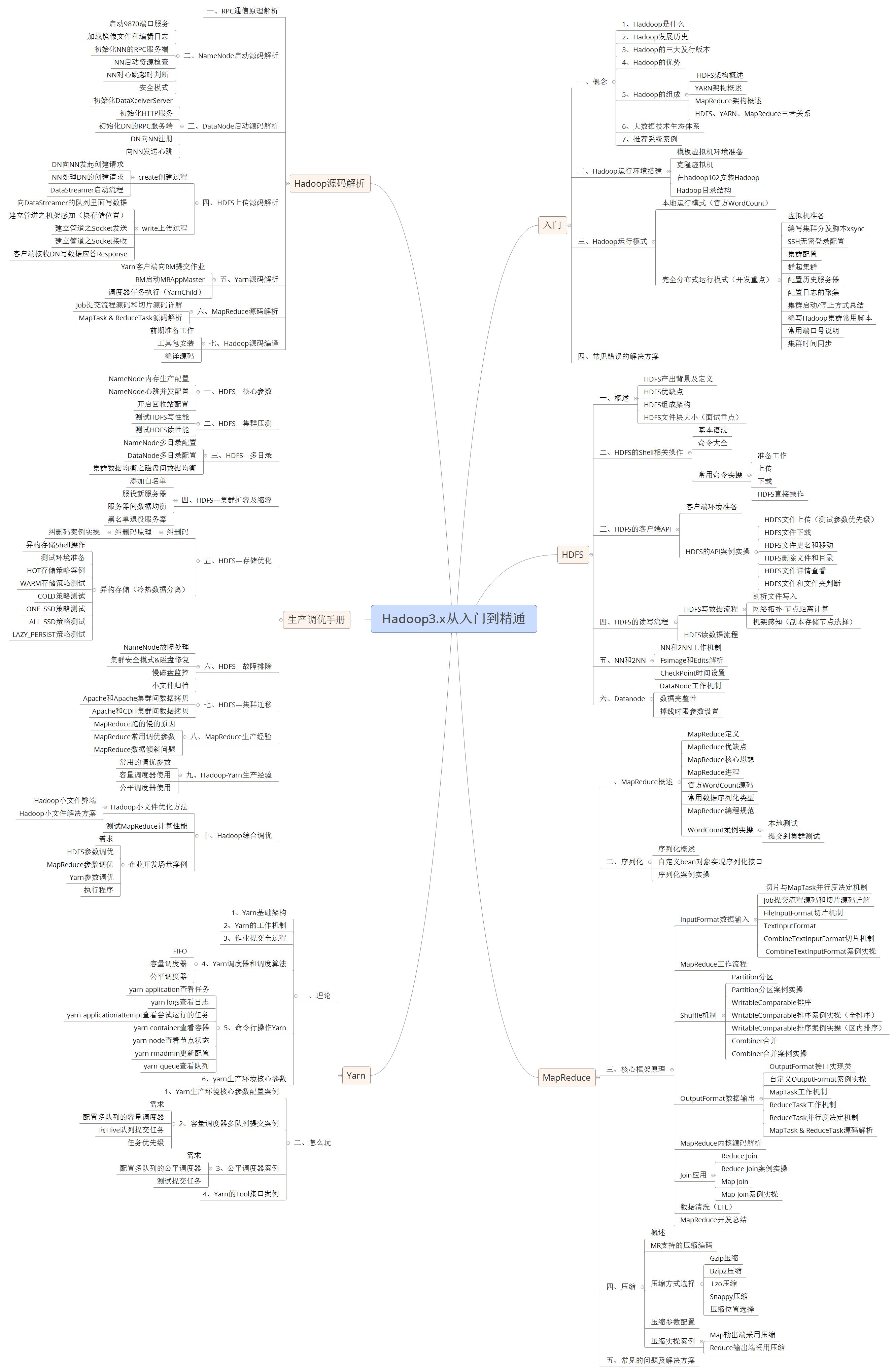
[root@node1 ~]# cd /export/server/hadoop-3.3.0/share/hadoop/mapreduce/
[root@node1 mapreduce]# hadoop jar hadoop-mapreduce-examples-3.3.0.jar wordcount /wordcount/input /wordcount/output
2023-03-20 14:43:07,516 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at node1/192.168.88.151:8032
2023-03-20 14:43:09,291 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1679293699463_0001
2023-03-20 14:43:11,916 INFO input.FileInputFormat: Total input files to process : 1
2023-03-20 14:43:12,313 INFO mapreduce.JobSubmitter: number of splits:1
2023-03-20 14:43:13,173 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1679293699463_0001
2023-03-20 14:43:13,173 INFO mapreduce.JobSubmitter: Executing with tokens: []
2023-03-20 14:43:14,684 INFO conf.Configuration: resource-types.xml not found
2023-03-20 14:43:14,684 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2023-03-20 14:43:17,054 INFO impl.YarnClientImpl: Submitted application application_1679293699463_0001
2023-03-20 14:43:17,123 INFO mapreduce.Job: The url to track the job: http://node1:8088/proxy/application_1679293699463_0001/
2023-03-20 14:43:17,124 INFO mapreduce.Job: Running job: job_1679293699463_0001
2023-03-20 14:43:52,340 INFO mapreduce.Job: Job job_1679293699463_0001 running in uber mode : false
2023-03-20 14:43:52,360 INFO mapreduce.Job: map 0% reduce 0%
2023-03-20 14:44:08,011 INFO mapreduce.Job: map 100% reduce 0%
2023-03-20 14:44:16,986 INFO mapreduce.Job: map 100% reduce 100%
2023-03-20 14:44:18,020 INFO mapreduce.Job: Job job_1679293699463_0001 completed successfully
2023-03-20 14:44:18,579 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=31
