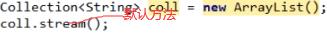Stream Collectors.groupingBy的四种用法 解决分组统计(计数求和平均数等)范围统计分组合并分组结果自定义映射等问题
Posted 涝山道士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Stream Collectors.groupingBy的四种用法 解决分组统计(计数求和平均数等)范围统计分组合并分组结果自定义映射等问题相关的知识,希望对你有一定的参考价值。
目录
前言
近期,由于业务需要,会统计一些简单的页面指标,如果每个统计都通过SQL实现的话,又略感枯燥乏味。于是选择使用Stream的分组功能。对于这些简单的统计指标来说,Stream的分组更为灵活,只需要提取出需要统计的数据,便可以对这些数据进行任意处理,而无需再次编写不同的SQL去统计不同的指标。
此文主要是总结我在此前的工作中使用到的Collectors.groupingBy的一些方法和技巧。根据平时使用的习惯,将Collectors.groupingBy的功能大致分为四种,但这种界定都是模糊的,并不是绝对,每种功能都可以穿插使用,这里只是更方便了解Collectors.groupingBy各个方法的使用规则。
四种分组功能如下:
- 基础分组功能
- 分组统计功能
- 分组合并功能
- 分组自定义映射功能
Stream的其它用法可以参考下文:
语法说明
基础语法
Collector<T, ?, Map<K, List<T>>> groupingBy(Function<? super T, ? extends K> classifier)
Collector<T, ?, Map<K, D>> groupingBy(Function<? super T, ? extends K> classifier, Collector<? super T, A, D> downstream)
Collector<T, ?, M> groupingBy(Function<? super T, ? extends K> classifier, Supplier<M> mapFactory, Collector<? super T, A, D> downstream)
- classifier:键映射:该方法的返回值是键值对的 键
- mapFactory:无参构造函数提供返回类型:提供一个容器初始化方法,用于创建新的 Map容器 (使用该容器存放值对)。
- downstream:值映射:通过聚合方法将同键下的结果聚合为指定类型,该方法返回的是键值对的 值。
前置数据
List<Student> students = Stream.of(
Student.builder().name("小张").age(16).clazz("高一1班").course("历史").score(88).build(),
Student.builder().name("小李").age(16).clazz("高一3班").course("数学").score(12).build(),
Student.builder().name("小王").age(17).clazz("高二1班").course("地理").score(44).build(),
Student.builder().name("小红").age(18).clazz("高二1班").course("物理").score(67).build(),
Student.builder().name("李华").age(15).clazz("高二2班").course("数学").score(99).build(),
Student.builder().name("小潘").age(19).clazz("高三4班").course("英语").score(100).build(),
Student.builder().name("小聂").age(20).clazz("高三4班").course("物理").score(32).build()
).collect(Collectors.toList());
分组的4种使用方法
1. 基础分组功能
说明:基础功能,分组并返回Map容器。将用户自定义的元素作为键,同时将键相同的元素存放在List中作为值。
Collectors.groupingBy:基础分组功能
下面的写法都是等价的
// 将不同课程的学生进行分类
Map<String, List<Student>> groupByCourse = students.stream().collect(Collectors.groupingBy(Student::getCourse));
Map<String, List<Student>> groupByCourse1 = students.stream().collect(Collectors.groupingBy(Student::getCourse, Collectors.toList()));
// 上面的方法中容器类型和值类型都是默认指定的,容器类型为:HashMap,值类型为:ArrayList
// 可以通过下面的方法自定义返回结果、值的类型
Map<String, List<Student>> groupByCourse2 = students.stream()
.collect(Collectors.groupingBy(Student::getCourse, HashMap::new, Collectors.toList()));
-
键类型、容器类型、值类型都可以进行自定义,一般来说键值类型都可以根据需要自定义结果,而容器类型则只能设置为Map(M extends Map<K, D>)的子类。
-
容器类型只能设置为Map类型,一般可以根据Map实现类的不同特性选择合适的容器:Hashmap LinkedHashMap ConcurrentHashMap WeakHashMap TreeMap Hashtable等等。
-
如需要保证students分组后的有序性的话,那么可以自定义容器类型为LinkedHashMap。
Collectors.groupingBy:自定义键——字段映射
一般而言,我们都是对一批Java对象进行分组,根据需求我们可能会选择其中的一个或多个字段,也可能会根据一些字段格式化操作,以此生成键。
例如:
- 身份证、手机号、ID
- 年份、月份、指定格式的日期
- 多个ID组合
- 日期 + 类型属性
- ……
// 字段映射 分组显示每个课程的学生信息
Map<String, List<Student>> filedKey = students.stream().collect(Collectors.groupingBy(Student::getCourse));
// 组合字段 分组现实每个班不同课程的学生信息
