基于Centos7.8的Hive安装
Posted 一直在路上的码农
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于Centos7.8的Hive安装相关的知识,希望对你有一定的参考价值。
1.安装部署Hive的基础前提:
该部分的安装需要在Hadoop 已经成功安装的基础上,并且要求Hadoop已经正常启动。
2.Hadoop集群搭建过程
2.1.Hadoop简介
Hadoop是由Apache基金会开源的 分布式储存+分布式计算平台提供分布式的储存和计算。是一个分布式的系统基础架构:用户可以在不了解分布式底层细节的情况下进行使用。
-
分布式文件系统:HDFS实现将文件分布式储存在很多服务器上
-
分布式计算框架:MapReduce实现在很多机器上分布式并行计算
-
分布式资源调度框架:YARN实现集群资源管理以及作业的调度
2.2.部署集群方式
1)Standalone mode(独立模式)
独立模式又称为单机模式,仅1个机器运行1个java进程,主要用于调试。
2)Pseudo-Distributed mode(伪分布式模式)
伪分布模式也是在1个机器上运行HDFS的NameNode和DataNode、YARN的 ResourceManger和NodeManager,但分别启动单独的java进程,主要用于调试。
3)Cluster mode(群集模式)-单节点模式-高可用HA模式
集群模式主要用于生产环境部署。会使用N台主机组成一个Hadoop集群。这种部署模式下,主节点和从节点会分开部署在不同的机器上。
2.3.安装单个Hadoop节点
本次先安装一套虚拟机的Hadoop节点,然后进行虚拟机拷贝。
2.3.1.安装Java环境
要搭建Hadoop集群,Java环境是必不可少的,而且集群的每台机器必须具有。
安装过程忽略,本次java环境版本为
#这一步创建一个软连接,后续会被hadoop调用的以及jpsall脚本调用
[root@hnode1 ~]$ ln -s /opt/software/jdk1.8.0_212/bin/java /bin/java
[root@hnode1 ~]$ ln -s /opt/software/jdk1.8.0_212/bin/jps /bin/jps
[root@hnode1 ~]$ java -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
2.3.2.系统环境配置
1)关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
2)配置静态地址,并且设置IP地址映射
这一步对主机配置静态P地址,并进行映射,可以方便我们后续的配置,同时也方便对集群进行通信
[root@hnode1 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
。。。。
BOOTPROTO="static"
。。。。。
IPADDR=192.168.1.61
GATEWAY=192.168.1.1
NETMASK=255.255.255.0
DNS1=192.168.1.1
[root@hnode1 ~]$ cat /etc/hosts
192.168.1.61 hnode1
192.168.1.62 hnode2
192.168.1.63 hnode3
3)添加Hadoop用户,并赋权
- 创建用户【密码也是hadoop】
在集群的搭建过程中,其实使用Root用户也是可以的,而且更加的方便。但是一般不会这样做,而是建立单独的Hadoop用户进行操作,这样也增加了集群的安全性。操作如下
[root@hnode1 ~]$ useradd hadoop
[root@hnode1 ~]$ passwd hadoop
......
- 配置hadoop用户具有root权限,方便后期加sudo执行root权限的命令
[root@hnode1 ~]# vim /etc/sudoers
......
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
hadoop ALL=(ALL) ALL
## Allows members of the 'sys' group to run networking, software,
## service management apps and more.
# %sys ALL = NETWORKING, SOFTWARE, SERVICES, STORAGE, DELEGATING, PROCESSES, LOCATE, DRIVERS
## Allows people in group wheel to run all commands
%wheel ALL=(ALL) ALL
hadoop ALL=(ALL) NOPASSWD:ALL
......
注意:hadoop这一行不要直接放到root行下面,因为所有用户都属于wheel组,你先配置了hadoop具有免密功能,但是程序执行到%wheel行时,该功能又被覆盖回需要密码。所以hadoop要放到%wheel这行下面。
- 在/opt目录下创建文件夹,并修改所属主和所属组为hadoop
[root@hnode1 ~]# mkdir /opt/software
[root@hnode1 ~]# chown hadoop:hadoop /opt/software
2.3.3.安装Hadoop
Hadoop下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz
[hadoop@hnode1 ~]$ cd /opt/software
[hadoop@hnode1 software]$ wget https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz
[hadoop@hnode1 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/software/
[hadoop@hnode1 software]$ vim /etc/profile
......
#HADOOP_HOME
export HADOOP_HOME=/opt/software/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
[hadoop@hnode1 software]$ source /etc/profile
[hadoop@hnode1 software]$ hadoop version
2.3.3.1 Hadoop目录
-
(1)bin目录:存放对Hadoop相关服务(hdfs,yarn,mapred)进行操作的脚本
-
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
-
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
-
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
-
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
2.3.3.2 本地运行模式(官方WordCount)
#创建一个wcinput文件夹,并且在wcinput文件下创建一个word.txt文件
[hadoop@hnode1 hadoop-3.1.3]$ mkdir wcinput
[hadoop@hnode1 hadoop-3.1.3]$ cd wcinput
[hadoop@hnode1 wcinput]$ vim word.txt
hadoop mapreduce
sdw go hadoop
sdw love china
#执行hadoop记性字数统计
[hadoop@hnode1 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput wcoutput
[hadoop@hnode1 hadoop-3.1.3]$ cat ./wcoutput/part-r-00000
china 1
go 1
hadoop 2
love 1
mapreduce 1
sdw 2
2.4.安装Hadoop集群
2.4.1. 集群规划
本课程搭建的是集群模式,以三台主机为例,以下是集群规划:
-
NameNode和SecondaryNameNode不要安装在同一台服务器
-
ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
| 节点名称 | hnode1 | hnode2 | hnode3 |
|---|---|---|---|
| IP地址 | 192.168.1.61 | 192.168.1.62 | 192.168.1.63 |
| HDFS | NameNode,DataNode | DataNode | SecondaryNameNode,DataNode |
| YARN | NodeManager | ResourceManager,NodeManager | NodeManager |
2.4.2. 安装和环境设置
2.4.2.1.拷贝虚拟机hnode1=>hnode2,hnode3
拷贝时候,注意需要将hnode1进行关机
2.4.2.2.分别修改hnode2,hnode3的主机名和IP
hnode2:192.168.1.62
hnode3:192.168.1.63
[root@hnode2 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
2.4.2.3.集群免密登录(三台都需要设置)
[hadoop@hnode1 hadoop-3.1.3]$ ssh-keygen -t rsa
[hadoop@hnode1 hadoop-3.1.3]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hnode1
[hadoop@hnode1 hadoop-3.1.3]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hnode2
[hadoop@hnode1 hadoop-3.1.3]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hnode3
2.4.2.4.集群分发脚本
1)功能:循环复制文件到所有节点的相同目录下
2)参考命令:rsync命令原始拷贝:
rsync -av /opt/software hadoop@hnode2:/opt/
3)脚本入参:要同步的文件名称
4)脚本执行范围:期望脚本在任何路径都能使用(脚本放在声明了全局环境变量的路径)
# 在/home/hadoop/bin目录下创建xsync文件
[hadoop@hnode1 ~]$ mkdir bin
[hadoop@hnode1 ~]$ vim ./bin/xsync
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ] ; then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hnode1 hnode2 hnode3
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ] ; then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
# 修改脚本 xsync 具有执行权限
[hadoop@hnode1 ~]$ chmod +x ./bin/xsync
# 测试脚本
[hadoop@hnode1 ~]$ xsync /home/hadoop/bin
# 将脚本复制到/bin中,以便全局调用
[hadoop@hnode1 bin]$ sudo cp xsync /bin/
2.5 配置Hadoop集群
2.5.1.配置文件说明
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
1)默认配置文件:
要获取的默认文件 文件存放在Hadoop的jar包中的位置
| 要获取的默认文件 | 文件存放在Hadoop的jar包中的位置 |
|---|---|
| core-default.xml | hadoop-common-3.1.3.jar/core-default.xml |
| hdfs-default.xml | hadoop-hdfs-3.1.3.jar/hdfs-default.xml |
| yarn-default.xml | hadoop-yarn-common-3.1.3.jar/yarn-default.xml |
| mapred-default.xml | hadoop-mapreduce-client-core-3.1.3.jar/mapred-default.xml |
