Mysql系列——详细剖析数据库“索引”上篇
Posted 博客小梦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mysql系列——详细剖析数据库“索引”上篇相关的知识,希望对你有一定的参考价值。
【mysql系列】——详细剖析数据库中的核心知识【索引】😎

😎博客昵称:博客小梦
😊最喜欢的座右铭:全神贯注的上吧!!!
😊作者简介:一名热爱C/C++,算法,数据库等技术、喜爱运动、热爱K歌、敢于追梦的小博主!
😘博主小留言:哈喽!😄各位CSDN的uu们,我是你的博客好友小梦,希望我的文章可以给您带来一定的帮助,话不多说,文章推上!欢迎大家在评论区唠嗑指正,觉得好的话别忘了一键三连哦!😘

前言🙌
哈喽各位友友们😊,我今天又学到了很多有趣的知识,现在迫不及待的想和大家分享一下!😘我仅已此文,和大家分享【【Mysql系列】——详细剖析数据库“索引”【上篇】~都是精华内容,可不要错过哟!!!😍😍😍
索引
索引概述
在数据之外,数据库系统还维护着满足查找算法的数据结构,这些数据结构以某种方式指向我们的数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。简单来说,索引是帮助Mysql高效获取数据的数据结构(有序)。
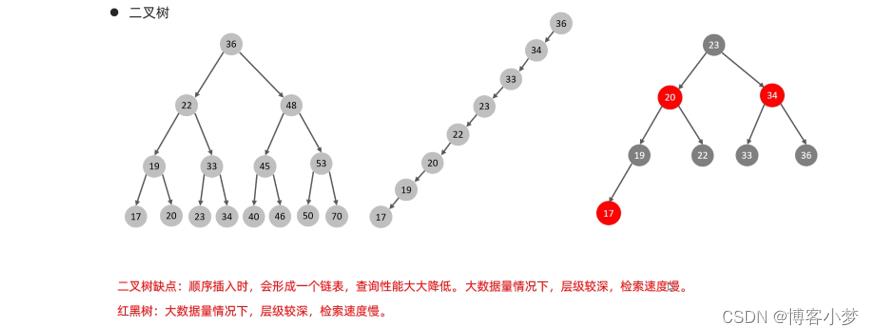
说到数据结构,大家可能一想到B+树、红黑树、二叉树等等各种各样的树就感到头疼。

其实不用那么慌张,我们只需要了解其结构和一些基本性质就行了。
为什么需要索引?
前面我们已经提到了,索引是一种数据结构,它能够帮助数据库快速查询数据,这就是它的主要作用。当没有索引的时候,我们在查询数据时,就像下面这幅图一样进行全表扫描,这样效率是非常低下的。
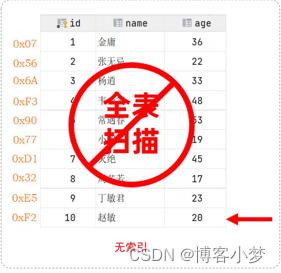
通常来说,一般提到数据库的索引时,其数据结构都是B+树数据结构。下面这幅图是一个大概展示了索引查找数据的画面,并非真正的B+树。

索引的优缺点
| 优势 | 劣势 |
|---|---|
| 提高数据检查的效率,降低数据库的IO成本 | 索引也是要占用空间的 |
| 通过索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗 | 索引大大提高了查询效率,同时却也降低更新表的速度,如对表进行的 insert、update、delete时,效率降低。 |
- 但是,现在的磁盘是很便宜的,所以索引占空间的问题就没有那么重要了。
- 其实在一个正常的业务中,进行增删改的操作远小于查询操作。所以索引的第二个不足也影响不大。
- 根据场景需求和业务需求选择是否使用索引。
索引结构
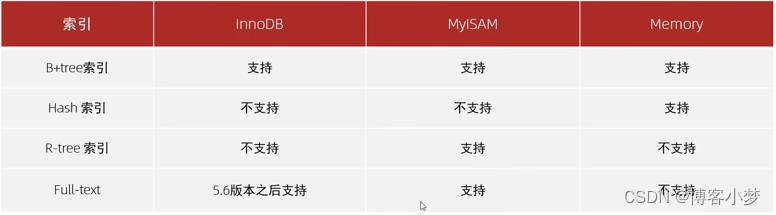
前面的博客已经提到过,索引是在存储引擎层实现的,不同的存储引擎有着不同的结构,主要包括一下几种:

默认索引都是B+树,面试的时候一般没有说明也是B+树索引结构。
索引的结构为什么不是二叉树和红黑树?
