大数据学习路线 学习笔记 Day2
Posted Z.S.D
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据学习路线 学习笔记 Day2相关的知识,希望对你有一定的参考价值。
一、python基础语法
变量、基本数据类型、类型之间的转换、运算符、选择结构、循环结构、数据容器、函数、类、异常处理
首先了解下注释:
# 单行注释
'''
多行注释
多行注释
'''二、变量
变量命名规则:
1.必须是大小写字母,数字以及下划线_组成
2.不能以数字开头
3.不能是关键字(保留字):在某一门语言中有特殊含义或功能的“字符串”
有哪些关键字?
打印关键字
import keyword
print(keyword.kwlist)4.命名原则:通俗易懂,见名思义,遵循写法
python中定义变量只需要取名字,不用注明类型,可自动推断
查看变量类型:
# 打印数据类型
i=1
n=1.1
print(type(i),type(n))python同样可以指定类型,但是python本身是一门动态数据类型的语言,虽然制定了类型但不会真正对代码进行限制
三、基本数据类型
四大基本数据类型:整型int、浮点类型float、字符串str、布尔类型bool
# 数据类型
i=100
f=-1.2554
str1="asfff"
str2='safgfe'
# python中也可以用单引号括起来表示字符串,在其他语言中一般表示字符
bool1=True
bool2=False
print(i,f,str1,str2,bool1,bool2)
print(type(i),type(f),type(str1),type(str2),type(bool1),type(bool2))
print('''
a
b
c''') #成对的三个单引号(双引号)''' '''/""" """ 表示一次打印多行字符串 无需换行符\\n字符串的常见用法
str='python,java,scala,sql'
# 倒转字符串
print(str[::-1]) #切片
# 切片一般用于提取数据容器中的一部分元素
# 切片完整的形式需要三个参数: 起始位置:结束位置:步长
# 默认值:起始位置默认从头开始,结束位置默认最后的位置,步长默认为1
# 提取Java
print(str[7:11:1]) #左闭右开[开始,结束) 故结束位置+1
# 指定字符进行切分
print(str.split(','))
print(type(str.split(','))) #列表类型
print(str.upper())#字符串大写
print(str.index('java'))#查找字符串出现的位置split:切分字符串
startswith:判断字符串是不是以某个字符开头,返回布尔值
endswith:判断字符串是不是以某个字符结尾,返回布尔值
upper、lower:转大小写
replace:替换字符串
strip:去除字符串左右两边的隐藏字符
count:统计某字符串出现的次数
index:查找字符串出现的位置
title :转换成标题写法,即首字母大写
转义字符用法
\\ 转义字符,有特殊意义=>无特殊意义 无特殊意义=>有特殊意义
print("I'm \\"fine\\".")
print("I'm\\\\ \\"fine\\".")
print("I'm\\ \\"fine\\".")
# \\\\ 与 \\ 打印出来一样,字符\\本身也要转义,所以\\\\表示的字符就是\\
print("a\\\\t b\\\\n") #将有意义的\\n \\t 转义为无意义
print(r'a\\t b\\n') #引号前加r 表示后面就是完整的字符串,不需要再在字符串内部进行转义运行结果:

