB,也可能多到6-7TB,为什么会造成这么大的差距呢?究其原因,我们来探究下Elasticsearch中的数据是如何存储。文章中我以Elasticsearch 2.3版本为示例,对应的lucene版本是5.5,Elasticsearch现在已经来到了6.5版本,数字类型、列存等存储结构有些变化,但基本的概念变化不多,文章中的内容依然适用。
Elasticsearch索引结构
Elasticsearch对外提供的是index的概念,可以类比为DB,用户查询是在index上完成的,每个index由若干个shard组成,以此来达到分布式可扩展的能力。比如下图是一个由10个shard组成的index。
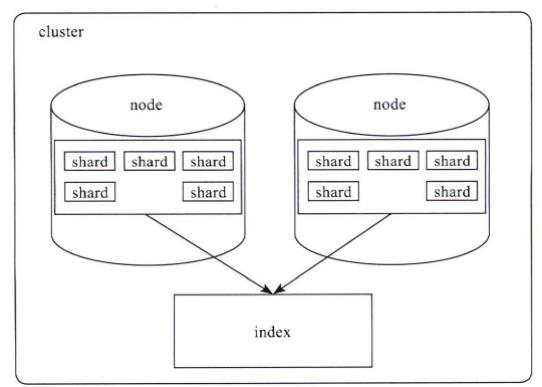
shard是Elasticsearch数据存储的最小单位,index的存储容量为所有shard的存储容量之和。Elasticsearch集群的存储容量则为所有index存储容量之和。
一个shard就对应了一个lucene的library。对于一个shard,Elasticsearch增加了translog的功能,类似于HBase WAL,是数据写入过程中的中间数据,其余的数据都在lucene库中管理的。
所以Elasticsearch索引使用的存储内容主要取决于lucene中的数据存储。
lucene数据存储
下面我们主要看下lucene的文件内容,在了解lucene文件内容前,大家先了解些lucene的基本概念。
lucene基本概念
segment : lucene内部的数据是由一个个segment组成的,写入lucene的数据并不直接落盘,而是先写在内存中,经过了refresh间隔,lucene才将该时间段写入的全部数据refresh成一个segment,segment多了之后会进行merge成更大的segment。lucene查询时会遍历每个segment完成。由于lucene* 写入的数据是在内存中完成,所以写入效率非常高。但是也存在丢失数据的风险,所以Elasticsearch基于此现象实现了translog,只有在segment数据落盘后,Elasticsearch才会删除对应的translog。
doc : doc表示lucene中的一条记录
field :field表示记录中的字段概念,一个doc由若干个field组成。
term :term是lucene中索引的最小单位,某个field对应的内容如果是全文检索类型,会将内容进行分词,分词的结果就是由term组成的。如果是不分词的字段,那么该字段的内容就是一个term。
倒排索引(inverted index): lucene索引的通用叫法,即实现了term到doc list的映射。
正排数据:搜索引擎的通用叫法,即原始数据,可以理解为一个doc list。
docvalues :Elasticsearch中的列式存储的名称,Elasticsearch除了存储原始存储、倒排索引,还存储了一份docvalues,用作分析和排序。
lucene文件内容
lucene包的文件是由很多segment文件组成的,segments_xxx文件记录了lucene包下面的segment文件数量。每个segment会包含如下的文件。
| Name | Extension | Brief Description |
|---|---|---|
| Segment Info | .si | segment的元数据文件 |
| Compound File | .cfs, .cfe | 一个segment包含了如下表的各个文件,为减少打开文件的数量,在segment小的时候,segment的所有文件内容都保存在cfs文件中,cfe文件保存了lucene各文件在cfs文件的位置信息 |
| Fields | .fnm | 保存了fields的相关信息 |
| Field Index | .fdx | 正排存储文件的元数据信息 |
| Field Data | .fdt | 存储了正排存储数据,写入的原文存储在这 |
| Term Dictionary | .tim | 倒排索引的元数据信息 |
| Term Index | .tip | 倒排索引文件,存储了所有的倒排索引数据 |
| Frequencies | .doc | 保存了每个term的doc id列表和term在doc中的词频 |
| Positions | .pos | Stores position information about where a term occurs in the index 全文索引的字段,会有该文件,保存了term在doc中的位置 |
| Payloads | .pay | Stores additional per-position metadata information such as character offsets and user payloads 全文索引的字段,使用了一些像payloads的高级特性会有该文件,保存了term在doc中的一些高级特性 |
| Norms | .nvd, .nvm | 文件保存索引字段加权数据 |
