Pandas统计分析基础:DataFrame的数据分析及画图功能(case:京津冀地区的gdp和人口的关系)
Posted Xlong~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pandas统计分析基础:DataFrame的数据分析及画图功能(case:京津冀地区的gdp和人口的关系)相关的知识,希望对你有一定的参考价值。
✅作者简介:大家好我是Xlong,一枚正在学习COMSOL、Python的工科研究僧
📃个人主页: Xlong的个人博客主页
🔥系列专栏: Python大数据分析
💖如果觉得博主的文章还不错的话,请👍支持一下博主哦🤞
在上篇文章中主要介绍了DataFrame中元素的增、删、改、查等基本功能,本篇文章主要是DataFrame的数据分析及画图功能的介绍。
目录
1.1.读取output.xlsx文件中的sheet1 (gdp数据)
一、DataFrame的数据分析功能
用上篇文章中导出的数据文件(output.xlsx)进行演示
1.1.读取output.xlsx文件中的sheet1 (gdp数据)
import pandas as pd
excelFile = r'output.xlsx'
df = pd.DataFrame(pd.read_excel(excelFile,sheet_name=0,index_col=0))#index_col=0,,可以去掉没意义的第一列标号和unnamed:0
print(df)运行结果:
北京市 天津市 河北省 ... 青海省 宁夏回族自治区 新疆维吾尔自治区
2018年 30319.98 18809.64 36010.27 ... 2865.23 3705.18 12199.08
2017年 28014.94 18549.19 34016.32 ... 2624.83 3443.56 10881.96
2016年 25669.13 17885.39 32070.45 ... 2572.49 3168.59 9649.70
2015年 23014.59 16538.19 29806.11 ... 2417.05 2911.77 9324.80
2014年 21330.83 15726.93 29421.15 ... 2303.32 2752.10 9273.46
2013年 19800.81 14442.01 28442.95 ... 2122.06 2577.57 8443.84
2012年 17879.40 12893.88 26575.01 ... 1893.54 2341.29 7505.31
2011年 16251.93 11307.28 24515.76 ... 1670.44 2102.21 6610.05
2010年 14113.58 9224.46 20394.26 ... 1350.43 1689.65 5437.47
2009年 12153.03 7521.85 17235.48 ... 1081.27 1353.31 4277.05
2008年 11115.00 6719.01 16011.97 ... 1018.62 1203.92 4183.21
2007年 9846.81 5252.76 13607.32 ... 797.35 919.11 3523.16
2006年 8117.78 4462.74 11467.60 ... 648.50 725.90 3045.26
2005年 6969.52 3905.64 10012.11 ... 543.32 612.61 2604.19
2004年 6033.21 3110.97 8477.63 ... 466.10 537.11 2209.09
2003年 5007.21 2578.03 6921.29 ... 390.20 445.36 1886.35
2002年 4315.00 2150.76 6018.28 ... 340.65 377.16 1612.65
2001年 3707.96 1919.09 5516.76 ... 300.13 337.44 1491.60
2000年 3161.66 1701.88 5043.96 ... 263.68 295.02 1363.56[19 rows x 31 columns]
1.2 求每个地区的gdp平均值
import pandas as pd
excelFile = r'output.xlsx'
df = pd.DataFrame(pd.read_excel(excelFile,sheet_name=0,index_col=0))#index_col=0,,可以去掉没意义的第一列标号和unnamed:0
