6种方式创建多层索引MultiIndex
Posted 尤尔小屋的猫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了6种方式创建多层索引MultiIndex相关的知识,希望对你有一定的参考价值。
49_6种方式创建多层索引MultiIndex
公众号:尤而小屋
作者:Peter
编辑:Peter
大家好,我是Peter~
在上一篇文章中介绍了如何创建Pandas中的单层索引,今天给大家带来的是如何创建Pandas中的多层索引。
pd.MultiIndex,即具有多个层次的索引。通过多层次索引,我们就可以操作整个索引组的数据。本文主要介绍在Pandas中创建多层索引的6种方式:
- pd.MultiIndex.from_arrays():多维数组作为参数,高维指定高层索引,低维指定低层索引。
- pd.MultiIndex.from_tuples():元组的列表作为参数,每个元组指定每个索引(高维和低维索引)。
- pd.MultiIndex.from_product():一个可迭代对象的列表作为参数,根据多个可迭代对象元素的笛卡尔积(元素间的两两组合)进行创建索引。
- pd.MultiIndex.from_frame:根据现有的数据框来直接生成
- groupby():通过数据分组统计得到
- pivot_table():生成透视表的方式来得到

pd.MultiIndex.from_arrays()
In [1]:
import pandas as pd
import numpy as np
通过数组的方式来生成,通常指定的是列表中的元素:
In [2]:
# 列表元素是字符串和数字
array1 = [["xiaoming","guanyu","zhangfei"],
[22,25,27]
]
m1 = pd.MultiIndex.from_arrays(array1)
m1
Out[2]:
MultiIndex([('xiaoming', 22),
( 'guanyu', 25),
('zhangfei', 27)],
)
In [3]:
type(m1) # 查看数据类型
通过type函数来查看数据类型,发现的确是:MultiIndex
Out[3]:
pandas.core.indexes.multi.MultiIndex
在创建的同时可以指定每个层级的名字:
In [4]:
# 列表元素全是字符串
array2 = [["xiaoming","guanyu","zhangfei"],
["male","male","female"]
]
m2 = pd.MultiIndex.from_arrays(
array2,
# 指定姓名和性别
names=["name","sex"])
m2
Out[4]:
MultiIndex([('xiaoming', 'male'),
( 'guanyu', 'male'),
('zhangfei', 'female')],
names=['name', 'sex'])
下面的例子是生成3个层次的索引且指定名字:
In [5]:
array3 = [["xiaoming","guanyu","zhangfei"],
["male","male","female"],
[22,25,27]
]
m3 = pd.MultiIndex.from_arrays(
array3,
names=["姓名","性别","年龄"])
m3
Out[5]:
MultiIndex([('xiaoming', 'male', 22),
( 'guanyu', 'male', 25),
('zhangfei', 'female', 27)],
names=['姓名', '性别', '年龄'])
pd.MultiIndex.from_tuples()
通过元组的形式来生成多层索引:
In [6]:
# 元组的形式
array4 = (("xiaoming","guanyu","zhangfei"),
(22,25,27)
)
m4 = pd.MultiIndex.from_arrays(array4)
m4
Out[6]:
MultiIndex([('xiaoming', 22),
( 'guanyu', 25),
('zhangfei', 27)],
)
In [7]:
# 元组构成的3层索引
array5 = (("xiaoming","guanyu","zhangfei"),
