GPFS和Lustre之后,还有谁来接盘?
Posted Hardy晗狄
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GPFS和Lustre之后,还有谁来接盘?相关的知识,希望对你有一定的参考价值。

文件系统从来都没有成为IT领域中最闪光的那部分,这或许可以解释在大型变革和新进入该领域的人,为什么没有注意到它。但在HPC领域,情况可能有所不同。
HPC方案供应商主要基于GPFS或Lustre的产品提供HPC文件解决方案,而且企业和HPC组织已经接受了这些产品。然而,近年来IT环境的变化已经说服一些公司和供应商重新考虑文件系统。诸如大规模分析和机器学习的兴起,HPC向主流企业应用的扩张以及云存储的发展等都给文件服务器带来了新的挑战,使得这些文件服务器变得日益复杂和难以管理。
并行文件系统的业务环境变化也更加关注GPFS和Lustre。特别是英特尔在2017年4月停止了销售Lustre企业版本的维护和发行,这样一个备受瞩目的Lustre支持者的决定引发了大众对Lustre未来的质疑,做后出售给DDN。
与此同时,又有一个并行文件系统BeeGFS兴起,其目标就是HPC领域。2005年,德国Fraunhofer高性能计算中心在该机构的一个计算机集群内部开始实施,该技术开始迅速攀升,2007年第一个测试版发布,一年后正式版首次发布。并在2009年商业化。在2014年,Fraunhofer拆出一家新公司ThinkParQ,以扩大其在HPC商业市场的覆盖面。最初被称为FhGFS的文件系统被命名为BeeGFS。
ThinkParQ的目标是为各种规模的组织提供开放源代码和免费软件Bee GFS,并提供从支持、咨询到系统集成商的合作伙伴关系等服务,开发包括BeeGFS在内的解决方案。并行文件系统软件的大部分开发仍在Fraunhofer中进行开发。
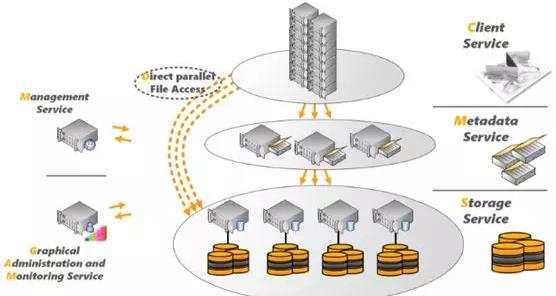
在2017年,ThinkParQ和BeeGFS开发人员在多个领域取得了进展,包括与集群管理软件制造商Bright Computing,HPC解决方案提供商Penguin Computing以及硬件制造商Ace Computers和QuantaCloud Computing等公司扩大合作关系,扩展到欧洲以外的俄罗斯和日本等地区,并在SC17超级计算展会上发布的BeeGFS v7.0版本,包括新的存储池设计,SSD和HDD混合磁盘支持,数据存放策略控制。
在日本,富士通宣布其即将推出的人工智能桥接云基础架构(ABCI)超级计算机将使用BeeGFS onDemand(BeeOND)实现加速,类似于HewlettPackard Enterprise上线的Tsubame3.0系统。据ThinkParQ称,该系统在计算节点采用1PB NVMe高速缓冲BeeOND,可实现1TB/s性能。
根据ThinkParQ首席执行官和BeeGFS首席执行官Sven Bruener的介绍,该公司对BeeGFS的兴趣有所增加,其中主要原因是BeeGFS对市场需求满足以及对Lustre及其未来发展的担忧。BeeGFS帮助公司在一个市场中获得竞争力,而这些市场竞争来源于提供经过市场考验的并行文件系统产品的知名供应商。
Intel放弃其Lustre商业化努力的决定导致合作伙伴将BeeGFS用于Lustre替代计划,因为与Lustre不同,BeeGFS起源于HPC世界。当大家使用BeeGFS时,他们得到的东西并非依靠Intel针对大量功能进行了优化,而主要是针对性能,这对许多用户而言非常重要。
由于性能问题和底层体系结构,各种组织倾向于使用BeeGFS替代GPFS和Lustre系统的,他们注意到从一开始,他们的文件系统表现相当好,但过了一段时间其表现就不再那么好了。BeeGFS更易于使用并且需要更少的维护。大多数用户实际上是从Lustre和GPFS等其他系统切换出来的,因为他们遇到了各方面的问题,然后他们开始尝试其他系统,然而在尝试的过程中,他们对BeeGFS开箱即用设置的容易程度和性能感到惊讶。
根据ThinkParQ全球销售咨询总监的说法,可扩展性也是BeeGFS一个差异化因素,BeeGFS的灵活性很好,以至于真的可以从两台服务器开始即时添加组件扩展。它可以与Panasas的PanFS文件系统进行比较,就连IBM这样的供应商也认可BeeGFS的市场表现。
IBM认为他们可以通过添加BeeGFS来销售更多的服务器硬件和存储控制器,因为GPFS相对来说非常复杂并且可能更昂贵。对于解决方案来,BeeGFS在各种环境下的体现出很好的灵活性。通过BeeGFS,可以使用较少的组件构建小规模系统,但如果系统需要增长,则只需按容量或性能要求添加组件即可(BeeGFS可以扩展到ExaByte规模),没有技术限制。