print(df.mean(numeric_only=None))#是针对每一列去操作运行结果:
北京市 14043.282632
天津市 9194.721053
河北省 19029.720000
山西省 8346.071579
内蒙古自治区 10004.022105
辽宁省 16118.040000
吉林省 8209.141579
黑龙江省 9662.531579
上海市 16340.200000
江苏省 41224.622632
浙江省 26604.160526
安徽省 12867.220526
福建省 15273.601579
江西省 9665.197895
山东省 37637.603158
河南省 22333.658421
湖北省 16681.162632
湖南省 16340.998947
广东省 45022.102632
广西壮族自治区 9521.931053
海南省 2149.985789
重庆市 8715.997895
四川省 17668.912632
贵州省 5597.343684
云南省 7890.748947
西藏自治区 582.042105
陕西省 10341.775789
甘肃省 4085.462105
青海省 1351.011053
宁夏回族自治区 1657.834737
新疆维吾尔自治区 5553.778421
dtype: float64
1.3 每年全国总体gdp
import pandas as pd
excelFile = r'output.xlsx'
df = pd.DataFrame(pd.read_excel(excelFile,sheet_name=0,index_col=0))#index_col=0,,可以去掉没意义的第一列标号和unnamed:0
print(df.sum(axis=1) ) #通过修改axis参数,可以使之对每一行作用运行结果:
2018年 914707.46
2017年 847140.10
2016年 780069.97
2015年 722767.87
2014年 684349.42
2013年 634345.33
2012年 576551.84
2011年 521441.11
2010年 437041.99
2009年 365303.69
2008年 333313.95
2007年 279737.86
2006年 232836.74
2005年 199228.10
2004年 167922.56
2003年 139537.19
2002年 120819.30
2001年 108775.71
2000年 98692.60
dtype: float64
1.4 快速查看每列数据的统计信息
import pandas as pd
excelFile = r'output.xlsx'
df = pd.DataFrame(pd.read_excel(excelFile,sheet_name=0,index_col=0))#index_col=0,,可以去掉没意义的第一列标号和unnamed:0
print(df.describe())运行结果:
北京市 天津市 ... 宁夏回族自治区 新疆维吾尔自治区
count 19.000000 19.000000 ... 19.000000 19.000000
mean 14043.282632 9194.721053 ... 1657.834737 5553.778421
std 8699.383871 6289.667859 ... 1171.810868 3555.326670
min 3161.660000 1701.880000 ... 295.020000 1363.560000
25% 6501.365000 3508.305000 ... 574.860000 2406.640000
50% 12153.030000 7521.850000 ... 1353.310000 4277.050000
75% 20565.820000 15084.470000 ... 2664.835000 8858.650000
max 30319.980000 18809.640000 ... 3705.180000 12199.080000[8 rows x 31 columns]
import pandas as pd
excelFile = r'output.xlsx'
df = pd.DataFrame(pd.read_excel(excelFile,sheet_name=0,index_col=0))#index_col=0,,可以去掉没意义的第一列标号和unnamed:0
print(df.T.describe()) #注意,describe()功能不支持换轴运行结果:
2018年 2017年 ... 2001年 2000年
count 31.000000 31.000000 ... 31.000000 31.000000
mean 29506.692258 27327.100000 ... 3508.893871 3183.632258
std 23905.147349 22186.906272 ... 2839.736508 2556.305244
min 1477.630000 1310.920000 ... 139.160000 117.800000
25% 15718.120000 15236.475000 ... 1816.450000 1620.500000
50% 21984.780000 20006.310000 ... 2279.340000 2080.040000
75% 36218.025000 33959.640000 ... 4663.285000 4298.630000
max 97277.770000 89705.230000 ... 12039.250000 10741.250000[8 rows x 19 columns]
二、 利用DataFrame画图
由于DataFrame天然是用来处理多组同类数据的,因此在绘制多组数据对比的柱状图、折线图、散点图等时均比用ndarray作为输入数据画图更为高效。
Case:京津冀地区的gdp和人口的关系
import pandas as pd
excelFile = r'output.xlsx'
df = pd.DataFrame(pd.read_excel(excelFile,sheet_name=0,index_col=0))#index_col=0,,可以去掉没意义的第一列标号和unnamed:0
JJJgdp = df[['北京市','天津市','河北省']]
print(JJJgdp,'\\n') #注意,describe()功能不支持换轴
dp = pd.DataFrame(pd.read_excel(excelFile,sheet_name=1,index_col=0))#index_col=0,,可以去掉没意义的第一列标号和unnamed:0
JJJpop = dp[['北京市','天津市','河北省']]
print(JJJpop)运行结果:
北京市 天津市 河北省
2018年 30319.98 18809.64 36010.27
2017年 28014.94 18549.19 34016.32
2016年 25669.13 17885.39 32070.45
2015年 23014.59 16538.19 29806.11
2014年 21330.83 15726.93 29421.15
2013年 19800.81 14442.01 28442.95
2012年 17879.40 12893.88 26575.01
2011年 16251.93 11307.28 24515.76
2010年 14113.58 9224.46 20394.26
2009年 12153.03 7521.85 17235.48
2008年 11115.00 6719.01 16011.97
2007年 9846.81 5252.76 13607.32
2006年 8117.78 4462.74 11467.60
2005年 6969.52 3905.64 10012.11
2004年 6033.21 3110.97 8477.63
2003年 5007.21 2578.03 6921.29
2002年 4315.00 2150.76 6018.28
2001年 3707.96 1919.09 5516.76
2000年 3161.66 1701.88 5043.96
北京市 天津市 河北省
2018年 2154 1560 7556
2017年 2171 1557 7520
2016年 2173 1562 7470
2015年 2171 1547 7425
2014年 2152 1517 7384
2013年 2115 1472 7333
2012年 2069 1413 7288
2011年 2019 1355 7241
2010年 1962 1299 7194
2009年 1860 1228 7034
2008年 1771 1176 6989
2007年 1676 1115 6943
2006年 1601 1075 6898
2005年 1538 1043 6851
2004年 1493 1024 6809
2003年 1456 1011 6769
2002年 1423 1007 6735
2001年 1385 1004 6699
