ElasticSearch高性能设计
Posted 毛奇志
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch高性能设计相关的知识,希望对你有一定的参考价值。
文章目录
- 一、前言
- 二、数据库搜索和ES搜索
- 三、ElasticSearch高性能设计
- 四、尾声
一、前言
二、数据库搜索和ES搜索
2.1 数据库搜索三个问题
容量问题: 电商网站商品上亿条时,涉及到单表数据过大必须拆分表,数据库磁盘占用过大必须分库(mycat)。
性能问题: mysql实现模糊查询必须使用 like关键字, 只有 后模糊 才能走索引,前模糊和全模糊都不会走索引,比如查询“笔记本电脑”等关键词时,上亿条数据的商品名字段逐行扫描,性能跟不上。
不能分词: 只能搜索完全和关键词一样的数据,那么数据量小时,搜索“笔记电脑”,“电脑”数据要不要给用户。
正式由于这些缺陷,在数据量比较小的站内搜索/垂直搜索,可以使用数据库,但是对于PB级别大数据量的互联网搜索,肯定不会使用数据库搜索。
Lucene的诞生解决了数据库的这三个问题,容量非常大,存储大数据量不需要分库分表;模糊查询性能非常快;而且还需要使用使用分词查询。Lucene 其实就是一个jar包,里面封装了全文检索的引擎、搜索的算法代码。开发时,引入lucen的jar包,通过api开发搜索相关业务。底层会在磁盘建立索引库。
但是Lucene 有一个最大的缺陷,它是一个单实例搜索引擎,这不符合分布式的互联网的需求,所以有了elasticsearch,它是一个多实例的分布式集群搜索引擎,elasticsearch 每个实例就是一个 lucence ,各个节点之间是平等的/平级的,没有主从关系。
elasticsearch 是使用Java语言编写的,与springboot项目集成起来非常方便。
2.2 Elasticsearch
Elasticsearch官网:https://www.elastic.co/cn/products/elasticsearch1.3.2
2.2.1 Elasticsearch的两个功能
Elasticsearch的两个功能:分布式的搜索引擎和数据分析引擎
搜索:互联网搜索、电商网站站内搜索、OA系统查询
数据分析:电商网站查询近一周哪些品类的图书销售前十;新闻网站,最近3天阅读量最高的十个关键词,舆情分析。
lucene和elasticsearch的区别
Lucene:最先进、功能最强大的搜索库,直接基于lucene开发,非常复杂,api复杂
Elasticsearch:基于lucene,封装了许多lucene底层功能,提供简单易用的restful api接口和许多语言的客户端,如java的高级客户端(Java High Level REST Client)和底层客户端(Java Low Level REST Client)
2.2.2 Elasticsearch的两个特点
分布式:ES自动可以将海量数据分散到多台服务器上去存储和检索,进行并行查询,提高搜索效率。相对的,Lucene是单机应用。
近实时:数据库上亿条数据查询,搜索一次耗时几个小时,是批处理(batch-processing)。而es只需秒级即可查询海量数据,所以叫近实时。秒级。
2.3 Elasticsearch核心概念 vs. 数据库核心概念
| 关系型数据库(比如Mysql) | 非关系型数据库(Elasticsearch) |
|---|---|
| 数据库Database | 索引Index |
| 表Table | 索引Index(原为Type) |
| 数据行Row | 文档Document |
| 数据列Column | 字段Field |
| 约束 Schema | 映射Mapping |
此外,ES也对应MySQL,有 order by、group by 这些操作,还有avg sum max min一系列聚合函数。我们现在对上表中ES各个概念介绍。
2.3.1 Index:索引
包含一堆有相似结构的文档数据。
索引创建规则:
(1) 仅限小写字母
(2) 不能包含\\、/、 *、?、"、<、>、|、#以及空格符等特殊符号
(3) 从7.0版本开始不再包含冒号
(4) 不能以-、_或+开头
(5) 不能超过255个字节(注意它是字节,因此多字节字符将计入255个限制)
2.3.2 Type:类型
每个索引里都可以有一个或多个type,type是index中的一个逻辑数据分类,一个type下的document,都有相同的fifield。7.x版本正式被去除。
问题:ES为什么要引入Type?
回答:因为关系型数据库比非关系型数据库的概念提出的早,而且很成熟,应用广泛。所以,后来很多NoSQL(包括:MongoDB,Elasticsearch等)都参考并延用了传统关系型数据库的基本概念。由于需要有一个对应关系型数据库表的概念,所以type应运而生。
问题:ES各个版本中的Type?
回答:在 5.X 版本中,一个 index 下可以创建多个 type;
在 6.X 版本中,一个 index下只能存在一个 type;
在7.X 版本中,直接去除了 type 的概念,就是说index 不再会有 type。
问题:为什么要7.X版本去除Type?
