GitHub 水项目之 快速上手 YOLOV5
Posted Huterox
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GitHub 水项目之 快速上手 YOLOV5相关的知识,希望对你有一定的参考价值。
文章目录
前言
先前咱们已经懂得了如何快速上手pytorch,并且搭建一个简单的神经网络,不过哪里依然有一些小问题,那就是我们还没有从自制数据集实现一个分类网络,所以后面有时间的话我会在总结一篇如何基于LeNet做一个简单的自定义的分类神经网络小dome。并且我们模仿 YOLO 的项目结构自己也来把这个小dome进行“规范”项目化。
不过我们当前的任务是如何去使用GitHub使用部署一个开源的深度学习项目,当然这个是基于Pytorch的。
在本篇文章当中将简单地介绍如何使用YoloV5,使用这个玩意儿做点好玩的事情,之后是如何使用训练我们自己的模型,来实现我们的一些功能。
环境准备
下载项目
打开gayhub


下载解压
然后打开你的Pytorch 。
这里非常贴心,有一个环境依赖的文件
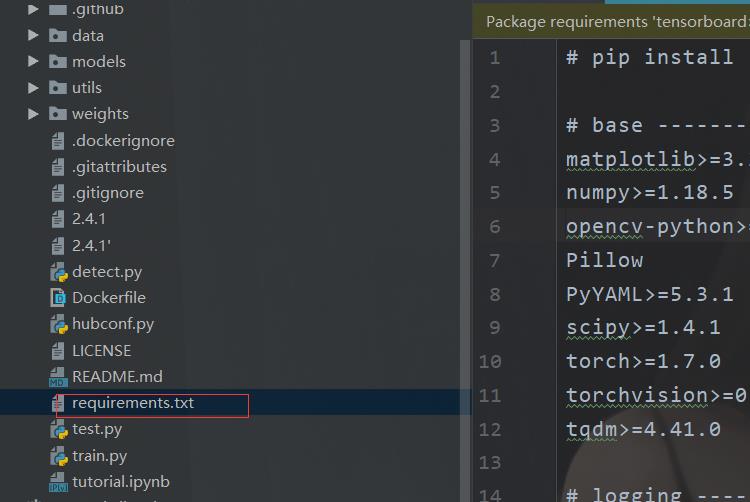
所以打开项目之后,我们只需要在控制台输入这样的指令

当然pycharm也有提示,不过如果你想让它自带给你下载安装环境的话,建议你换一个镜像,或者科学上网。
下载权重文件
如果我们不想从0开始的话,我们还需要去下载他们训练好的权重文件,这样一来我们就能快速上手。

下载之后放在这里
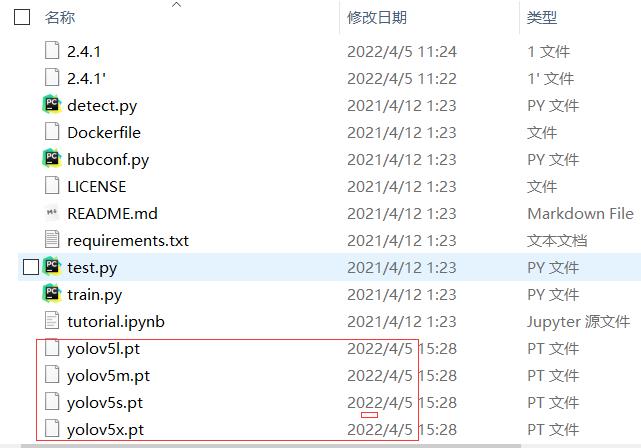
获取
为了方便读者,已经俺自己,我把项目上传到了百度云盘。需要的自取
链接:https://pan.baidu.com/s/1tXbtecPGki_QyyohrlRjig
提取码:6666
项目结构
任何一个机器学习项目,或者深度学习项目其实无非几步