FILE: Number of bytes written=529345
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=142
HDFS: Number of bytes written=17
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=11303
Total time spent by all reduces in occupied slots (ms)=6220
Total time spent by all map tasks (ms)=11303
Total time spent by all reduce tasks (ms)=6220
Total vcore-milliseconds taken by all map tasks=11303
Total vcore-milliseconds taken by all reduce tasks=6220
Total megabyte-milliseconds taken by all map tasks=11574272
Total megabyte-milliseconds taken by all reduce tasks=6369280
Map-Reduce Framework
Map input records=2
Map output records=5
Map output bytes=53
Map output materialized bytes=31
Input split bytes=108
Combine input records=5
Combine output records=2
Reduce input groups=2
Reduce shuffle bytes=31
Reduce input records=2
Reduce output records=2
Spilled Records=4
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=546
CPU time spent (ms)=3680
Physical memory (bytes) snapshot=499236864
Virtual memory (bytes) snapshot=5568684032
Total committed heap usage (bytes)=365953024
Peak Map Physical memory (bytes)=301096960
Peak Map Virtual memory (bytes)=2779201536
Peak Reduce Physical memory (bytes)=198139904
Peak Reduce Virtual memory (bytes)=2789482496
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=34
File Output Format Counters
Bytes Written=17
[root@node1 mapreduce]#
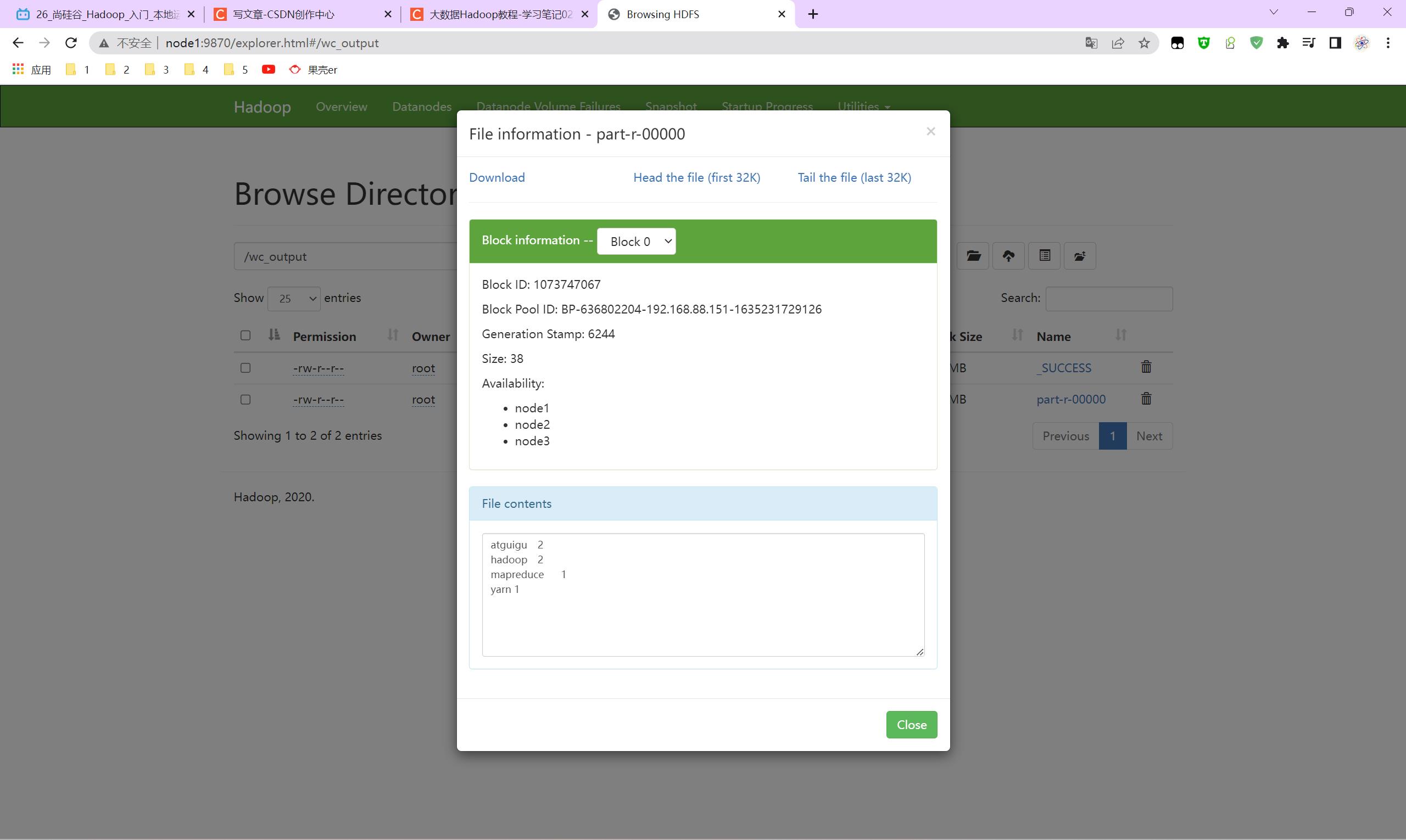
[root@node1 mapreduce]# hadoop jar hadoop-mapreduce-examples-3.3.0.jar wordcount /wc_input /wc_output
2023-03-20 15:01:48,007 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at node1/192.168.88.151:8032