格式化字符串
1. %形式格式化
user='张三'
year=2023
month=3
day=21
hour=20
minutes=38
seconds=30
percent='80%'
print('''尊贵的%s用户,
截至到%d年%d月%d日%d时%d分%d秒,
您当前流量已使用%s''' % (user,year,month,day,hour,minutes,seconds,percent))
# %s 字符串占位符,可通用
user='张三'
year=2023
month=3
day=21
hour=20
minutes=38
seconds=35.612
percent=80.1554438
print('''尊贵的%s用户,
截至到%d年%02d月%d日%d时%d分%f秒,
您当前流量已使用%06.2f%%''' % (user,year,month,day,hour,minutes,seconds,percent))
# %s 字符串占位符,可通用
# %2d月表示月前面两位整型,%02d月表示月前面两位,不够用0补齐
# %% 在格式转换符之后表示一个%
# %f 为浮点型占位符,默认保留6位小数。
# %a.bf表示保留b位小数,全部位数为a位,a<b则等同于未设置a,a>b且a足够大时
#前面需用空格补齐位数(前面加0,用0补齐)2. format方法实现字符串格式化(三个方法)
user='张三'
year=2023
month=3
day=21
hour=20
minutes=38
seconds=35.612
percent=80.1554438
print('''尊贵的0用户,
截至到1年2月3日4时5分6秒,
您当前流量已使用7:5.2f%'''.format(user,year,month,day,hour,minutes,seconds,percent))
# 用format方法实现字符串格式化 方法一
user='张三'
year=2023
month=3
day=21
hour=20
minutes=38
seconds=35.612
percent=80.1554438
print(f'''尊贵的user用户,
截至到year年month月day日hour时minutes分seconds秒,
您当前流量已使用percent:5.2f%''')
# 用format方法实现字符串格式化 方法二 '''后加f等同于format方法
user='张三'
year=2023
month=3
day=21
hour=20
minutes=38
seconds=35.612
percent=80.1554438
print('''尊贵的u用户,
截至到y年m月d日h时min分s秒,
您当前流量已使用p:8.2f%'''.format(y=year,m=month,d=day,min=minutes,p=percent,u=user,h=hour,s=seconds))
# 用format方法实现字符串格式化 方法三
#变量名匹配套用format方法,优点在于变量名顺序可以随意调整
大数据学习路线 学习笔记 Day5
大数据学习路线 学习笔记 Day5
一、数据容器
list列表、tuple元组、dict字典、set集合
1. list 列表
list列表是一种有序的集合,可以随时添加和删除其中的元素。list列表中的每个值都有对应的位置值,称之为索引index,第一个索引是 0,第二个索引是 1,依此类推。
list的特点:有序,可变,元素类型不要求统一,元素可以重复
# 定义一个list,并查看类型,列表用 [ ] 定义
list1=[1,2,5,3,1,'abc',1.1,False]
print(list1)
print(type(list1))
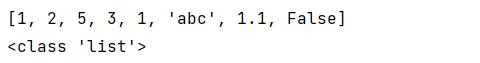
列表内元素可以重复,也可以不是同一种数据类型
list1=[1,2,5,3,1,'abc',1.1,False]
# 有序的证明:如果可以通过索引(下标index)提取容器中的元素则证明它是有序的
print(list1[0])
print(list1[4])
print(list1[7])
print(list1[-2])#python支持负数索引,表示从右往左数第几个

通过 list[下标值] 可以提取容器中的元素,这也证明了list列表是有序的数据容器。python支持负数索引,表示从右往左数第几个。
但是,当输入的下标值超出范围时,就会报错。
list1=[1,2,5,3,1,'abc',1.1,False]
print(list1[8])

报错!!! 错误原因:下标超出范围,即越界!!!
list列表常用操作
如索引、 切片、增加、删除、修改、查询元素等
定义一个list用变量classmates接收,保存了班里同学的名字 classmates = [‘James’, ‘Kobe’, ‘Polo’]
list列表自带了很多方法可以进行调用
列表增删操作示例:
# 定义一个list用变量classmates接收,保存了班里同学的名字
classmates=['James','Kobe','Polo']
# 增
classmates.append(('Irving'))
print(classmates) #append方法在列表内添加元素,直接添加到末尾
classmates.insert(2,'Joedan')
print(classmates) #insert方法通过指定下标,在准确位置插入元素
# 删
classmates.remove('James')
print(classmates) #remove方法指定元素进行移除
classmates.pop(0)
print(classmates) #pop方法通过指定下标,移除指定元素
del classmates[0]
print(classmates) #del关键字也可指定下标移除元素

注意:列表list的这些方法是作用在列表本身上的,方法的返回值为空值 ,例如:
classmates=['James','Kobe','Polo']
classmates.append(('Irving'))
print(classmates.append(('Irving')))
print(classmates)
# append方法是在列表本身内部添加元素,改变的是classmates列表本身。直接print,返回值为None
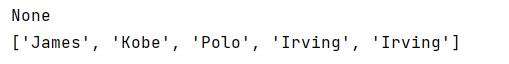
列表查改操作示例:
list1=[1,10,3,5,4,7,9,1,6,7,1,12,1]
# 查
print(list1.index(6)) #index方法查找指定元素的下标值,查询位置
print(list1.count(1)) #count方法查找指定值出现的次数
print(len(list1)) #用len函数可以查询列表的长度,即下标的最大值
# 改
list1.sort()
print(list1) #sort方法将原列表从小到大排序
list1.reverse()
print(list1) #reverse方法将原列表中的元素反转
list1[0]=20
print(list1) #通过指定下标值直接修改某个元素
list1.clear()
print(list1) #clear方法清空列表