虽然BeeGFS用户主要集中在欧洲,但ThinkParQ在其他地区如俄罗斯、美国和日本也在迅速增长,像Oak Ridge这样的国家实验室大约有二十个多个。ThinkParQ拥有部署容量约在10PB范围的客户也遍布多个行业,包括生物信息学领域,维也纳大学等,拥有数千个部署节点。
当BeeGFS出现时,其他大型厂商正在支持其他老牌文件系统(如Lustre、GPFS、StorNext等),一些开发自己的文件系统的公司正在努力增长,实际上,BeeGFS可以满足不断变化的市场需求。
纵观历史,GPFS将在25年前就已经出现,并更关注于数据管理。而Lustre在17年前作为一个试验性项目开发出来。15年前,固态硬盘尚不存在,他们也不知道未来的存储环境会有什么样的需求。如今,BeeGFS开发人员了解了这些限制,他们也看到了市场的动向和市场的需求,他们的客户确实需要独立于硬件的软件解决方案,从而充分利用组件的全部优势,通过易用性简化运维管理,无需专业人员。
BeeGFS系统背后的魔力在于它坐落在本地文件系统之上的Linux系统的用户空间中,这使得它非常非常灵活,因为通常如果您要设置HPC环境,需要一个专用的元数据服务器、存储服务器组件。然而BeeGFS具有很好的灵活性,可以将BeeGFS组件安装连接到存储节点,也可以设置文件系统实例。HPC非常流行的BurstBuffer技术,在BeeGFS称之为BeeGFS on Demand,它有效缓解现有HPC环境中令人讨厌的浪涌IO模式,通过闪存介质保障系统在任何时候的性能要求。
实际上,Bright Computing已经与BeeGFS合作了几年了,努力如何简单在Bright集群之上部署这个BeeGFS,并在健康检查BeeGFS和监测BeeGFS方面做出更多努力。实际上,Bright是可以集成GPFS和Lustre并行文件系统使用,在Bright Computing看来,他们对GPFS,Lustre和BeeGFS都有丰富经验,但发现BeeGFS是最轻量的,即使没有与BeeGFS集成,也不像Lustre和GPFS那么难以安装部署。
今天分享到此为止,关于BeeGFS文件系统架构、技术和生态分析文章,请大家搜索历史文章查阅。此外,前期详细分享过整个<从高性能计算(HPC)技术演变解析方案、生态和行业发展趋势>分析,并整理成电子书,目录如下:
第1章 HPC行业和市场概述 1
1.1 HPC主要场景和分类 3
1.2 HPC系统主要组成 11
1.3 HPC IO业务模型 12
1.4 HPC系统架构演变 13
1.5 HPC市场的主流玩家 14
1.5.1 HPC存储厂商分类 15
1.5.2 Burst Buffer介绍 15
1.5.3 Panasas和Seagate介绍 17
1.5.4 主流并行文件系统 17
1.6 HPC对存储的主要诉求 19
1.7 HPC系统的衡量标准 20
1.8 HPC未来的技术趋势 22
第2章 HPC场景的存储形态 23
2.1 HPC为何是NAS存储 23
2.2 本地存储引入的问题 23
2.3 HPC主要的存储形态 25
第3章 Lustre文件系统解析 26
3.1 Lustre文件系统概述 26
3.2 Intel Lustre企业版开源策略 26
3.3 Lustre文件系统架构 27
3.4 Lustre Stripe切片技术 30
3.5 Lustre 的IO性能特征 34
3.5.1 写性能优于读性能 34
3.5.2 大文件性能表现好 35
3.5.3 小文件性能表现差 35
3.6 Lustre小文件优化 36
3.7 Lustre性能优化最佳实践 38
第4章 GPFS文件系统解析 39
4.1 GPFS文件系统概述 39
4.1.1 GPFS文件系统架构 40
4.1.2 GPFS文件系统逻辑架构 41
4.2 GPFS文件系统对象 42
4.2.1 网络共享磁盘NSD 42
4.2.2 集群节点及客户端节点 43
4.2.3 仲裁Node和Tiebreaker磁盘 43
4.3 GPFS集群仲裁机制 43
4.3.1 仲裁节点机制 44
4.3.2 仲裁磁盘机制 44
4.4 Failure Group失效组 44
4.5 GPFS文件系统伸缩性 45
4.6 GPFS文件系统负载均衡 45
第5章 Spectrum Scale架构详解 46
5.1 Spectrum Scale云集成 48
5.2 Spectrum Scale存储服务 49
5.3 Spectrum Scale交付模型 50
5.4 Spectrum Scale架构分类 51
5.5 企业存储特性 52
5.5.1 数据分级至云 52
5.5.2 Spectrum Scale RAID技术 53
5.5.3 Active文件管理 53
5.5.4 快照技术 53
5.5.5 Cache加速 54
5.5.6 分级存储管理 55
5.5.7 文件和对象访问 56
5.5.8 加密和销毁 57
5.6 虚拟化部署 57
5.7 LTFS带库技术 58
5.8 Elastic Storage Server 61
第6章 BeeGFS文件系统解析 62
