FlinkSQL平台化之路-StreamX提交源码剖析
Posted darkness0604
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了FlinkSQL平台化之路-StreamX提交源码剖析相关的知识,希望对你有一定的参考价值。
前言背景
在公司里做实时计算开发,之前大部分job都采用的是基于java的streaming编程方式进行的,这样的好处很明显:足够灵活,可以应对各种复杂的实时分析场景,但缺点也很明显:上手存在门槛,需要懂code,如果是一个逻辑简单的计算需求,用code整体编写起来的方式,会让整个流程也略显笨重…
于是我开始想,目前的公司流式开发的流程也趋于稳定了,而对于后续接近来的需求,如果可以用SQL解决,就尽可能用SQL解决,这样无论是从开发成本或者是未来如果版本升级造成的迁移成本都会有一个明显的降低。
而如果单纯通过Flink-SQL来进行提交任务,每次再为此去编写一个java job未免有点脱了裤子放屁的感觉,我更期望的方式是:在一个可视化的界面上,我键入了若干行SQL,当点击提交的时候, 将SQL转化成flink job工作流图,然后开始实时任务的计算。
调研过程
Flink-SQL-Gateway
首先是调研了一下市面上比较有代表的第三方对于这块的实现,最先找到的就是比较有名的阿里出品的Flink-SQL-Gateway,它提供了Rest接口,只需要通过HTTP请求,将SQL提交给它,就会将SQL进行解析成Job,然后提交到集群去执行。
**问题:**开发社区极其不活跃,甚至已经到了很长时间没有更新的状态,因为flink一直在更新,而它却一直止步,而主要的更新来源反倒是来自信赖它的人们的PR,主要的开发人员只是偶尔看到合并一下PR,且不保准合并上来的代码就是可运行的:我把最新版本的github代码拉下来,是没办法运行成功的,有明显的编译错误,后面通过一点点自己改好,才能跑起来。
Dlink
这个相对于上面就好用多了,直接满足了我想要的大部分设想,比如说可视化平台、比如说SQL校验、SQL解析、SQL转成可运行Job,关于它有的一切,官方是这么说的:
● 可视化交互式 FlinkSQL 和 SQL 的数据开发平台:自动提示补全、语法高亮、调试执行、语法校验、语句美化、全局变量等
●支持全面的多版本的 FlinkSQL 作业提交方式:Local、Standalone、Yarn Session、Yarn Per-Job、Kubernetes Session、Kubernetes Application
● 支持 Apache Flink所有的 Connector、UDF、CDC等
● 支持 FlinkSQL 语法增强:兼容 Apache Flink SQL、表值聚合函数、全局变量、CDC多源合并、执行环境、语句合并、共享会话等
● 支持易扩展的 SQL作业提交方式:ClickHouse、Doris、Hive、mysql、Oracle、Phoenix、PostgreSql、SqlServer等
● 支持实时调试预览 Table 和 ChangeLog 数据及图形展示
● 支持语法逻辑检查、作业执行计划、字段级血缘分析等
● 支持Flink 元数据、数据源元数据查询及管理● 支持实时任务运维:作业上线下线、作业信息、集群信息、作业快照、异常信息、作业日志、数据地图、即席查询、历史版本、报警记录等
● 支持作为多版本 FlinkSQL Server 的能力以及 OpenApi
● 支持易扩展的实时作业报警及报警组:钉钉、微信企业号等
● 支持完全托管的 SavePoint 启动机制:最近一次、最早一次、指定一次等● 支持多种资源管理:集群实例、集群配置、Jar、数据源、报警组、报警实例、文档、用户、系统配置等
问题:
1、开发力量薄弱:虽然更新的相对来说还算活跃,但是这个项目的维护和开发者只有一个人,项目之所以会出现,是因为作者所在公司也需要搭建这种可视化平台, 他在这个过程中,把其中可通用的部分抽离出来开源并且陆续迭代,并且主要是自己一个人维护(不得不说,这个作者也很厉害的)
2、局部操作存在原生化,封装维度不高,不太好操作:对于flink任务提交后,集群任务的管理有点原生化和不太智能,例如在这里面,它是以yarn中的容器为粒度进行任务生命周期的管理的,这意味着: 当你以per-job部署模式构建任务时, 在Dlink中会生成一个容器(在Dlink中也会存储元信息,绑定你job启动的yarn容器的id),但当这个任务重启或者关闭后,还需要你自己手动去移除在Dlink中的信息,否则时间长了,将会遗留很多垃圾容器
其实Dlink已经很强大了,但我还是想要一个更“现代化”,可以最好以一个计算任务为主体,屏蔽底层细节,让操作的人可以不具备很多的底层前置知识,也可以完成一个任务的提交。
StreamX
铺垫了这么多,终于到了今天要重点描述的主角,在我找了很多实现之后,最终定在了这块开源软件的身上,WHY?