之后项目再提供一个接口,用来加载使用我们的训练好的模型。
那么这个其实也不例外

第一个“Hello World”
接下来我们来看一下如何使用YOLOV5。
我们首先进入detect.py这个文件。我们首先在这里发现了几个超参数的设置
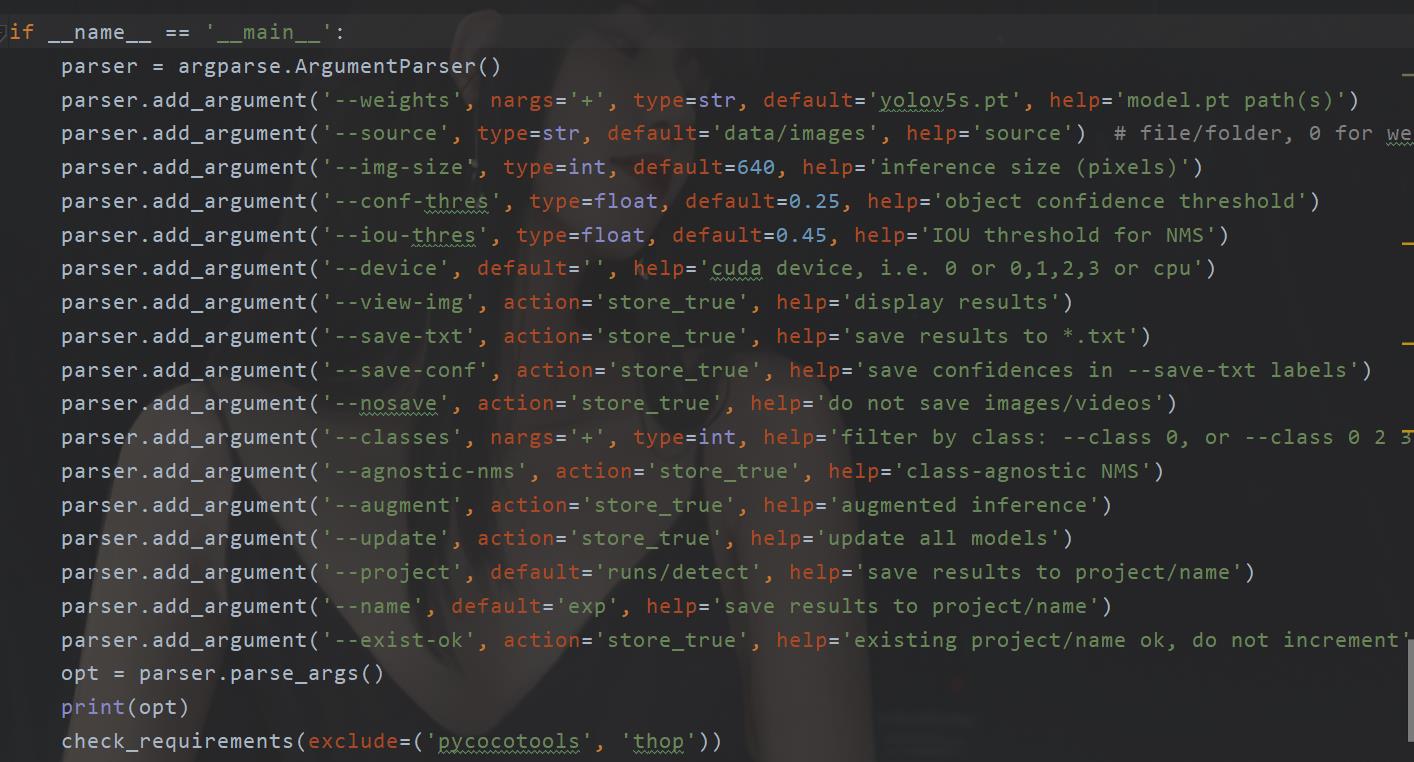
重点是两个可以看到。
一个是 weights 这个是设置咱们的权重模型,这个很明显默认实在咱们的项目根目录下。
还有一个是咱们的资源文件。打开那个文件夹我们发现了有个文件里面图片
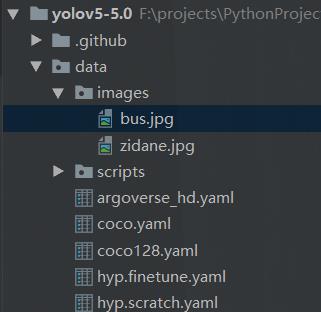
ok,接下来啥也不管,我们先直接运行一下我们的这个文件
控制台输出这个