6.1 ThinkParQ介绍 62
6.2 BeeGFS操作系统兼容性 63
6.3 BeeGFS系统架构 63
6.3.1 管理服务器介绍 64
6.3.2 元数据服务器介绍 65
6.3.3 对象存储服务介绍 66
6.3.4 文件系统客户端 67
6.4 BeeGFS安装和设置 68
6.5 BeeGFS调优和配置 69
6.6 BeeOND Burst Buffer 69
6.7 BeeGFS配额特性 72
6.8 BeeGFS的Buddy镜像 73
6.9 BeeGFS支持API概述 75
6.10 BeeGFS系统配置要求 75
6.10.1 存储服务器配置 76
6.10.2 元数据服务器配置 77
6.10.3 客户端服务器配置 77
6.10.4 管理守护进程配置 78
6.11 BeeGFS支持的网络类型 78
6.12 通过NAS导出BeeGFS 78
6.13 BeeGFS生态和合作 79
第7章 主流HPC产品和解决方案 82
7.1 DDN存储解决方案和产品 82
7.1.1 DDN S2A平台和产品 83
7.1.2 DDN SFA平台和产品 85
7.1.3 DDN WOS平台和产品 86
7.1.4 DDN Scaler系列网关产品 87
7.1.5 Burst Buffer加速产品 91
7.1.6 FlashScale全闪存产品 93
7.2 希捷存储解决方案和产品 96
7.2.1 ClusterStor产品架构 99
7.2.2 ClusterStor 管理介绍 100
7.2.3 ClusterStor配置扩展方式 101
7.2.4 ClusterStor存储软件集成 104
第8章 Burst Buffer技术和产品分析 107
8.1 Cray DataWarp技术和产品 107
8.1.1 Burst Buffer场景匹配 109
8.1.2 Burst Buffer技术架构 110
8.1.3 Cray技术演进蓝图 113
8.1.4 Cray HPC方案和产品 114
8.2 DDN Burst Buffer产品 117
8.2.1 IME产品架构 117
8.2.2 IME14KX产品介绍 120
8.2.3 IME240产品介绍 121
8.3 EMC Burst Buffer产品 122
8.3.1 aBBa产品架构 123
8.3.2 aBBa软件堆栈 124
第9章 HPC主流网络和技术分析 126
9.1 InfiniBand技术和基础知识 126
9.1.1 IB技术的发展 126
9.1.2 IB技术的优势 127
9.1.3 IB网络重要概念 129
9.1.4 IB协议堆栈分析 130
9.1.5 IB应用场景分析 134
9.2 InfiniBand技术和架构 135
9.2.1 IB 网络和拓扑组成 135
9.2.2 软件协议栈OFED 139
9.2.3 InfiniBand网络管理 140
9.2.4 并行计算集群能力 141
9.2.5 基于socket网络应用 142
9.2.6 IB对存储协议支持 142
9.2.7 RDMA技术介绍 143
9.3 Mellanox产品分析 143
9.3.1 Infiniband交换机 145
9.3.2 InfiniBand适配器 148
9.3.3 Infiniband路由和网关设备 149
9.3.4 Infiniband线缆和收发器 150
9.4 InfiniBand和OPA之争 151
9.4.1 True Scale Fabric软件架构 152
9.4.2 Intel InfiniBand产品家族 154
9.4.3 Omni-Path产品介绍 155
9.4.4 OPA和InfiniBand对比 156
第10章 HPC超算系统排名和评估 160
10.1 TOP500基准和排名 162
10.2 Green500基准和排名 165
10.3 HPC系统其他评估基准 167
10.3.1 GTC-P应用基准 173
10.3.2 Meraculous测试基准 173
10.3.3 MILC测试基准 174
10.3.4 MiniDFT测试基准 174
10.3.5 MiniPIC测试基准 174
10.3.6 PENNANT测试基准 175
10.3.7 SNAP测试基准 175
10.3.8 UMT测试基准 175
10.3.9 Crossroads基准 175
10.3.10 IOR BenchMark基准 176
10.3.11 Mdtest测试基准 176
10.3.12 STREAM测试基准 176
通过链接获取电子书详情:架构师技术联盟 https://k.weidian.com/75et8ri2,点击原文链接获取“从高性能计算(HPC)技术演变解析方案、生态和行业发展趋势”资料总结。
以上是关于GPFS和Lustre之后,还有谁来接盘?的主要内容,如果未能解决你的问题,请参考以下文章