首先,它作为Gitee的GVP项目,参与开发维护的力量足够丰厚,因此迭代速度也是相当的快,陆续还依然在有大量的人在加入贡献,可以明显感受到这个项目的活跃度是非常高的,这里我主要挑出来我认为最重要的几点:
● 快捷的日常操作(任务启动、停止、savepoint,从savepoint恢复)
● Flink所有部署模式的支持(Remote/K8s-Native-Application/K8s-Native-Session/YARN-Application/YARN-Per-Job/YARN-Session)
● 项目配置和依赖版本化管理
● Flink SQL WebIDE
● 从任务开发阶段到部署管理全链路支持,对于计算任务,告别传统的打包,手动上传到集群的操作,可直接push到代码托管仓库,后续通过streamx勾勾点点就行
源码剖析
好的, 那么选中了streamx之后,也操作了一下它的整个对任务的配置提交流程,其实让我最好奇的还是,当一个SQL编写完毕,提交,任务启动,这中间到底发生了啥?
streamX由许多模块组成,其中,作为可视化web供用户点击操作的模块是:streamx-console
这个web模块就是一个springboot项目,因此,直接来到这个模块,找到对应提交任务的controller,最终定位到所在位置是:
com.streamxhub.streamx.console.core.controller.ApplicationController#start
启动任务接口
@PostMapping("start")
@RequiresPermissions("app:start")
public RestResponse start(Application app)
try
applicationService.checkEnv(app);
applicationService.starting(app);
applicationService.start(app, false);
return RestResponse.create().data(true);
catch (Exception e)
return RestResponse.create().data(false).message(e.getMessage());
我们要找的是它是如何在哪里把我们提交的SQL解析成Job的,那一定是在启动任务的时候操作的,因此我们深入追踪这里:
applicationService.start(app, false);
里面有一段逻辑值得注意:
提交任务类型判断
if (application.isCustomCodeJob())
if (application.isUploadJob())
appConf = String.format("json://\\"%s\\":\\"%s\\"",
ConfigConst.KEY_FLINK_APPLICATION_MAIN_CLASS(),
application.getMainClass()
);
else
switch (application.getApplicationType())
case STREAMX_FLINK:
String format = applicationConfig.getFormat() == 1 ? "yaml" : "prop";
appConf = String.format("%s://%s", format, applicationConfig.getContent());
break;
case APACHE_FLINK:
appConf = String.format("json://\\"%s\\":\\"%s\\"", ConfigConst.KEY_FLINK_APPLICATION_MAIN_CLASS(), application.getMainClass());
break;
default:
throw new IllegalArgumentException("[StreamX] ApplicationType must be (StreamX flink | Apache flink)... ");
if (executionMode.equals(ExecutionMode.YARN_APPLICATION))
switch (application.getApplicationType())
case STREAMX_FLINK:
flinkUserJar = String.format("%s/%s", application.getAppLib(), application.getModule().concat(".jar"));
break;
case APACHE_FLINK:
flinkUserJar = String.format("%s/%s", application.getAppHome(), application.getJar());
break;
default:
throw new IllegalArgumentException("[StreamX] ApplicationType must be (StreamX flink | Apache flink)... ");
//关注这里,如果是一个Flink-SQL类型的任务
else if (application.isFlinkSqlJob())
FlinkSql flinkSql = flinkSqlService.getEffective(application.getId(), false);
assert flinkSql != null;
//1) dist_userJar
String sqlDistJar = commonService.getSqlClientJar();
//2) appConfig
appConf = applicationConfig == null ? null : String.format("yaml://%s", applicationConfig.getContent());
//3) client
if (executionMode.equals(ExecutionMode.YARN_APPLICATION))
String clientPath = Workspace.remote().APP_CLIENT();
flinkUserJar = String.format("%s/%s", clientPath, sqlDistJar);
else
throw new UnsupportedOperationException("Unsupported...");
else if (application.isFlinkSqlJob())
这里我们可以看到,StreamX是在这里进行对提交任务的判断,那如果是一个Flink-SQL的任务,它做了什么:
//1) dist_userJar