我们在run这个文件夹下找到了咱们运行后的结果

到此我们的第一个Hello World 就完成了。
参数设定(detect)
那么接下来我们可以好好看看这个参数有哪些可以设定的。
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='yolov5s.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='data/images', help='source') # file/folder, 0 for webcam
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
opt = parser.parse_args()
print(opt)
check_requirements(exclude=('pycocotools', 'thop'))
这里的话我们可以参考这篇文章
https://cloud.tencent.com/developer/article/1874301
里面有关于参数的详细设定。
实现实时检测
我们先来看看效果

全程我啥也没干,我只是打开了我都手机摄像头,和一个IP摄像头软件。
下载软件

打开服务器
然后记录下你局域网的IP地址
例如我这里是


然后进入你的detect文件里面,你可以直接在参数里面设置,也可以python 运行单个文件的时候设置
就可以了。
然后点击运行。
不过我们实际上想要做的没有那么简单。而且说实话YOLO以我目前接触的东西来说,这玩意压根不算框架,只是一个Dome,一个实现好了的 用于目标检测的 残差神经网络dome。 所以为了方便运用和改写,我们需要去仔细阅读它的源码,方便后面改造这个框架。这个框架我简单看了一下从工程角度上来说,不复杂,比Spring简单多了,当然它的难度也不是工程难度,而是专业理论。
自己训练
接下来终于到了自己训练一个小玩意的时候了。
不过在此之前,你需要去下载一个打标签的软件。当然你也可以使用在线的,不过需要科学上网,所以我这里就没必要介绍了。
所以咱们这里使用的是LabelImg。
使用LabelImg
关于这个软件呢,使用非常简单,主要是安装使用比较麻烦。
先下载源码。这个我稍后会给出百度云盘链接。
由于我是coda环境,所以我只需要先下载源码,解压
然后进入这个文件夹
安装 pyqt
conda install pyqt=5
pyrcc5 -o resources.py resources.qrc
此时还不够,大概率会出问题。所以你需要把
这个生成的文件,移动到libs里面


最后是运行
一切正常,接下来是获取这个软件
链接:https://pan.baidu.com/s/14y-0vqU7u9JkDBaAw7Odxg
提取码:6666
标注
这里的话,我就随便搞几张图片玩玩了。
制作数据集
前面我们其实还只是完成了准备工作,接下来才是比较复杂的点,那就是制作数据集,这个LabelImg打包好之后的数据集的格式其实是VOC格式的,当然那里也可以切换为yolo的格式,不过后面都还是要再转换的。
先来看看我们一开始的数据集的样子

在让我们看看最后的文件长啥样
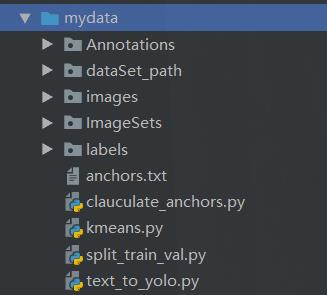
接下来我依次介绍这些脚本和处理操作。 这些代码都是copy的,目标只有一个制作一个标准的VOC数据集,然后给Yolo识别。
由于只是做演示,所以我的图片的数据集合不会太多。

关于图片的获取的话,可以自己写个爬虫是吧。这里一定要注意图片尺寸要一致(我后面翻车了)
划分训练文件
这里的话,我们主要运行这个脚本。

# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='Annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0 # 训练集和验证集所占比例。 这里没有划分测试集
train_percent = 0.9 # 训练集所占比例,可自己进行调整
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
运行完之后,会出现这样的文件

生成标签
之后是生成我们的标签。

下面的路径自己看着改
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ["猫羽雫", "喵喵~","女孩"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('F:\\projects\\PythonProject\\yolov5-5.0\\mydata\\Annotations\\%s.xml' % (image_id), encoding='UTF-8')
out_file = open('F:\\projects\\PythonProject\\yolov5-5.0\\mydata\\labels\\%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
# difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('F:\\projects\\PythonProject\\yolov5-5.0\\mydata\\labels'):
os.makedirs('F:\\projects\\PythonProject\\yolov5-5.0\\mydata\\labels')
image_ids = open('F:\\projects\\PythonProject\\yolov5-5.0\\mydata\\/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
if not os.path.exists('F:\\projects\\PythonProject\\yolov5-5.0\\mydata\\dataSet_path/'):
os.makedirs('F:\\projects\\PythonProject\\yolov5-5.0\\mydata\\dataSet_path/')
list_file = open('dataSet_path/%s.txt' % (image_set), 'w')
# 这行路径不需更改,这是相对路径
for image_id in image_ids:
list_file.write('F:\\projects\\PythonProject\\yolov5-5.0\\mydata/images/%s.jpg\\n' % (image_id))
convert_annotation(image_id)
list_file.close()
之后会出现两个文件夹
这里里面一个是我们图片的真实存放地址,还有一个是标签文本。
聚合操作
这个呢,主要是用来设置我们的目标框大小的,这里有两个脚本,这两个脚本的目的就是用来计算我们在数据集里面,手动框出来的框的平均大小,目的是为了,在我们得到的训练好后的模型,它给我们框出来的框的大小不会太奇怪,控制在一个合适的范围。
辅助脚本