2)自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。
3)环境配置文件
a)hadoop-env.sh
文件中设置的是Hadoop运行时需要的环境变量。JAVA_HOME是必须设置的,即使我们当前的系统中设置了JAVA_HOME,它也是不认识的,因为Hadoop即使是在本机上执行,它也是把当前的执行环境当成远程服务器。
[hadoop@hnode2 hadoop-3.1.3]$ vim etc/hadoop/hadoop-env.sh
......
export JAVA_HOME=/opt/software/jdk1.8.0_212
......
b)mapred-env.sh
在该文件中需要指定JAVA_HOME,将原文件的JAVA_HOME配置前边的注释去掉,然后按照以下方式修改:
[hadoop@hnode2 hadoop-3.1.3]$ vim etc/hadoop/mapred-env.sh
......
export JAVA_HOME=/opt/software/jdk1.8.0_212
......
2.5.2.配置集群
1)核心配置文件: core-site.xml
hadoop的核心配置文件,有默认的配置项core-default.xml。
core-default.xml与core-site.xml的功能是一样的,如果在core-site.xml里没有配置的属性,则会自动会获取core-default.xml里的相同属性的值。
[hadoop@hnode1 ~]$ cd $HADOOP_HOME/etc/hadoop
[hadoop@hnode1 hadoop]$ pwd
/opt/software/hadoop-3.1.3/etc/hadoop
[hadoop@hnode1 hadoop]$ vim core-site.xml
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hnode1:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/software/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为hadoop -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
</configuration>
2)HDFS配置文件: hdfs-site.xml
HDFS的核心配置文件,主要配置HDFS相关参数,有默认的配置项hdfs-default.xml。
hdfs-default.xml与hdfs-site.xml的功能是一样的,如果在hdfs-site.xml里没有配置的属性,则会自动会获取hdfs-default.xml里的相同属性的值。
[hadoop@hnode1 hadoop]$ vim hdfs-site.xml
<configuration>
<!-- 第一个 web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hnode1:9870</value>
</property>
<!-- 第二个 web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hnode3:9868</value>
</property>
</configuration>
3)YARN配置文件: yarn-site.xml
YARN的核心配置文件,在该文件中的标签中添加以下配置,
[hadoop@hnode1 hadoop]$ vim yarn-site.xml
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hnode2</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
</value>
</property>
</configuration>
4)MapReduce配置文件: mapred-site.xml
MapReduce的核心配置文件,Hadoop默认只有个模板文件mapred-site.xml.template,需要使用该文件复制出来一份mapred-site.xml文件
[hadoop@hnode1 hadoop]$ vim mapred-site.xml
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2.5.3.集群上分发配置文件
在集群上分发配置好的Hadoop配置文件
[hadoop@hnode1 hadoop]$ xsync /opt/software/hadoop-3.1.3/etc/hadoop/
==================== hnode1 ====================
sending incremental file list
sent 888 bytes received 18 bytes 1,812.00 bytes/sec
total size is 107,793 speedup is 118.98
==================== hnode2 ====================
sending incremental file list
hadoop/
hadoop/core-site.xml
hadoop/hdfs-site.xml
hadoop/mapred-site.xml
hadoop/yarn-site.xml
sent 3,526 bytes received 139 bytes 7,330.00 bytes/sec
total size is 107,793 speedup is 29.41
==================== hnode3 ====================
sending incremental file list
hadoop/
hadoop/core-site.xml
hadoop/hdfs-site.xml
hadoop/mapred-site.xml
hadoop/yarn-site.xml
sent 3,526 bytes received 139 bytes 2,443.33 bytes/sec
total size is 107,793 speedup is 29.41
2.6.群起集群
2.6.1.配置workers
[hadoop@hnode1 hadoop]$ vim /opt/software/hadoop-3.1.3/etc/hadoop/workers
hnode1
hnode2
hnode3
该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
2.6.2.同步所有节点配置文件
[hadoop@hnode1 hadoop]$ xsync /opt/software/hadoop-3.1.3/etc/
==================== hnode1 ====================
sending incremental file list
sent 917 bytes received 19 bytes 1,872.00 bytes/sec
total size is 107,814 speedup is 115.19
==================== hnode2 ====================
sending incremental file list
etc/hadoop/
etc/hadoop/workers
sent 998 bytes received 51 bytes 2,098.00 bytes/sec
total size is 107,814 speedup is 102.78
==================== hnode3 ====================
sending incremental file list
etc/hadoop/
etc/hadoop/workers
sent 998 bytes received 51 bytes 2,098.00 bytes/sec
total size is 107,814 speedup is 102.78
2.6.3.启动集群
1)格式化NameNode
如果集群是第一次启动,需要在hnode1节点格式化NameNode
注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。
这里hdfs namenode -format
[hadoop@hnode1 hadoop]$ hadoop namenode -format
WARNING: Use of this script to execute namenode is deprecated.
WARNING: Attempting to execute replacement "hdfs namenode" instead.
WARNING: /opt/software/hadoop-3.1.3/logs does not exist. Creating.
2023-03-25 12:25:52,718 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = hnode1/192.168.1.61
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 3.1.3
。。。。
2)启动HDFS
[hadoop@hnode1 hadoop]$ sbin/start-dfs.sh
错误1:JAVA_HOME is not set and could not be found
可能是因为JAVA_HOME环境没配置正确,还有一种情况是即使各结点都正确地配置了JAVA_HOME,但在集群环境下还是报该错误,解决方法是显示地重新声明一遍JAVA_HOME
解决方法:
在hadoop-env.sh中,再显示地重新声明一遍JAVA_HOME
[hadoop@hnode1 hadoop]$ vim hadoop-env.sh
。。。。。。
export JAVA_HOME=/opt/software/jdk1.8.0_212
。。。。。。
错误2:hnode1: ERROR: Cannot set priority of datanode process 6081
[hadoop@hnode1 hadoop-3.1.3]$ sbin/start-dfs.sh
Starting namenodes on [hnode1]
Starting datanodes
hnode1: ERROR: Cannot set priority of datanode process 6081
Starting secondary namenodes [hnode3]
解决方法:
###先确保启动
[hadoop@hnode1 hadoop-3.1.3]$ sbin/stop-dfs.sh
Stopping namenodes on [hnode1]
Stopping datanodes
Stopping secondary namenodes [hnode3]
###删除数据目录
[hadoop@hnode1 hadoop-3.1.3]$ rm -rf data/
###删除日志目录
[hadoop@hnode1 hadoop-3.1.3]$ rm -rf logs/
###再次格式化NameNode
[hadoop@hnode1 hadoop-3.1.3]$ hdfs namenode -format
2023-03-25 12:52:22,156 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = hnode1/192.168.1.61
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 3.1.3
###再次启动
[hadoop@hnode1 hadoop-3.1.3]$ sbin/start-dfs.sh
Starting namenodes on [hnode1]
Starting datanodes
Starting secondary namenodes [hnode3]
3)启动YARN(在配置了ResourceManager的节点hnode2)
[hadoop@hnode2 hadoop-3.1.3]$ sbin/start-yarn.sh
Starting resourcemanager
Starting nodemanagers
4)Web端查看HDFS的NameNode(hnode1)
a)浏览器中输入:http://192.168.1.61:9870
b)查看HDFS上存储的数据信息
5)Web端查看YARN的ResourceManager(hnode2)
a)浏览器中输入:http://192.168.1.62:8088/cluster