答: 因为 Elasticsearch 设计初期,是直接查考了关系型数据库的设计模式,存在了 type(数据表)的概念。但是,其搜索引擎是基于 Lucene 的,这种 “基因”决定了 type 是多余的。 Lucene 的全文检索功能之所以快,是因为 倒序索引 的存在。而这种 倒序索引 的生成是基于 index 的,而并非 type。多个type 反而会减慢搜索的速度。为了保持 Elasticsearch “一切为了搜索” 的宗旨,适当的做些改变(去除 type)也是无可厚非的,也是值得的。
问题:为何不是在 6.X 版本开始就直接去除 type,而是要逐步去除type?
回答:因为历史原因,前期 Elasticsearch 支持一个 index 下存在多个 type的,而且,有很多项目在使用Elasticsearch 作为数据库。如果直接去除 type 的概念,不仅是很多应用 Elasticsearch 的项目将面临业务、功能和代码的大改,而且对于 Elasticsearch 官方来说,也是一个巨大的挑战(这个是伤筋动骨的大手术,很多涉及到 type源码是要修改的)。所以,权衡利弊,采取逐步过渡的方式,最终,推迟到 7.X 版本才完成 “去除 type” 这个 革命性的变革。
2.3.3 Document:文档
es中的最小数据单元。一个document就像数据库中的一条记录。通常以json格式显示。多个document存储于一个索引(Index)中。
2.3.4 Field:字段
就像数据库中的列(Columns),定义每个document应该有的字段。
2.3.5 Shard:分片
index数据过大时,将index里面的数据,分为多个shard,分布式的存储在各个服务器上面。可以支持海量数据和高并发,提升性能和吞吐量,充分利用多台机器的cpu。
2.3.6 Replica:副本
在分布式环境下,任何一台机器都会随时宕机,如果宕机,index的一个分片没有,导致此index不能搜索。所以,为了保证数据的安全,我们会将每个index的分片进行备份,存储在另外的机器上。保证少数机器宕机es集群仍可以搜索。能正常提供查询和插入的分片我们叫做主分片(primary shard),其余的我们就管他们叫做备份的分片(replica shard)。
2.4 Elasticsearch文档存储
先说Elasticsearch的文件存储,Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式,比如下面这条用户数据:
"name" : "carl",
"sex" : "Male",
"age" : 18,
"birthDate": "1990/05/10",
"interests": [ "sports", "music" ]
用Mysql这样的数据库存储就会容易想到建立一张User表,有name,sex等字段,在Elasticsearch里这就是一个文档,当然这个文档会属于一个User的类型,各种各样的类型存在于一个索引当中。这里有一份简易的将Elasticsearch和关系型数据术语对照表:
关系数据库 ⇒ 数据库 ⇒ 表 ⇒ 行 ⇒ 列(Columns)
Elasticsearch ⇒ 索引(Index) ⇒ 类型(type) (7.x版本正式将type剔除) ⇒ 文档 (Docments) ⇒ 字段(Fields)
一个 Elasticsearch 集群可以包含多个索引(数据库),也就是说其中包含了很多类型(表)。这些类型中包含了很多的文档(行),然后每个文档中又包含了很多的字段(列)。Elasticsearch的交互,可以使用JavaAPI,也可以直接使用HTTP的Restful API方式,
三、ElasticSearch高性能设计
ElasticSearch基于Lucene,同时解决了关系型数据库的单表容量问题、查询性能问题、不能分词查询问题,即实现了存得多、查得快、查得聪明,那么,ElasticSearch是如何做到的呢?这都要归功于ElasticSearch内部的一系列高性能设计,让我们来认识一下。
3.1 倒排索引的设计让ElasticSearch查询更快
为什么ElasticSearch比传统的数据库查询更快,因为ElasticSearch是基于倒排索引,但是传统数据库是基于B树/B+树。
传统数据库:二叉树查找效率是O(n),同时插入新的节点不必移动全部节点,所以用树型结构存储索引,能同时兼顾插入和查询的性能(AVL)。因此在这个基础上,再结合磁盘的读取特性(顺序读/随机读)(多路查找树,B树)。传统的关系型数据库采用的是B-Tree/B+Tree这样的数据结构:为了提高查询的效率,减少磁盘寻道次数,将多个值作为一个数组通过连续区间存放,一次寻道读取多个数据,同时也降低树的高度。
ElasticSearch:ES的搜索数据结构模型基于倒排索引。倒排索引是指数据存储时,进行分词建立term索引库。倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(inverted file)。
问题:ElasticSearch结构化数据怎么储存呢?
