基于最近邻的邻鸢尾花数据集回归问题
Posted ZHW_AI课题组
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于最近邻的邻鸢尾花数据集回归问题相关的知识,希望对你有一定的参考价值。
目录
1. 作者介绍
王倩倩,女,西安工程大学电子信息学院,2021级研究生
研究方向:智能信息处理
电子邮件:2421926488@qq.com
吴燕子,女,西安工程大学电子信息学院,2021级研究生,张宏伟人工智能课题组
研究方向:人工智能与模式识别
电子邮件:1219428323@qq.com
2.最近邻算法介绍
2.1 最近邻算法介绍
K最近邻法(k-nearest neighbor, KNN)是1967年由Cover和Hart提出的一种基本分类与回归方法,属于有监督学习的惰性学习算法(边测试,边训练),没有明显的训练过程。
存在一个样本数据集合,称作为训练样本集,样本集中每个数据都存在标签,即我们知道样本集中每一个数据与所属分类的对应关系。输入没有标签的新数据后,将新的数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本最近邻的分类标签。我们只选择样本数据集中前k个最相似的数据,这就是k最近邻算法中k的出处,通常k是不大于20的整数。最后选择k个最相似数据中出现次数最多的分类,作为新数据的分类。对于回归问题,使用KNN计算某个数据点的预测值时,模型会从训练数据集中选择离该数据点最近的k个数据点,并且把他们的y值取均值,把该均值作为新数据点的预测值。
2.2 KNN分类与回归分类
分类是判断对应类别,是最终预测的结果,要么是A要么是B要么是C,预测的结果和种类都是已经确定的,研究的目标是离散型的。
回归:回归实际上就是“最佳拟合”根据已有的数据拟合出一条最佳的直线和曲线,用于预测其他数据的目标值,回归的输出是一个具体值,比如今天吃不吃饭,预测一下明天的体重,这个体重是一个变化的值,可能是一条线上任意的一个,这就是回归,在一定的取值范围内可以随便取,研究的目标是连续的。
KNN算法的原理:
1.计算测试样本与训练集中所有样本之间的相似度(使用距离表征相似度.)
2.按照距离递增排序
3.选择与测试样本中距离最近的k个训练样本.
4.根据选择出的K个样本的标签,进行投票或平均 (投票为分类问题,求平均为回归问题)。
下图为KNN 回归模型
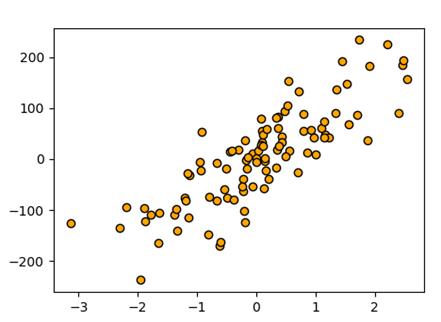
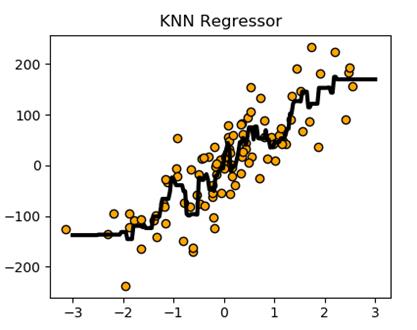
基于K最近邻算法的回归:
Sklearn实现的两种K最近邻回归算法:
① Kneighbors Regressor类:基于每个查询点的k个最近邻实现,其中k是用户指定的整数值。
② RadiusNeighborsRegressor类:基于每个查询点的固定半径r内的临点数量实现,其中r是用户指定的浮点数值