| Per-Document Values | .dvd, .dvm | lucene的docvalues文件,即数据的列式存储,用作聚合和排序 |
| Term Vector Data | .tvx, .tvd, .tvf | Stores offset into the document data file 保存索引字段的矢量信息,用在对term进行高亮,计算文本相关性中使用 |
| Live Documents | .liv | 记录了segment中删除的doc |
测试数据示例
下面我们以真实的数据作为示例,看看lucene中各类型数据的容量占比。
写100w数据,有一个uuid字段,写入的是长度为36位的uuid,字符串总为3600w字节,约为35M。
数据使用一个shard,不带副本,使用默认的压缩算法,写入完成后merge成一个segment方便观察。
使用线上默认的配置,uuid存为不分词的字符串类型。创建如下索引:
PUT test_field
{
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0",
"refresh_interval": "30s"
}
},
"mappings": {
"type": {
"_all": {
"enabled": false
},
"properties": {
"uuid": {
"type": "string",
"index": "not_analyzed"
}
}
}
}
}
首先写入100w不同的uuid,使用磁盘容量细节如下:
health status index pri rep docs.count docs.deleted store.size pri.store.size
green open test_field 1 0 1000000 0 122.7mb 122.7mb
-rw-r--r-- 1 weizijun staff 41M Aug 19 21:23 _8.fdt
-rw-r--r-- 1 weizijun staff 17K Aug 19 21:23 _8.fdx
-rw-r--r-- 1 weizijun staff 688B Aug 19 21:23 _8.fnm
-rw-r--r-- 1 weizijun staff 494B Aug 19 21:23 _8.si
-rw-r--r-- 1 weizijun staff 265K Aug 19 21:23 _8_Lucene50_0.doc
-rw-r--r-- 1 weizijun staff 44M Aug 19 21:23 _8_Lucene50_0.tim
-rw-r--r-- 1 weizijun staff 340K Aug 19 21:23 _8_Lucene50_0.tip
-rw-r--r-- 1 weizijun staff 37M Aug 19 21:23 _8_Lucene54_0.dvd
-rw-r--r-- 1 weizijun staff 254B Aug 19 21:23 _8_Lucene54_0.dvm
-rw-r--r-- 1 weizijun staff 195B Aug 19 21:23 segments_2
-rw-r--r-- 1 weizijun staff 0B Aug 19 21:20 write.lock
可以看到正排数据、倒排索引数据,列存数据容量占比几乎相同,正排数据和倒排数据还会存储Elasticsearch的唯一id字段,所以容量会比列存多一些。
35M的uuid存入Elasticsearch后,数据膨胀了3倍,达到了122.7mb。Elasticsearch竟然这么消耗资源,不要着急下结论,接下来看另一个测试结果。
我们写入100w一样的uuid,然后看看Elasticsearch使用的容量。
health status index pri rep docs.count docs.deleted store.size pri.store.size
green open test_field 1 0 1000000 0 13.2mb 13.2mb
-rw-r--r-- 1 weizijun staff 5.5M Aug 19 21:29 _6.fdt
-rw-r--r-- 1 weizijun staff 15K Aug 19 21:29 _6.fdx
-rw-r--r-- 1 weizijun staff 688B Aug 19 21:29 _6.fnm
-rw-r--r-- 1 weizijun staff 494B Aug 19 21:29 _6.si
-rw-r--r-- 1 weizijun staff 309K Aug 19 21:29 _6_Lucene50_0.doc
-rw-r--r-- 1 weizijun staff 7.0M Aug 19 21:29 _6_Lucene50_0.tim
-rw-r--r-- 1 weizijun staff 195K Aug 19 21:29 _6_Lucene50_0.tip