回答:
我们拿到三条结构化数据:
| ID | Name | Age | Sex |
|---|---|---|---|
| 1 | 叮咚 | 18 | Female |
| 2 | Tom | 50 | Male |
| 3 | carl | 18 | Male |
ID是Elasticsearch自建的文档id,那么Elasticsearch建立的索引如下:
Name:
| Term | Posting List |
|---|---|
| 叮咚 | 1 |
| TOM | 2 |
| carl | 3 |
Age:
| Term | Posting List |
|---|---|
| 50 | 2 |
| 18 | [1,3] |
Sex:
| Term | Posting List |
|---|---|
| Female | 1 |
| Male | [2,3] |
Elasticsearch分别为每个field都建立了一个从该filed到ID的映射关系,这个映射关系就被称为倒排索引。无论是何种类型的倒排索引,里面的 ID 都是存储到一个 Posting List 的结构中,这个 Posting List 就被称为是倒排表。
从上面三个表中,左边列Tom,carl, 18, Female这些叫term(分类索引),而右边列[1,2]就是Posting List(倒排表)。Posting list就是一个int的数组,存储了所有符合某个term的文档id。
通过posting list这种索引方式可以很快进行查找,比如要找age=18的词条,就是1和3。但是,如果这里有上千万的记录呢?答案是Term Dictionary。
Term Dictionary(词典)
Elasticsearch为了能快速找到某个term,将所有的term排个序,二分法查找term,log(N)的查找效率,就像通过字典查找一样,这就是Term Dictionary。现在好像跟我们的传统B树的方式一样啊 。那么我们的ES有什么进步呢?答案是将一个更小的词典Term Index存放到内存里面。
Term Index(词典索引)
B-Tree通过减少磁盘寻道次数来提高查询性能,Elasticsearch也是采用同样的思路,直接通过内存查找term,不读磁盘,但是如果term太多,term dictionary也会很大,放内存不现实,于是有了Term Index,就像字典里的索引页一样,A开头的有哪些term,分别在哪页,可以理解term index是一颗树,这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。
所以term index不需要存下所有的term,而仅仅是他们的一些前缀与Term Dictionary的block之间的映射关系,可以使term index缓存到内存中。从term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘随机读的次数。
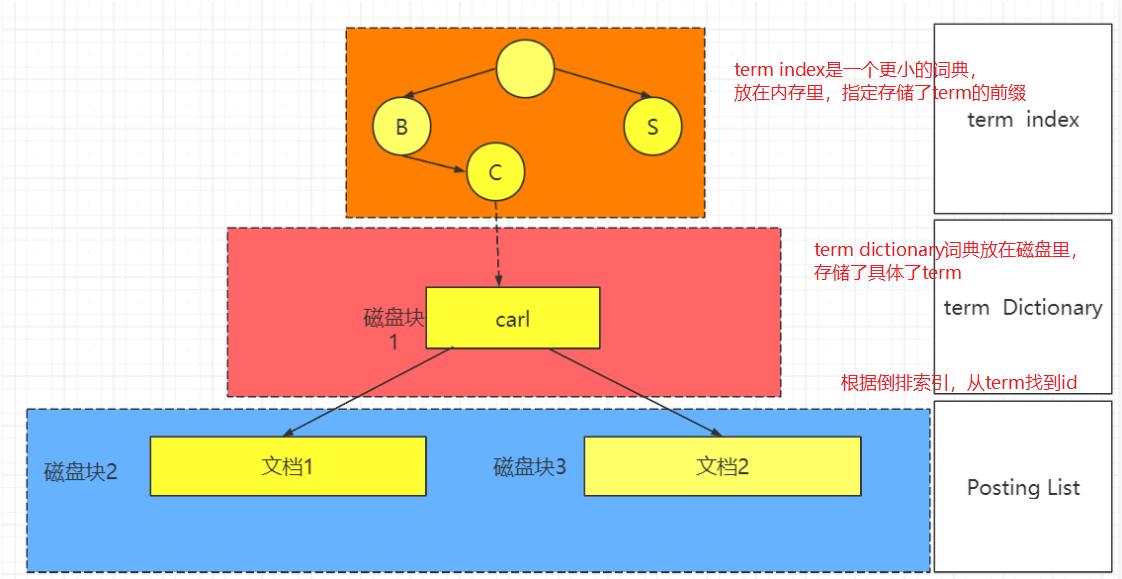
block块:文件系统不是一个扇区一个扇区的来读数据,太慢了,所以有了block(块)的概念,它是一个块一个块的读取的,block才是文件存取的最小单位。