K最近邻回归适用于数据标签为连续变量的情况,K最近邻回归预测样本的标签由它最近临标签的均值计算而来,例有一系列样本坐标(X,Y),给定一个测试坐标X1,求对应曲线上对应的Y1,用KNN算法即取K个离X1最近的样本坐标,然后对他们Y1值求平均值。
2.3 KNN回归算法流程
使用kNN计算某个数据点的预测值时,模型会从训练数据集中选择离该数据点最近的k个数据点,并且把他们的y值取均值,把该均值作为新数据点的预测值。
A.找出待预测样本的K个最近的邻居
B.统计这K个邻居的标签的均值
C.这个均值就是待测样本的预测值
进行回归时,找到临近的k个样本,可采用普通的算术平均算法或考虑距离差异的加权平均等输出。
3. 实验过程
3.1 鸢尾花数据集
Iris 鸢尾花数据集内包含 3 类分别是山鸢尾 (Iris-setosa),变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica),共 150 条记录,每类各 50 个数据,每条记录都有 4 项特征:萼片长度、萼片宽度、花瓣长度、花瓣宽度,可以通过这4个特征预测鸢尾花卉属于哪一品种。

3.2代码实现
此次代码演示使用数据库中的鸢尾花数据集,通过前三个的特征值,预测第四个特征值。根据前三个特征找出新数据的K个最近邻,将这些邻居的第四个特征的平均值赋给该数据,然后再根据k个邻居的第4个特征值,去预测当前样本的第4个特征值。
#导入程序运行所需的库
from numpy import *
import numpy as np
import pandas as pd
from sklearn import datasets
import matplotlib as mpl
import matplotlib.pyplot as plt
#提取鸢尾花数据集
iris = datasets.load_iris()
data = pd.DataFrame(iris.data)
data = data.sample(len(data), random_state=20)
'''
定义KNN类,用于回归。并在类中定义初始化方法与训练与预测方法
class KNN: # KNN算法的实现
使用python实现K最近邻算法。(算法用于回归预测)
get_ipython算法用于回归预测,根据前三个前三个特征属性,
寻找最近的k个邻居,然后在根据k个邻居的第4个特征值,
去预测当前样本的第4个特征值。
'''
def __init__(self, k):
#初始化方法
self.k = k
def fit(self, X, y):
# 将X和y转换成ndarray数组形式,方便统一操作
self.X = np.asarray(X)
self.y = np.asarray(y)
def predict(self, X):
'''据参数传递的x,对样本数据进行预测
X:类数组类型。形状:[样本数量,特征数量]
待测试的样本特征
result:数组类型。
预测结果值。
'''
# 转换成数组类型
X = np.asarray(X)