Map<String, List<Student>> combineFiledKey = students.stream().collect(Collectors.groupingBy(student -> student.getClazz() + "#" + student.getCourse()));
Collectors.groupingBy:自定义键——范围
有时候除了根据指定字段外,我们还需要根据对不同区间内的数据设置不同的键,区别于字段,这种范围类型的键多数情况下都是通过比较来生成的,常用于统计指标。
例如:
- 对是否有某种属性、类型进行统计
- 统计多个区间内的人数、比例
// 根据两级范围 将学生划分及格不及格两类
Map<Boolean, List<Student>> customRangeKey = students.stream().collect(Collectors.groupingBy(student -> student.getScore() > 60));
// 根据多级范围 根据学生成绩来评分
Map<String, List<Student>> customMultiRangeKey = students.stream().collect(Collectors.groupingBy(student ->
if (student.getScore() < 60)
return "C";
else if (student.getScore() < 80)
return "B";
return "A";
));
后文剩下的三个功能点其作用都是自定义值的类型,它们都基于第三个参数:Collector<? super T, A, D> downstream。它们都是通过实现Collector接口来实现各种downstream操作,从而完成值的自定义设置。
2. 分组统计功能
说明:分组后,对同一分组内的元素进行计算:计数、平均值、求和、最大最小值、范围内数据统计。
Collectors.counting:计数
计数语法:
Collector<T, ?, Long> counting()
// 计数
Map<String, Long> groupCount = students.stream()
.collect(Collectors.groupingBy(Student::getCourse, Collectors.counting()));
Collectors.summingInt:求和
求和语法:
Collector<T, ?, Integer> summingInt(ToIntFunction<? super T> mapper)
Collector<T, ?, Long> summingLong(ToLongFunction<? super T> mapper)
Collector<T, ?, Double> summingDouble(ToDoubleFunction<? super T> mapper)
求和针对流中元素类型的不同,分别提供了三种计算方式:Int、Double、Long。计算方式与计算结果必须与元素类型匹配。
// 求和
Map<String, Integer> groupSum = students.stream()
.collect(Collectors.groupingBy(Student::getCourse, Collectors.summingInt(Student::getScore)));
Collectors.averagingInt:平均值
平均值语法:
Collector<T, ?, Double> averagingInt(ToIntFunction<? super T> mapper)
Collector<T, ?, Double> averagingLong(ToLongFunction<? super T> mapper)
Collector<T, ?, Double> averagingDouble(ToDoubleFunction<? super T> mapper)
平均值计算关注点:
- 平均值有三种计算方式:Int、Double、Long。
- 计算方式仅对计算结果的精度有影响。
- 计算结果始终返回Double。
// 增加平均值计算
Map<String, Double> groupAverage = students.stream()
.collect(Collectors.groupingBy(Student::getCourse, Collectors.averagingInt(Student::getScore)));
Collectors.minBy:最大最小值
最大最少值语法:
Collector<T, ?, Optional<T>> minBy(Comparator<? super T> comparator)
Collector<T, ?, Optional<T>> maxBy(Comparator<? super T> comparator)
Collectors.collectingAndThen语法:
Collector<T,A,RR> collectingAndThen(Collector<T,A,R> downstream, Function<R,RR> finisher)
- Function<R,RR>:提供参数类型为R,返回结果类型为RR。
Collectors.minBy方法返回的类型为Optional<T>>,在取数据时还需要校验Optional是否为空。
不过这一步可以通过Collectors.collectingAndThen方法实现,并返回校验结果。Collectors.collectingAndThen的作用便是在使用聚合函数之后,对聚合函数的结果进行再加工。
// 同组最小值
Map<String, Optional<Student>> groupMin = students.stream()
.collect(Collectors.groupingBy(Student::getCourse,Collectors.minBy(Comparator.comparing(Student::getCourse))));
// 使用Collectors.collectingAndThen方法,处理Optional类型的数据
Map<String, Student> groupMin2 = students.stream()
.collect(Collectors.groupingBy(Student::getCourse,
Collectors.collectingAndThen(Collectors.minBy(Comparator.comparing(Student::getCourse)), op ->op.orElse(null))));
// 同组最大值
Map<String, Optional<Student>> groupMax = students.stream()
.collect(Collectors.groupingBy(Student::getCourse,Collectors.maxBy(Comparator.comparing(Student::getCourse))));