-rw-r--r-- 1 weizijun staff 244K Aug 19 21:29 _6_Lucene54_0.dvd
-rw-r--r-- 1 weizijun staff 252B Aug 19 21:29 _6_Lucene54_0.dvm
-rw-r--r-- 1 weizijun staff 195B Aug 19 21:29 segments_2
-rw-r--r-- 1 weizijun staff 0B Aug 19 21:26 write.lock
这回35M的数据Elasticsearch容量只有13.2mb,其中还有主要的占比还是Elasticsearch的唯一id,100w的uuid几乎不占存储容积。
所以在Elasticsearch中建立索引的字段如果基数越大(count distinct),越占用磁盘空间。
我们再看看存100w个不一样的整型会是如何。
health status index pri rep docs.count docs.deleted store.size pri.store.size
green open test_field 1 0 1000000 0 13.6mb 13.6mb
-rw-r--r-- 1 weizijun staff 6.1M Aug 28 10:19 _42.fdt
-rw-r--r-- 1 weizijun staff 22K Aug 28 10:19 _42.fdx
-rw-r--r-- 1 weizijun staff 688B Aug 28 10:19 _42.fnm
-rw-r--r-- 1 weizijun staff 503B Aug 28 10:19 _42.si
-rw-r--r-- 1 weizijun staff 2.8M Aug 28 10:19 _42_Lucene50_0.doc
-rw-r--r-- 1 weizijun staff 2.2M Aug 28 10:19 _42_Lucene50_0.tim
-rw-r--r-- 1 weizijun staff 83K Aug 28 10:19 _42_Lucene50_0.tip
-rw-r--r-- 1 weizijun staff 2.5M Aug 28 10:19 _42_Lucene54_0.dvd
-rw-r--r-- 1 weizijun staff 228B Aug 28 10:19 _42_Lucene54_0.dvm
-rw-r--r-- 1 weizijun staff 196B Aug 28 10:19 segments_2
-rw-r--r-- 1 weizijun staff 0B Aug 28 10:16 write.lock
从结果可以看到,100w整型数据,Elasticsearch的存储开销为13.6mb。如果以int型计算100w数据的长度的话,为400w字节,大概是3.8mb数据。忽略Elasticsearch唯一id字段的影响,Elasticsearch实际存储容量跟整型数据长度差不多。
我们再看一下开启最佳压缩参数对存储空间的影响:
health status index pri rep docs.count docs.deleted store.size pri.store.size
green open test_field 1 0 1000000 0 107.2mb 107.2mb
-rw-r--r-- 1 weizijun staff 25M Aug 20 12:30 _5.fdt
-rw-r--r-- 1 weizijun staff 6.0K Aug 20 12:30 _5.fdx
-rw-r--r-- 1 weizijun staff 688B Aug 20 12:31 _5.fnm
-rw-r--r-- 1 weizijun staff 500B Aug 20 12:31 _5.si
-rw-r--r-- 1 weizijun staff 265K Aug 20 12:31 _5_Lucene50_0.doc
-rw-r--r-- 1 weizijun staff 44M Aug 20 12:31 _5_Lucene50_0.tim
-rw-r--r-- 1 weizijun staff 322K Aug 20 12:31 _5_Lucene50_0.tip
-rw-r--r-- 1 weizijun staff 37M Aug 20 12:31 _5_Lucene54_0.dvd
-rw-r--r-- 1 weizijun staff 254B Aug 20 12:31 _5_Lucene54_0.dvm
-rw-r--r-- 1 weizijun staff 224B Aug 20 12:31 segments_4
-rw-r--r-- 1 weizijun staff 0B Aug 20 12:00 write.lock
结果中可以发现,只有正排数据会启动压缩,压缩能力确实强劲,不考虑唯一id字段,存储容量大概压缩到接近50%。
我们还做了一些实验,Elasticsearch默认是开启_all参数的,_all可以让用户传入的整体json数据作为全文检索的字段,可以更方便的检索,但在现实场景中已经使用的不多,相反会增加很多存储容量的开销,可以看下开启_all的磁盘空间使用情况:
health status index pri rep docs.count docs.deleted store.size pri.store.size
green open test_field 1 0 1000000 0 162.4mb 162.4mb
-rw-r--r-- 1 weizijun staff 41M Aug 18 22:59 _20.fdt
-rw-r--r-- 1 weizijun staff 18K Aug 18 22:59 _20.fdx
-rw-r--r-- 1 weizijun staff 777B Aug 18 22:59 _20.fnm
-rw-r--r-- 1 weizijun staff 59B Aug 18 22:59 _20.nvd
-rw-r--r-- 1 weizijun staff 78B Aug 18 22:59 _20.nvm
-rw-r--r-- 1 weizijun staff 539B Aug 18 22:59 _20.si
-rw-r--r-- 1 weizijun staff 7.2M Aug 18 22:59 _20_Lucene50_0.doc
-rw-r--r-- 1 weizijun staff 4.2M Aug 18 22:59 _20_Lucene50_0.pos
-rw-r--r-- 1 weizijun staff 73M Aug 18 22:59 _20_Lucene50_0.tim
-rw-r--r-- 1 weizijun staff 832K Aug 18 22:59 _20_Lucene50_0.tip
-rw-r--r-- 1 weizijun staff 37M Aug 18 22:59 _20_Lucene54_0.dvd
-rw-r--r-- 1 weizijun staff 254B Aug 18 22:59 _20_Lucene54_0.dvm
-rw-r--r-- 1 weizijun staff 196B Aug 18 22:59 segments_2
-rw-r--r-- 1 weizijun staff 0B Aug 18 22:53 write.lock
开启_all比不开启多了40mb的存储空间,多的数据都在倒排索引上,大约会增加30%多的存储开销。所以线上都直接禁用。
然后我还做了其他几个尝试,为了验证存储容量是否和数据量成正比,写入1000w数据的uuid,发现存储容量基本为100w数据的10倍。我还验证了数据长度是否和数据量成正比,发现把uuid增长2倍、4倍,存储容量也响应的增加了2倍和4倍。在此就不一一列出数据了。
lucene各文件具体内容和实现
lucene数据元信息文件
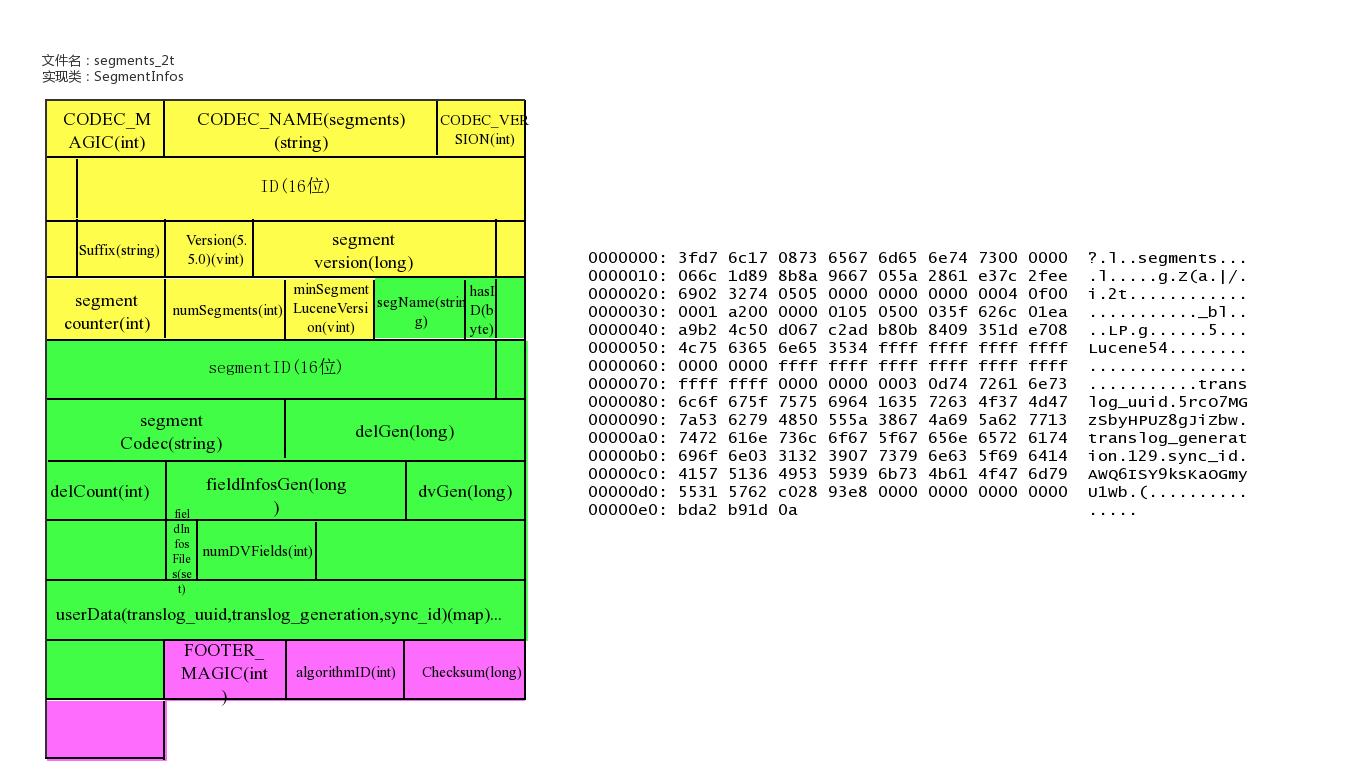
文件名为:segments_xxx
该文件为lucene数据文件的元信息文件,记录所有segment的元数据信息。
该文件主要记录了目前有多少segment,每个segment有一些基本信息,更新这些信息定位到每个segment的元信息文件。
lucene元信息文件还支持记录userData,Elasticsearch可以在此记录translog的一些相关信息。
文件示例
具体实现类
public final class SegmentInfos implements Cloneable, Iterable<SegmentCommitInfo> {
// generation是segment的版本的概念,从文件名中提取出来,实例中为:2t/101
private long generation; // generation of the "segments_N" for the next commit
private long lastGeneration; // generation of the "segments_N" file we last successfully read
// or wrote; this is normally the same as generation except if
// there was an IOException that had interrupted a commit
/** Id for this commit; only written starting with Lucene 5.0 */
private byte[] id;
/** Which Lucene version wrote this commit, or null if this commit is pre-5.3. */
private Version luceneVersion;
/** Counts how often the index has been changed. */
public long version;
/** Used to name new segments. */
// TODO: should this be a long ...?