2000年 1364 1001 6674
2.1 折线图
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
excelFile = r'output.xlsx'
df = pd.DataFrame(pd.read_excel(excelFile,sheet_name=0,index_col=0))#index_col=0,,可以去掉没意义的第一列标号和unnamed:0
JJJgdp = df[['北京市','天津市','河北省']]
dp = pd.DataFrame(pd.read_excel(excelFile,sheet_name=1,index_col=0))#index_col=0,,可以去掉没意义的第一列标号和unnamed:0
JJJpop = dp[['北京市','天津市','河北省']]
fig_JJJ,ax_JJJ=plt.subplots()
#ax_jjj.cla()
JJJgdp.plot(ax=ax_JJJ,style='--o')
#df.plot()画图时,可以将已有的子图赋值给其ax属性,这样画图就会画到已有的子图里,便于后续修改
plt.rcParams['font.sans-serif']=['SimHei'] #图中字体改为黑体以兼容中文
plt.rcParams['axes.unicode_minus']=False #负号显示的问题
plt.show()运行结果:
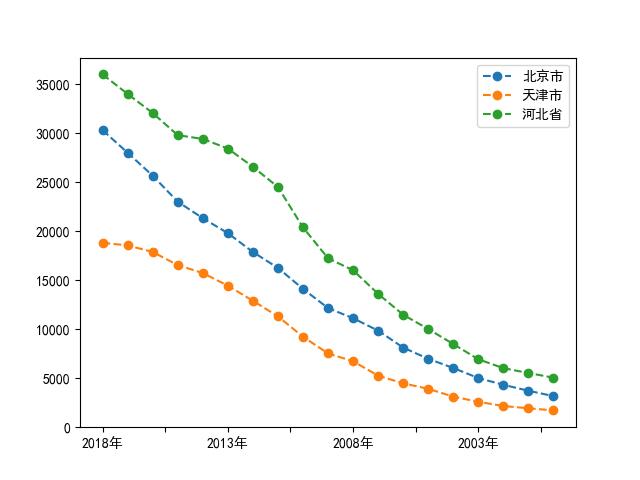
DataFrame在画图时,默认是以每一列为一个分类,index为横轴,数值为纵轴
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
excelFile = r'output.xlsx'
df = pd.DataFrame(pd.read_excel(excelFile,sheet_name=0,index_col=0))#index_col=0,,可以去掉没意义的第一列标号和unnamed:0
JJJgdp = df[['北京市','天津市','河北省']]
dp = pd.DataFrame(pd.read_excel(excelFile,sheet_name=1,index_col=0))#index_col=0,,可以去掉没意义的第一列标号和unnamed:0
JJJpop = dp[['北京市','天津市','河北省']]
fig_JJJ,ax_JJJ=plt.subplots()
#ax_JJJ.cla()
JJJgdp.plot(ax=ax_JJJ,style='--o')
#df.plot()画图时,可以将已有的子图赋值给其ax属性,这样画图就会画到已有的子图里,便于后续修改
plt.rcParams['font.sans-serif']=['SimHei'] #图中字体改为黑体以兼容中文
plt.rcParams['axes.unicode_minus']=False #负号显示的问题
ax_JJJ.set_xlabel('年份')
ax_JJJ.set_ylabel('GDP')
ax_JJJ.set_xticks(np.arange(0,20,1))
plt.show()
fig_JJJ.savefig('line.jpg', bbox_inches = 'tight')#保存图片
运行结果:
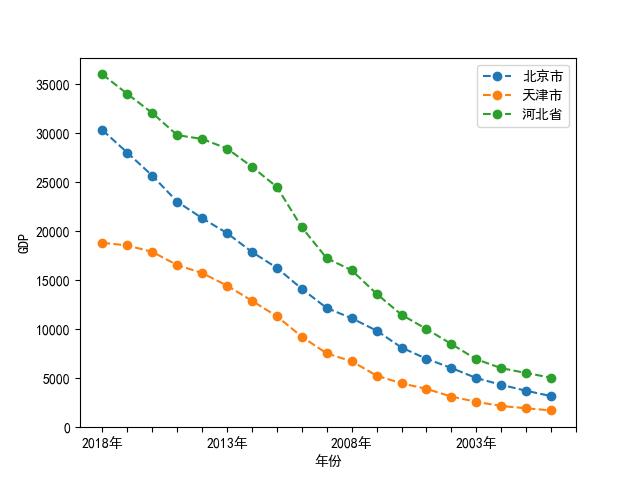
2.2 柱状图
绘制分类的柱状图,可以避免像之前那样设置柱的宽度了
import pandas as pd
import matplotlib.pyplot as plt
excelFile = r'output.xlsx'
df = pd.DataFrame(pd.read_excel(excelFile,sheet_name=0,index_col=0))#index_col=0,,可以去掉没意义的第一列标号和unnamed:0
JJJgdp = df[['北京市','天津市','河北省']]
dp = pd.DataFrame(pd.read_excel(excelFile,sheet_name=1,index_col=0))#index_col=0,,可以去掉没意义的第一列标号和unnamed:0
JJJpop = dp[['北京市','天津市','河北省']]
fig_bar1,ax_bar1=plt.subplots()
JJJgdp.plot.bar(ax=ax_bar1)
plt.rcParams['font.sans-serif']=['SimHei'] #图中字体改为黑体以兼容中文