2023-03-20 15:01:49,475 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1679293699463_0002
2023-03-20 15:01:50,522 INFO input.FileInputFormat: Total input files to process : 1
2023-03-20 15:01:51,010 INFO mapreduce.JobSubmitter: number of splits:1
2023-03-20 15:01:51,894 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1679293699463_0002
2023-03-20 15:01:51,894 INFO mapreduce.JobSubmitter: Executing with tokens: []
2023-03-20 15:01:52,684 INFO conf.Configuration: resource-types.xml not found
2023-03-20 15:01:52,687 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2023-03-20 15:01:53,237 INFO impl.YarnClientImpl: Submitted application application_1679293699463_0002
2023-03-20 15:01:53,487 INFO mapreduce.Job: The url to track the job: http://node1:8088/proxy/application_1679293699463_0002/
2023-03-20 15:01:53,492 INFO mapreduce.Job: Running job: job_1679293699463_0002
2023-03-20 15:02:15,329 INFO mapreduce.Job: Job job_1679293699463_0002 running in uber mode : false
2023-03-20 15:02:15,342 INFO mapreduce.Job: map 0% reduce 0%
2023-03-20 15:02:26,652 INFO mapreduce.Job: map 100% reduce 0%
2023-03-20 15:02:40,297 INFO mapreduce.Job: map 100% reduce 100%
2023-03-20 15:02:41,350 INFO mapreduce.Job: Job job_1679293699463_0002 completed successfully
2023-03-20 15:02:41,557 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=60
FILE: Number of bytes written=529375
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=149
HDFS: Number of bytes written=38
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=8398
Total time spent by all reduces in occupied slots (ms)=9720
Total time spent by all map tasks (ms)=8398