b)查看YARN上运行的Job信息
2.6.4.集群测试
1)上传文件到集群
- 上传小文件
[hadoop@hnode1 subdir0]$ hadoop fs -mkdir /input
[hadoop@hnode1 subdir0]$ hadoop fs -put $HADOOP_HOME/wcinput/word.txt /input
- 上传大文件
[hadoop@hnode1 subdir0]$ hadoop fs -put /opt/software/jdk-8u212-linux-x64.tar.gz /
2)上传文件后查看文件存放在什么位置
- 查看HDFS文件存储路径
[hadoop@hnode1 subdir0]$ pwd
/opt/software/hadoop-3.1.3/data/dfs/data/current/BP-116411289-192.168.1.61-1679719942549/current/finalized/subdir0/subdir0
- 查看HDFS在磁盘存储文件内容
###这个文件是从刚才上传的word.txt
[hadoop@hnode1 subdir0]$ cat blk_1073741825
hadoop mapreduce
sdw go hadoop
sdw love china
[hadoop@hnode1 subdir0]$ pwd
/opt/software/hadoop-3.1.3/data/dfs/data/current/BP-116411289-192.168.1.61-1679719942549/current/finalized/subdir0/subdir0
3)拼接(就是刚才上传的jdk-8u212-linux-x64.tar.gz)
[hadoop@hnode1 subdir0]$ ll
total 191944
-rw-rw-r--. 1 hadoop hadoop 46 Mar 25 13:55 blk_1073741825
-rw-rw-r--. 1 hadoop hadoop 11 Mar 25 13:55 blk_1073741825_1001.meta
-rw-rw-r--. 1 hadoop hadoop 134217728 Mar 25 13:56 blk_1073741826
-rw-rw-r--. 1 hadoop hadoop 1048583 Mar 25 13:56 blk_1073741826_1002.meta
-rw-rw-r--. 1 hadoop hadoop 60795424 Mar 25 13:56 blk_1073741827
-rw-rw-r--. 1 hadoop hadoop 474975 Mar 25 13:56 blk_1073741827_1003.meta
[hadoop@hnode1 subdir0]$ cat blk_1073741826>> jdk_8_212.tar.gz
[hadoop@hnode1 subdir0]$ cat blk_1073741827>> jdk_8_212.tar.gz
[hadoop@hnode1 subdir0]$ ll
total 585160
-rw-rw-r--. 1 hadoop hadoop 46 Mar 25 13:55 blk_1073741825
-rw-rw-r--. 1 hadoop hadoop 11 Mar 25 13:55 blk_1073741825_1001.meta
-rw-rw-r--. 1 hadoop hadoop 134217728 Mar 25 13:56 blk_1073741826
-rw-rw-r--. 1 hadoop hadoop 1048583 Mar 25 13:56 blk_1073741826_1002.meta
-rw-rw-r--. 1 hadoop hadoop 60795424 Mar 25 13:56 blk_1073741827
-rw-rw-r--. 1 hadoop hadoop 474975 Mar 25 13:56 blk_1073741827_1003.meta
-rw-rw-r--. 1 hadoop hadoop 195013152 Mar 25 14:06 jdk_8_212.tar.gz
[hadoop@hnode1 subdir0]$ tar -zxvf jdk_8_212.tar.gz
jdk1.8.0_212/
。。。。。
#可以正常解压
4)下载
[hadoop@hnode1 ~]$ hadoop fs -get /jdk-8u212-linux-x64.tar.gz ./
2023-03-25 14:08:49,219 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
[hadoop@hnode1 ~]$ ll
total 520600
drwxrwxr-x. 2 hadoop hadoop 19 Mar 25 11:17 bin
-rw-rw-r--. 1 hadoop hadoop 338075860 Jul 3 2020 hadoop-3.1.3.tar.gz
-rw-r--r--. 1 hadoop hadoop 195013152 Mar 25 14:08 jdk-8u212-linux-x64.tar.gz
5)执行wordcount程序
[hadoop@hnode1 hadoop-3.1.3]$ hadoop jar /opt/software/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
。。。。。。。
[hadoop@hnode1 hadoop-3.1.3]$ hadoop fs -ls /output
Found 2 items
-rw-r--r-- 3 hadoop supergroup 0 2023-03-25 15:11 /output/_SUCCESS
-rw-r--r-- 3 hadoop supergroup 47 2023-03-25 15:11 /output/part-r-00000
[hadoop@hnode1 hadoop-3.1.3]$ hadoop fs -cat /output/part-r-00000
2023-03-25 15:17:10,862 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
china 1
go 1
hadoop 2
love 1
mapreduce 1
sdw 2
错误1:Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.
说明:计算wordcount出错,错误提示补充mapred-site.xml配置
先执行hadoop classpath命令得到classpath:
[hadoop@hnode2 hadoop-3.1.3]$ hadoop classpath
/opt/software/hadoop-3.1.3/etc/hadoop:/opt/software/hadoop-3.1.3/share/hadoop/common/lib/*:/opt/software/hadoop-3.1.3/share/hadoop/common/*:/opt/software/hadoop-3.1.3/share/hadoop/hdfs:/opt/software/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/software/hadoop-3.1.3/share/hadoop/hdfs/*:/opt/software/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/opt/software/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/software/hadoop-3.1.3/share/hadoop/yarn:/opt/software/hadoop-3.1.3/share/hadoop/yarn/lib/*:/opt/software/hadoop-3.1.3/share/hadoop/yarn/*
再修改mapred-site.xml配置,增加如下:
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/software/hadoop-3.1.3/etc/hadoop:/opt/software/hadoop-3.1.3/share/hadoop/common/lib/*:/opt/software/hadoop-3.1.3/share/hadoop/common/*:/opt/software/hadoop-3.1.3/share/hadoop/hdfs:/opt/software/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/software/hadoop-3.1.3/share/hadoop/hdfs/*:/opt/software/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/opt/software/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/software/hadoop-3.1.3/share/hadoop/yarn:/opt/software/hadoop-3.1.3/share/hadoop/yarn/lib/*:/opt/software/hadoop-3.1.3/share/hadoop/yarn/*</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=//opt/software/hadoop-3.1.3/etc/hadoop:/opt/software/hadoop-3.1.3/share/hadoop/common/lib/*:/opt/software/hadoop-3.1.3/share/hadoop/common/*:/opt/software/hadoop-3.1.3/share/hadoop/hdfs:/opt/software/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/software/hadoop-3.1.3/share/hadoop/hdfs/*:/opt/software/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/opt/software/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/software/hadoop-3.1.3/share/hadoop/yarn:/opt/software/hadoop-3.1.3/share/hadoop/yarn/lib/*:/opt/software/hadoop-3.1.3/share/hadoop/yarn/*</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/software/hadoop-3.1.3/etc/hadoop:/opt/software/hadoop-3.1.3/share/hadoop/common/lib/*:/opt/software/hadoop-3.1.3/share/hadoop/common/*:/opt/software/hadoop-3.1.3/share/hadoop/hdfs:/opt/software/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/software/hadoop-3.1.3/share/hadoop/hdfs/*:/opt/software/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/opt/software/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/software/hadoop-3.1.3/share/hadoop/yarn:/opt/software/hadoop-3.1.3/share/hadoop/yarn/lib/*:/opt/software/hadoop-3.1.3/share/hadoop/yarn/*</value>
</property>
2.7.配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
1)配置mapred-site.xml
[hadoop@hnode1 hadoop-3.1.3]$ vim etc/hadoop/mapred-site.xml
####追加一下配置