索引的B+树结构
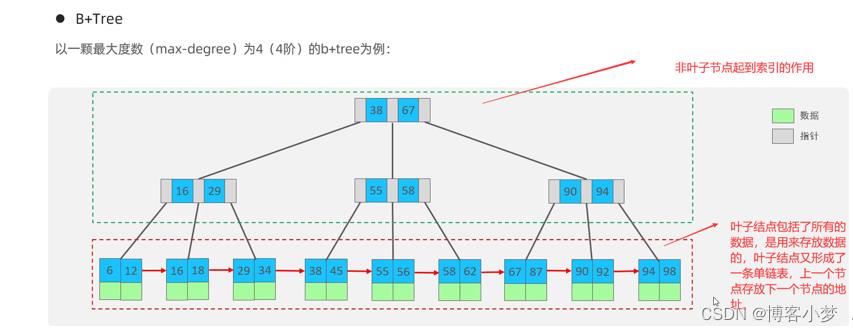
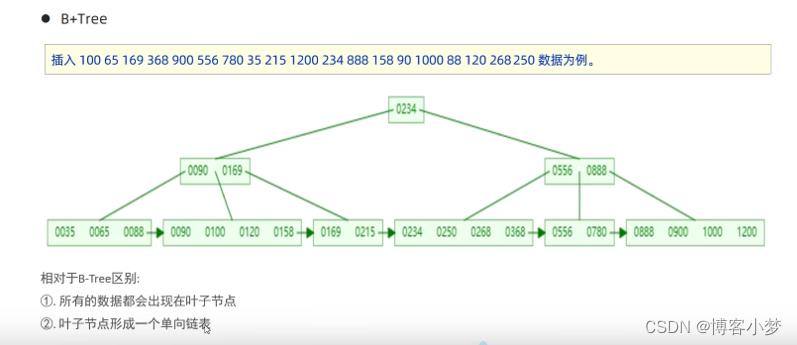
上面都是数据结构中的B+数结构,而在Mysql中,是对其进行优化的。在原B+Tree的基础上,增加了一个指向相邻叶子结点的链表指针,就形成了带有顺序指针的B+Tree,提高区间访问性能。
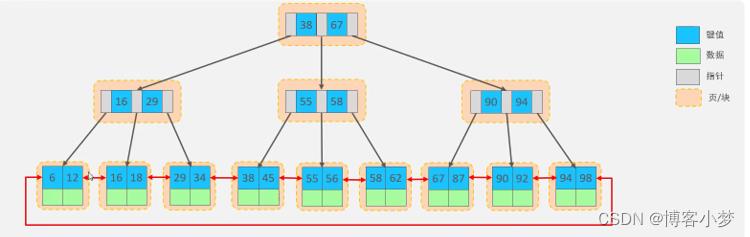
索引的Hash结构
哈希表就是采用一定的Hash算法,将键值换算成新的hash值,映射到对应的槽位上,然后存储在hash表中。如果两个或者多个键值,映射到一个相同的槽位上,他们就产生了hash冲突(也称为是hash碰撞),可以通过链表来解决这个问题。
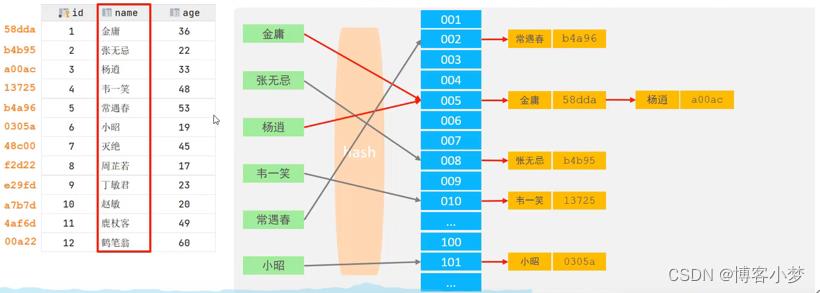
Hash结构索引的特点
- Hash索引只能用于对等比较( = , in),不支持范围查询(between,>,<,…)
- 无法利用索引完成排序操作。我们可以看到,数据在hash表中的存储是无序的。
- 查询效率高,通常只需要一次检索就可以了,效率通常要高于B+Tree索引。这里之所以说是通常而不是一定,是因为在可能会发生hash冲突。
注意:在Mysql中,支持hash索引的是Memory引擎,而INnoDB中具有自适应的hash功能,hash索引是存储引擎根据B+Tree索引在指定条件下自动构建的。
思考:为什么InnoDB存储引擎选择使用B+Tree索引结构呢?