# 保存预测的结果
result = []
for x in X:
# 计算距离(对于测试集中的每个样本,依次计算与训练集中所有样本X的距离)
dis = np.sqrt(np.sum((x - self.X) ** 2, axis=1))
# 返回数组排序后,每个元素在原数组中的索引
index = dis.argsort()
# 取距离最近的K个元素索引(在原数组中的索引)
index = index[:self.k]
# 返回数组中每个元素出现的次数,计算均值,加入到返回的结果列表中
result.append(np.mean(self.y[index]))
# 最大元素索引,即出现次数最多的元素
return np.asarray(result)
构建训练集与测试集,用于对模型进行训练与预测。并输出预测结果
t = data.sample(len(data),random_state=0)
train_X = t.iloc[:120,:-1]
train_y = t.iloc[:120,-1]
test_X = t.iloc[120:,:-1]
test_y = t.iloc[120:,-1]
knn = KNN(k=3)
knn.fit(train_X,train_y)
result = knn.predict(test_X)
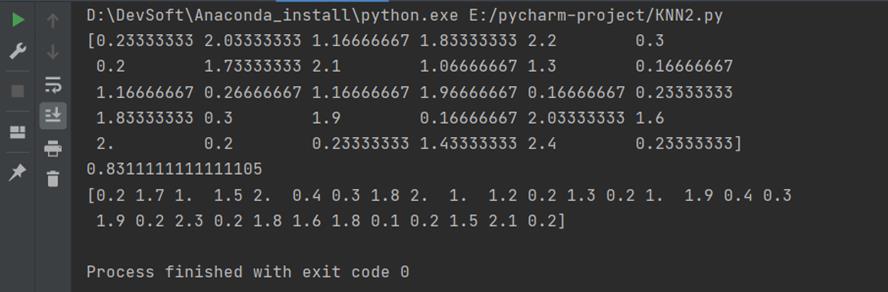
# 结果
disp(result)
print(np.sum((result-test_y)**2))
disp(test_y.values)
mpl.rcParams["font.family"] = "SimHei"
mpl.rcParams["axes.unicode_minus"] = False
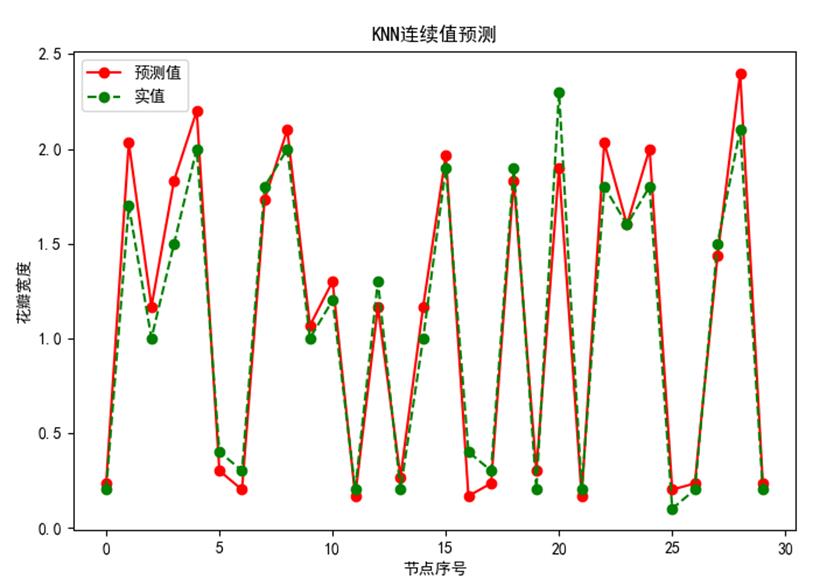
# 五、绘制预测值与真实值,并进行对比。
plt.figure(figsize=(10,8))
# 绘制预测值
plt.plot(result,"ro-",label="预测值")
# 绘制真实值
plt.plot(test_y.values,"go--",label="实值")
plt.title("KNN连续值预测")
plt.xlabel("节点序号")
plt.ylabel("花瓣宽度")
plt.legend()
plt.show()
3.3 运行结果
3.4问题分析
问题:在导入鸢尾花数据集时代码导入的是本地的数据集文件,出现数据报错,经过检查后发现在本地没有下载过相关数据集
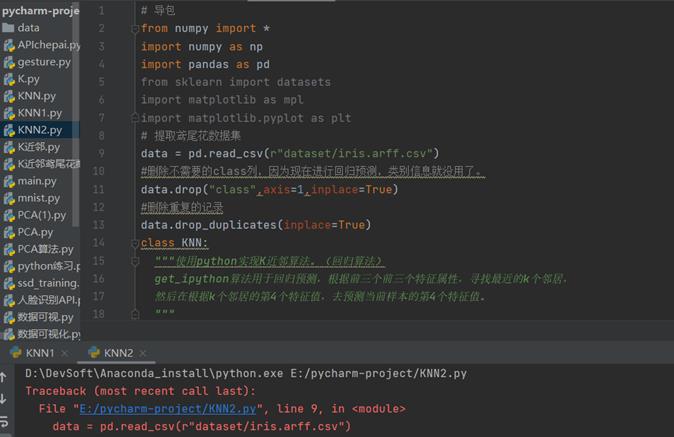
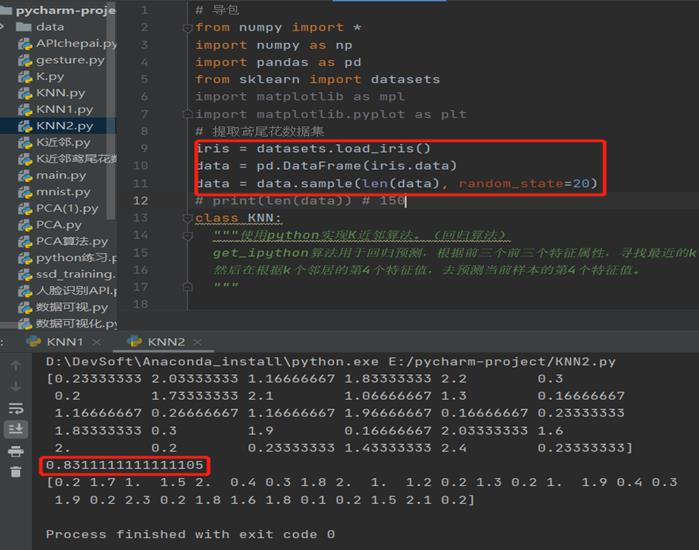
解决方法:通过检查代码,通过更改数据集导入代码,直接从数据集库导入后,能够成功运行出结果
以上是关于基于最近邻的邻鸢尾花数据集回归问题的主要内容,如果未能解决你的问题,请参考以下文章