解密GaussDB(for Influx)时序洞察
Posted 华为云开发者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解密GaussDB(for Influx)时序洞察相关的知识,希望对你有一定的参考价值。
本文分享自华为云社区《华为云GaussDB(for Influx)揭秘第三期:解密GaussDB(for Influx)时序洞察》,作者: 高斯Influx官方博客。
背景
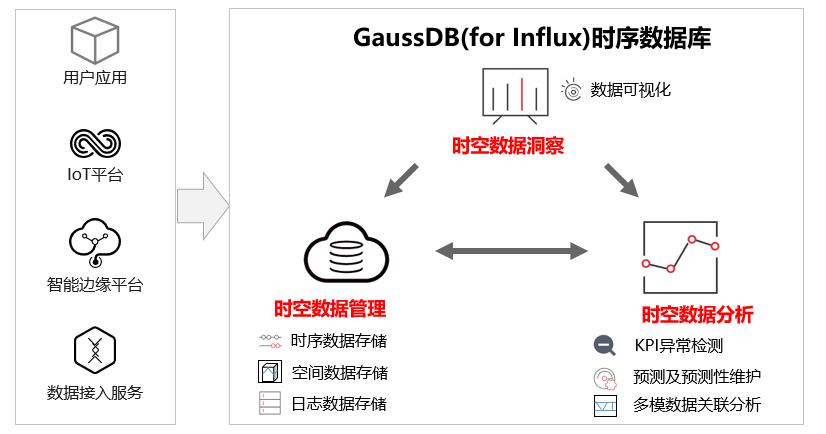
GaussDB(for Influx)是一款基于华为自研的计算存储分离架构,兼容InfluxDB生态的云原生NoSQL时序数据库,提供一站式时序数据存储,分析,展示功能。其中时序洞察提供了针对时序数据的可视化功能。
在监控领域,我们经常见到绚丽的监控大屏,实时反映整个系统运行情况,就是监控看板功能。通过监控看板,可以高效的运用监控数据辅助定位故障、性能调优、容量规划;可以查看各产品的监控数据走势及对比;可以跨产品展示关键指标的实时数据、历史数据和整体走势。业务人员可以根据该信息对业务进行及时调整。
监控看板系统的特点和挑战
看板功能极大的提升了业务的分析和运维的效率,包括可视化的展示多个监控指标的走势,展示多个设备某一监控指标的聚合数据;跨设备展示关键指标,掌握不同设备之间关键指标的对比和变化;可自定义设置数据样式,数据自动刷新等等。比如下图是对于服务器的监控包括,虚拟机的内存、CPU、磁盘、IO等指标进行可视化展示:

在使用过程中存在以下几个痛点:
查询并发大
随着物联网,车联网,数据中心等规模不断扩大,需要监控的指标数据量迅速增长,业务的运维和监控压力不断增大;有时候一个看板需要整面墙来展示,需要同时展示上千指标的实时变化情况。而每次看板上指标的更新背后就是对数据库进行一次查询;以华为云监控为例,华为云目前提供了200+的各种服务,每个服务都有上万个实例需要监控;比如数据库服务,就有近10万个实例需要监控;每个实例都会监控多个指标信息,例如CPU,内存,磁盘使用率,磁盘读写IO,网络出口流量,入口流量,TCP链接等基本信息,还有包括TPS,QPS,缓存命中率,主从延迟,慢查询,锁状态,链接数,读写延迟,读写并发等数据库特有的信息,总计有50多个基础指标需要监控。因此华为云监控业务当前基础的服务需要每次查询超过20000个查询语句,这些查询每分钟下发一次;
传统的zabbix,prometheus,druid等监控工具已经无法满足业务的需求,其多数只有单机版部署能力,处理能力和扩展能力有限。
查询时延要求低
在运维监控场景下,需要实时关注业务的变化情况,因此看板的刷新频次一般是秒级,这就要求所有的查询必须在秒级甚至毫秒级内完成,由于监控数据量庞大,时间线数量多,加之查询并发大,如何满足查询时延的要求,是时序数据库共同面临的一个技术挑战。
而现有产品大多数在批量查询场景下,查询延迟大;例如开源版的InfluxDB针对批量的查询,在内部也是串行执行的,这样总体的查询返回时间基本上在秒级别以上。OpenTSDB只有在rowkey上有索引,在多维查找时只能scan,延迟非常高。
GaussDB(for Influx)在监控看板中的优势
在云计算,物联网,车联网等大规模业务场景下,监控系统不仅仅只是反馈当前业务状态,还要提供故障预测,告警预测,性能调优,资源容量规划,自动化运维等高级功能;业界也涌现出一些专门针对时序数据进行存储,分析和展示的产品;当前大多数自建监控看板的实现是基于prometheus和Grafana等不同开源组件来搭建,而GaussDB(for Influx)提供数据存储、分析、可视化一站式功能。
GaussDB(for Influx)通过实现Hint查询,rollupcache,批量查询优化等功能。有效降低了查询时延。下面是针对几种常见查询和企业版influxdb的时延对比。
预设数据为:
| 时间线 | 数据量 | 导入前数据大小-G |
|---|---|---|
| 250万 | 151亿 | 337.5 |
时延对比:
| 查询模型 | 具体查询语句 |
|---|---|
| query1 | select * from sensor where f=‘f1’ and d=‘d2’ and s=‘s1’ and time>=1514768400000000000 and time<=1514772000000000000 |
| query2 | select * from sensor where f=‘f1’ and s=‘d2’ and value>=3.0 and time>=1514768400000000000 and time<1514854800000000000 |
| query3 | select mean(value) from sensor where f=‘f1’ and s=‘s1’ and time>=1514768400000000000 and time<=1514854800000000000 group by f,d,s,time(1h) |
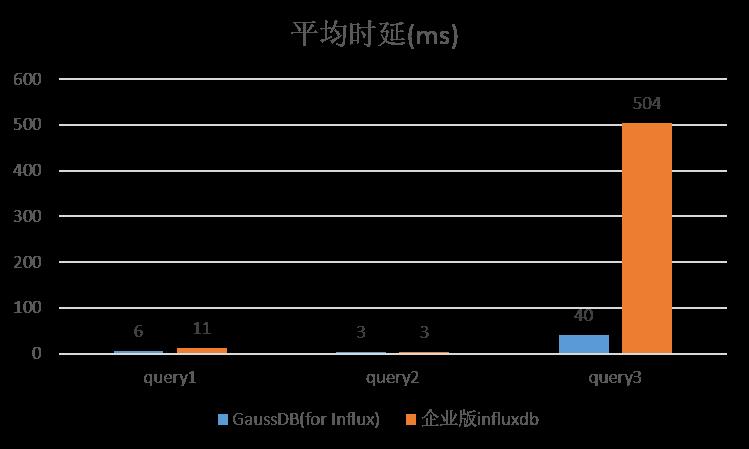
如图所示,在常见的查询模型中GaussDB(for Influx)查询时延明显优于企业版的influxdb,特别是在带有聚合算子的查询中时延只有企业版influxdb的十分之一。接下来详细介绍下Gaussdb(for Influx)针对看板场景所做的具体优化工作。
Hint查询方式
GaussDB(for Influx)内部支持倒排索引,大部分监控场景的查询性能和效率得到了很大的提升。但是在大批量查询的场景下,还是无法实现毫秒级的查询性能要求。查询语句按照涉及的时间线可以分为单时间线查询和多时间线查询;单时间线查询是指,查询条件可以唯一确认一个时间线的查询;在看板场景中经常会用这类查询,比如查询某台设备的CPU指标。针对单时间线数据查询,GaussDB(for Influx)设计了Hint功能。
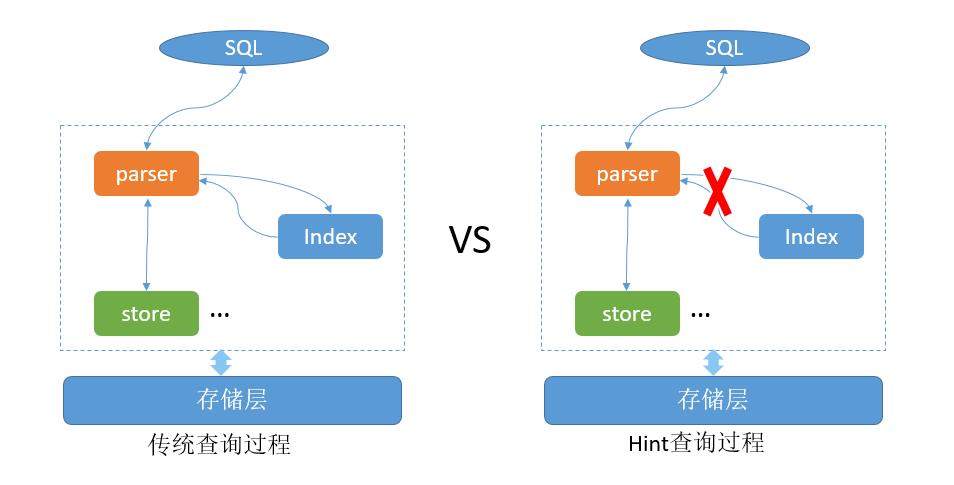
常规的查询都是解析查询语句后,通过倒排索引的功能查找到具体的数据分布位置,再依据这些信息去store层读取具体的数据,而GaussDB(for Influx)的Hint功能允许客户在执行单时间线查询时不用通过倒排索引去查找,而是直接能获取到具体数据的分布位置,从而直接去store层读取数据,这一功能大大降低查询的时延。
下图为hint查询和非hint查询的时延对比,测试条件为:300万时间线,单时间线查询;执行查询1000次平均时延。