String sqlDistJar = commonService.getSqlClientJar();
这是什么?我们知道,在我们正常手动往flink集群提交一个由code编写的flink job的时候,需要提交一个用户自定义编写code的jar包给flink集群,然后flink任务的Job Graph也是通过由这个用户自定义code的job中的main方法所去生成的,你会不会好奇:如果仅仅是一段SQL,我只是提交了一段SQL,也不会有什么jar包了,那这个Job Graph从哪里来的?好的,带着这个问题,我们去看,这个所谓的SqlClientJar到底是个啥:
@Override
public String getSqlClientJar()
if (sqlClientJar == null)
File localClient = WebUtils.getAppClientDir();
assert localClient.exists();
List<String> jars =
Arrays.stream(Objects.requireNonNull(localClient.list())).filter(x -> x.matches("streamx-flink-sqlclient-.*\\\\.jar"))
.collect(Collectors.toList());
if (jars.isEmpty())
throw new IllegalArgumentException("[StreamX] can no found streamx-flink-sqlclient jar in " + localClient);
if (jars.size() > 1)
throw new IllegalArgumentException("[StreamX] found multiple streamx-flink-sqlclient jar in " + localClient);
sqlClientJar = jars.get(0);
return sqlClientJar;
这里我们发现,他其实叫做streamx-flink-sqlclient的jar,这个jar包是啥?在哪? 我们会发现,这个是streamx在打包streamx-console项目的时候,会把这个jar打进去:
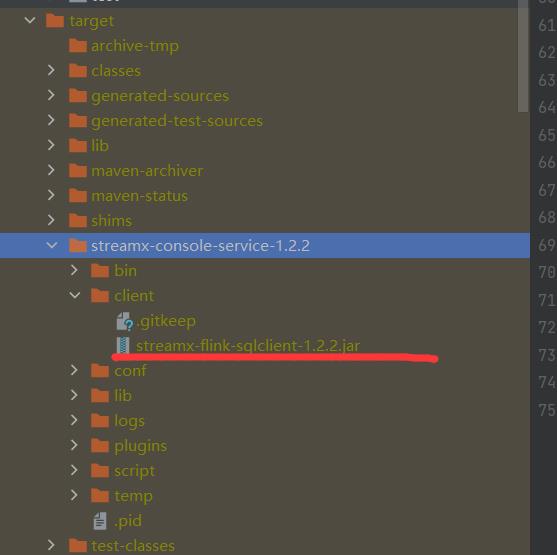
也就是说,在运行streamx-console时,这个jar肯定是拿的到的。
那还有个问题,这里面到底是啥东西? 我们来看一下streamx-flink-sqlclient的源码:
streamx-flink-sqlclient
它在源码中,处于streamx-plugin模块中,有一个streamx-flink-sqlclient:
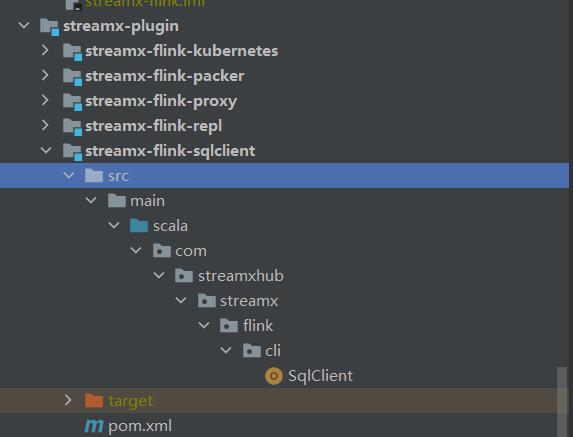
可以看到,只有一个SqlClient的Scala Object,看看写了啥:
object SqlClient extends FlinkStreamTable
override def handle(): Unit = context.sql()
implicit def callback(message: String): Unit =
println(message)
这个可能你得用过streamx才知道,它简化了一个job的code编写,关于一个job的环境设置与提交会被streamx的上下文调起,你只需要编写一个handle方法,在里边编写核心逻辑即可,因此只需要看这个handle做了啥,发现只写了一句: context.sql(),我们往里面跟,看看做了啥:
def sql(sql: String = null)(implicit callback: String => Unit = null): Unit = FlinkSqlExecutor.executeSql(sql, parameter, this)
private[streamx] def executeSql(sql: String, parameter: ParameterTool, context: TableEnvironment)(implicit callbackFunc: String => Unit = null): Unit =
val flinkSql: String = if (sql == null || sql.isEmpty) parameter.get(KEY_FLINK_SQL()) else parameter.get(sql)
val sqlEmptyError = SqlError(SqlErrorType.VERIFY_FAILED, "sql is empty", sql).toString
require(flinkSql != null && flinkSql.trim.nonEmpty, sqlEmptyError)
def callback(r: String): Unit =
callbackFunc match
case null => logInfo(r)
case x => x(r)
//TODO registerHiveCatalog
val insertArray = new ArrayBuffer[String]()
SqlCommandParser.parseSQL(flinkSql).foreach(x =>
val args = if (x.operands.isEmpty) null else x.operands.head
val command = x.command.name
x.command match
case USE =>
context.useDatabase(args)
logInfo(s"$command: $args")
case USE_CATALOG =>
context.useCatalog(args)
logInfo(s"$command: $args")
case SHOW_CATALOGS =>
val catalogs = context.listCatalogs
callback(s"$command: $catalogs.mkString("\\n")")
case SHOW_CURRENT_CATALOG =>
val catalog = context.getCurrentCatalog
callback(s"$command: $catalog")
case SHOW_DATABASES =>
val databases = context.listDatabases
callback(s"$command: $databases.mkString("\\n")")
case SHOW_CURRENT_DATABASE =>
val database = context.getCurrentDatabase
callback(s"$command: $database")