Collectors.summarizingInt:完整统计(同时获取以上的全部统计结果)
完整统计语法:
Collector<T, ?, IntSummaryStatistics> summarizingInt(ToIntFunction<? super T> mapper)
Collector<T, ?, LongSummaryStatistics> summarizingLong(ToLongFunction<? super T> mapper)
Collector<T, ?, DoubleSummaryStatistics> summarizingDouble(ToDoubleFunction<? super T> mapper)
统计方法提供了三种计算方式:Int、Double、Long。它会将输入元素转为上述三种计算方式的基本类型,然后进行计算。Collectors.summarizingXXX方法可以计算一般统计所需的所有结果。
无法向下转型,即Long无法转Int等。
返回结果取决于用的哪种计算方式。
// 统计方法同时统计同组的最大值、最小值、计数、求和、平均数信息
HashMap<String, IntSummaryStatistics> groupStat = students.stream()
.collect(Collectors.groupingBy(Student::getCourse, HashMap::new,Collectors.summarizingInt(Student::getScore)));
groupStat.forEach((k, v) ->
// 返回结果取决于用的哪种计算方式
v.getAverage();
v.getCount();
v.getMax();
v.getMin();
v.getSum();
);
Collectors.partitioningBy:范围统计
Collectors.partitioningBy语法:
Collector<T, ?, Map<Boolean, D>> partitioningBy(Predicate<? super T> predicate)
Collector<T, ?, Map<Boolean, D>> partitioningBy(Predicate<? super T> predicate, Collector<? super T, A, D> downstream)
- predicate:条件参数,对分组的结果划分为两个范围。
上面的统计都是基于某个指标项的。如果我们需要统计范围,比如:得分大于、小于60分的人的信息,那么我们可以通过Collectors.partitioningBy方法对映射结果进一步切分
// 切分结果,同时统计大于60和小于60分的人的信息
Map<String, Map<Boolean, List<Student>>> groupPartition = students.stream()
.collect(Collectors.groupingBy(Student::getCourse, Collectors.partitioningBy(s -> s.getScore() > 60)));
// 同样的,我们还可以对上面两个分组的人数数据进行统计
Map<String, Map<Boolean, Long>> groupPartitionCount = students.stream()
.collect(Collectors.groupingBy(Student::getCourse, Collectors.partitioningBy(s -> s.getScore() > 60, Collectors.counting())));
Collectors.partitioningBy仅支持将数据划分为两个范围进行统计,如果需要划分多个,可以嵌套Collectors.partitioningBy执行,不过需要在执行完后,手动处理不需要的数据。也可以在第一次Collectors.partitioningBy获取结果后,再分别对该结果进行范围统计。
Map<String, Map<Boolean, Map<Boolean, List<Student>>>> groupAngPartitionCount = students.stream()
.collect(Collectors.groupingBy(Student::getCourse, Collectors.partitioningBy(s -> s.getScore() > 60,
Collectors.partitioningBy(s -> s.getScore() > 90))));
3. 分组合并功能
说明:将同一个键下的值,通过不同的方法最后合并为一条数据。
Collectors.reducing:合并分组结果
Collectors.reducing语法:
Collector<T, ?, Optional> reducing(BinaryOperator op)
Collector<T, ?, T> reducing(T identity, BinaryOperator op)
Collector<T, ?, U> reducing(U identity, Function<? super T, ? extends U> mapper, BinaryOperator op)
- identity:合并标识值(因子),它将参与累加函数和合并函数的运算(即提供一个默认值,在流为空时返回该值,当流不为空时,该值作为起始值,参与每一次累加或合并计算)
- mapper:映射流中的某个元素,并根据此元素进行合并。
- op:合并函数,将mapper映射的元素,进行两两合并,最初的一个元素将于合并标识值进行合并。
// 合并结果,计算每科总分
Map<String, Integer> groupCalcSum = students.stream()
.collect(Collectors.groupingBy(Student::getCourse, Collectors.reducing(0, Student::getScore, Integer::sum)));
// 合并结果,获取每科最高分的学生信息
Map<String, Optional<Student>> groupCourseMax = students.stream()
.collect(Collectors.groupingBy(Student::getCourse, Collectors.reducing(BinaryOperator.maxBy(Comparator.comparing(Student::getScore)))));
Collectors.joining:合并字符串
Collectors.joining语法:
Collector<CharSequence, ?, String> joining()