public int counter;
/** Version of the oldest segment in the index, or null if there are no segments. */
private Version minSegmentLuceneVersion;
private List<SegmentCommitInfo> segments = new ArrayList<>();
/** Opaque Map<String, String> that user can specify during IndexWriter.commit */
public Map<String,String> userData = Collections.emptyMap();
}
/** Embeds a [read-only] SegmentInfo and adds per-commit
* fields.
*
* @lucene.experimental */
public class SegmentCommitInfo {
/** The {@link SegmentInfo} that we wrap. */
public final SegmentInfo info;
// How many deleted docs in the segment:
private int delCount;
// Generation number of the live docs file (-1 if there
// are no deletes yet):
private long delGen;
// Normally 1+delGen, unless an exception was hit on last
// attempt to write:
private long nextWriteDelGen;
// Generation number of the FieldInfos (-1 if there are no updates)
private long fieldInfosGen;
// Normally 1+fieldInfosGen, unless an exception was hit on last attempt to
// write
private long nextWriteFieldInfosGen; //fieldInfosGen == -1 ? 1 : fieldInfosGen + 1;
// Generation number of the DocValues (-1 if there are no updates)
private long docValuesGen;
// Normally 1+dvGen, unless an exception was hit on last attempt to
// write
private long nextWriteDocValuesGen; //docValuesGen == -1 ? 1 : docValuesGen + 1;
// TODO should we add .files() to FieldInfosFormat, like we have on
// LiveDocsFormat?
// track the fieldInfos update files
private final Set<String> fieldInfosFiles = new HashSet<>();
// Track the per-field DocValues update files
private final Map<Integer,Set<String>> dvUpdatesFiles = new HashMap<>();
// Track the per-generation updates files
@Deprecated
private final Map<Long,Set<String>> genUpdatesFiles = new HashMap<>();
private volatile long sizeInBytes = -1;
}
segment的元信息文件
文件后缀:.si
每个segment都有一个.si文件,记录了该segment的元信息。
segment元信息文件中记录了segment的文档数量,segment对应的文件列表等信息。
文件示例

具体实现类
/**
* Information about a segment such as its name, directory, and files related
* to the segment.
*
* @lucene.experimental
*/
public final class SegmentInfo {
// _bl
public final String name;
/** Where this segment resides. */
public final Directory dir;
/** Id that uniquely identifies this segment. */
private final byte[] id;
private Codec codec;
// Tracks the Lucene version this segment was created with, since 3.1. Null
// indicates an older than 3.0 index, and it's used to detect a too old index.
// The format expected is "x.y" - "2.x" for pre-3.0 indexes (or null), and
// specific versions afterwards ("3.0.0", "3.1.0" etc.).