图中明显可以看出,在单时间线查询场景下,hint查询时延明显优于非hint查询。
rollupcache
在监控看板业务场景下,每次数据更新时下发的都是同样的查询语句,只是时间上的差异。
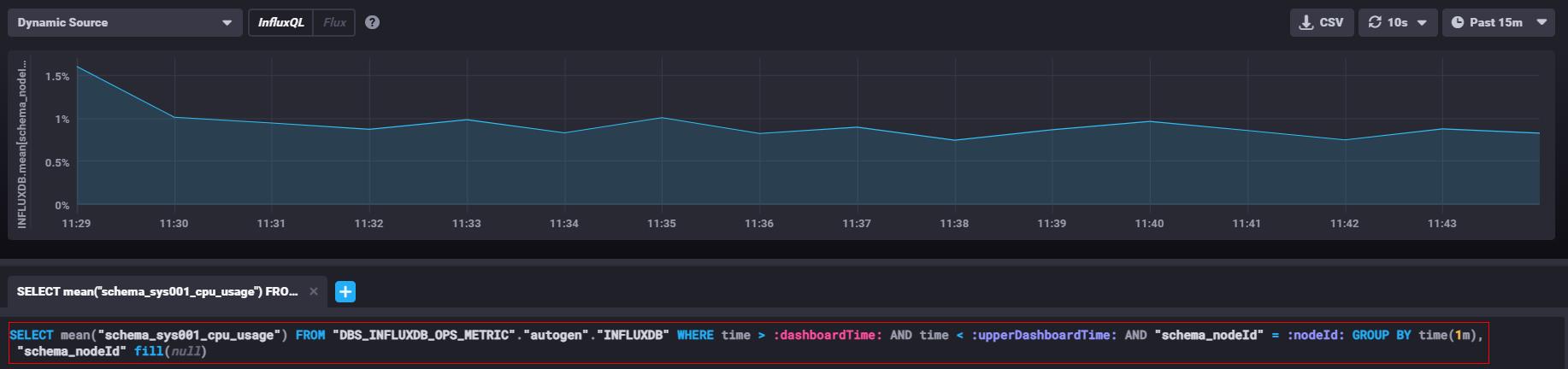
例如上图展示的一个监控CPU指标的看板,每次刷新时间为10s,每次展示15分钟的数据,假设第一次查询时间是15:00:00 ~ 15:15:00之间的数据,等到10s刷新之后,第二次下发的查询时间为15:00:10 ~ 15:15:10 之间的数据。可以发现,其实看板每次下发的查询数据,90%以上都是重复数据,因此GuassDB(for Influx)实现了rollupcache功能。
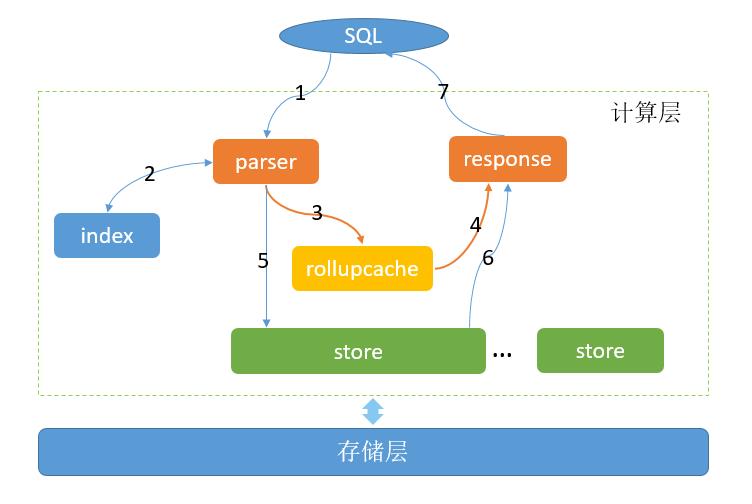
1.接受查询SQL;
2.查找对应的索引;
3.如果rollupcache中有存储数据,则直接从rollupcache中读取;
4.从rollupcache中返回数据;
5.如果rollupcache中没有,或者只有部分数据,缺少的数据从store中读取;
6.从store获取数据;
7.结果返回给客户。
rollupcache功能会缓存之前的查询结果,新的查询执行时,会优先判断是否命中缓存结果,如果全部命中,则直接返回;如果部分命中,则对未命中部分进行常规查询,将结果返回;如果完全没有命中,则等同于常规执行。这种直接使用缓存数据的方式极大的提高了查询的性能,特别适合于监控看板这种查询语句几乎不变的场景。
针对常用的聚合算子,在300万时间线数量下,执行1000次查询,rollupcache功能和非rollupcache功能的查询平均时延对比如下图:

从上图可以看出rollupcache功能将时延降低了10倍左右。
批量查询优化
很多场景下用户业务需要下发大量查询语句,在一些开源产品中并不支持批量查询,或者只是部分支持。比如,在开源的InfluxDB中,支持批量发送查询语句,但是在数据库内部,却是串行处理这些批量发送过来的查询请求,导致批量查询的性能没有真正释放出来。
GuassDB(for Influx)提供了针对批量查询的并发查询能力,每个batch所包含的查询语句在内核中可以并发执行。同时提供了相关参数,可以控制查询的并发量,可以根据业务的具体场景和机器资源进行调整,既满足了业务的查询性能,也不会因为查询占用过多资源影响其他业务。
使用GaussDB(for Influx)时序洞察功能
如何快速开通看板功能,可参考GaussDB(for Influx)的时序洞察部分:
时序洞察_云数据库 GaussDB NoSQL _GaussDB(for Influx)_用户指南_华为云
开通后就可以使用看板功能了。
创建看板
GaussDB(for Influx)支持的时序洞察功能操作非常便捷,点击Dashboards中的Create Dashboard按钮就可以创建一个空的看板。

创建成功后,点击Add Data就可以创建需要关注的指标了。
添加自定义指标
点击Add Data后,会跳转到如下图所示的界面:

图表上显示的数据是依据业务设置的查询语句返回的数据,查询语句支持InfluxQL和Flux。例如上图中CPU的指标对应的查询语句。
SELECT mean("schema_sys001_cpu_usage") FROM "DBS_INFLUXDB_OPS_METRIC"."autogen"."INFLUXDB" WHERE time > :dashboardTime: AND time < :upperDashboardTime: AND "schema_nodeId" = :nodeId: GROUP BY time(1m), "schema_nodeId" fill(null)
也可以将多个数值放在同一个图表中进行对比,查询语句的写法可参考下图:

SELECT mean("usage_system") AS "system", mean("usage_user") AS "user", mean("usage_idle") AS "idle" FROM "telegraf"."autogen"."cpu" WHERE time > :dashboardTime: AND time < :upperDashboardTime: AND "cpu"='cpu-total' AND "host"='ecs-c8ad-xie' GROUP BY time(:interval:) FILL(null)
也可以通过group by 语句分开,例如可以分别观察CPU0和CPU-total的指标,如下图:
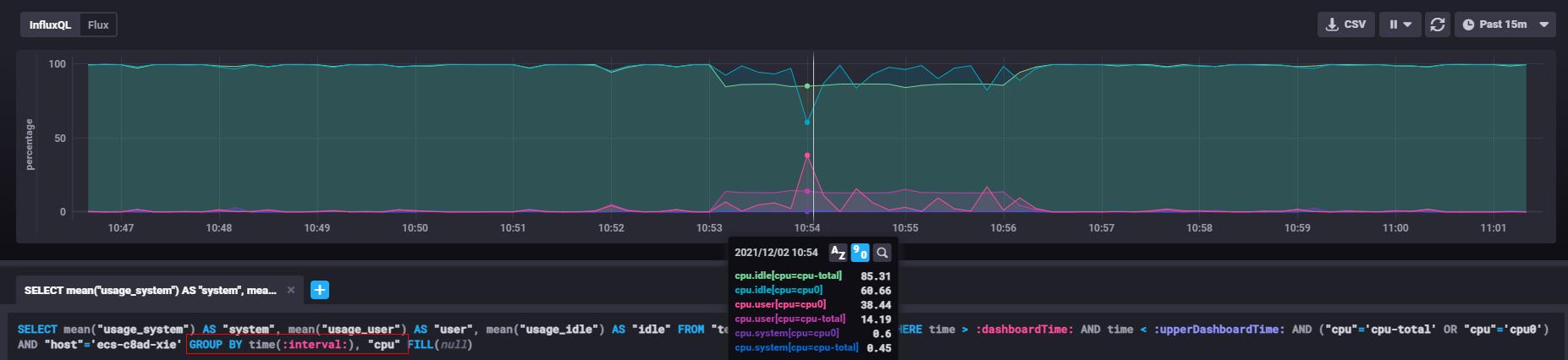
SELECT mean("usage_system") AS "system", mean("usage_user") AS "user", mean("usage_idle") AS "idle" FROM "telegraf"."autogen"."cpu" WHERE time > :dashboardTime: AND time < :upperDashboardTime: AND ("cpu"='cpu-total' OR "cpu"='cpu0') AND "host"='ecs-c8ad-xie' GROUP BY time(:interval:), "cpu" FILL(null)
其核心在于查询语句的写法。
也可以进行展示图形的设置,选择下图中Visualization按钮,就可以看到如下界面:

可以选择设置数据展示类型,调整图形的颜色,例如可以把图形设置成Step-Plot方式,如下图:

设置完成后点击右上角保存就可以在看板中看到了,如下图的CPU Usage就是我们上面步骤添加的指标项:

其他功能
GaussDB(for Influx)的时序洞察还支持,权限管理、分析任务管理、告警管理,指标预测等功能。
总结
GaussDB(for Influx)是一款基于计算存储分离架构,兼容InfluxDB生态的云原生时序数据库。在云计算平台高性能,高可靠,高安全,可弹性伸缩的基础上,提供时序数据的存储、分析、展示功能,同时具有高写入性能、灵活扩容、高压缩率和高查询性能等特点。
同时GaussDB(forInflux)通过实现Hint功能,rollupcache功能,以及并发查询的能力,有效的降低了大批量查询的时延,满足了大规模监控看板的业务需求。
本文作者:华为 云数据库创新Lab & 华为云时空数据库团队
以上是关于解密GaussDB(for Influx)时序洞察的主要内容,如果未能解决你的问题,请参考以下文章
云数据库 GaussDB(for Influx) 解密第十一期:让智能电网中时序数据处理更高效
解读华为云GaussDB(for Influx):最佳实践之数据建模