Collector<CharSequence, ?, String> joining(CharSequence delimiter)
Collector<CharSequence, ?, String> joining(CharSequence delimiter, CharSequence prefix, CharSequence suffix)
- delimiter:分隔符
- prefix:每个字符的前缀
- suffix:每个字符的后缀
Collectors.joining只能对字符进行操作,因此一般会与其它downstream方法组合使用。
// 统计各科的学生姓名
Map<String, String> groupCourseSelectSimpleStudent = students.stream()
.collect(Collectors.groupingBy(Student::getCourse, Collectors.mapping(Student::getName, Collectors.joining(","))));
4. 分组自定义映射功能
说明:实际上Collectors.groupingBy的第三个参数downstream,其实就是就是将元素映
Java25Stream流:集合对象.stream()
文章目录
1.Stream流引入: list.stream().filter
package com.itheima07.boot; import java.util.ArrayList; import java.util.List; // 代码冗余: 1. 循环太多 2. 判断太多 public class StreamBootDemo { public static void main(String[] args) { List<String> list = new ArrayList<>(); list.add("张无忌"); list.add("周芷若"); list.add("赵敏"); list.add("张强"); list.add("张三丰"); //张集合 List<String> zhangList = new ArrayList<>(); for (String name : list) { if (name.startsWith("张")) { zhangList.add(name); } } //短集合 : 张集合基础上,只要名字3个 List<String> shortList = new ArrayList<>(); for (String name : zhangList) { if (name.length() == 3) { shortList.add(name); } } for (String name : shortList) { //遍历打印 System.out.println(name); } } }
package com.itheima07.boot; import java.util.ArrayList; import java.util.List; // Stream 流: 1. 基于函数式编程延伸出来的一种用法。 2. 作用: 简化 集合数据 处理过程中的代码冗余问题 public class StreamBootDemo02 { public static void main(String[] args) { List<String> list = new ArrayList<>(); list.add("张无忌"); list.add("周芷若"); list.add("赵敏"); list.add("张强"); list.add("张三丰"); list.stream().filter(name -> name.startsWith("张")) //name就是集合中的每个元素 .filter(name -> name.length() == 3).forEach(name-> System.out.println(name)); } }2.Stream流的获取:.stream(),Stream.of(array)
如下排除静态方法,ArrayList能用stream方法的话,是从Collection里继承这方法。
package com.itheima08.stream; import com.sun.org.apache.bcel.internal.generic.NEW; import java.util.*; import java.util.stream.Stream; /* * Stream 流: Stream流对象的获取: * 1. 集合 * Collection接口 默认方法 stream() * 2. 数组 * Stream.of(T...); 使用这个 * Stream.of(T); */ public class StreamGetDemo { public static void main(String[] args) { Collection<String> coll = new HashSet<>(); Stream<String> stream = coll.stream(); //1111111111111111111111111111111111111111111111111111111111111111111111111111 HashMap<String, String> map = new HashMap<>(); // Set set = map.keySet(); // set.stream(); Stream<String> stream1 = map.keySet().stream(); Stream<Map.Entry<String, String>> stream2 = map.entrySet().stream(); //111111111111111111111111111111111111111111111111111111111111111111111111111 String[] array = {"a","b"}; Stream<String> stream3 = Stream.of(array); Integer[] array2 = {1,2,3}; Stream<Integer> stream4 = Stream.of(array2); //T... -> T=Integer,把每个元素拆开。//泛型 必须是 引用类型 int[] array3 = {1,2,3}; //如果说数组要获取Stream流,不要用基本类型数组, 把整个数组当成一个元素无法拆开,不要用如下 Stream<int[]> stream5 = Stream.of(array3);// T -> T = int[] } }3.Stream流的终结方法:list.stream().count()