// see o.a.l.util.Version.
private Version version;
private int maxDoc; // number of docs in seg
private boolean isCompoundFile;
private Map<String,String> diagnostics;
private Set<String> setFiles;
private final Map<String,String> attributes;
}
fields信息文件
文件后缀:.fnm
该文件存储了fields的基本信息。
fields信息中包括field的数量,field的类型,以及IndexOpetions,包括是否存储、是否索引,是否分词,是否需要列存等等。
文件示例
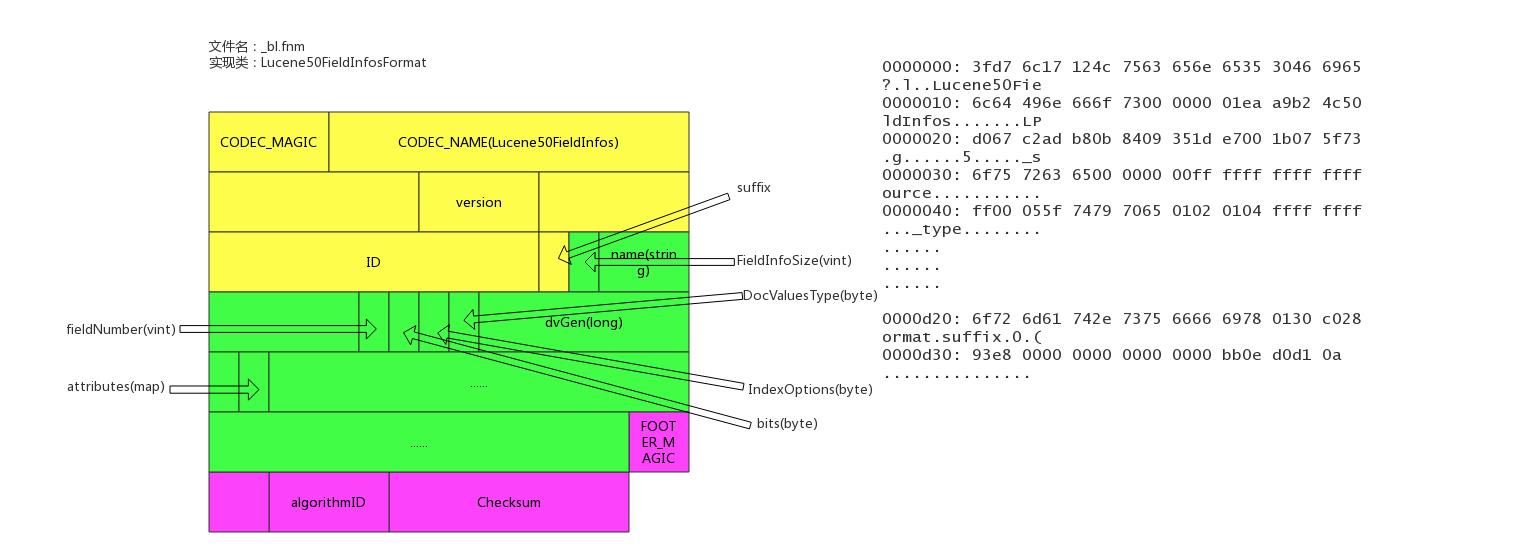
具体实现类
/**
* Access to the Field Info file that describes document fields and whether or
* not they are indexed. Each segment has a separate Field Info file. Objects
* of this class are thread-safe for multiple readers, but only one thread can
* be adding documents at a time, with no other reader or writer threads
* accessing this object.
**/
public final class FieldInfo {
/** Field's name */
public final String name;
/** Internal field number */
//field在内部的编号
public final int number;
//field docvalues的类型
private DocValuesType docValuesType = DocValuesType.NONE;
// True if any document indexed term vectors
private boolean storeTermVector;
private boolean omitNorms; // omit norms associated with indexed fields
//index的配置项
private IndexOptions indexOptions = IndexOptions.NONE;
private boolean storePayloads; // whether this field stores payloads together with term positions
private final Map<String,String> attributes;
// docvalues的generation
private long dvGen;
}
数据存储文件
文件后缀:.fdx, .fdt
索引文件为.fdx,数据文件为.fdt,数据存储文件功能为根据自动的文档id,得到文档的内容,搜索引擎的术语习惯称之为正排数据,即doc_id -> content,es的_source数据就存在这
索引文件记录了快速定位文档数据的索引信息,数据文件记录了所有文档id的具体内容。
文件示例

具体实现类
/**
* Random-access reader for {@link CompressingStoredFieldsIndexWriter}.
* @lucene.internal
*/
public final class CompressingStoredFieldsIndexReader implements Cloneable, Accountable {
private static final long BASE_RAM_BYTES_USED = RamUsageEstimator.shallowSizeOfInstance(CompressingStoredFieldsIndexReader.class);
final int maxDoc;
//docid索引,快速定位某个docid的数组坐标
final int[