理由有以下几点:
- 相对于二叉树,层级更少,搜索效率更高;
- 对于B-树,无论是叶子结点还是非叶子节点,都会保存数据,这样导致了一页中存储的键值减少,指针跟着减少(键值key 的个数比指针数少1),要同样保存大量的数据,只能增加树的高度,导致性能的降低;
- 相对于Hash索引,B+Tree支持范围匹配和排序操作的。而Hash索引不能。
总结撒花💞
本篇文章旨在分享【Mysql系列】——详细剖析数据库“索引”【上篇】。希望大家通过阅读此文有所收获!😘如果我写的有什么不好之处,请在文章下方给出你宝贵的意见😊。如果觉得我写的好的话请点个赞赞和关注哦~😘😘😘
Mysql系列——详细剖析数据库中的存储引擎
【Mysql系列】——详细剖析数据库中的存储引擎😎

😎博客昵称:博客小梦
😊最喜欢的座右铭:全神贯注的上吧!!!
😊作者简介:一名热爱C/C++,算法,数据库等技术、喜爱运动、热爱K歌、敢于追梦的小博主!
😘博主小留言:哈喽!😄各位CSDN的uu们,我是你的博客好友小梦,希望我的文章可以给您带来一定的帮助,话不多说,文章推上!欢迎大家在评论区唠嗑指正,觉得好的话别忘了一键三连哦!😘

前言🙌
哈喽各位友友们😊,我今天又学到了很多有趣的知识,现在迫不及待的想和大家分享一下!😘我仅已此文,和大家分享【Mysql系列】——详细剖析数据库中的存储引擎~都是精华内容,可不要错过哟!!!😍😍😍
存储引擎
什么是存储引擎?
存储引擎是数据库中非常关键的部分,它就像是飞机、火箭中的引擎那样。我们能不能把飞机上的存储引擎发到火箭上去呢? 显然是不可能的,因为引擎的使用是要看使用的场景的。而在Mysql中,存储引擎也是一样的,其没有好坏之分。我们需要在合适的场景下使用合适的存储引擎才是我们需要做到位的。存储引擎就是存储数据、建立索引、更新/查询数据等技术的实现方式。存储引擎是基于表的,而不是基于库的,所以存储引擎也可以被称为表类型。