package com.itheima09.method; import java.util.ArrayList; import java.util.Collection; import java.util.Collections; import java.util.function.Consumer; /* * Stream流的方法 * 1. 终结方法 : 不支持链式编程 (返回值: 基本类型) * 2. 拼接方法 : 支持链式编程 (返回值: 当前类型,引用类型) * * 终结方法: * 1.foreach * void forEach(Consumer<? super T> action); * 底层: 迭代器 , 需要消费参数(集合中每一个元素) * 2.count * long count() : 获取集合中的元素个数 */ public class EndDemo { public static void main(String[] args) { // method(); //abc ArrayList<Integer> list = new ArrayList<>(); Collections.addAll(list, 5,3,2,4); // for (Integer integer : list) { //list.for快捷 // System.out.println(integer); // } //11111111111111111111111111111111111111111111111111111111111111111111 //stream流打印,先获取stream流对象 /* list.stream().forEach(new Consumer<Integer>() { @Override public void accept(Integer t) { System.out.println(t); //遍历打印list集合 } });*/ //如下等于上面 // list.stream().forEach(t-> System.out.println(t)); //11111111111111111111111111111111111111111111111111111111111111111111 long count = list.stream().count(); System.out.println(count); //4 } private static void method() { // StringBuilder sb = new StringBuilder(); // StringBuilder sb2 = sb.append("a"); // StringBuilder sb3 = sb2.append("b"); StringBuilder sb = new StringBuilder(); sb.append("a").append("b").append("c").equals("abc"); //append拼接方法,equals终结方法,因为equals返回boolean基本类型,不能再调用方法 System.out.println(sb); } }4.Stream流的拼接方法:Stream.concat
package com.itheima09.method; import java.util.ArrayList; import java.util.Collections; import java.util.HashSet; import java.util.function.Predicate; import java.util.stream.Stream; /* * Stream的拼接方法 * 1. filter 过滤 * Stream<T> filter(Predicate<? super T> predicate); * 1. Predicate : public boolean test(String s) * 2. s是集合中每一个元素 , 迭代器 * 3. return true : 表示保留这个元素 * 2. limit 取用前几个 * Stream<T> limit(long count) * 只要前count个元素, 没有越界 * 3. skip 跳过前几个 * Stream<T> skip(long n); * 4. static concat 组合,静态方法 * static <T> Stream<T> concat(Stream<T> a, Stream< T> b) * 合并两个stream,整合一个stream */ public class ChainDemo { //Chain:链 public static void main(String[] args) { ArrayList<String> list = new ArrayList<>(); Collections.addAll(list,"张三","张三丰","李四","李世石"); //.filter返回值类型是stream,调完filter还能调filter,就像Stringbuild调完append还可再调append // list.stream().filter(new Predicate<String>() { // @Override // public boolean test(String s) { // return s.startsWith("张"); // } // }).forEach(s -> System.out.println(s)); //张三 张三丰 // list.stream().filter(s->s.startsWith("张")).forEach(s-> System.out.println(s)); //等同上面 // list.stream().limit(5).forEach(t-> System.out.println(t)); //没有索引越界,因为迭代器没有索引,最多4个就给4个 // list.stream().skip(3).forEach(t-> System.out.println(t)); //李世石 ArrayList<String> list2 = new ArrayList<>(); Collections.addAll(list2,"王五","王五百","马六"); Stream<String> stream1 = list.stream(); Stream<String> stream2 = list2.stream(); Stream.concat(stream1,stream2).forEach(t-> System.out.println(t)); //张三...7个元素 } }5.Stream源码分析:consumer.accept
