Unicode ASCII UTF-8 GBK关系
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Unicode ASCII UTF-8 GBK关系相关的知识,希望对你有一定的参考价值。
参考技术A首先必须知道一个概念 - 字符集
计算机中的所有字符, 说到底都是用二进制的 0/1 排列组合来表示的, 因此就需要有一个规范来规定每个字符对应 0/1 排列组合, 这样的规范就是 字符集 .
Unicode, ASCII, GB2312, GBK 都是字符集. UTF-8不是!
最早的计算机在设计时采用 8 个 bit 作为一个字节 - byte, 所以, 一个字节能表示的范围就是 00000000 到 11111111, 也就是 0 到 255, 一共 256 种状态, 每一个状态对应一个符号, 可以表示 256 个符号.
美国有关的标准化组织就出台了 ASCII 编码, 对英语字符, 数字以及部分符号与二进制位之间的关系, 做了统一规定, 一共规定了 128 个字符的编码. 只占用了一个字节的后面 7 位, 最前面一位统一规定为 0, 一直沿用至今.
每个 ASCII 编码占用一个字节, 即 8 bit.
如果加上最前面一位, 即后 128 个最前面一位为 1 的编码, 被称为 扩展ASCII码 . 显示英语用 前 128 个符号编码就够了, 但是用来表示其他语言是不够的. 比如, 在法语中, 字母上方有注音符号, 它就无法用 ASCII 码表示. 于是, 一些欧洲国家就利用字节中闲置的最高位编入新的符号. 比如, 法语中的 é 的编码为 130(二进制10000010). 这样一来, 这些欧洲国家使用的编码体系, 可以表示最多 256 个符号.
但是中文怎么办?
如果要表示中文, 显然一个字节是不够的, 至少需要两个字节, 而且还不能和 ASCII 编码冲突, 所以, 中国制定了 GB2312 编码, 用来把中文编进去.
后来发现这 GB2312 还是不够用, 汉字实在是太多了, 于是国内程序员又对这个字符集进行了扩充, 总之最后扩充成了GBK标准, GBK 依旧使用两个字节表示一个汉字. GBK 是在 GB2312 基础上扩容后兼容 GB2312 的标准.
同理, 日文和韩文等其他语言也有这个问题. 为了统一所有文字的编码, Unicode 应运而生.
它为 每种语言中的每个字符设定了统一并且唯一的二进制编码, 能够使计算机实现跨语言、跨平台的文本转换及处理.
Unicode 与 ASCII 是兼容的, 通常用两个字节表示一个字符, 原有的英文编码从单字节变成双字节,只需要把高字节全部填为 0 就可以.
但是, 这里就有一个问题, 这些英文字母只需要一个字节就能存储, 现在用两个字节, 文件的体积就可能要扩大两倍. 这没办法接受!
因此,Unicode 有了各种各样的实现形式,最出名的是UTF-8
UTF-8 就是在互联网上使用最广的一种 Unicode 的 实现方式 .
UTF-8 最大的一个特点, 就是它是一种变长的编码方式. 它可以使用1~4个字节表示一个符号, 根据不同的符号而变化字节长度.
UTF-8 的编码规则:
举例:
python中,ascii,unicode,utf8,gbk之间的关系梳理
在计算机中,经常遇到编码问题,本节主要梳理下ascii,unicode,utf8,gbk 这几种编码之间的关系。
ASCII
计算机中,所有数据都以0和1来表示。在一开始的时候,要表示的内容比较少,人们使用了ascii编码的方式来编码。
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 -1 = 255,所以,ASCII码最多只能表示 255 个符号。
1 1 1 1 1 1 1 1 =2**0+2**1+2**2+2**3+2**4+2**5+2**6+2**7 = 2**8-1=255
Unicode,UTF-8,GBK
随着计算机的发展,显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。Unicode规定所有字符和符号最少使用2字节(16位)来表示,即2**16-1=65535
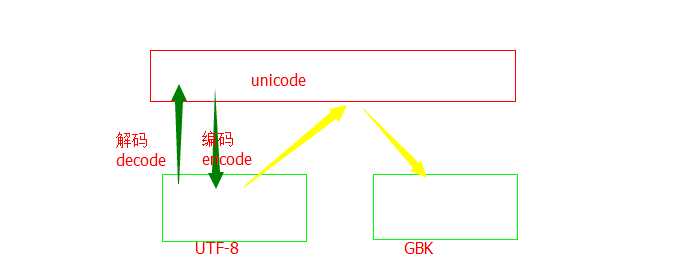
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
GBK,也是基于Unicode编码的进一步优化,GBK的文字编码是用双字节来表示的,即不论中、英文字符均使用双字节来表示
Unicode与UTF-8,GBK的关系,如图:
Python环境
在python2中, python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill)
所以,如果在文件中有中文时,ascii码将无法表示。因此,在.py 文件中,应该明确告诉python解释器,用什么编码来执行源代码,即:
#!/usr/bin/env python # -*- coding: utf-8 -*- print "你好,世界"
在python3中, python解释器,默认以Unicode对内容进行编码,所以不需指定编码格式即可表示中文。
以上是关于Unicode ASCII UTF-8 GBK关系的主要内容,如果未能解决你的问题,请参考以下文章
python中,ascii,unicode,utf8,gbk之间的关系梳理
ASCII,GBK,和Unicode的UTF-8,UTF-16,UTF-32阐述