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hnode1:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hnode1:19888</value>
</property>
2)分发配置
[hadoop@hnode1 hadoop-3.1.3]$ xsync $HADOOP_HOME/etc/hadoop/mapred-site.xml
3)在hnode1启动历史服务器
[hadoop@hnode1 hadoop-3.1.3]$ mapred --daemon start historyserver
4)查看历史服务器是否启动
[hadoop@hnode1 hadoop-3.1.3]$ jps
5)查看JobHistory
http://192.168.1.61:19888/jobhistory
2.8.配置日志的聚集
-
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
-
hnode1、hnode2、hnode3的日志统一上传了
-
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
-
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryServer。
-
开启日志聚集功能具体步骤如下:
1)配置yarn-site.xml
[hadoop@hnode1 hadoop-3.1.3]$ vim etc/hadoop/yarn-site.xml
# 在该文件里面增加如下配置。
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hnode1:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
2)分发配置
[hadoop@hnode1 hadoop-3.1.3]$ xsync $HADOOP_HOME/etc/hadoop/yarn-site.xml
3)关闭NodeManager 、ResourceManager和historyServer
[hadoop@hnode2 hadoop-3.1.3]$ sbin/stop-yarn.sh
Stopping nodemanagers
Stopping resourcemanager
[hadoop@hnode1 hadoop-3.1.3]$ mapred --daemon stop historyserver
4)启动NodeManager 、ResourceManage和HistoryServer
[hadoop@hnode2 hadoop-3.1.3]$ sbin/stop-yarn.sh
Stopping nodemanagers
Stopping resourcemanager
[hadoop@hnode1 hadoop-3.1.3]$ mapred --daemon start historyserver
5)删除HDFS上已经存在的输出文件
[hadoop@hnode2 hadoop-3.1.3]$ hadoop fs -ls /output
Found 2 items
-rw-r--r-- 3 hadoop supergroup 0 2023-03-25 15:11 /output/_SUCCESS
-rw-r--r-- 3 hadoop supergroup 47 2023-03-25 15:11 /output/part-r-00000
[hadoop@hnode2 hadoop-3.1.3]$ hadoop fs -rm -r /output
Deleted /output
6)执行WordCount程序
[hadoop@hnode1 hadoop-3.1.3]$ hadoop jar /opt/software/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
7)查看日志
a)历史服务器地址
http://hadoop102:19888/jobhistory
b)历史任务列表
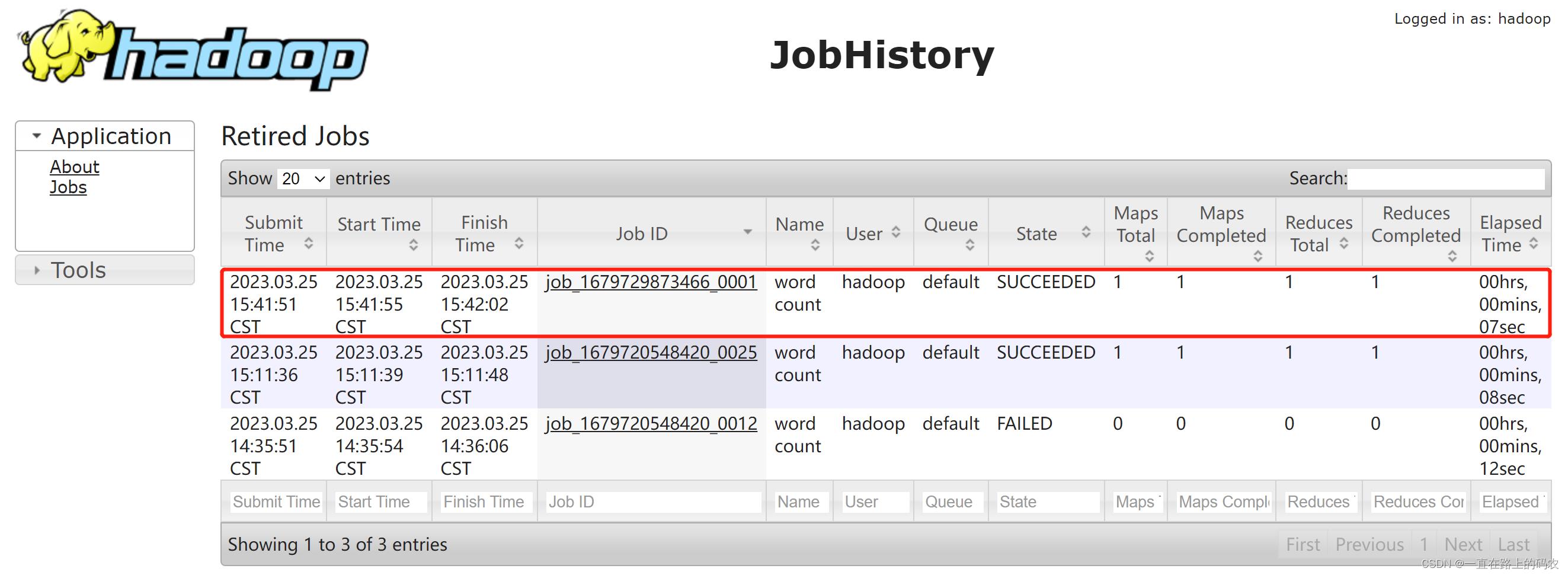
c)查看任务运行日志
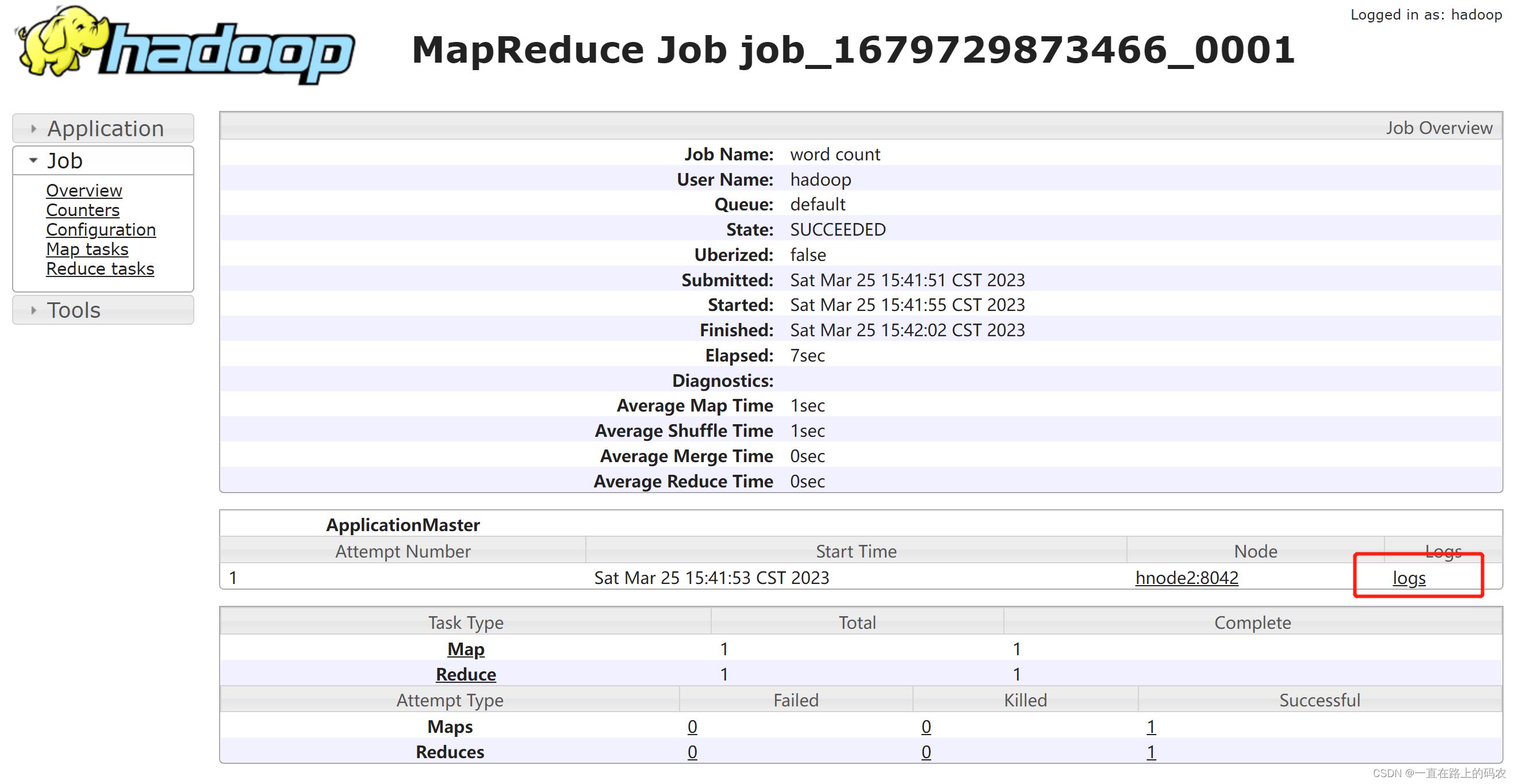
d)运行日志详情
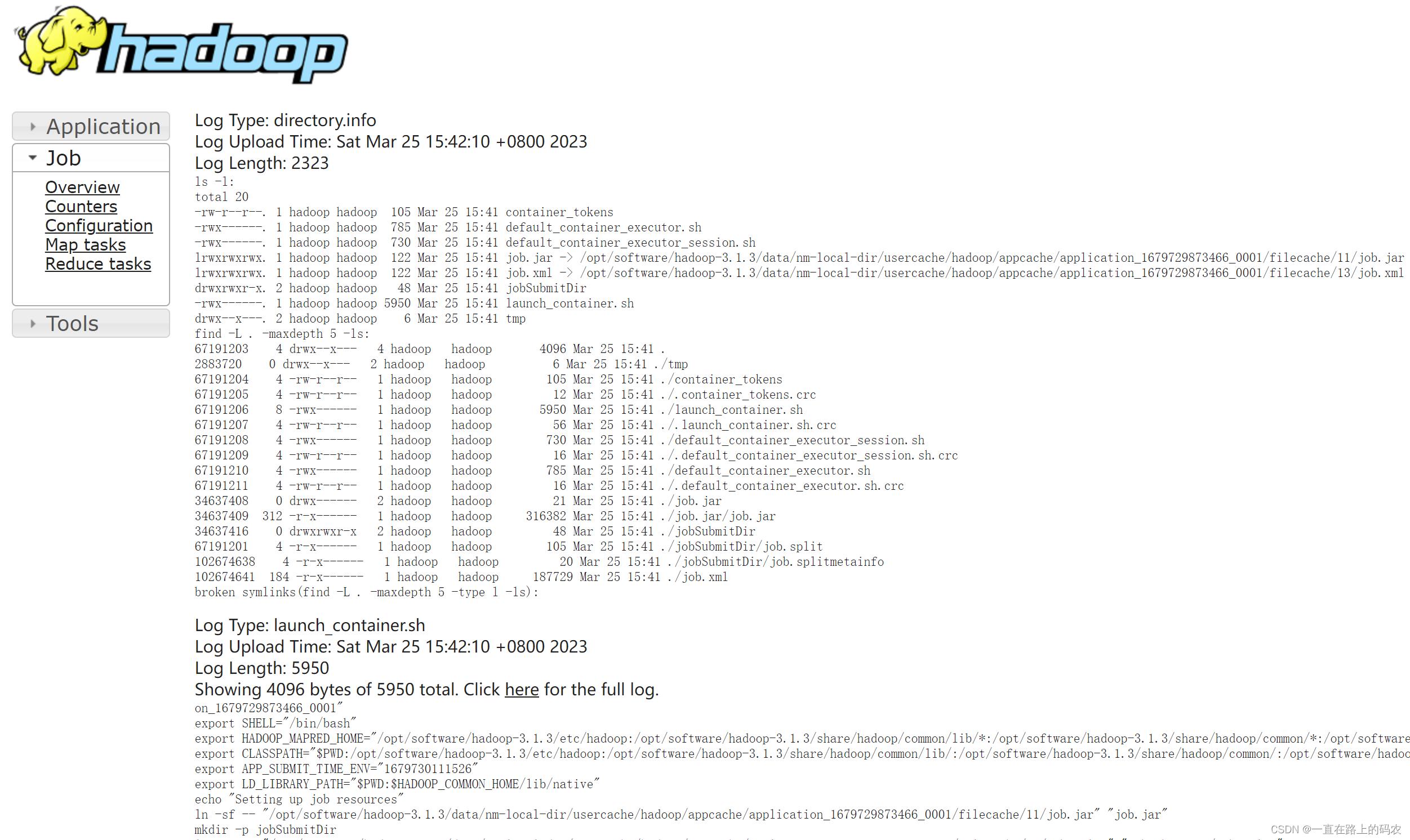
2.9.集群启动/停止方式总结
1)各个模块分开启动/停止\\常用
- 整体启动/停止HDFS
start-dfs.sh/stop-dfs.sh
- 整体启动/停止YARN
start-yarn.sh/stop-yarn.sh
2)各个服务组件逐一启动/停止
- 分别启动/停止HDFS组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode
- 启动/停止YARN
yarn --daemon start/stop resourcemanager/nodemanager
2.10. 编写Hadoop集群常用脚本
1)Hadoop集群启停脚本(包含HDFS,yarn,Historyserver):myhadoop.sh
[hadoop@hnode1 hadoop-3.1.3]$ cd ~/bin/
[hadoop@hnode1 bin]$ vim myhadoop.sh
#!/bin/bash
if [ $# -lt 1 ]; then
echo "No Args Input..."
exit
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hnode1 "/opt/software/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hnode2 "/opt/software/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hnode1 "/opt/software/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hnode1 "/opt/software/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hnode2 "/opt/software/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hnode1 "/opt/software/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
[hadoop@hnode1 bin]$ chmod +x myhadoop.sh
2)查看三台服务器Java进程脚本:jpsall.sh
[hadoop@hnode1 bin]$ vim jpsall.sh
#!/bin/bash
for host in hnode1 hnode2 hnode3
do
echo =============== $host ===============
ssh $host jps
done
[hadoop@hnode1 bin]$ chmod +x jpsall.sh
3)分发/home/hadoop/bin目录,保证自定义脚本在三台机器上都可以使用
[hadoop@hnode1 bin]$ xsync /home/hadoop/bin/
==================== hnode1 ====================
sending incremental file list
sent 143 bytes received 17 bytes 320.00 bytes/sec
total size is 1,754 speedup is 10.96
==================== hnode2 ====================
sending incremental file list
bin/
bin/jpsall.sh
bin/myhadoop.sh
sent 352 bytes received 70 bytes 281.33 bytes/sec
total size is 1,754 speedup is 4.16
==================== hnode3 ====================
sending incremental file list
bin/
bin/jpsall.sh
bin/myhadoop.sh
sent 1,383 bytes received 58 bytes 2,882.00 bytes/sec
total size is 1,754 speedup is 1.22
3.Hive部署
3.1.安装Hive
3.1.1安装mysql 5.7并配置
[root@hnode1 ~]# wget https://dev.mysql.com/get/mysql57-community-release-el7-9.noarch.rpm
.........
2023-03-25 16:58:20 (303 MB/s) - ‘mysql57-community-release-el7-9.noarch.rpm’ saved [9224/9224]
[root@hnode1 ~]# rpm -ivh mysql57-community-release-el7-9.noarch.rpm
[root@hnode1 ~]# yum install mysql-community-server --nogpgcheck
[root@hnode1 ~]# systemctl start mysqld
#####获得临时密码
[root@hnode1 ~]# grep "A temporary password" /var/log/mysqld.log | awk ' print $NF'
4%araUogghWq
##用了临时密码登进去,修改成ROOT@yy123
[root@hnode1 ~]# mysql --connect-expired-password -uroot -p
......
mysql> set PASSWORD=PASSWORD('ROOT@yy123');
Query OK, 0 rows affected, 1 warning (0.00 sec)
......
[root@hnode1 ~]# mysql -uroot -p
......
mysql> use mysql;
......
mysql> update user set authentication_string=password('ROOT@yy123') where user='root';
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'localhost' IDENTIFIED BY 'ROOT@yy123' WITH GRANT OPTION;
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'ROOT@yy123' WITH GRANT OPTION;
mysql> flush privileges;
......
3.1.2.上传Hive执行包,并解压,并配置环境变量
安装包版本:apache-hive-3.1.2-bin.tar.gz
[hadoop@hnode1 software]$ tar -zxvf apache-hive-3.1.2-bin.tar.gz
apache-hive-3.1.2-bin/LICENSE
apache-hive-3.1.2-bin/NOTICE
apache-hive-3.1.2-bin/RELEASE_NOTES.txt
。。。。。。
# 改一下文件夹名称
[hadoop@hnode1 software]$ mv apache-hive-3.1.2-bin hive3.1.2
[hadoop@hnode1 lib]$ vim /home/hadoop/.bash_profile
#####追加下面内容
export HIVE_HOME=/opt/software/hive3.1.2
export PATH=$HIVE_HOME/bin:$PATH
[hadoop@hnode1 lib]$ source ~/.bash_profile
3.1.3.在mysql中创建用户:myhive,密码:MYHIVE@yy123,并且创建数据库myhive
[root@hnode1 ~]# mysql -uroot -p
......
mysql> grant all on *.* to myhive@'%' identified by 'MYHIVE@yy123';
mysql> grant all on *.* to myhive@'localhost' identified by 'MYHIVE@yy123';
mysql> flush privileges;
