espnet中的transformer和LSTM语言模型对比实验
Posted 华为云开发者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了espnet中的transformer和LSTM语言模型对比实验相关的知识,希望对你有一定的参考价值。
本文分享自华为云社区《espnet中的transformer和LSTM语言模型对比---以aishell为例》,作者: 可爱又积极 。
NLP特征提取器简介 - RNN和Transformer
近年来,深度学习在各个NLP任务中都取得了SOTA结果,我们先了解一下现阶段在自然语言处理领域最常用的特征抽取结构。
长短期记忆网络(LSTM)
传统RNN的做法是将所有知识全部提取出来,不作任何处理的输入到下一个时间步进行迭代。就像参加考试一样,如果希望事先把书本上的所有知识都记住,到了考试的时候,早期的知识恐怕已经被近期的知识完全覆盖了,提取不到长远时间步的信息是很正常的。而人类是这样做的吗?显然不是的,我们通常的做法是对知识有一个理性判断,重要的知识给予更高的权重,重点记忆,不那么重要的可能没多久就忘了,这样,才能在面对考试的时候有较好的发挥。在我看来,LSTM的结构更类似于人类对于知识的记忆方式。理解LSTM的关键就在于理解两个状态ct和at和内部的三个门机制:
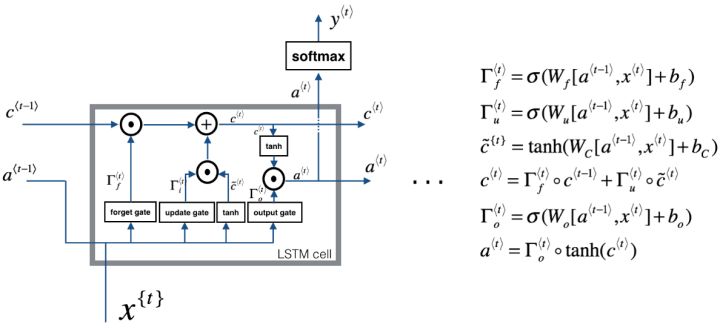
图中我们可以看见,LSTM Cell在每个时间步接收上个时间步的输入有两个,传给下一个时间步的输出也有两个。通常,我们将c(t)看作全局信息,at看作全局信息对下一个Cell影响的隐藏状态。
遗忘门、输入门(图中的update gate)和输出门分别都是一个激活函数为sigmoid的小型单层神经网络。由于sigmoid在(0,1)范围内的取值,有效的用于判断是保留还是“遗忘”信息(乘以接近1的值表示保留,乘以接近0的值表示遗忘),为我们提供了信息选择性传输的能力。
这样看下来,是不是觉得LSTM已经十分"智能"了呢?但实际上,LSTM还是有其局限性:时序性的结构一方面使其很难具备高效的并行计算能力(当前状态的计算不仅要依赖当前的输入,还要依赖上一个状态的输出),另一方面使得整个LSTM模型(包括其他的RNN模型,如GRU)总体上更类似于一个马尔可夫决策过程,较难以提取全局信息。
GRU可以看作一个LSTM的简化版本,其将at与ct两个变量整合在一起,且讲遗忘门和输入门整合为更新门,输出门变更为重制门,大体思路没有太大变化。两者之间的性能往往差别不大,但GRU相对来说参数量更少。收敛速度更快。对于较少的数据集我建议使用GRU就已经足够了,对于较大的数据集,可以试试有较多参数量的LSTM有没有令人意外的效果。
Transformer
图中红框内为Encoder框架,黄框内为Decoder框架,其均是由多个Transformer Block堆叠而成的。这里的Transformer Block就代替了我们LSTM和CNN结构作为了我们的特征提取器,也是其最关键的部分。
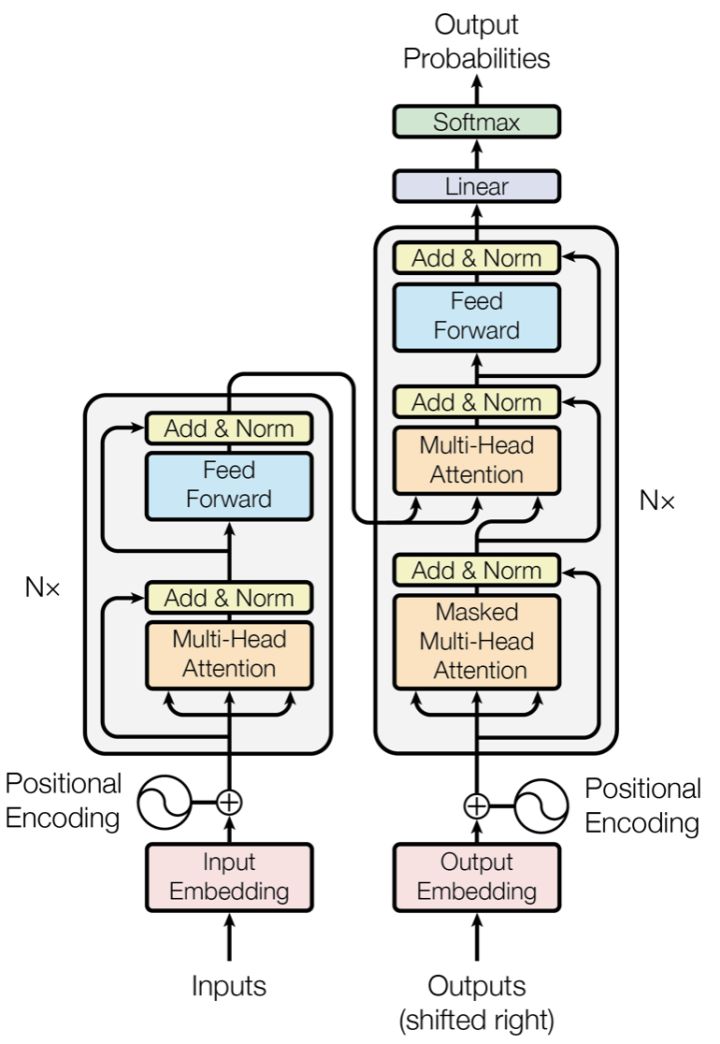