Mysql的体系结构:
Mysql的体系结构分为四层:
MYsql的体系结构如下图所示:
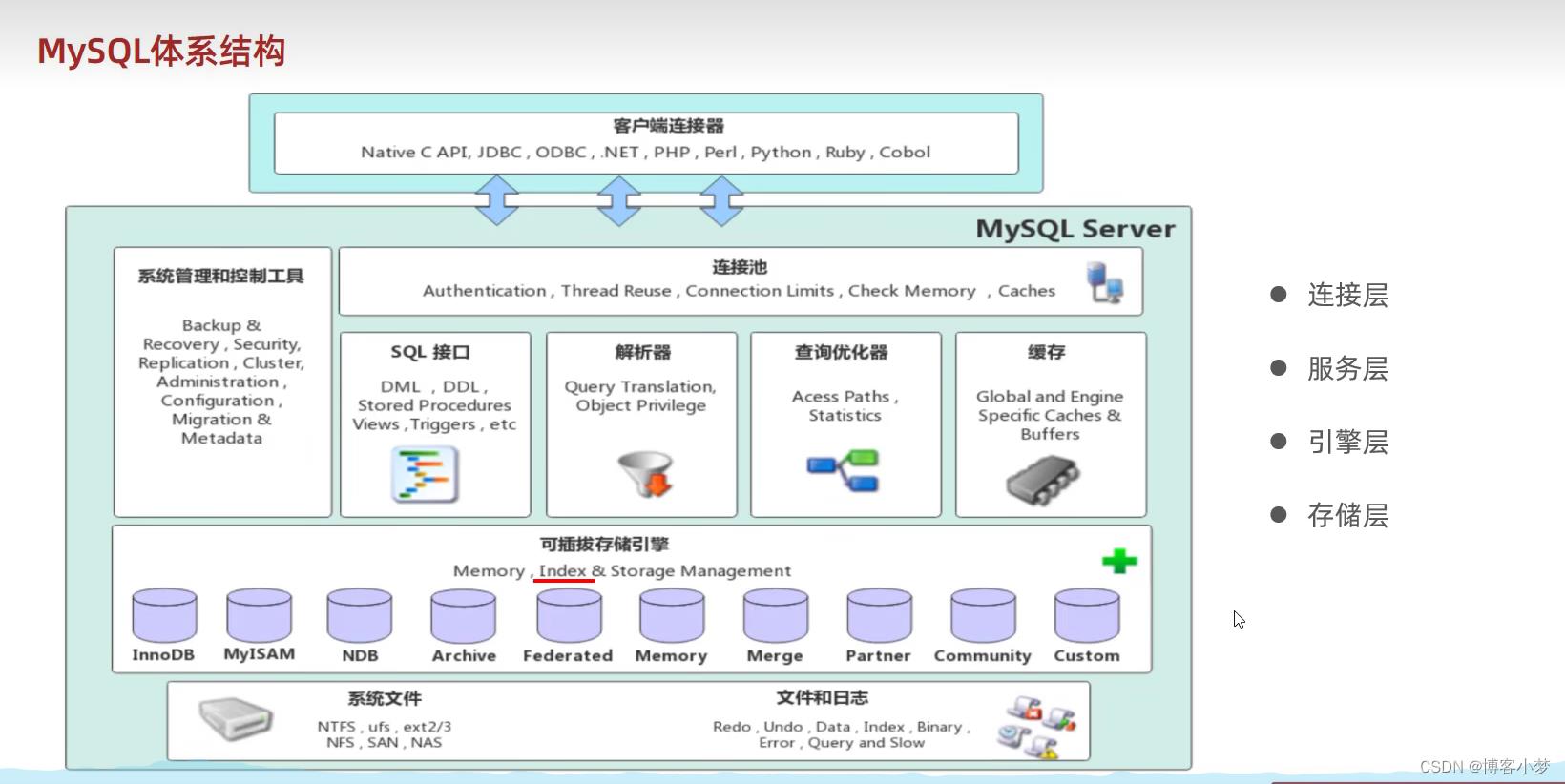
连接层
最上层是一些客户端和链接服务,主要完成一些类似于连接处理,授权认证,及相关的安全方案,服务器也会为安全接入的每个客户端验证它所具有的操作权限。
服务层
第二层架构主要完成大多数的核心服务功能,如SOL接口,并完成缓存的查询,SOL的分析和优化,部分内置函数的执行。所有跨存储引擎的功能也在这一层实现,如 过程、函数等。
引擎层
存储引警真正的负责了MvSOL中数据的存储和提取,服务器通过API和存储引警进行通信。不同的存储引擎具有不同的功能,这样我们可以根据自己的需要,来选取合适的存储引擎。
存储层
主要是将数据存储在文件系统之上:并完成与存储引擎的交互。
存储引擎的查看