......
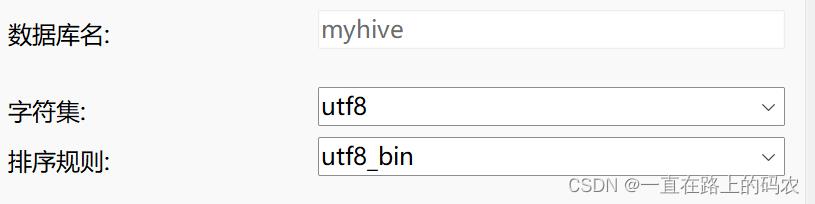
3.2.配置Hive
3.2.1 进入hive安装目录下,创建一个临时的IO文件iotmp,专门为hive来存放临时的io文件
[hadoop@hnode1 hive3.1.2]$ mkdir iotmp
[hadoop@hnode1 hive3.1.2]$ ll
total 56
drwxrwxr-x. 3 hadoop hadoop 157 Mar 25 16:49 bin
drwxrwxr-x. 2 hadoop hadoop 4096 Mar 25 16:49 binary-package-licenses
drwxrwxr-x. 2 hadoop hadoop 4096 Mar 25 18:14 conf
drwxrwxr-x. 4 hadoop hadoop 34 Mar 25 16:49 examples
drwxrwxr-x. 7 hadoop hadoop 68 Mar 25 16:49 hcatalog
drwxrwxr-x. 2 hadoop hadoop 6 Mar 25 18:17 iotmp
drwxrwxr-x. 2 hadoop hadoop 44 Mar 25 16:49 jdbc
drwxrwxr-x. 4 hadoop hadoop 12288 Mar 25 18:04 lib
-rw-r--r--. 1 hadoop hadoop 20798 Aug 23 2019 LICENSE
-rw-r--r--. 1 hadoop hadoop 230 Aug 23 2019 NOTICE
-rw-r--r--. 1 hadoop hadoop 2469 Aug 23 2019 RELEASE_NOTES.txt
drwxrwxr-x. 4 hadoop hadoop 35 Mar 25 16:49 scripts
3.2.2.进入hive安装目录下的conf目录,配置hive-env.sh文件
hive3.1.2的路径:/opt/software/hive3.1.2/conf
hadoop-3.1.3的路径:/opt/software/hadoop-3.1.3
[hadoop@hnode1 software]$ cd /opt/software/hive3.1.2/conf/
[hadoop@hnode1 conf]$ cp hive-env.sh.template hive-env.sh
[hadoop@hnode1 conf]$ vim hive-env.sh
......
# Set HADOOP_HOME to point to a specific hadoop install directory
export HADOOP_HOME=/opt/software/hadoop-3.1.3
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/opt/software/hive3.1.2/conf
......
3.2.3.进入hive安装目录下的conf目录,然后修改配置文件:
[hadoop@hnode1 conf]$ cd /opt/software/hive3.1.2/conf/
[hadoop@hnode1 conf]$ vim hive-site.xml
<configuration>
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hnode1:3306/myhive?characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>myhive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>MYHIVE@yy123</value>
</property>
<!--在hive 安装目录下,创建一个临时的IO文件iotmp,专门为hive来存放临时的io文件。-->
<property>
<name>hive.querylog.location</name>
<value>/opt/software/hive3.1.2/iotmp</value>
<description>Location of Hive run time structured log file</description>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/opt/software/hive3.1.2/iotmp</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/opt/software/hive3.1.2/iotmp</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
</configuration>
3.2.4.将mysql的java connector复制到依赖库中
连接驱动文件:mysql-connector-java.jar,自行下载
[hadoop@hnode1 conf]$ cd /opt/software/hive3.1.2/lib/
[hadoop@hnode1 lib]$ ll |grep mysql-connector-java
-rw-rw-r--. 1 hadoop hadoop 969018 Mar 25 17:50 mysql-connector-java.jar
3.2.5.初始化hive数据库【myhive】
[hadoop@hnode1 lib]$ cd /opt/software/hive3.1.2/bin/
[hadoop@hnode1 bin]$ schematool -dbType mysql -initSchema
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/software/hive3.1.2/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/software/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Metastore connection URL: jdbc:mysql://hnode1:3306/myhive?characterEncoding=UTF-8
Metastore Connection Driver : com.mysql.jdbc.Driver
Metastore connection User: myhive
Starting metastore schema initialization to 3.1.0
Initialization script hive-schema-3.1.0.mysql.sql
Initialization script completed
schemaTool completed
验证数据库初始化
[root@hnode1 conf]# mysql -uroot -p
.......
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| myhive |
| mysql |
| performance_schema |
| sys |
+--------------------+
5 rows in set (0.00 sec)
mysql> use myhive;
......
mysql> show tables;
+-------------------------------+
| Tables_in_myhive |
+-------------------------------+
| AUX_TABLE |
| BUCKETING_COLS |
| CDS |
| COLUMNS_V2 |
......
3.3.启动Hive
[hadoop@hnode1 lib]$ hive
which: no hbase in (/opt/software/hive3.1.2/bin:/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/software/jdk1.8.0_212/bin:/opt/software/hadoop-3.1.3/bin:/opt/software/hadoop-3.1.3/sbin:/home/hadoop/.local/bin:/home/hadoop/bin:/opt/software/jdk1.8.0_212/bin:/opt/software/hadoop-3.1.3/bin:/opt/software/hadoop-3.1.3/sbin:/home/hadoop/.local/bin:/home/hadoop/bin)
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/software/hive3.1.2/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/software/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1357)
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1338)
at org.apache.hadoop.mapred.JobConf.setJar(JobConf.java:518)
at org.apache.hadoop.mapred.JobConf.setJarByClass(JobConf.java:536)
at org.apache.hadoop.mapred.JobConf.<init>(JobConf.java:430)
at org.apache.hadoop.hive.conf.HiveConf.initialize(HiveConf.java:5141)
at org.apache.hadoop.hive.conf.HiveConf.<init>(HiveConf.java:5099)
at org.apache.hadoop.hive.common.LogUtils.initHiveLog4jCommon(LogUtils.java:97)
at org.apache.hadoop.hive.common.LogUtils.initHiveLog4j(LogUtils.java:81)
at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:699)
at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:683)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:318)
at org.apache.hadoop.util.RunJar.main(RunJar.java:232)
错误1:Exception in thread “main” java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
解决:hive的guava版本是19.0的,hadoop的guava版本是27.0。替换版本,需要:高版本替换低版本
[hadoop@hnode1 lib]$ ll /opt/software/hive3.1.2/lib |grep guava
-rw-r--r--. 1 hadoop hadoop 2308517 Sep 27 2018 guava-19.0.jar
-rw-r--r--. 1 hadoop hadoop 971309 May 21 2019 jersey-guava-2.25.1.jar
[hadoop@hnode1 lib]$ ll /opt/software/hadoop-3.1.3/share/hadoop/common/lib |grep guava
-rw-r--r--. 1 hadoop hadoop 2747878 Sep 12 2019 guava-27.0-jre.jar
-rw-r--r--. 1 hadoop hadoop 2199 Sep 12 2019 listenablefuture-9999.0-empty-to-avoid-conflict-with-guava.jar
########替换版本,需要:高版本替换低版本
[hadoop@hnode1 lib]$ cp /opt/software/hadoop-3.1.3/share/hadoop/common/lib/guava-27.0-jre.jar /opt/software/hive3.1.2/lib
基于CentOS6.5安装Hive-1.2.2
Hadoop环境已安装完成,链接《》
安装hive
注意1.x和2.x版本区别较大,此处安装的是1.x的版本
准备安装包
使用hadoop用户