case SHOW_TABLES =>
val tables = context.listTables().filter(!_.startsWith("UnnamedTable"))
callback(s"$command: $tables.mkString("\\n")")
case SHOW_FUNCTIONS =>
val functions = context.listUserDefinedFunctions()
callback(s"$command: $functions.mkString("\\n")")
case SHOW_MODULES =>
val modules = context.listModules()
callback(s"$command: $modules.mkString("\\n")")
case SET =>
if (!tableConfigOptions.containsKey(args))
throw new IllegalArgumentException(s"$args is not a valid table/sql config, please check link: https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/table/config.html")
val operand = x.operands(1)
if (TableConfigOptions.TABLE_SQL_DIALECT.key().equalsIgnoreCase(args))
Try(SqlDialect.valueOf(operand.toUpperCase()))
.map(context.getConfig.setSqlDialect(_))
.getOrElse(throw new IllegalArgumentException(s"$operand is not a valid dialect"))
else
context.getConfig.getConfiguration.setString(args, operand)
logInfo(s"$command: $args --> $operand")
case RESET =>
val confDataField = classOf[Configuration].getDeclaredField("confData")
confDataField.setAccessible(true)
val confData = confDataField.get(context.getConfig.getConfiguration).asInstanceOf[util.HashMap[String, AnyRef]]
if (args.toUpperCase == "ALL")
confData.synchronized
confData.clear()
else
confData.synchronized
confData.remove(args)
logInfo(s"$command: $args")
case DESC | DESCRIBE =>
val schema = context.scan(args).getSchema
val builder = new StringBuilder()
builder.append("Column\\tType\\n")
for (i <- 0 to schema.getFieldCount)
builder.append(schema.getFieldName(i).get() + "\\t" + schema.getFieldDataType(i).get() + "\\n")
callback(builder.toString())
case EXPLAIN =>
val tableResult = context.executeSql(x.originSql)
val r = tableResult.collect().next().getField(0).toString
callback(r)
case INSERT_INTO | INSERT_OVERWRITE => insertArray += x.originSql
case SELECT =>
throw new Exception(s"[StreamX] Unsupported SELECT in current version.")
case INSERT_INTO | INSERT_OVERWRITE |
CREATE_FUNCTION | DROP_FUNCTION | ALTER_FUNCTION |
CREATE_CATALOG | DROP_CATALOG |
CREATE_TABLE | DROP_TABLE | ALTER_TABLE |
CREATE_VIEW | DROP_VIEW |
CREATE_DATABASE | DROP_DATABASE | ALTER_DATABASE =>
try
lock.lock()
val result = context.executeSql(x.originSql)
logInfo(s"$command:$args")
finally
if (lock.isHeldByCurrentThread)
lock.unlock()
case _ => throw new Exception(s"[StreamX] Unsupported command: $x.command")
)
if (insertArray.nonEmpty)
val statementSet = context.createStatementSet()
insertArray.foreach(statementSet.addInsertSql)
statementSet.execute() match
case t if t != null =>
Try(t.getJobClient.get.getJobID).getOrElse(null) match
case x if x != null => logInfo(s"jobId:$x")
case _ =>
case _ =>
logInfo(s"\\n\\n\\n==============flinkSql==============\\n\\n $flinkSql\\n\\n============================\\n\\n\\n")
看完上面的代码,我们大概了解到,这里面就是对flink sql字符串的拆分
以上是关于FlinkSQL平台化之路-StreamX提交源码剖析的主要内容,如果未能解决你的问题,请参考以下文章
Flink sql 之 TopN 与 StreamPhysicalRankRule (源码解析)
95-910-140-源码-FlinkSQL-FlinkSQL简介