大数据之使用Flink处理Kafka中的数据到Redis
Posted Eternity.Arrebol
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据之使用Flink处理Kafka中的数据到Redis相关的知识,希望对你有一定的参考价值。
文章目录
前言
本题来源于全国职业技能大赛之大数据技术赛项赛题(其他暂不透露)
题目:使用Flink消费Kafka中ProduceRecord主题的数据,统计在已经检验的产品中,各设备每五分钟生产产品总数,将结果存入Redis中,key值为“totalproduce”,value值为“设备id,最近五分钟生产总数”。
注:ProduceRecord主题,生产一个产品产生一条数据;
change_handle_state字段为1代表已经检验,0代表未检验;
时间语义使用Processing Time。
提示:以下是本篇文章正文内容,下面案例可供参考(使用Scala语言编写)
一、读题分析
涉及组件:Flink,Kafka,Redis
涉及知识点:
1.Flink消费Kafka中的数据
2.Flink将数据存入到Redis数据库中
3.Flink时间窗口的概念和使用(难点)
4.FlinkSQL算子的使用
二、使用步骤
1.导入配置文件到pom.xml
<!--flink连接kafka配置-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.14.0</version>
</dependency>
<!--配置redis链接-->
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.12</artifactId>
<version>1.1.0</version>
</dependency>2.代码部分
直接上代码,代码如下(示例):
package C.dataAndCalculation.shtd_industry.tasl2_FlinkDealKafka
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import org.apache.flink.streaming.connectors.redis.RedisSink
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand, RedisCommandDescription, RedisMapper
import java.util.Properties
object FlinkToKafkaRedis
def main(args: Array[String]): Unit =
//创建FLink流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置并行度
env.setParallelism(1)
//指定时间语义
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime)
//Kafka的配置
val properties = new Properties()
properties.setProperty("bootstrap.servers", "bigdata1:9092,bigdata2:9092,bigdata3:9092")
properties.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringSerializer")
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("auto.offset.reset", "earliest")
//读取Kafka数据
val kafkaStream: DataStream[String] = env.addSource(new FlinkKafkaConsumer[String]("ProduceRecord", new
SimpleStringSchema(), properties))
//使用flink算子对数据进行处理
val dateStream = kafkaStream
.map(line =>
val data = line.split(",")
(data(1).toInt, data(9).toInt)
)
.filter(_._2 == 1)
.keyBy(_._1)
.timeWindow(Time.minutes(1))
.sum(1)
//打印做测试
dateStream.print("ds")
//连接Redis数据库的配置
val config: FlinkJedisPoolConfig = new FlinkJedisPoolConfig.Builder()
.setHost("bigdata1")
.setPort(6379)
.build()
// 创建RedisSink对象,并将数据写入Redis
val redisSink = new RedisSink[(Int, Int)](config, new MyRedisMapper)
// 发送数据
dateStream.addSink(redisSink)
//执行Flink程序
env.execute("FlinkToKafkaToRedis")
// 根据题目要求
class MyRedisMapper extends RedisMapper[(Int, Int)]
//这里使用RedisCommand.HSET不用RedisCommand.SET,前者创建RedisHash表后者创建Redis普通的String对应表
override def getCommandDescription: RedisCommandDescription = new RedisCommandDescription(RedisCommand.HSET,
"totalproduce")
override def getKeyFromData(t: (Int, Int)): String = t._1 + ""
override def getValueFromData(t: (Int, Int)): String = t._2 + ""
三、重难点分析
//使用flink算子对数据进行处理
val dateStream = kafkaStream
.map(line =>
val data = line.split(",")
(data(1).toInt, data(9).toInt)
)
.filter(_._2 == 1)
.keyBy(_._1)
.timeWindow(Time.minutes(1))
.sum(1)从Kafka读取ProduceRecord的数据,格式如下:
20,116,0009,2023-03-16 15:43:01,2023-03-16 15:43:09,2023-03-16 15:43:15,20770,1900-01-01 00:00:00,184362,0
21,110,0006,2023-03-16 15:42:43,2023-03-16 15:43:13,2023-03-16 15:43:17,12794,1900-01-01 00:00:00,183215,0
22,111,0003,2023-03-16 15:42:39,2023-03-16 15:43:11,2023-03-16 15:43:19,21168,1900-01-01 00:00:00,180754,1
23,116,00010,2023-03-16 15:43:15,2023-03-16 15:43:18,2023-03-16 15:43:22,20464,1900-01-01 00:00:00,185938,0