plt.rcParams['axes.unicode_minus']=False #负号显示的问题
plt.show()运行结果:
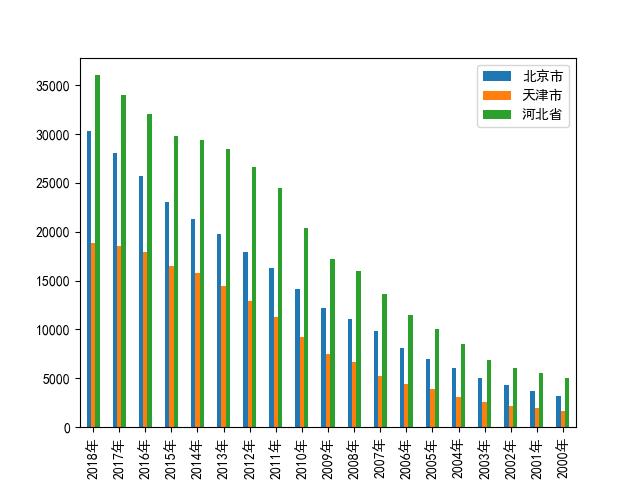
fig_bar1.savefig('bar1.jpg', bbox_inches = 'tight')#保存上图,名为‘bar1.jpg’.import pandas as pd
import matplotlib.pyplot as plt
excelFile = r'output.xlsx'
df = pd.DataFrame(pd.read_excel(excelFile,sheet_name=0,index_col=0))#index_col=0,,可以去掉没意义的第一列标号和unnamed:0
JJJgdp = df[['北京市','天津市','河北省']]
dp = pd.DataFrame(pd.read_excel(excelFile,sheet_name=1,index_col=0))#index_col=0,,可以去掉没意义的第一列标号和unnamed:0
JJJpop = dp[['北京市','天津市','河北省']]
plt.rcParams['font.sans-serif']=['SimHei'] #图中字体改为黑体以兼容中文
plt.rcParams['axes.unicode_minus']=False #负号显示的问题
fig_bar2,ax_bar2=plt.subplots()
JJJgdp.plot.barh(ax=ax_bar2) #barh的h即把方向调到horizon,横向
plt.show()运行结果:
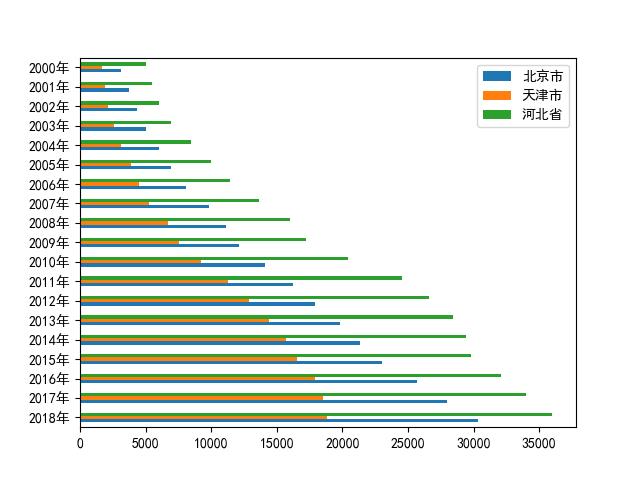
fig_bar2.savefig('bar2.jpg', bbox_inches = 'tight')#保存图片
还可以把每一类都各自画到一个独立的子图里,省的挤在一起。例如:画出三个省分开的图

import pandas as pd
import matplotlib.pyplot as plt
excelFile = r'output.xlsx'
df = pd.DataFrame(pd.read_excel(excelFile,sheet_name=0,index_col=0))#index_col=0,,可以去掉没意义的第一列标号和unnamed:0
JJJgdp = df[['北京市','天津市','河北省']]
dp = pd.DataFrame(pd.read_excel(excelFile,sheet_name=1,index_col=0))#index_col=0,,可以去掉没意义的第一列标号和unnamed:0
JJJpop = dp[['北京市','天津市','河北省']]
plt.rcParams['font.sans-serif']=['SimHei'] #图中字体改为黑体以兼容中文
plt.rcParams['axes.unicode_minus']=False #负号显示的问题
fig_bar3,ax_bar3=plt.subplots(3,1)
#JJJgdp.plot.bar(ax=ax_bar3,subplots=True) #subplots=True可以把每一列作为一个子图分开画
#JJJgdp.plot.bar(ax=ax_bar3,subplots=True,sharex=True) #sharex=True 可以让这3个纵向排列的图共用一个横轴
JJJgdp.plot.bar(ax=ax_bar3,subplots=True,sharex=True,title=['','','']) #title可以给三个子图加标题,加空标题即可起到去掉标题的作用
ax_bar3[1].set_ylabel('GDP (亿元)') #每个子图都可以做进一步修改
plt.show()运行结果:
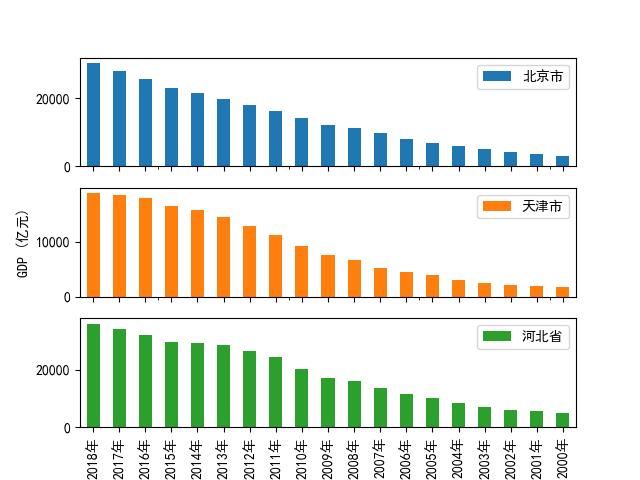
fig_bar3.savefig('bar3.jpg', bbox_inches = 'tight')#保存图片以上就是《Pandas统计分析基础(4):DataFrame的数据分析及画图功能》,如果有改进的建议,欢迎在评论区留言交流~
持续更新中......原创不易,各位看官请随手点下Follow和Star,感谢!!!
以上是关于Pandas统计分析基础:DataFrame的数据分析及画图功能(case:京津冀地区的gdp和人口的关系)的主要内容,如果未能解决你的问题,请参考以下文章