3.2 FST的设计让ElasticSearch用最小的内存存储Term Index
Finite StateTransducers 简称 FST,通常中文译作有穷状态转换器或者有限状态传感器,FST是一项将一个字节序列映射到block块的技术。
假设我们现在要将mop, moth, pop, star, stop and top(term index里的term前缀)映射到序号:0,1, 2,3,4,5(term dictionary的block位置)。最简单的做法就是定义个Map<string, integer="">,找到自己的位置对应入座就好了,但从内存占用少的角度想想,有没有更优的办法呢?答案就是:FST。
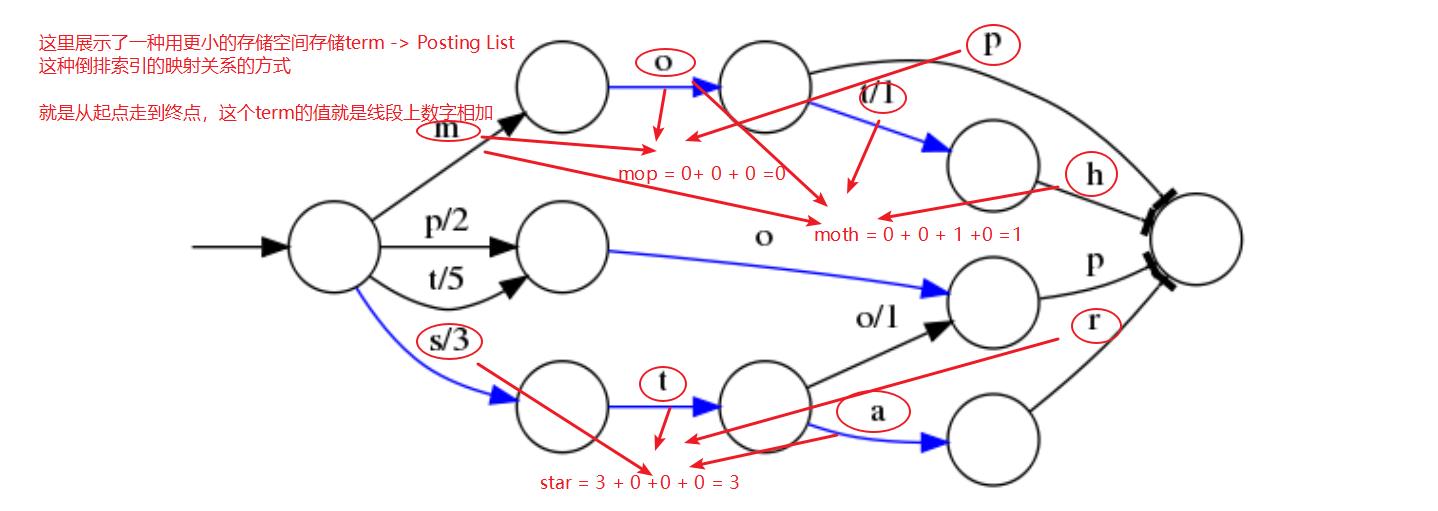
看图可知:
mop = 0 + 0 + 0 = 0
moth = 0 + 0 + 1 + 0 = 1
pop = 2 + 0 + 0 = 2
star = 3 + 0 + 0 +0 = 3
stop = 3 +0 +1 + 0 = 4
top = 5 + 0 + 0 = 5
⭕ 表示一种状态 , -->表示状态的变化过程,上面的字母/数字表示状态变化和权重。将单词分成单个字母通过⭕ 和–>表示出来,0权重不显示。如果⭕ 后面出现分支,就标记权重,最后整条路径上的权重加起来就是这个单词对应的序号。当遍历上面的每一条边的时候,都会加上这条边的输出,比如当输入是 stop 的时候会经过 s/3 和 o/1 ,相加得到的排序的顺序是 4 ;而对于 mop ,得到的排序的结果是 0 。
但是这个树并不会包含所有的term,而是很多term的前缀,通过这些前缀快速定位到这个前缀所属的磁盘的block,再从这个block去找文档列表。为了压缩词典的空间,实际上每个block都只会保存block内不同的部分,比如 mop 和 moth 在同一个以 mo 开头的block,那么在对应的词典里面只会保存 p 和 th ,这样空间利用率提高了一倍。
使用有限状态转换器在内存消耗上面要比远比 SortedMap 要少,但是在查询的时候需要更多的CPU资源。维基百科的索引就是使用的FST,只使用了69MB的空间,花了大约8秒钟,就为接近一千万个词条建立了索引,使用的堆空间不到256MB。
在ES中有一种查询叫模糊查询(fuzzy query),根据搜索词和字段之间的编辑距离来判断是否匹配。在ES4.0之前,模糊查询会先让检索词和所有的term计算编辑距离筛选出所有编辑距离内的字段;在ES4.0之后,采用了由Robert开发的,直接通过有限状态转换器就可以搜索指定编辑距离内的单词的方法,将模糊查询的效率提高了超过100倍。
现在已经把词典压缩成了词条索引,尺寸已经足够小到放入内存,通过索引能够快速找到文档列表。现在又有另外一个问题,把所有的文档的id放入磁盘中会不会占用了太多空间?如果有一亿个文档,每个文档有10个字段,为了保存这个posting list就需要消耗十亿个integer的空间,磁盘空间的消耗也是巨大的,ES采用了一个更加巧妙的方式来保存所有的id。这就是压缩技巧之Frame Of Reference。