24,116,0002,2023-03-16 15:43:22,2023-03-16 15:43:21,2023-03-16 15:43:24,18414,1900-01-01 00:00:00,188880,1
25,114,00010,2023-03-16 15:42:47,2023-03-16 15:43:18,2023-03-16 15:43:26,25280,1900-01-01 00:00:00,186866,1
26,117,0003,2023-03-16 15:42:53,2023-03-16 15:43:24,2023-03-16 15:43:28,10423,1900-01-01 00:00:00,183201,1
首先从Kafka提取到数据后是流数据,我们需要使用DatastreamAPI相关的算子进行数据处理,
1.对每一条数据进行map转换,目的就是提取到我们需要的数据。在这里使用了lambda表达式,也可以自己写一个类继承MapFunction(这里不做演示)。
2.使用filter过滤题目中“为1代表已经检验,0代表未检验”。
3.使用keyby对数据进行分组操作,此时数据的类型是keyedStream,按照设备ID进行分组。
4.使用timeWindow前必须要进行keyby操作,本身就是keyedStream中的方法。根据题目“各设备每五分钟生产产品总数”使用时间窗口函数。
注:这里的Time方法的包必须是
org.apache.flink.streaming.api.windowing.time.Time
否则无效,并且这里还需要指定时间语义题目中有给,在env设置指定时间语义
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime)
5.这里类型是windowdStream,最后对数据进行聚合操作,转变为DataStream
总结
本文仅仅介绍了Flink对Kafka中的数据提取进行一系列转换存入到Redis的操作,题目不难,难的是能否熟练使用Flink的算子和对时间窗口概念的理解。
---最后附上导入到Redis数据库的图---
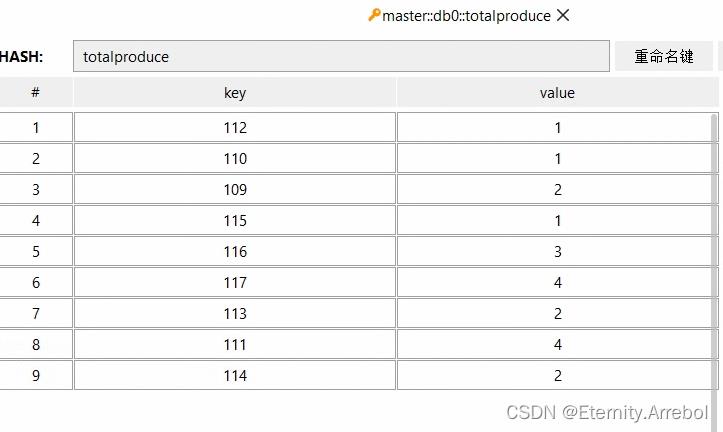
Flink系列之:基于scala语言实现flink实时消费Kafka Topic中的数据
Flink系列之:基于scala语言实现flink实时消费Kafka Topic中的数据
一、引入flink相关依赖
<groupId>com.bigdata</groupId>
<artifactId>flink</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<flink.version>1.13.1</flink.version>
<scala.binary.version>2.12</scala.binary.version>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-scala -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_$scala.binary.version</artifactId>
<version>$flink.version</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-scala -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_$scala.binary.version</artifactId>
<version>$flink.version</version>
<!-- <scope>provided</scope>-->
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_$scala.binary.version</artifactId>
<version>$flink.version</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_$scala.binary.version</artifactId>
<version>$flink.version</version>
</dependency>
</dependencies>
二、properties保存连接kafka的配置
//用properties保存kafka连接的相关配置
val properties = new Properties()
properties.setProperty("bootstrap.servers","10.129.44.26:9092,10.129.44.32:9092,10.129.44.39:9092")
properties.setProperty("sasl.jaas.config","org.apache.kafka.common.security.plain.PlainLoginModule required username=\\"debezium\\" password=\\"swlfalfal\\";")
properties.setProperty("security.protocol","SASL_PLAINTEXT")
properties.setProperty("sasl.mechanism", "PLAIN")
properties.setProperty("group.id","flink-test")
properties.setProperty("auto.offset.reset","earliest")
三、构建flink实时消费环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env.setRestartStrategy(RestartStrategies.noRestart())
四、添加Kafka源和处理数据
val lines: DataStream[String] = env.addSource(new FlinkKafkaConsumer[String]
("debezium-test-optics_uds",new SimpleStringSchema(),properties))
lines.print()
//触发执行
env.execute()
五、完整代码
import org.apache.flink.api.common.restartstrategy.RestartStrategies
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import java.util.Properties
object SourceKafka
def main(args: Array[String]): Unit =
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env.setRestartStrategy(RestartStrategies.noRestart())
//用properties保存kafka连接的相关配置
val properties = new Properties()
properties.setProperty("bootstrap.servers","10.129.44.26:9092,10.129.44.32:9092,10.129.44.39:9092")
properties.setProperty("sasl.jaas.config","org.apache.kafka.common.security.plain.PlainLoginModule required username=\\"debezium\\" password=\\"******\\";")