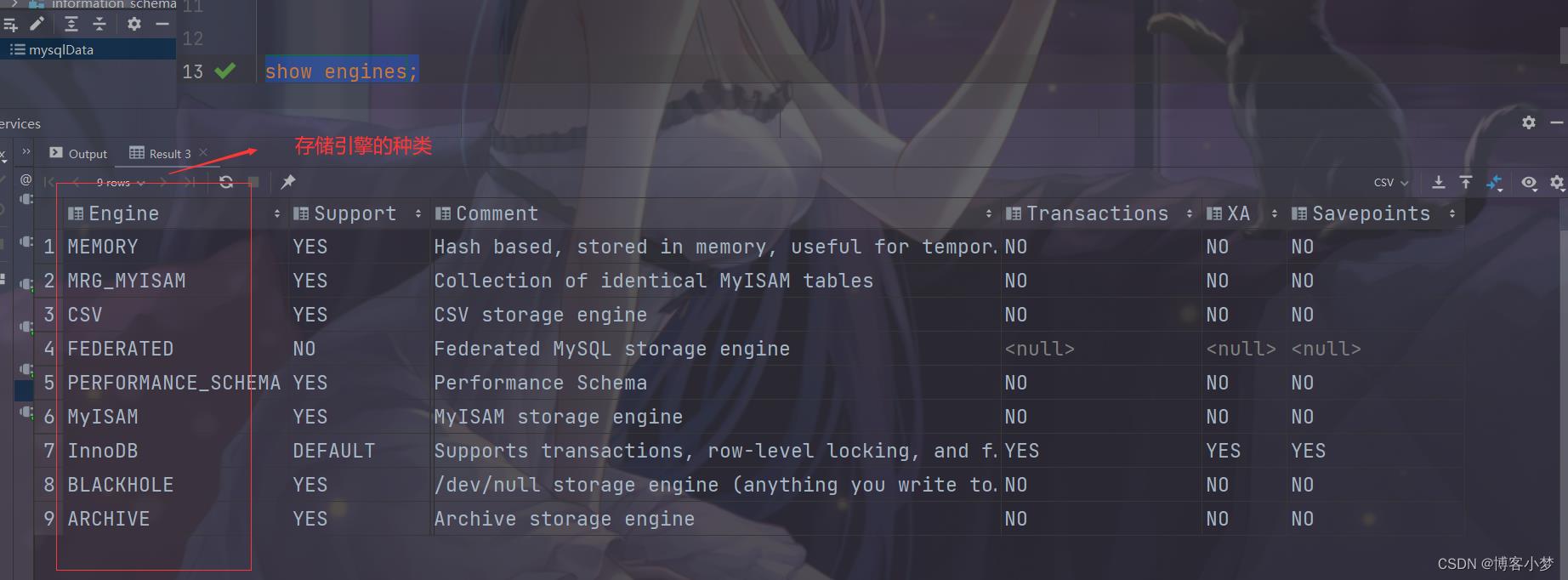
存储引擎是有很多的,在MYsql 5.5 之后,默认的存储引擎是InnoDB 存储引擎。之前默认的是Memory 存储引擎。
show engines;
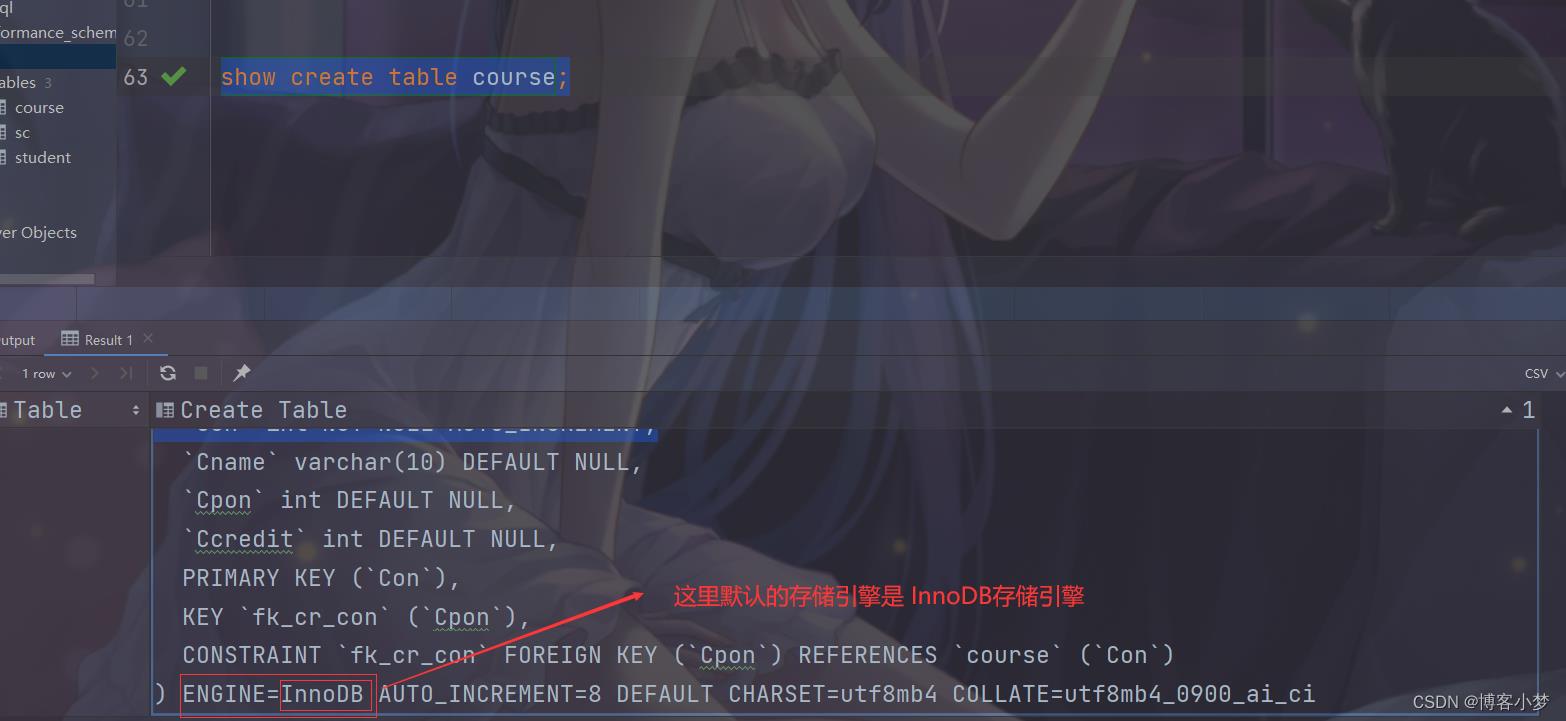
create table Course(
Con int primary key auto_increment,
Cname varchar(10),
Cpon int,
Ccredit int
)
show create table course;
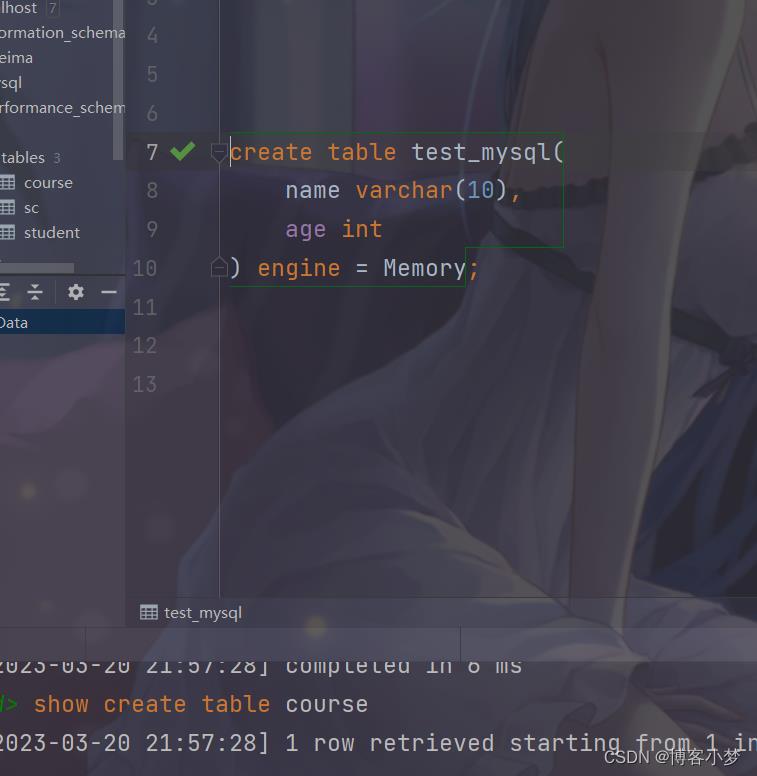
存储引擎的指定
例如,我们可以在创建表的同时,指定此表的存储引擎类型。
create table test_mysql(
name varchar(10),