3.3 Frame Of Reference的设计让ElasticSearch用最小的磁盘存储Posting List
Frame Of Reference 可以翻译成索引帧
Elasticsearch里除了上面说到用FST压缩term index外,对posting list也有压缩技巧。为了方便压缩,Elasticsearch要求posting list是有序的(为了提高搜索的性能,再任性的要求也得满足)。同时为了减小存储空间,所有的id都会进行delta编码(即增量编码)。
比如现在有id列表 [73, 300, 302, 332, 343, 372] ,转化成每一个id相对于前一个id的增量值(第一个id的前一个id默认是0,增量就是它自己)列表是 [73, 227, 2, 30, 11, 29] 。在这个新的列表里面,所有的id都是小于255的,所以每个id只需要一个字节存储。
解释:Elasticsearch要求posting list是有序的,除了第一个id以外,后面的id都存储为前一个id的增量,则
当 id列表为 [73, 300, 302, 332, 343, 372] ,Elasticsearch不会直接存储这个id列表,而是会计算增量,
第一个id为73,直接存储;
第二个id为300,但是不会存储300这个值,而是存储 300-73 =227 这个增量;
第三个id为302,但是不会存储302这个值,而是存储 302-(73+227) =2 这个增量;
以此类推,最后Elasticsearch的posting list实际存储的是 [73, 227, 2, 30, 11, 29] ,这样存储的数字就变小了,可以用更小的数据类型来存储每个值,从而达到节约磁盘空间。
实际上ES会做的更加精细,它会把所有的文档分成很多个block,每个block正好包含256个文档,然后单独对每个文档进行增量编码,计算出存储这个block里面所有文档最多需要多少位来保存每个id,并且把这个位数作为头信息(header)放在每个block 的前面。这个技术叫Frame of Reference,翻译成索引帧。
比如对上面的数据进行压缩(假设每个block只有3个文件而不是256),压缩过程如下
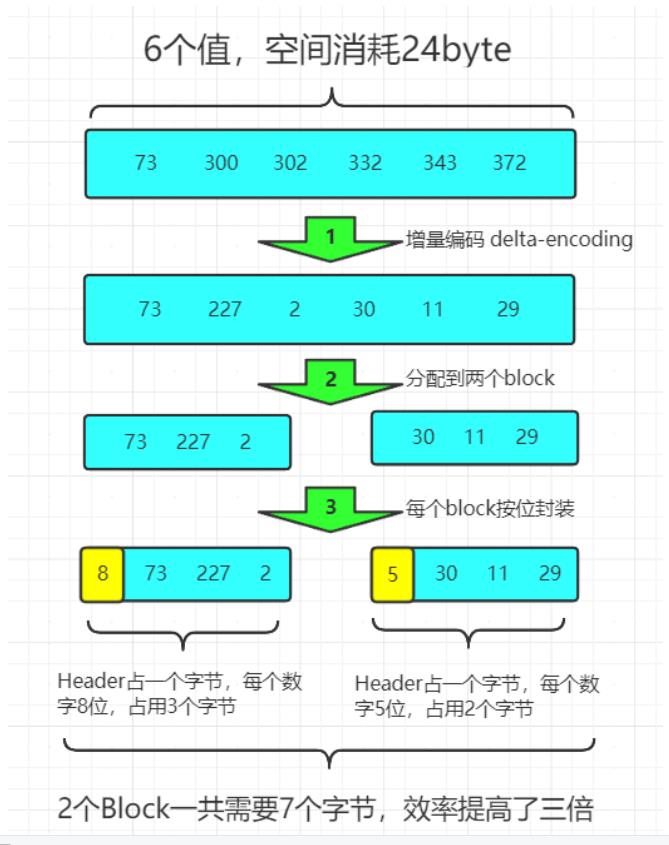
如果直接存储六个int类型,每个int类型4字节,需要24字节;但是使用增量编码,然后拆分到不同block里面,最后加一个header信息,表示数字个数,因为每个block中存储数字256以内,所以header中数字最大值位256,只需要 8位(一个字节)就足够存储header。然后对于第一个block中最大值位227,2 ^7 =128 ,2 ^8 =256,所以每个数字需要8位,则第一个block需要四字节(header头占一个字节,后面三个数字每个占一个字节)。对于第二个block中最大值是30,因为 2 ^5 =32 ,只需要 5 位就可以存放,所以第二个block只需要三字节(header一个字节,每个数字5位,就是5*3=15位,就是两字节(16位)就够了),所以两个block只需要7个字节,如果不使用增量编码,直接存储int需要24字节,占用磁盘空间仅仅 1/3 .