properties.setProperty("security.protocol","SASL_PLAINTEXT")
properties.setProperty("sasl.mechanism", "PLAIN")
properties.setProperty("group.id","flink-test")
properties.setProperty("auto.offset.reset","earliest")
//添加kafka源,并打印数据
val lines: DataStream[String] = env.addSource(new FlinkKafkaConsumer[String]
("debezium-test-optics_uds",new SimpleStringSchema(),properties))
lines.print()
//触发执行
env.execute()
六、执行程序查看消费到的数据

"schema":
"type":"struct",
"fields":[
"type":"struct",
"fields":[
"type":"int32",
"optional":false,
"field":"sid"
,
"type":"string",
"optional":false,
"field":"sname"
,
"type":"int64",
"optional":false,
"name":"io.debezium.time.Timestamp",
"version":1,
"field":"updatetime"
,
"type":"string",
"optional":false,
"field":"ssex"
],
"optional":true,
"name":"debezium_test_optics_uds.Value",
"field":"before"
,
"type":"struct",
"fields":[
"type":"int32",
"optional":false,
"field":"sid"
,
"type":"string",
"optional":false,
"field":"sname"
,
"type":"int64",
"optional":false,
"name":"io.debezium.time.Timestamp",
"version":1,
"field":"updatetime"
,
"type":"string",
"optional":false,
"field":"ssex"
],
"optional":true,
"name":"debezium_test_optics_uds.Value",
"field":"after"
,
"type":"struct",
"fields":[
"type":"string",
"optional":false,
"field":"version"
,
"type":"string",
"optional":false,
"field":"connector"
,
"type":"string",
"optional":false,
"field":"name"
,
"type":"int64",
"optional":false,
"field":"ts_ms"
,
"type":"string",
"optional":true,
"name":"io.debezium.data.Enum",
"version":1,
"parameters":
"allowed":"true,last,false,incremental"
,
"default":"false",
"field":"snapshot"
,
"type":"string",
"optional":false,
"field":"db"
,
"type":"string",
"optional":true,
"field":"sequence"
,
"type":"string",
"optional":true,
"field":"table"
,
"type":"int64",
"optional":false,
"field":"server_id"
,
"type":"string",
"optional":true,
"field":"gtid"
,
"type":"string",
"optional":false,
"field":"file"
,
"type":"int64",
"optional":false,
"field":"pos"
,
"type":"int32",
"optional":false,
"field":"row"
,
"type":"int64",
"optional":true,
"field":"thread"
,
"type":"string",
"optional":true,
"field":"query"
],
"optional":false,
"name":"io.debezium.connector.mysql.Source",
"field":"source"
,
"type":"string",
"optional":false,
"field":"op"
,
"type":"int64",
"optional":true,
"field":"ts_ms"
,
"type":"struct",
"fields":[
"type":"string",
"optional":false,
"field":"id"
,
"type":"int64",
"optional":false,
"field":"total_order"
,
"type":"int64",
"optional":false,
"field":"data_collection_order"
],
"optional":true,
"field":"transaction"
],
"optional":false,
"name":"debezium_test_optics_uds.Envelope"
,
"payload":
"before":null,
"after":
"sid":3600,
"sname":"f",
"updatetime":1661126400000,
"ssex":"a"
,
"source":
"version":"1.9.6.Final",
"connector":"mysql",
"name":"debezium-uds8-optics8-test_1h",
"ts_ms":1665155935000,
"snapshot":"false",
"db":"dw",
"sequence":null,
"table":"student",
"server_id":223344,
"gtid":null,
"file":"mysql-bin.000012",
"pos":6193972,
"row":0,
"thread":66072,
"query":"/* ApplicationName=DBeaver 21.0.1 - SQLEditor <Script-3.sql> */ insert into dw.student values(3600,'f','20220822','a')"
,
"op":"c",
"ts_ms":1665155935640,
"transaction":null
以上是关于大数据之使用Flink处理Kafka中的数据到Redis的主要内容,如果未能解决你的问题,请参考以下文章
Flink系列之:基于scala语言实现flink实时消费Kafka Topic中的数据
简析Spark Streaming/Flink的Kafka动态感知