age int
) engine = Memory;
存储引擎的特点
这里重点介绍以下 InnoDB
InnoDB介绍
InnoDB是一种兼顾高可靠性和高性能的通用存储引擎,在 MvSOL 5.5 之后,InnoDB是默认的 MvSOL存储引擎。
InnoDB特点
- DML操作遵循ACID模型,支持事务;
- 行级锁,提高并发访问性能;
- 支持外键FOREIGN KEY约束,保证数据的完整性和正确性:
InnoDB文件
- xxx.ibd:xxx代表的是表名,innoDB引擎的每张表都会对应这样一个表空间文件,存储该表的表结构(frm、sdi)、数据和索引。
- 参数:innodb file per table

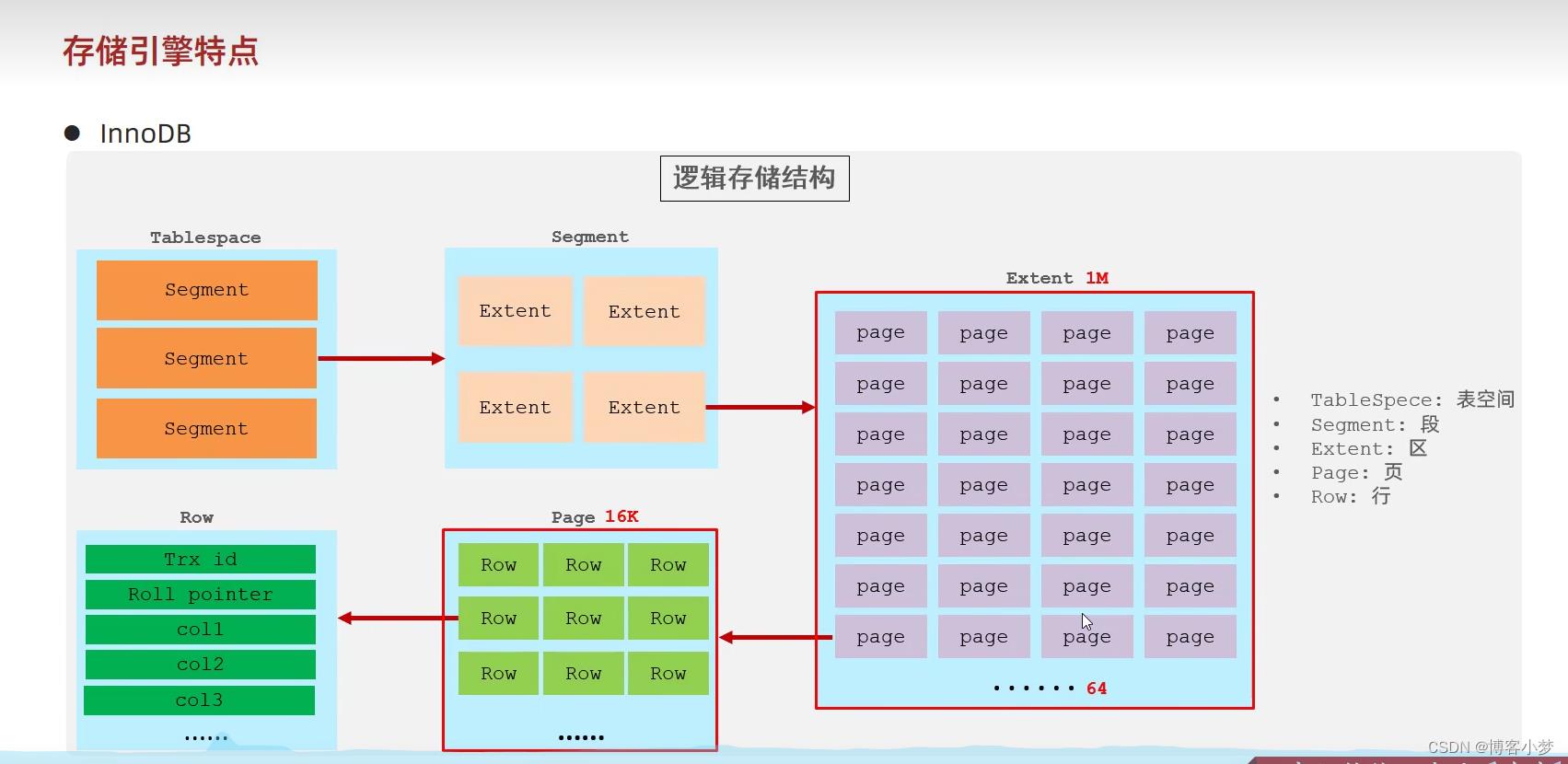
最后用一张图,来展示一下InnoDB 的逻辑存储结构。