解压文件到/opt/bigdata

修改文件
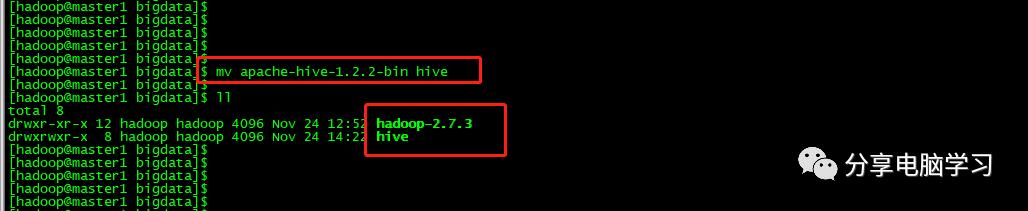
进入root用户

修改环境变量

添加hive环境变量
export HIVE_HOME=/opt/bigdata/hive
export PATH=$PATH:$HIVE_HOME/bin
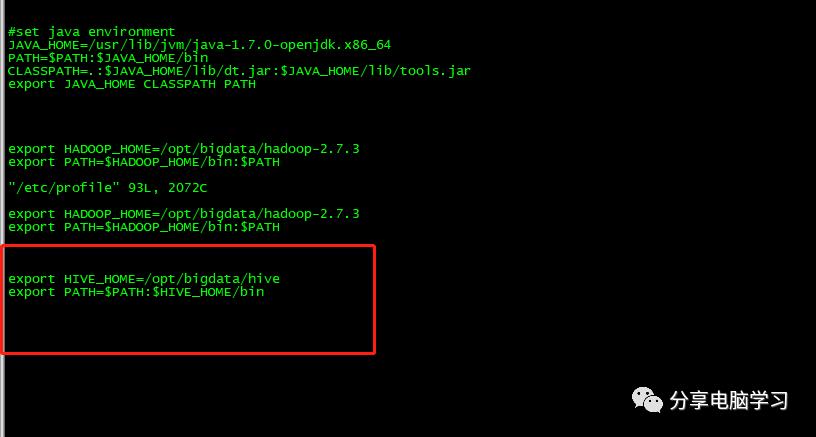
使/etc/profile里的配置立即生效

验证Hive安装

使用hadoop用户

进入/opt/bigdata/hive/conf/
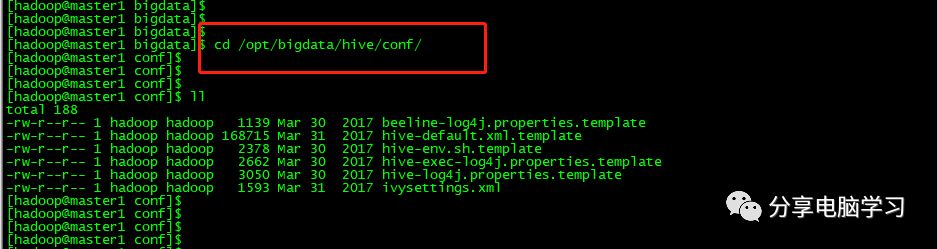
将配置文件
hive-env.sh.template、hive-log4j.properties.template和hive-default.xml.template
拷贝一份分别命名为hive-env.sh、hive-log4j.properties和hive-site.xml
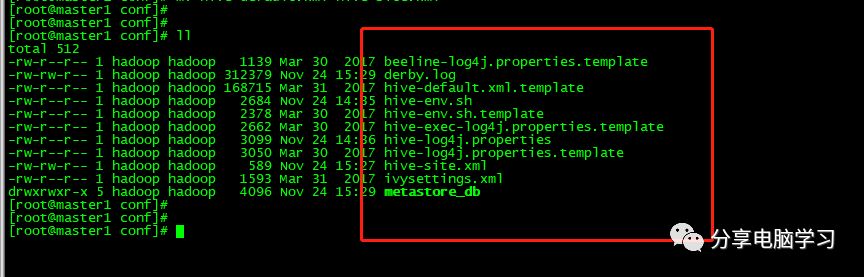
cp hive-env.sh.template hive-env.sh
cp hive-log4j.properties.template hive-log4j.properties
cp hive-default.xml.template hive-site.xml
编辑环境文件 vim hive-env.sh

添加以下内容

编辑hive-log4j.properties
该配置是用于hive日志的存放及配置,可以根据此配置找到hive的运行日志文件

添加以下内容
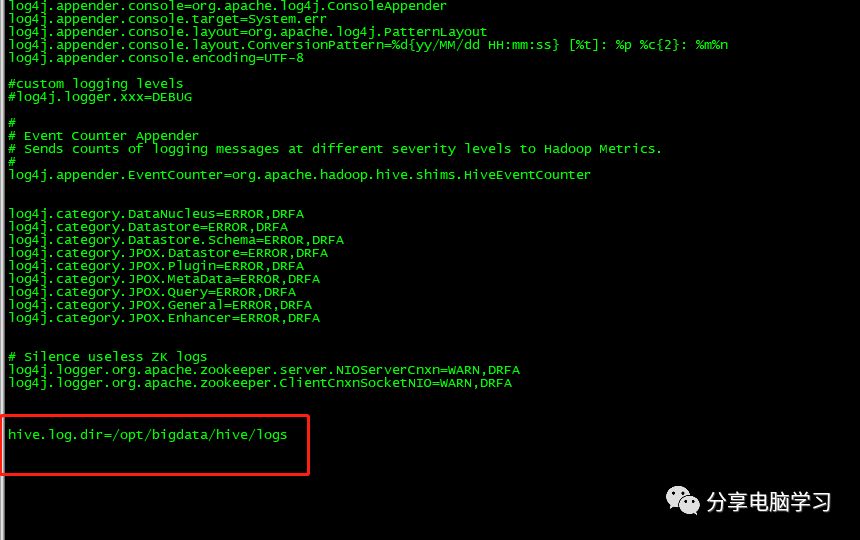
编辑文件hive-site.xml
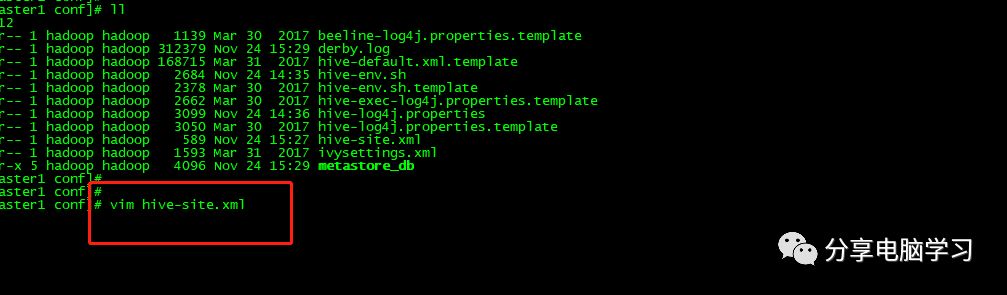
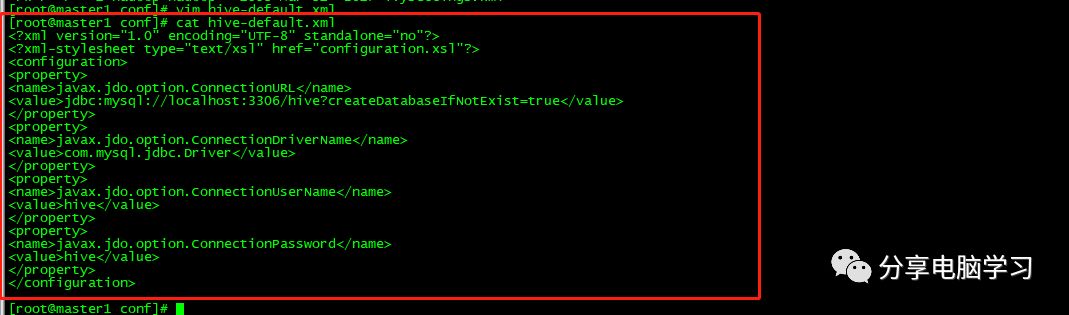
添加以下内容
文件内容
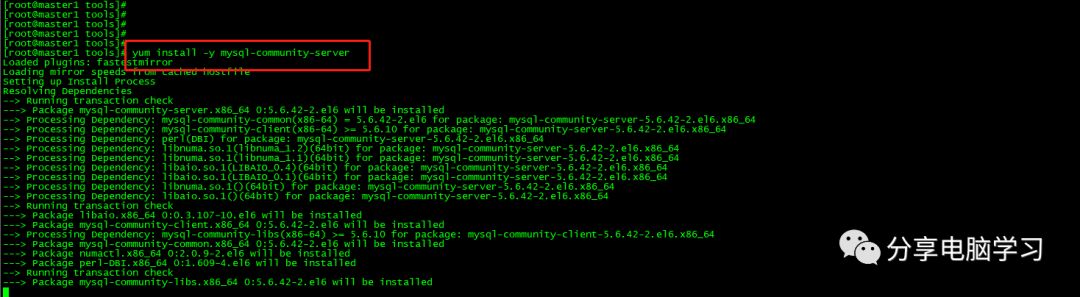
安装Mysql
看是否有Mysql