Total time spent by all reduce tasks (ms)=9720
Total vcore-milliseconds taken by all map tasks=8398
Total vcore-milliseconds taken by all reduce tasks=9720
Total megabyte-milliseconds taken by all map tasks=8599552
Total megabyte-milliseconds taken by all reduce tasks=9953280
Map-Reduce Framework
Map input records=4
Map output records=6
Map output bytes=69
Map output materialized bytes=60
Input split bytes=100
Combine input records=6
Combine output records=4
Reduce input groups=4
Reduce shuffle bytes=60
Reduce input records=4
Reduce output records=4
Spilled Records=8
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=1000
CPU time spent (ms)=3880
Physical memory (bytes) snapshot=503771136
Virtual memory (bytes) snapshot=5568987136
Total committed heap usage (bytes)=428343296
Peak Map Physical memory (bytes)=303013888
Peak Map Virtual memory (bytes)=2782048256
Peak Reduce Physical memory (bytes)=200757248
Peak Reduce Virtual memory (bytes)=2786938880
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=49
File Output Format Counters
Bytes Written=38
[root@node1 mapreduce]# pwd
/export/server/hadoop-3.3.0/share/hadoop/mapreduce
[root@node1 mapreduce]#
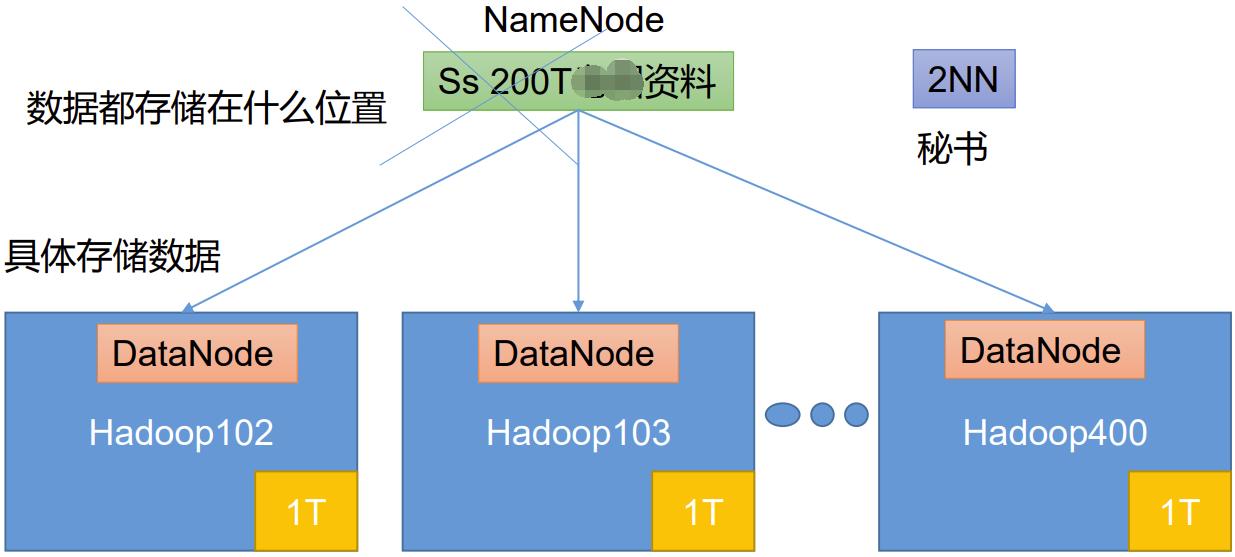
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
连接成功
Last login: Mon Mar 20 16:01:40 2023
[root@node1 ~]# su atguigu
[atguigu@node1 root]$ cd /home/atguigu/
[atguigu@node1 ~]$ pwd
/home/atguigu
[atguigu@node1 ~]$ xsync bin/
==================== node1 ====================
The authenticity of host 'node1 (192.168.88.151)' can't be established.
ECDSA key fingerprint is SHA256:+eLT3FrOEuEsxBxjOd89raPi/ChJz26WGAfqBpz/KEk.