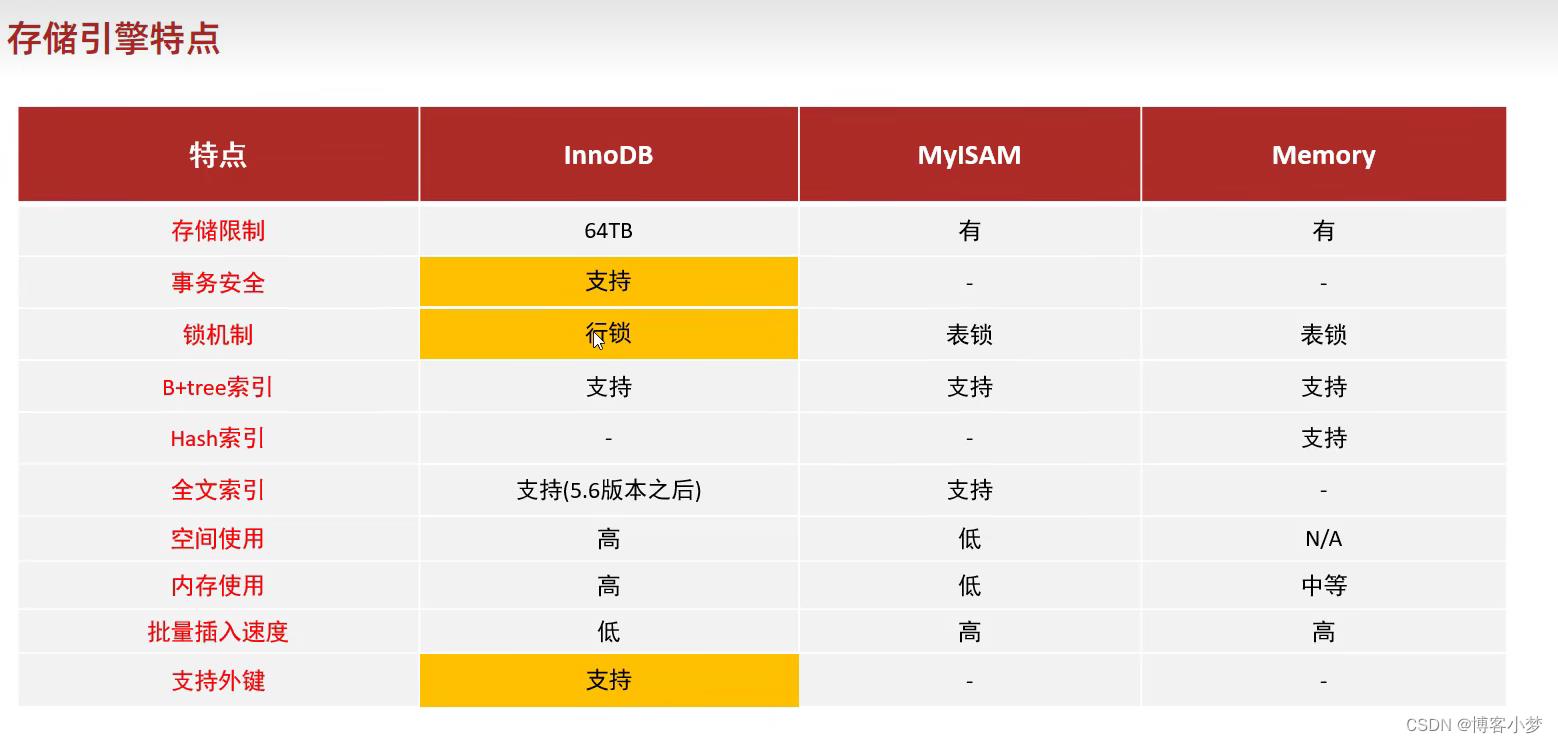
总结:InnoDB 是支持事务的,而MyISAM不支持;InnoDB 是支持行锁的,而MyISAM不支持,支持表锁;InnoDB 是支持外键的,而MyISAM不支持;
存储引擎的选择

总结撒花💞
本篇文章旨在分享【Mysql系列】——详细剖析数据库中的存储引擎。希望大家通过阅读此文有所收获!😘如果我写的有什么不好之处,请在文章下方给出你宝贵的意见😊。如果觉得我写的好的话请点个赞赞和关注哦~😘😘😘
以上是关于Mysql系列——详细剖析数据库“索引”上篇的主要内容,如果未能解决你的问题,请参考以下文章
深度挖掘RocketMQ底层源码「底层源码挖掘系列」透彻剖析贯穿RocketMQ的消费者端的运行核心的流程(上篇)
精华推荐 | 深入浅出 RocketMQ原理及实战「底层源码挖掘系列」透彻剖析贯穿RocketMQ的消费者端的运行核心的流程(上篇)