("male","male","female"),
(22,25,27))
m5 = pd.MultiIndex.from_arrays(array5)
m5
Out[7]:
MultiIndex([('xiaoming', 'male', 22),
( 'guanyu', 'male', 25),
('zhangfei', 'female', 27)],
)
列表和元组是可以混合使用的:
- 最外层是列表
- 里面全部是元组
In [8]:
array6 = [("xiaoming","guanyu","zhangfei"),
("male","male","female"),
(18,35,27)
]
# 指定名字
m6 = pd.MultiIndex.from_arrays(array6,names=["姓名","性别","年龄"])
m6
Out[8]:
MultiIndex([('xiaoming', 'male', 18),
( 'guanyu', 'male', 35),
('zhangfei', 'female', 27)],
names=['姓名', '性别', '年龄'] # 指定名字
)
pd.MultiIndex.from_product()
使用可迭代对象的列表作为参数,根据多个可迭代对象元素的笛卡尔积(元素间的两两组合)进行创建索引。
在Python中,我们使用 isinstance()函数 判断python对象是否可迭代:
# 导入 collections 模块的 Iterable 对比对象
from collections import Iterable


通过上面的例子我们总结:常见的字符串、列表、集合、元组、字典都是可迭代对象
下面举例子来说明:
In [18]:
names = ["xiaoming","guanyu","zhangfei"]
numbers = [22,25]
m7 = pd.MultiIndex.from_product(
[names, numbers],
names=["name","number"]) # 指定名字
m7
Out[18]:
MultiIndex([('xiaoming', 22),
('xiaoming', 25),
( 'guanyu', 22),
( 'guanyu', 25),
('zhangfei', 22),
('zhangfei', 25)],
names=['name', 'number'])
In [19]:
# 需要展开成列表形式
strings = list("abc")
lists = [1,2]
m8 = pd.MultiIndex.from_product(
[strings, lists],
names=["alpha","number"])
m8
Out[19]:
MultiIndex([('a', 1),
('a', 2),
('b', 1),
('b', 2),
('c', 1),
('c', 2)],
names=['alpha', 'number'])
In [20]:
# 使用元组形式
strings = ("a","b","c")
lists = [1,2]
m9 = pd.MultiIndex.from_product(
[strings, lists],
names=["alpha","number"])
m9
Out[20]:
MultiIndex([('a', 1),
('a', 2),
('b', 1),
('b', 2),
('c', 1),
('c', 2)],
names=['alpha', 'number'])
In [21]:
# 使用range函数
strings = ("a","b","c") # 3个元素
lists = range(3) # 0,1,2 3个元素
m10 = pd.MultiIndex.from_product(
[strings, lists],
names=["alpha","number"])
m10
Out[21]:
MultiIndex([('a', 0),
('a', 1),
('a', 2),
('b', 0),
('b', 1),
('b', 2),
('c', 0),
('c', 1),
('c', 2)],
names=['alpha', 'number'])
In [22]:
# 使用range函数
strings = ("a","b","c")
list1 = range(3) # 0,1,2
list2 = ["x","y"]
m11 = pd.MultiIndex.from_product(
[strings, list1, list2],
names=["name","l1","l2"]
)
m11 # 总个数 3*3*2=18
总个数是``332=18`个:
Out[22]:
MultiIndex([('a', 0, 'x'),
('a', 0, 'y'),
('a', 1, 'x'),
('a', 1, 'y'),
('a', 2, 'x'),
('a', 2, 'y'),
('b', 0, 'x'),
('b', 0, 'y'),
('b', 1, 'x'),
('b', 1, 'y'),
('b', 2, 'x'),
('b', 2, 'y'),
('c', 0, 'x'),
('c', 0, 'y'),
('c', 1, 'x'),
('c', 1, 'y'),
('c', 2, 'x'),
('c', 2, 'y')],
names=['name', 'l1', 'l2'])
pd.MultiIndex.from_frame()
通过现有的DataFrame直接来生成多层索引:
df = pd.DataFrame("name":["xiaoming","guanyu","zhaoyun"],
"age":[23,39,34],
"sex":["male","male","female"])
df
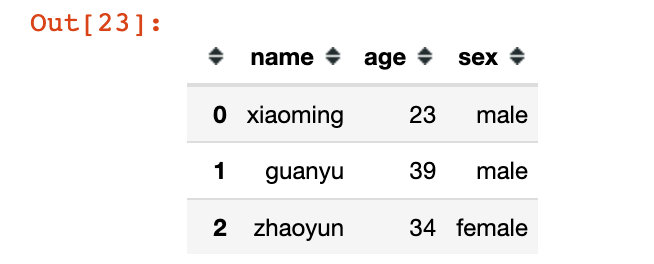
直接生成了多层索引,名字就是现有数据框的列字段:
In [24]:
pd.MultiIndex.from_frame(df)
Out[24]:
MultiIndex([('xiaoming', 23, 'male'),
( 'guanyu', 39, 'male'),
( 'zhaoyun', 34, 'female')],
names=['name', 'age', 'sex'])
通过names参数来指定名字:
In [25]:
# 可以自定义名字
pd.MultiIndex.from_frame(df,names=["col1","col2","col3"])
Out[25]:
MultiIndex([('xiaoming', 23, 'male'),
( 'guanyu', 39, 'male'),
( 'zhaoyun', 34, 'female')],
names=['col1', 'col2', 'col3'])
groupby()
通过groupby函数的分组功能计算得到:
In [26]:
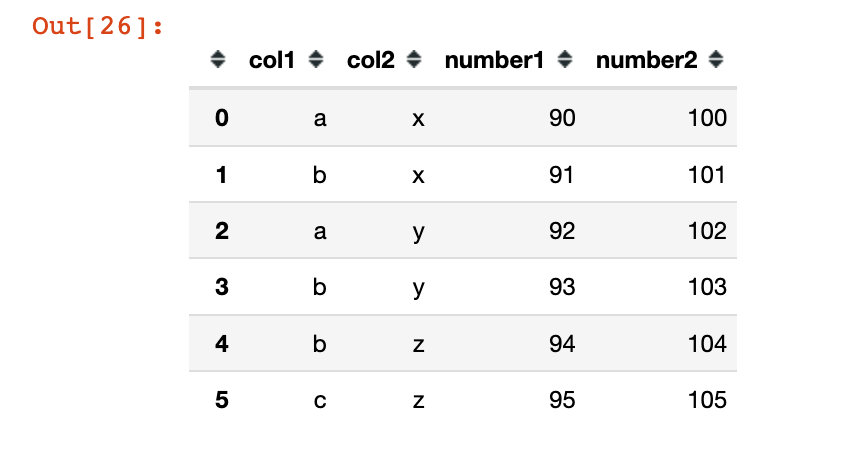
df1 = pd.DataFrame("col1":list("ababbc"),
"col2":list("xxyyzz"),
"number1":range(90,96),
"number2":range(100,106))
df1
Out[26]:
df2 = df1.groupby(["col1","col2"]).agg("number1":sum,
"number2":np.mean)
df2

查看数据的索引:
In [28]:
df2.index
Out[28]:
MultiIndex([('a', 'x'),
('a', 'y'),
('b', 'x'),
('b', 'y'),
('b', 'z'),
('c', 'z')],
names=['col1', 'col2'])
pivot_table()
通过数据透视功能得到:
In [29]:
df3 = df1.pivot_table(values=["col1","col2"],index=["col1","col2"])
df3
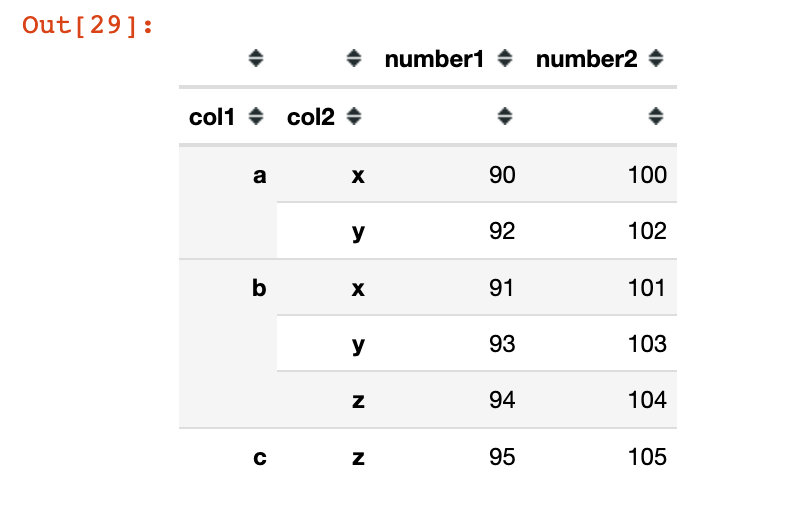
In [30]:
df3.index
Out[30]:
MultiIndex([('a', 'x'),
('a', 'y'),
('b', 'x'),
('b', 'y'),
('b', 'z'),
('c', 'z')],
names=['col1', 'col2'])
以上是关于6种方式创建多层索引MultiIndex的主要内容,如果未能解决你的问题,请参考以下文章