增量编码的本质上posting list有序排列,然后存储增量数字比原数字小,用每个数字用更少的位数就可以表示。
8个二进制位构成一个字节。这种压缩算法的原理就是通过增量,将原来的大数变成小数仅存储增量值,再精打细算按bit排好队,最后通过字节存储,而不是大大咧咧的尽管是2也是用int(4个字节)来存储。
在返回结果的时候,其实也并不需要把所有的数据直接解压然后一股脑全部返回,可以直接返回一个迭代器 iterator ,直接通过迭代器的 next 方法逐一取出压缩的id,这样也可以极大的节省计算和内存开销。
通过以上的方式可以极大的节省posting list的空间消耗,提高查询性能。不过ES为了提高filter过滤器查询的性能,还做了更多的工作,那就是缓存。
3.4 Roaring Bitmaps的设计让ElasticSearch用最小的磁盘存储缓存filter
ES会缓存频率比较高的filter查询,其中的原理也比较简单,即生成 (fitler, segment数据空间) 和id列表的映射,但是和倒排索引不同,我们只把常用的filter缓存下来而倒排索引是保存所有的,并且filter缓存应该足够快,不然直接查询不就可以了。ES直接把缓存的filter放到内存里面,映射的posting list放入磁盘中。
ES在filter缓存使用的压缩方式和倒排索引的压缩方式并不相同,filter缓存使用了roaring bitmap的数据结构,在查询的时候相对于上面的Frame of Reference方式CPU消耗要小,查询效率更高,代价就是需要的存储空间(磁盘)更多。
Roaring Bitmap是由int数组和bitmap这两个数据结构改良过的成果——int数组速度快但是空间消耗大,bitmap相对来说空间消耗小但是不管包含多少文档都需要12.5MB的空间,即使只有一个文件也要12.5MB的空间,这样实在不划算,所以权衡之后就有了下面的Roaring Bitmap。
3.4.1 认识Roaring Bitmaps数据结构
Bitmap是一种数据结构,假设有某个posting list:[1,3,4,7,10]
对应的bitmap就是:[1,0,1,1,0,0,1,0,0,1]
非常直观,用0/1表示某个值是否存在,比如10这个值就对应第10位,对应的bit值是1,这样用一个字节就可以代表8个文档id,旧版本(5.0之前)的Lucene就是用这样的方式来压缩的,但这样的压缩方式仍然不够高效,如果有1亿个文档,那么需要12.5MB的存储空间,这仅仅是对应一个索引字段(我们往往会有很多个索引字段)。于是有人想出了Roaring bitmaps这样更高效的数据结构。
解释:如果有1亿个文档,那么需要12.5MB的存储空间