作者采用Attention机制的原因是考虑到RNN(或者LSTM,GRU等)的计算限制为是顺序的,也就是说RNN相关算法只能从左向右依次计算或者从右向左依次计算,这种机制带来了两个问题:
- 时间片t的计算依赖t-1时刻的计算结果,这样限制了模型的并行能力;
- 顺序计算的过程中信息会丢失,尽管LSTM等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象,LSTM依旧无能为力。
Transformer的提出解决了上面两个问题,首先它使用了Attention机制,将序列中的任意两个位置之间的距离是缩小为一个常量;其次它不是类似RNN的顺序结构,因此具有更好的并行性,符合现有的GPU框架。
从语义特征提取能力:Transformer显著超过RNN和CNN,RNN和CNN两者能力差不太多。
长距离特征捕获能力:CNN极为显著地弱于RNN和Transformer,Transformer微弱优于RNN模型,但在比较远的距离上(主语谓语距离大于13),RNN微弱优于Transformer,所以综合看,可以认为Transformer和RNN在这方面能力差不太多,而CNN则显著弱于前两者。这部分我们之前也提到过,CNN提取长距离特征的能力收到其卷积核感受野的限制,实验证明,增大卷积核的尺寸,增加网络深度,可以增加CNN的长距离特征捕获能力。而对于Transformer来说,其长距离特征捕获能力主要受到Multi-Head数量的影响,Multi-Head的数量越多,Transformer的长距离特征捕获能力越强。
任务综合特征抽取能力:通常,机器翻译任务是对NLP各项处理能力综合要求最高的任务之一,要想获得高质量的翻译结果,对于两种语言的词法,句法,语义,上下文处理能力,长距离特征捕获等方面的性能要求都是很高的。从综合特征抽取能力角度衡量,Transformer显著强于RNN和CNN,而RNN和CNN的表现差不太多。
并行计算能力:对于并行计算能力,上文很多地方都提到过,并行计算是RNN的严重缺陷,而Transformer和CNN差不多。
espnet中的transformer和LSTM语言模型对比实验
espnet所有的例子中语言模均默认是LSTM,这里我以aishell为例,epoch设置为20,batchsize=64。
LSTM结构配置:
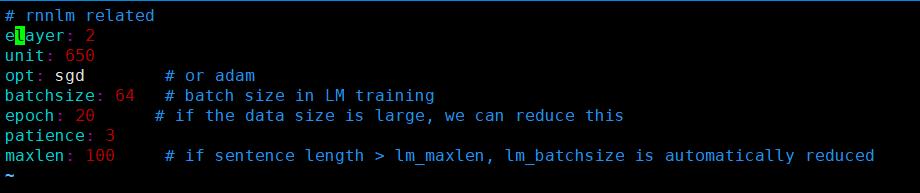
LSTM结果:
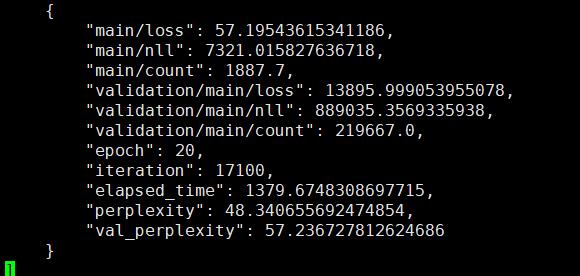
将语言模型换为transformer。transformer结构配置:

transformer结果:
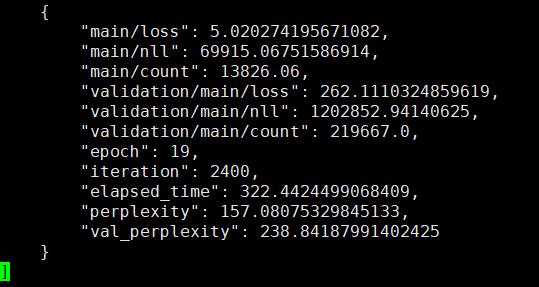
实验结论: transformer语言模型的loss确实比lstm要小,但由于语言模型序列信息是非常重要的,transformer只能获取模糊的位置信息,因此transformer的困惑度比lstm要大!后续应该就这一方面进行改进。
以上是关于espnet中的transformer和LSTM语言模型对比实验的主要内容,如果未能解决你的问题,请参考以下文章
LSTM已死,Transformer当立(LSTM is dead. Long Live Transformers! ):下