注意:查操作可以直接print出来,因为没有改变列表本身,其返回值就是找到的量
补充:两个列表合并的方法:
# extend 拓展list
l1 = [1, 2, 3, 4]
l2 = [2, 3, 4, 5, 6]
print(l1)
print(l2)
l1.extend(l2)
print(l1)
# 两个list直接相加
l3 = [1, 2, 3, 4, 5]
l4 = [2, 3, 4, 5, 6]
l5 = l3 + l4
print(l3)
print(l4)
print(l5)

切片操作
list2=[1,2,3,4,5,6,7,8]
print(list2)
print(list2[0:7:1]) #左闭右开[开始,结束),故下标为7的数字8没有打印出来
print(type(list2[0:7:1])) #切片返回的也是一个列表
print(list2[::])
'''起始位置、结束位置、步长都可以省略,如省略则等于默认值。
默认值:起始位置默认从头开始,结束位置默认最后的位置,步长默认为1'''
print(list2[::-1]) #将列表从尾部往前逐一输出,最后得到列表顺序颠倒的效果
print(list2[::2]) #步长为2,即间隔一个输出一个
print(list2) #切片操作返回新的列表,没有改变原列表

切片一般用于提取数据容器中的一部分元素 ,切片操作需要提供起始索引位置和最后索引位置,然后用冒号 : 将两者分开,切片操作返回一系列从起始索引位置开始到最后索引位置结束的列表。
注意:结果包含起始位置的值,但不包含结束位置的值
起始位置、结束位置、步长都可以省略,如省略则等于默认值
切片操作同样适用于:字符串、元组中,以及后续numpy、pandas中的数据结构

2.tuple元组
tuple元组是一种可以使得代码更安全,防止错误赋值导致重要对象的改变的数据容器。
特点:不可变,有序,元素类型不要求统一,元素可以重复
与列表list的唯一区别就在于元组是不可变的!!!!!元组一般用于数据传入和接收过程中不可修改的场景。
#定义一个元组,并打印类型,元组用 ( ) 定义
classmates = ('James', 'Kobe', 'Polo')
print(classmates)
print(type(classmates))

由于元组是不可变的,因此元组对象没有 append()、insert()和del这样的方法,tuple元组自带的方法相对来说就很少了。
tuple中就两个方法:index、count同list类似
classmates = ('James', 'Kobe', 'Polo')
# 通过下标取元素
print(classmates[1])
# 元组的 index 方法,查询指定元素下标
print(classmates.index('Polo'))
# 元组的 count 方法,查询指定元素数量
print(classmates.count('Polo'))
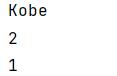
因为元组不能修改 ,所以不能进行赋值操作
classmates = ('James', 'Kobe', 'Polo')
classmates[1]='Mike'

报错!!错误原因:元组类型不支持赋值操作。
如何创建只有一个元素的元组?
# 创建只有一个元素的元组时,不能使用()
tuple1 = (1)
print(tuple1, type(tuple1)) # 1 <class 'int'>
tuple2 = (1,)
print(tuple2, type(tuple2))
tuple3 = tuple([1]) # 需要通过list传递元素 构建元组
print(tuple3, type(tuple3))

创建只有一个元素的元组时,不能直接使用 ( ) ,可以使用 ( 元素,)的形式,或者使用列表传递元素。
再补充一个关于列表list的知识点:列表生成式
列表生成式,是一种Python内置,非常简单却强大,可以通过表达式推导来生成一个list列表的方式,又名列表推导式。
我们如何生成[1 * 1, 2 * 2, 3 * 3, …, 10 * 10]的一个列表?
方法一:使用循环语句
# 列表生成式
# 方法一:循环
list=[]
for i in range(1,11):
list.append('*'.format(i,i))
print(list)
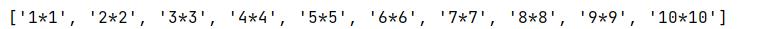
方法二:使用列表推导式,一行代码即可代替循环生成上面的list。
写列表生成式时,把要生成的元素x * x放到前面,后面跟for循环,就可以把list创建出来。
# 方法二:列表推导式
print(['*'.format(i,i) for i in range(1,11)])
for循环后面还可以加上if判断,例如仅将偶数筛选出来:
还可以使用两层循环,例如生成ABC和XYZ中全部字母的排列组合:
print(['*'.format(i,i) for i in range(1,11) if i%2==0])
print([m+n for m in 'ABC' for n in 'XYZ'])

关于列表推导式的详细示例可以看我的另一篇博客:
用Python一行代码打印九九乘法表
以上是关于大数据学习路线 学习笔记 Day2的主要内容,如果未能解决你的问题,请参考以下文章