package com.itheima10.source; import java.util.ArrayList; import java.util.Collection; import java.util.function.Consumer; import java.util.function.Predicate; public class MyStream { Collection<String> coll; //属性 public MyStream(Collection<String> coll){ this.coll = coll; } public void forEach(Consumer<String> consumer){ for (String s : coll) { //快捷键coll.foreach consumer.accept(s); //接口调用方法执行子类重写的方法即下面SourceDemo.java中System.out.println(t),s就是t, } } public MyStream filter(Predicate<String> predicate){ ArrayList<String> list = new ArrayList<>(); //list集合只添加 推断结果true的元素,新的 for (String s : coll) { boolean result = predicate.test(s); //打印,父类引用调用方法执行子类重写方法即下面SourceDemo.java中t.length()==2 if(result){ list.add(s); } } coll = list; //集合重置为list即保留下来的集合 return this; } }package com.itheima10.source; import java.util.ArrayList; import java.util.Collections; public class SourceDemo { public static void main(String[] args) { ArrayList<String> list = new ArrayList<>(); Collections.addAll(list,"张三","李四光","王五"); /* * foreach: * 1. 迭代器(底层) * 2. t是集合中的每一个元素 * 执行次数 = 集合元素个数 */ // new MyStream(list).forEach(t -> System.out.println(t)); /* * MyStream filter(Predicate<String> predicate) * predicate : boolean test(T t); * 1. 迭代器 * 2. t 是集合中的每一个元素 * 3. 返回true : 表示保留这个元素 */ new MyStream(list).filter(t -> t.length()==2).forEach(t-> System.out.println(t)); } }
如下案例比较:package com.itheima11.union; import java.util.ArrayList; import java.util.List; public class Demo01 { public static void main(String[] args) { List<String> one = new ArrayList<>(); one.add("迪丽热巴"); one.add("宋远桥"); one.add("苏星河"); one.add("老子"); one.add("庄子"); one.add("孙子"); one.add("洪七公"); List<String> two = new ArrayList<>(); two.add("古力娜扎"); two.add("张无忌"); two.add("张三丰"); two.add("赵丽颖"); two.add("张二狗"); two.add("张天爱"); two.add("张三"); List<String> oneA = new ArrayList<>(); // 第一个队伍只要名字为3个字的成员姓名; for (String name : one) { if (name.length() == 3) { oneA.add(name); } } List<String> oneB = new ArrayList<>(); // 第一个队伍筛选之后只要前3个人; for (int i = 0; i < 3; i++) { oneB.add(oneA.get(i)); } //11111111111111111111111111111111111111111111111111111111111111111111111111111111111111 List<String> twoA = new ArrayList<>(); // 第二个队伍只要姓张的成员姓名; for (String name : two) { if (name.startsWith("张")) { twoA.add(name); } } List<String> twoB = new ArrayList<>(); // 第二个队伍筛选之后不要前2个人; for (int i = 2; i < twoA.size(); i++) { twoB.add(twoA.get(i)); } //11111111111111111111111111111111111111111111111111111111111111111111111111111111111111 List<String> totalNames = new ArrayList<>(); // 将两个队伍合并为一个队伍; totalNames.addAll(oneB); totalNames.addAll(twoB); for (String name : totalNames) { // 打印整个队伍的姓名信息。 System.out.println(name); } } }package com.itheima11.union; import java.util.ArrayList; import java.util.List; import java.util.stream.Stream; public class Demo02 { public static void main(String[] args) { List<String> one = new ArrayList<>(); one.add("迪丽热巴"); one.add("宋远桥"); one.add("苏星河"); one.add("老子"); one.add("庄子"); one.add("孙子"); one.add("洪七公"); List<String> two = new ArrayList<>(); two.add("古力娜扎"); two.add("张无忌"); two.add("张三丰"); two.add("赵丽颖"以上是关于Stream Collectors.groupingBy的四种用法 解决分组统计(计数求和平均数等)范围统计分组合并分组结果自定义映射等问题的主要内容,如果未能解决你的问题,请参考以下文章