ECDSA key fingerprint is MD5:18:42:ad:0f:2b:97:d8:b5:68:14:6a:98:e9:72:db:bb.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'node1,192.168.88.151' (ECDSA) to the list of known hosts.
atguigu@node1's password:
atguigu@node1's password:
sending incremental file list
sent 98 bytes received 17 bytes 17.69 bytes/sec
total size is 727 speedup is 6.32
==================== node2 ====================
The authenticity of host 'node2 (192.168.88.152)' can't be established.
ECDSA key fingerprint is SHA256:+eLT3FrOEuEsxBxjOd89raPi/ChJz26WGAfqBpz/KEk.
ECDSA key fingerprint is MD5:18:42:ad:0f:2b:97:d8:b5:68:14:6a:98:e9:72:db:bb.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'node2,192.168.88.152' (ECDSA) to the list of known hosts.
atguigu@node2's password:
atguigu@node2's password:
sending incremental file list
sent 94 bytes received 17 bytes 44.40 bytes/sec
total size is 727 speedup is 6.55
==================== node3 ====================
The authenticity of host 'node3 (192.168.88.153)' can't be established.
ECDSA key fingerprint is SHA256:+eLT3FrOEuEsxBxjOd89raPi/ChJz26WGAfqBpz/KEk.
ECDSA key fingerprint is MD5:18:42:ad:0f:2b:97:d8:b5:68:14:6a:98:e9:72:db:bb.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'node3,192.168.88.153' (ECDSA) to the list of known hosts.
atguigu@node3's password:
atguigu@node3's password:
sending incremental file list
sent 94 bytes received 17 bytes 44.40 bytes/sec
total size is 727 speedup is 6.55
[atguigu@node1 ~]$
----------------------------------------------------------------------------------------
连接成功
Last login: Mon Mar 20 17:22:20 2023 from 192.168.88.151
[root@node2 ~]# su atguigu
[atguigu@node2 root]$ vim /etc/sudoers
您在 /var/spool/mail/root 中有新邮件
[atguigu@node2 root]$ su root
密码:
[root@node2 ~]# vim /etc/sudoers
[root@node2 ~]# cd /opt/
[root@node2 opt]# ll
总用量 0
drwxr-xr-x 4 atguigu atguigu 46 3月 20 11:32 module
drwxr-xr-x. 2 root root 6 10月 31 2018 rh
drwxr-xr-x 2 atguigu atguigu 67 3月 20 10:47 software
[root@node2 opt]# su atguigu
[atguigu@node2 opt]$ cd /home/atguigu/
[atguigu@node2 ~]$ llk
bash: llk: 未找到命令
[atguigu@node2 ~]$ ll
总用量 0
drwxrwxr-x 2 atguigu atguigu 19 3月 20 15:56 bin
[atguigu@node2 ~]$ cd ~
您在 /var/spool/mail/root 中有新邮件
[atguigu@node2 ~]$ ll
总用量 0
drwxrwxr-x 2 atguigu atguigu 19 3月 20 15:56 bin
[atguigu@node2 ~]$ ll
总用量 0
drwxrwxr-x 2 atguigu atguigu 19 3月 20 15:56 bin
您在 /var/spool/mail/root 中有新邮件
[atguigu@node2 ~]$ cd bin
[atguigu@node2 bin]$ ll
总用量 4
-rwxrwxrwx 1 atguigu atguigu 727 3月 20 16:00 xsync
[atguigu@node2 bin]$
----------------------------------------------------------------------------------------
连接成功
Last login: Mon Mar 20 17:22:26 2023 from 192.168.88.152
[root@node3 ~]# vim /etc/sudoers
您在 /var/spool/mail/root 中有新邮件