bitmap就是按位存储,空间变为原来的1/8,1亿 = 110 ^8 ,除以 110 ^6 (1M)= 100 ,再次除以 8 = 12.5,所以需要 12.5M
Bitmap的缺点是存储空间随着文档个数线性增长,Roaring bitmaps需要打破这个魔咒就一定要用到某些指数特性.
(1) Roaring Bitmap首先会根据每个id的高16位分配id到对应的block里面,比如第一个block里面id应该都是在0到65535之间,第二个block的id在65536和131071之间
(2) 对于每一个block里面的数据,根据id数量分成两类
a. 如果数量小于4096,就是用short数组保存
b. 数量大于等于4096,就使用bitmap保存
3.4.2 ES中使用Roaring Bitmaps数据结构
在每一个block里面,一个数字实际上只需要2个字节来保存就行了,因为高16位在这个block里面都是相同的,高16位就是block的id,block id和文档的id都用short保存。
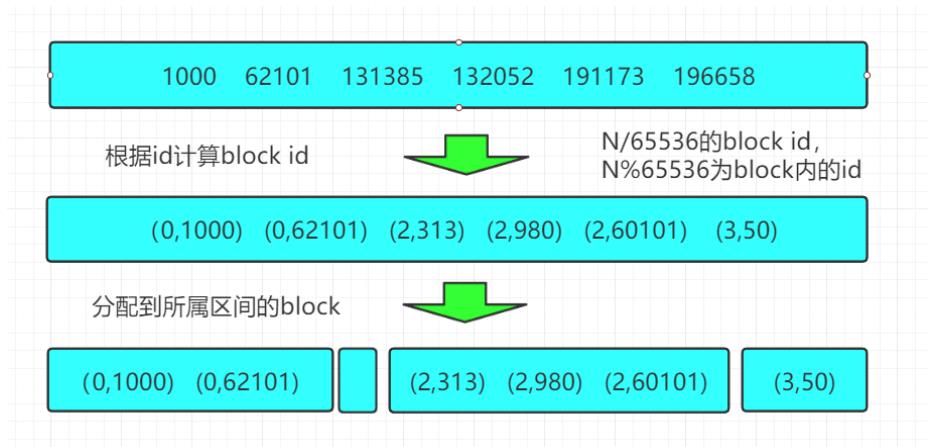
至于4096这个分界线,因为当数量小于4096的时候,如果用bitmap就需要8kB的空间,而使用2个字节的数组空间消耗就要少一点。比如只有2048个值,每个值2字节,一共只需要4kB就能保存,但是bitmap需要8kB。
解释:在每一个block里面,一个数字实际上只需要2个字节来保存就行了
因为 N%66536 的值是 0~65535 ,需要的位数是16位,所以两个字节就可以了,直接使用java中的short类型就可以了
解释:对于每一个block里面的数据,如果数量小于4096,就是用short数组保存,每个数组元素都是一个short类型;对于每一个block里面的数据,如果数量大于等于4096,就使用bitmap保存。
对于数量等于4096(2 ^12 = 4 * 2 ^10 =4k)的时候,如果用bitmap就需要8kB的空间,如果用short数组也是8KB
short数组:4096个值就是2 ^12 = 4k,然后 4k * 2B = 8kB
bitmap:因为 N%66536 的值是 0~65535 ,所以每个block中存储的最大数量就是 2 ^16,对于bitmap来说,只需要 8KB 就可以满足了 8KB = 8 * 1K * 1B(8b) = 2 ^3 * 2 ^10 * 2 ^3 = 2 ^16
解释:只有2048个值,每个值2字节,使用short类型一共只需要4kB就能保存,但是bitmap需要8kB
short数组:2048个值就是2 ^11 = 2k,然后 2k * 2B = 4kB