import numpy as np
def iou(box, clusters):
"""
Calculates the Intersection over Union (IoU) between a box and k clusters.
:param box: tuple or array, shifted to the origin (i. e. width and height)
:param clusters: numpy array of shape (k, 2) where k is the number of clusters
:return: numpy array of shape (k, 0) where k is the number of clusters
"""
x = np.minimum(clusters[:, 0], box[0])
y = np.minimum(clusters[:, 1], box[1])
if np.count_nonzero(x == 0) > 0 or np.count_nonzero(y == 0) > 0:
raise ValueError("Box has no area") # 如果报这个错,可以把这行改成pass即可
intersection = x * y
box_area = box[0] * box[1]
cluster_area = clusters[:, 0] * clusters[:, 1]
iou_ = intersection / (box_area + cluster_area - intersection)
return iou_
def avg_iou(boxes, clusters):
"""
Calculates the average Intersection over Union (IoU) between a numpy array of boxes and k clusters.
:param boxes: numpy array of shape (r, 2), where r is the number of rows
:param clusters: numpy array of shape (k, 2) where k is the number of clusters
:return: average IoU as a single float
"""
return np.mean([np.max(iou(boxes[i], clusters)) for i in range(boxes.shape[0])])
def translate_boxes(boxes):
"""
Translates all the boxes to the origin.
:param boxes: numpy array of shape (r, 4)
:return: numpy array of shape (r, 2)
"""
new_boxes = boxes.copy()
for row in range(new_boxes.shape[0]):
new_boxes[row][2] = np.abs(new_boxes[row][2] - new_boxes[row][0])
new_boxes[row][3] = np.abs(new_boxes[row][3] - new_boxes[row][1])
return np.delete(new_boxes, [0, 1], axis=1)
def kmeans(boxes, k, dist=np.median):
"""
Calculates k-means clustering with the Intersection over Union (IoU) metric.
:param boxes: numpy array of shape (r, 2), where r is the number of rows
:param k: number of clusters
:param dist: distance function
:return: numpy array of shape (k, 2)
"""
rows = boxes.shape[0]
distances = np.empty((rows, k))
last_clusters = np.zeros((rows,))
np.random.seed()
# the Forgy method will fail if the whole array contains the same rows
clusters = boxes[np.random.choice(rows, k, replace=False)]
while True:
for row in range(rows):
distances[row] = 1 - iou(boxes[row], clusters)
nearest_clusters = np.argmin(distances, axis=1)
if (last_clusters == nearest_clusters).all():
break
for cluster in range(k):
clusters[cluster] = dist(boxes[nearest_clusters == cluster], axis=0)
last_clusters = nearest_clusters
return clusters
if __name__ == '__main__':
a = np.array([[1, 2, 3, 4], [5, 7, 6, 8]])
print(translate_boxes(a))
这个脚本不用运行,是一个工具类。
需要运行的脚本

这里也是注意路径修改
# -*- coding: utf-8 -*-
# 根据标签文件求先验框
import os
import numpy as np
import xml.etree.cElementTree as et
from kmeans import kmeans, avg_iou
FILE_ROOT = "F:\\projects\\PythonProject\\yolov5-5.0\\mydata/" # 根路径
ANNOTATION_ROOT = "Annotations" # 数据集标签文件夹路径
ANNOTATION_PATH = FILE_ROOT + ANNOTATION_ROOT
ANCHORS_TXT_PATH = "F:\\projects\\PythonProject\\yolov5-5.0\\mydata/anchors.txt" #anchors文件保存位以上是关于GitHub 水项目之 快速上手 YOLOV5的主要内容,如果未能解决你的问题,请参考以下文章