[root@node3 ~]# cd /opt/
[root@node3 opt]# ll
总用量 0
drwxr-xr-x 4 atguigu atguigu 46 3月 20 11:32 module
drwxr-xr-x. 2 root root 6 10月 31 2018 rh
drwxr-xr-x 2 atguigu atguigu 67 3月 20 10:47 software
[root@node3 opt]# cd ~
您在 /var/spool/mail/root 中有新邮件
[root@node3 ~]# ll
总用量 4
-rw-------. 1 root root 1340 9月 11 2020 anaconda-ks.cfg
-rw------- 1 root root 0 2月 23 16:20 nohup.out
[root@node3 ~]# ll
总用量 4
-rw-------. 1 root root 1340 9月 11 2020 anaconda-ks.cfg
-rw------- 1 root root 0 2月 23 16:20 nohup.out
您在 /var/spool/mail/root 中有新邮件
[root@node3 ~]# cd ~
[root@node3 ~]# ll
总用量 4
-rw-------. 1 root root 1340 9月 11 2020 anaconda-ks.cfg
-rw------- 1 root root 0 2月 23 16:20 nohup.out
[root@node3 ~]# su atguigu
[atguigu@node3 root]$ cd ~
[atguigu@node3 ~]$ ls
bin
[atguigu@node3 ~]$ ll
总用量 0
drwxrwxr-x 2 atguigu atguigu 19 3月 20 15:56 bin
[atguigu@node3 ~]$ cd bin
[atguigu@node3 bin]$ ll
总用量 4
-rwxrwxrwx 1 atguigu atguigu 727 3月 20 16:00 xsync
[atguigu@node3 bin]$
----------------------------------------------------------------------------------------
连接成功
Last login: Mon Mar 20 16:01:40 2023
[root@node1 ~]# su atguigu
[atguigu@node1 root]$ cd /home/atguigu/
[atguigu@node1 ~]$ pwd
/home/atguigu
[atguigu@node1 ~]$ xsync bin/
==================== node1 ====================
The authenticity of host 'node1 (192.168.88.151)' can't be established.
ECDSA key fingerprint is SHA256:+eLT3FrOEuEsxBxjOd89raPi/ChJz26WGAfqBpz/KEk.
ECDSA key fingerprint is MD5:18:42:ad:0f:2b:97:d8:b5:68:14:6a:98:e9:72:db:bb.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'node1,192.168.88.151' (ECDSA) to the list of known hosts.
atguigu@node1's password:
atguigu@node1's password:
sending incremental file list
sent 98 bytes received 17 bytes 17.69 bytes/sec
total size is 727 speedup is 6.32
==================== node2 ====================
The authenticity of host 'node2 (192.168.88.152)' can't be established.
ECDSA key fingerprint is SHA256:+eLT3FrOEuEsxBxjOd89raPi/ChJz26WGAfqBpz/KEk.
ECDSA key fingerprint is MD5:18:42:ad:0f:2b:97:d8:b5:68:14:6a:98:e9:72:db:bb.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'node2,192.168.88.152' (ECDSA) to the list of known hosts.
atguigu@node2's password:
atguigu@node2's password:
sending incremental file list
sent 94 bytes received 17 bytes 44.40 bytes/sec
total size is 727 speedup is 6.55
==================== node3 ====================
The authenticity of host 'node3 (192.168.88.153)' can't be established.
ECDSA key fingerprint is SHA256:+eLT3FrOEuEsxBxjOd89raPi/ChJz26WGAfqBpz/KEk.
ECDSA key fingerprint is MD5:18:42:ad:0f:2b:97:d8:b5:68:14:6a:98:e9:72:db:bb.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'node3,192.168.88.153' (ECDSA) to the list of known hosts.