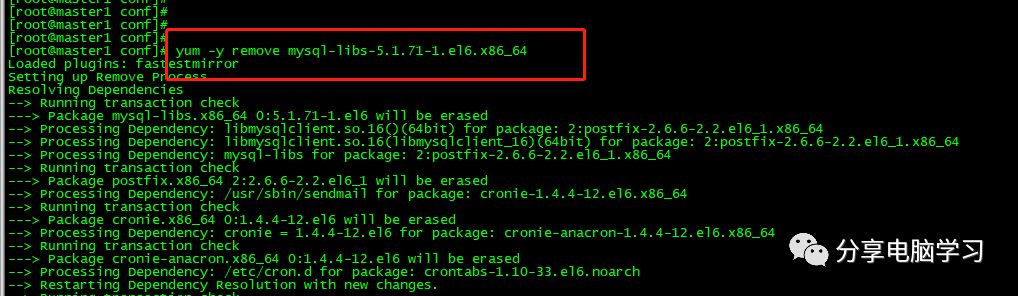
切换回root

卸载Mysql
再查看是否有安装好的(已经没有了)

下载Mysql
wget http://repo.mysql.com/mysql-community-release-el6-5.noarch.rpm

然后我们继续执行

用yum repolist mysql这个命令查看一下是否已经有mysql可安装文件
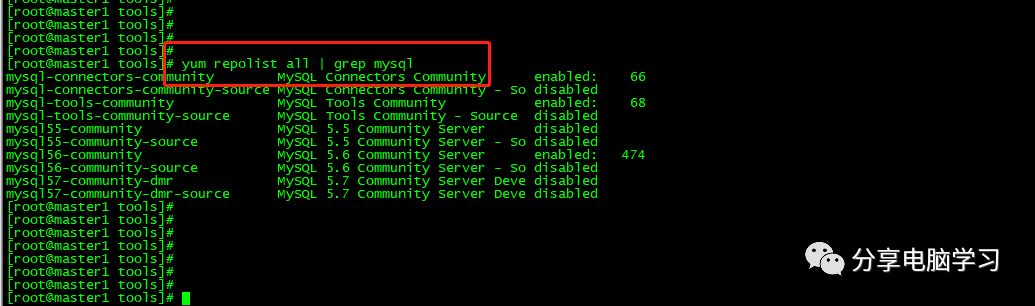
安装Mysql
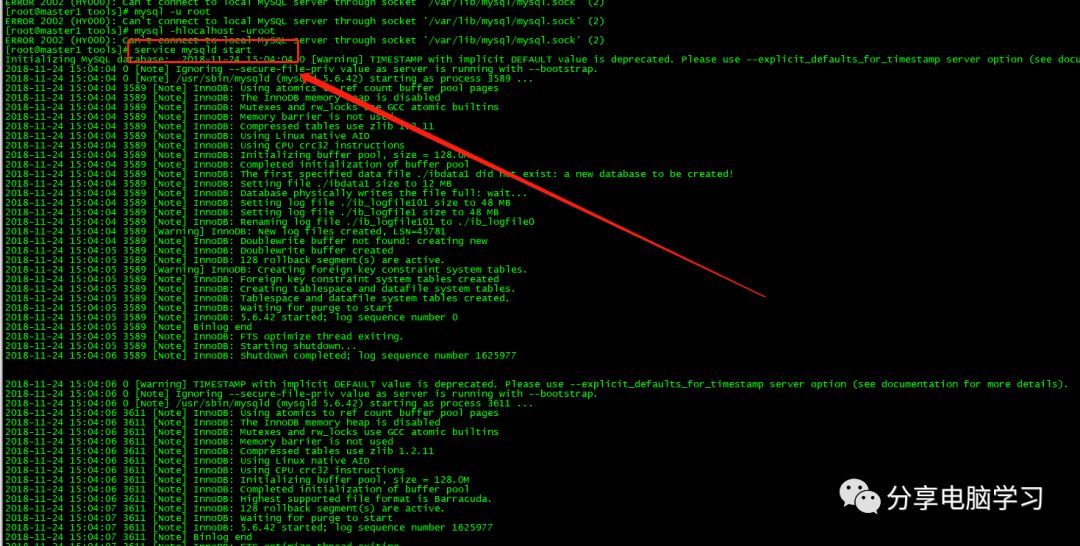
启动Mysql
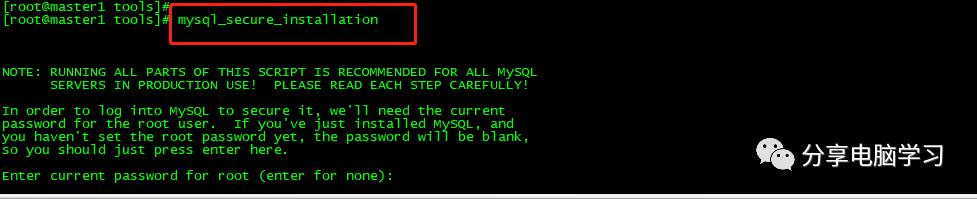
mysql安全设置(系统会一路问你几个问题,基本上一路yes)
登录数据库,使用mysql库
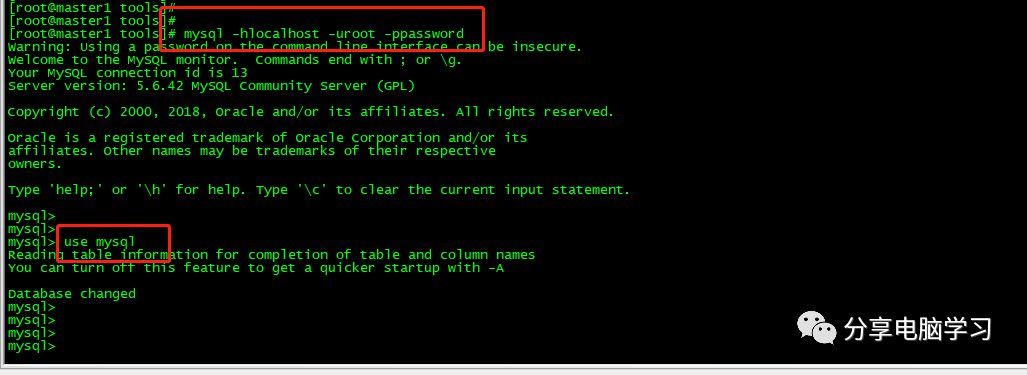
更新密码
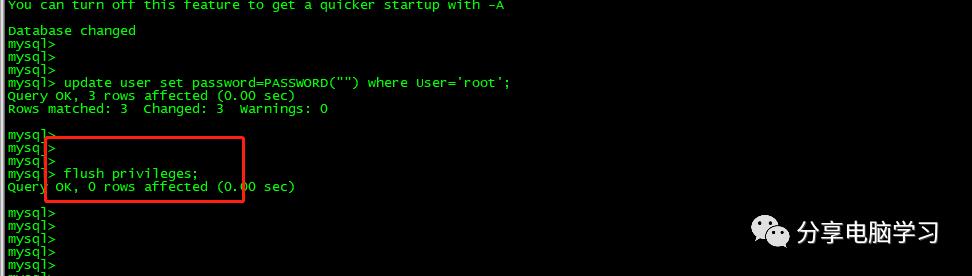
update user set password=PASSWORD("") where User='root';