bitmap:因为 N%66536 的值是 0~65535 ,所以每个block中存储的最大数量就是 2 ^16,对于bitmap来说,只需要 8KB 就可以满足了 8KB = 8 * 1K * 1B(8b) = 2 ^3 * 2 ^10 * 2 ^3 = 2 ^16
小结:无论是存储1个数字还是65536个数字,使用bitmap都需要8KB,当存储的数字量小于4096的时候,使用short数组更好,因为占内存更小。
由此见得,Elasticsearch使用的倒排索引确实比关系型数据库的B-Tree索引快。
3.5 跳表实现多个field的联合索引做倒排索引
上面说了半天都是单field索引,如果多个field索引的联合查询,倒排索引如何满足快速查询的要求呢?答案是利用跳表(Skip list)的数据结构快速做“与”运算,或者利用上面提到的bitset按位“与” 来实现。
3.5.1 认识跳表这个数据结构
先看看跳表的数据结构:
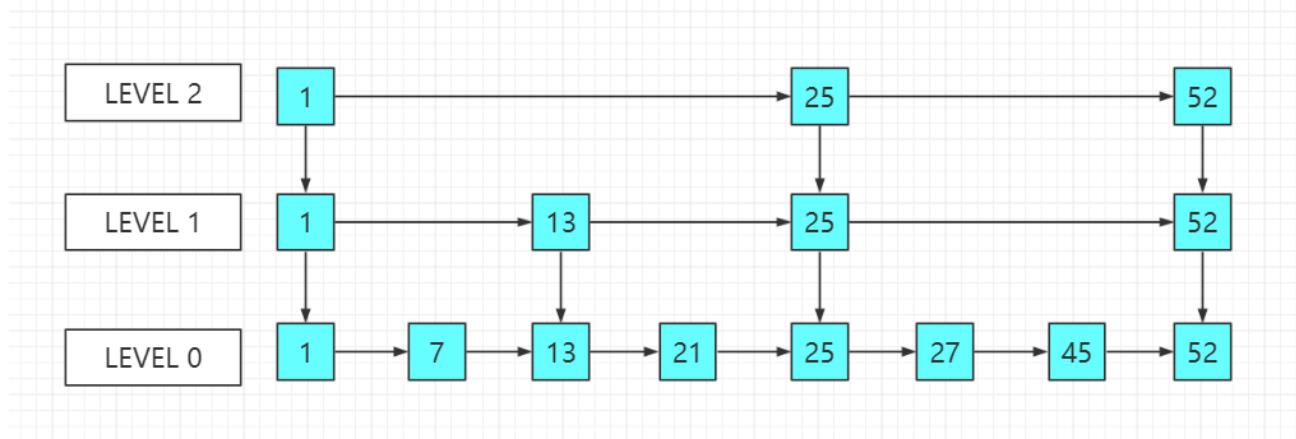
将一个有序链表level0,挑出其中几个元素到level1及level2,每个level越往上,选出来的指针元素越少,查找时依次从高level往低查找,比如45,先找到level2的25,最后找到45,查找效率和2叉树的效率相当,但也是用了一定的空间冗余来换取的。
3.5.2 跳表实现多个field的联合索引做倒排索引
假设有下面三个posting list需要联合索引:
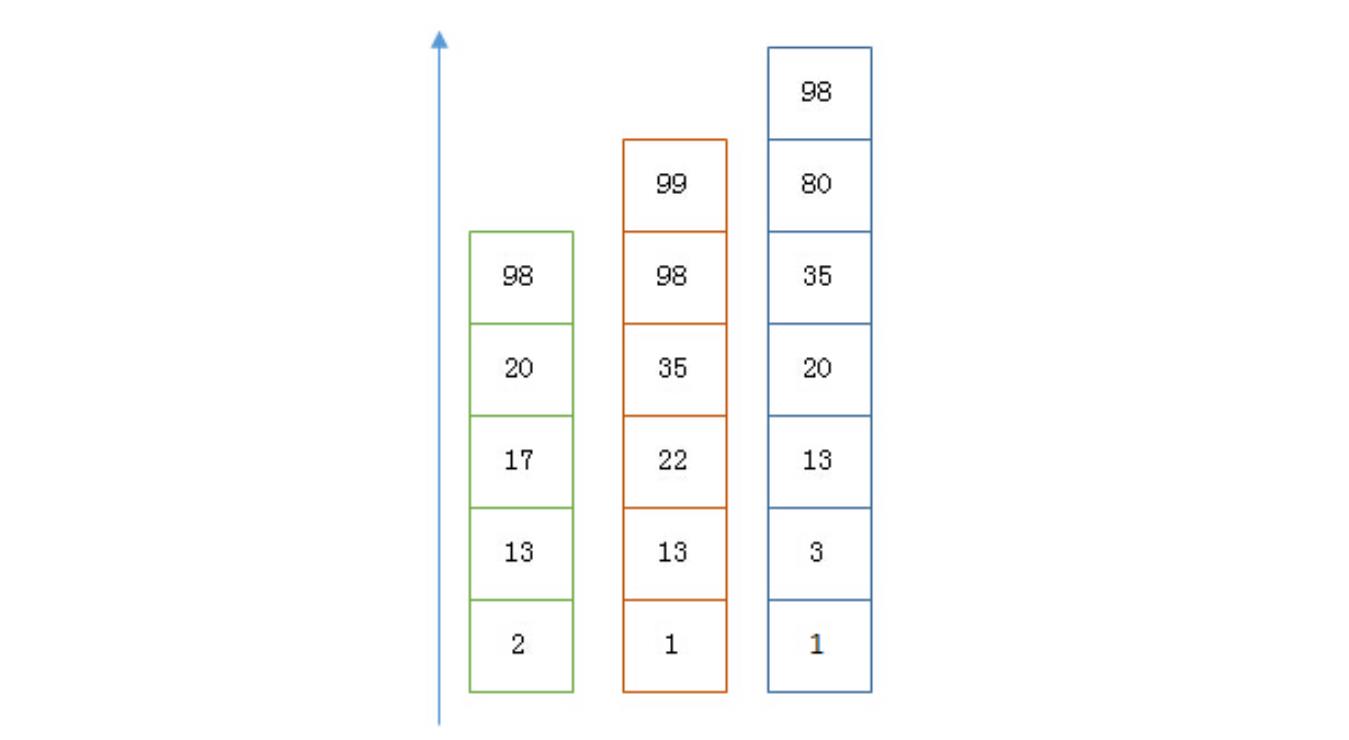
如果使用跳表,对最短的posting list中的每个id,逐个在另外两个posting list中查找看是否存在,最后得到交集的结果。
如果使用bitset(基于bitMap),就很直观了,直接按位与,得到的结果就是最后的交集。
注意,这是我们倒排索引实现联合索引的方式,不是我们ES就是这样操作的。
3.6 总结和思考
Elasticsearch的索引思路是将磁盘里的东西尽量搬进内存,减少磁盘随机读取次数(同时也利用磁盘顺序读特性),结合各种奇技淫巧的压缩算法,用及其苛刻的态度使用内存。
所以,对于使用Elasticsearch进行索引时需要注意:
(1) 不需要索引的字段,一定要明确定义出来,因为默认是自动建索引的
(2) 对于String类型的字段,不需要analysis(分词)的也需要明确定义出来,因为默认也是会analysis的
(3) 选择有规律的ID很重要,随机性太大的ID(比如java的UUID)不利于查询,因为压缩算法都是对Posting list里的大量ID进行压缩的,那如果ID是顺序的,或者是有公共前缀等具有一定规律性的ID,压缩比会比较高;
四、尾声
ElasticSearch高性能设计,完成了。
天天打码,天天进步!!
以上是关于ElasticSearch高性能设计的主要内容,如果未能解决你的问题,请参考以下文章