atguigu@node3's password:
atguigu@node3's password:
sending incremental file list
sent 94 bytes received 17 bytes 44.40 bytes/sec
total size is 727 speedup is 6.55
[atguigu@node1 ~]$ xsync /etc/profile.d/my_env.sh
==================== node1 ====================
atguigu@node1's password:
atguigu@node1's password:
.sending incremental file list
sent 48 bytes received 12 bytes 13.33 bytes/sec
total size is 223 speedup is 3.72
==================== node2 ====================
atguigu@node2's password:
atguigu@node2's password:
sending incremental file list
my_env.sh
rsync: mkstemp "/etc/profile.d/.my_env.sh.guTzvB" failed: Permission denied (13)
sent 95 bytes received 126 bytes 88.40 bytes/sec
total size is 223 speedup is 1.01
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1178) [sender=3.1.2]
==================== node3 =========&#
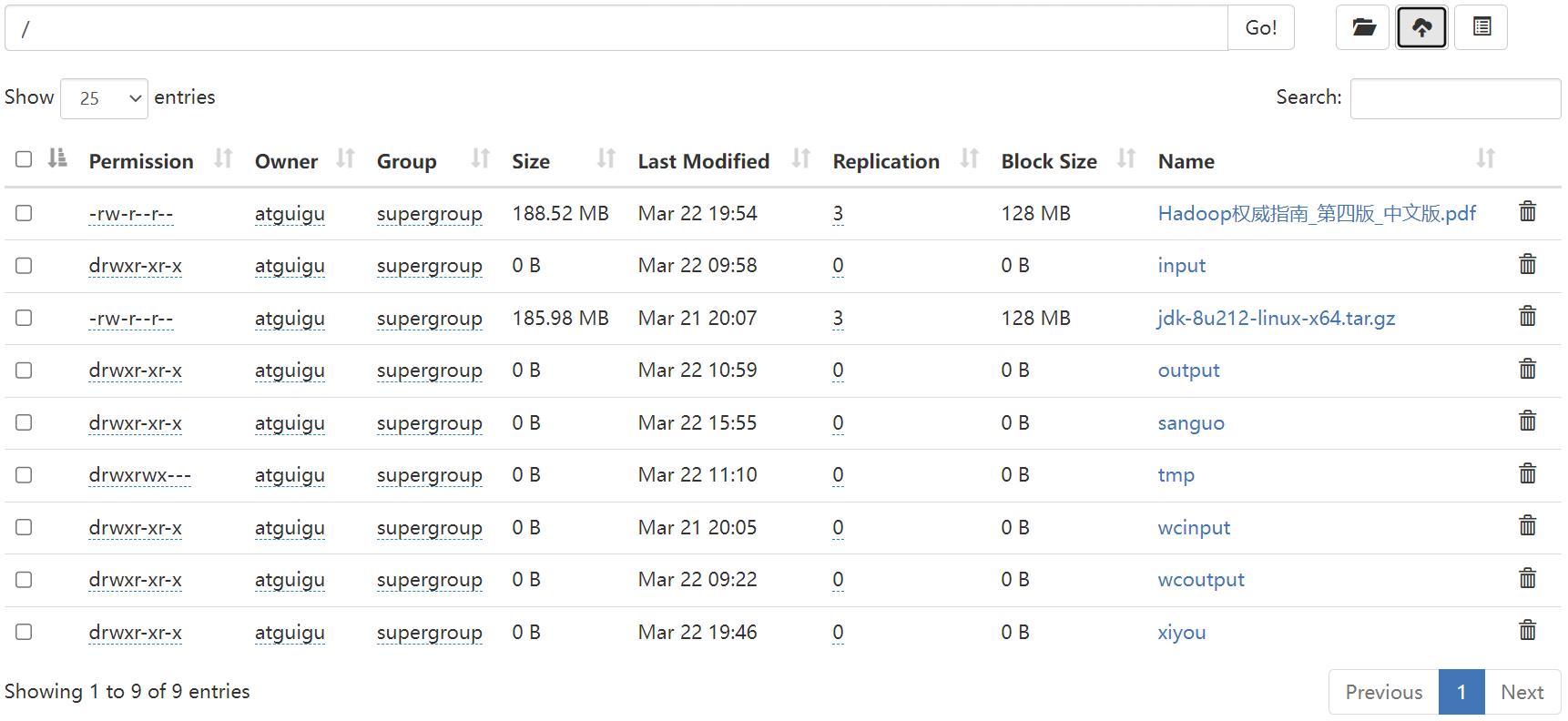
//文件下载
@Test
public void testGet() throws IOException
//参数的解读,参数一:原文件是否删除、参数二:原文件路径HDFS、参数三:Windows目标地址路径、参数四:crc校验
// fs.copyToLocalFile(false, new Path("hdfs://node1/xiyou/huaguoshan2/sunwukong.txt"), new Path("D:\\\\bigData\\\\file\\\\download"), false);
fs.copyToLocalFile(false, new Path("hdfs://node1/xiyou/huaguoshan2/"), new Path("D:\\\\bigData\\\\file\\\\download"), false);
// fs.copyToLocalFile(false, new Path("hdfs://node1/a.txt"), new Path("D:\\\\"), false);