刷新缓存
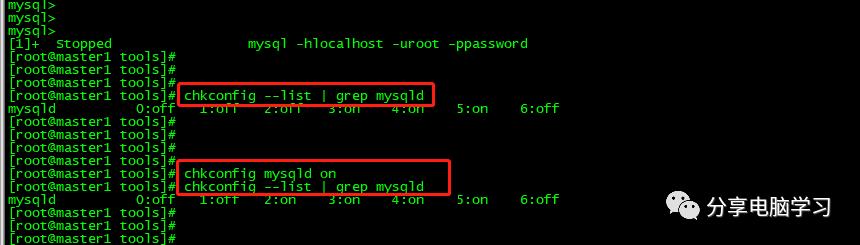
查看mysql是否自启动,并且设置开启自启动命令
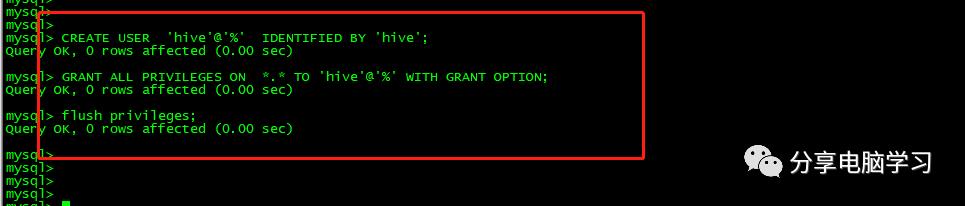
新建hive数据库,用来保存hive的元数据

将hive数据库下的所有表的所有权限赋给hive用户,并配置hive为hive-site.xml中的连接密码,然后刷新系统权限关系表
将mysql-connector-java-***.jar,复制到hive安装目录下的lib下

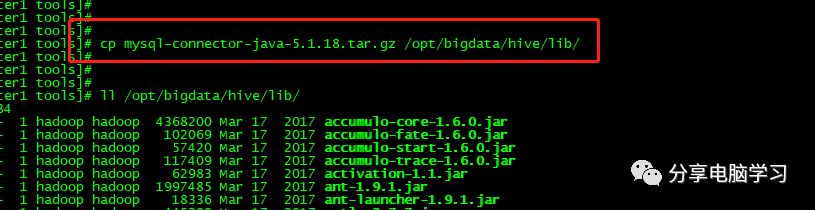
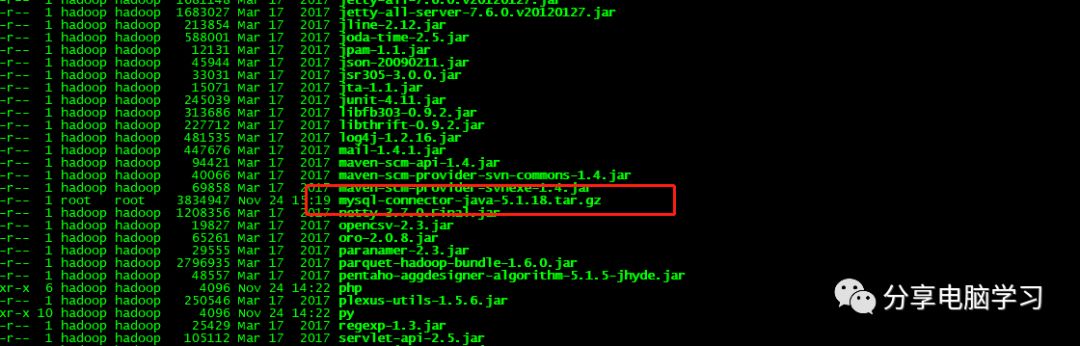
注:当使用的 hive 是 2.x 之前的版本,不做初始化也是 OK 的,当 hive 第一次启动的 时候会自动进行初始化,只不过会不会生成足够多的元数据库中的表。在使用过程中会 慢慢生成。但最后进行初始化。如果使用的 2.x 版本的 Hive,那么就必须手动初始化元 数据库
schematool -dbType mysql –initSchema
此处忽略、注意1.x和2.x版本区别较大,此处安装的是1.x的版本
启动hadoop

我们启动hive
出现错误
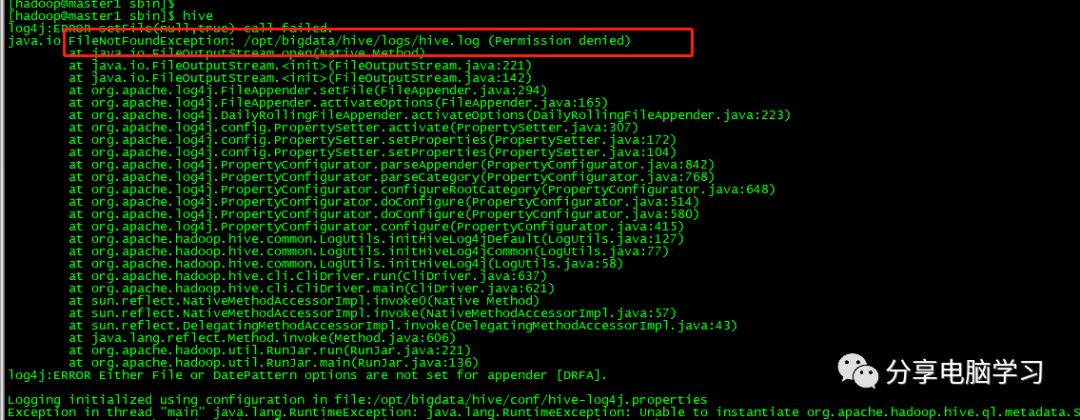
使用root用户更改权限
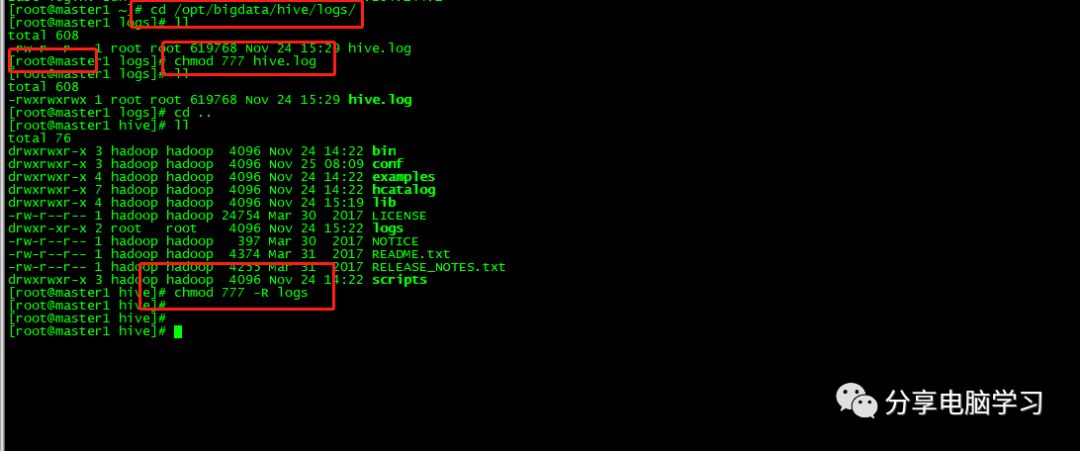
第二个错误

搜索查询得知是metastore没有启动
注:后台启动:
hive --service metastore 2>&1 >> /var/log.log &

依然有错误,显示驱动包的问题

我记得有驱动包,我们进去查看下,发现用户组的问题,并且没有解压

我们删除

然后重新拷贝

新的错误
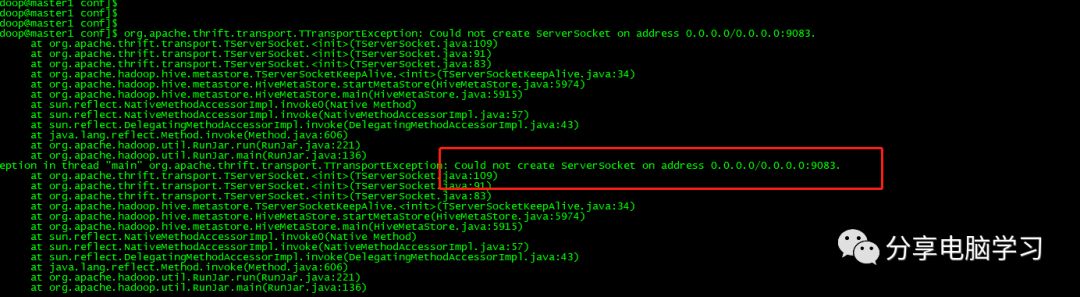
之前启动hive失败了,但是进程以及启动起来,使用jps命令查看,然后使用kill -9 进程号,杀死重启即可。
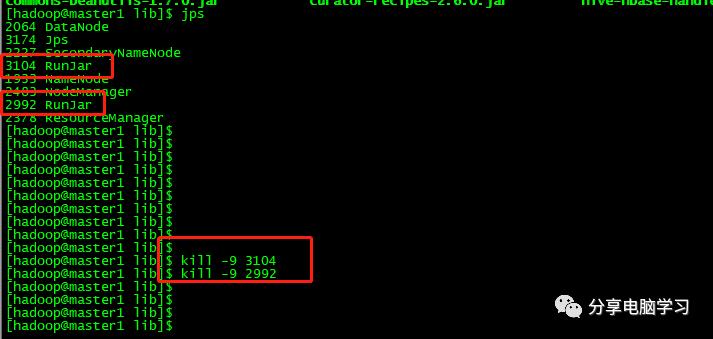
再重新启动
Hive也成功了
以上是关于基于Centos7.8的Hive安装的主要内容,如果未能解决你的问题,请参考以下文章