GlusterFS脑裂案例-brick中的存储数据不一致
Posted EbowTang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GlusterFS脑裂案例-brick中的存储数据不一致相关的知识,希望对你有一定的参考价值。
问题描述:
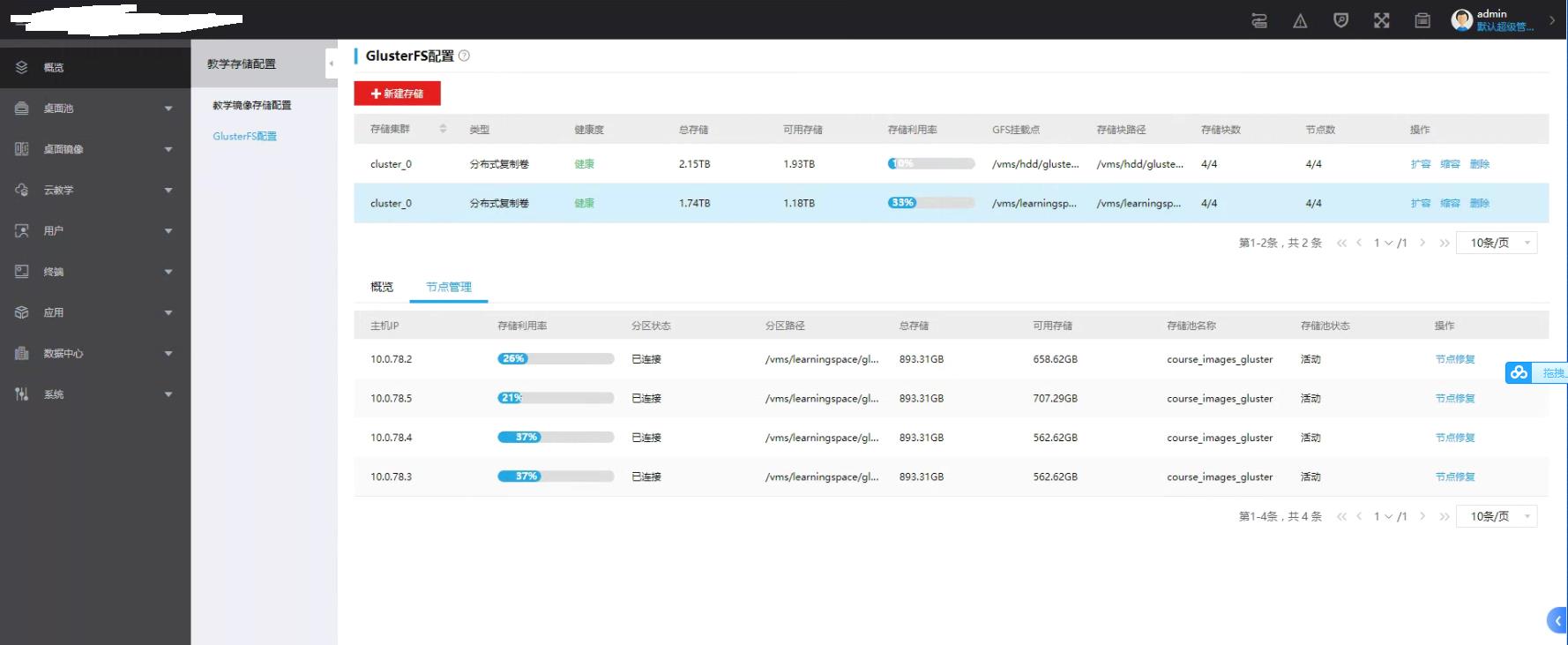
四主机集群,2副本的GlusterFS,某个学校年前将服务器关机,开学后将服务器开机,登录管理平台发现,两个glusterfs存储卷,均显示主机存储池不活动,且存储卷异常(不健康)(下图是修复好一个后截的图,仅示例)
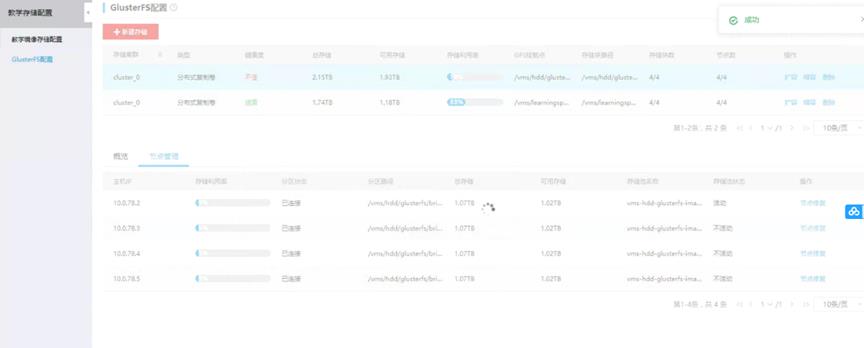
处理步骤:
这个集群服务器上有两个glusterfs存储卷,首先检查其中一个glusterfs存储卷(hdd磁盘创建的卷),通过下面的状态快速检查节点和存储卷状态,然后再尝试查看日志(本案例直接通过查询状态检查出了问题)。
1,查看brick连接是否正常,是否脑裂
# gluster volume heal volume_name info
2,查看卷是否在平衡状态中
# gluster volume rebalance volume_name status
3,查看集群中的卷信息和状态:
# gluster volume info
4,查看所有节点的基本状态(显示的时候不包括本节点):
# gluster peer status
第一个存储卷的状态关键截图如下,未现异常
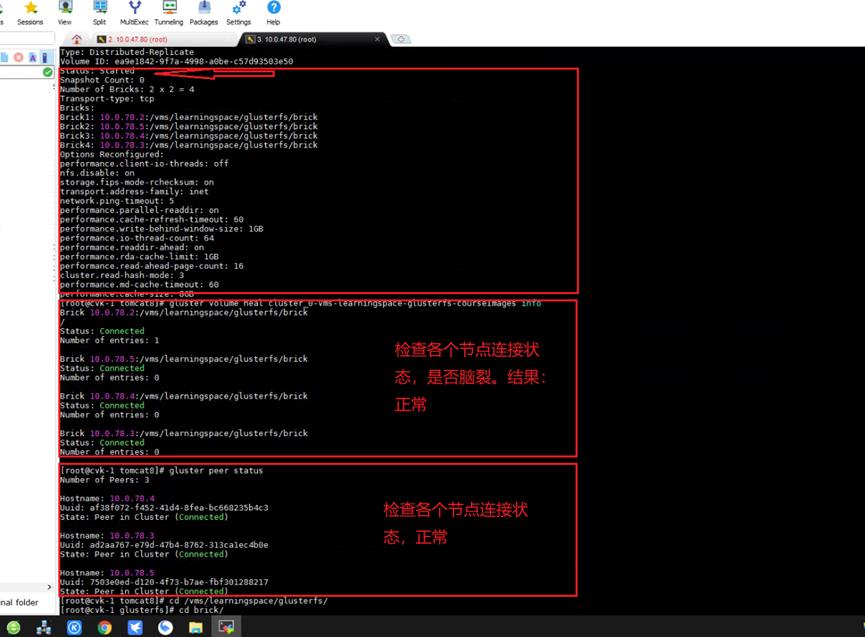
因此直接到管理平台前端尝试修复,发现可以直接修复成功(当存储池不活动,或者未创建,该修复按钮可以创建或者去启动不活动的存储池),最终该存储卷通过前端修复直接恢复正常:
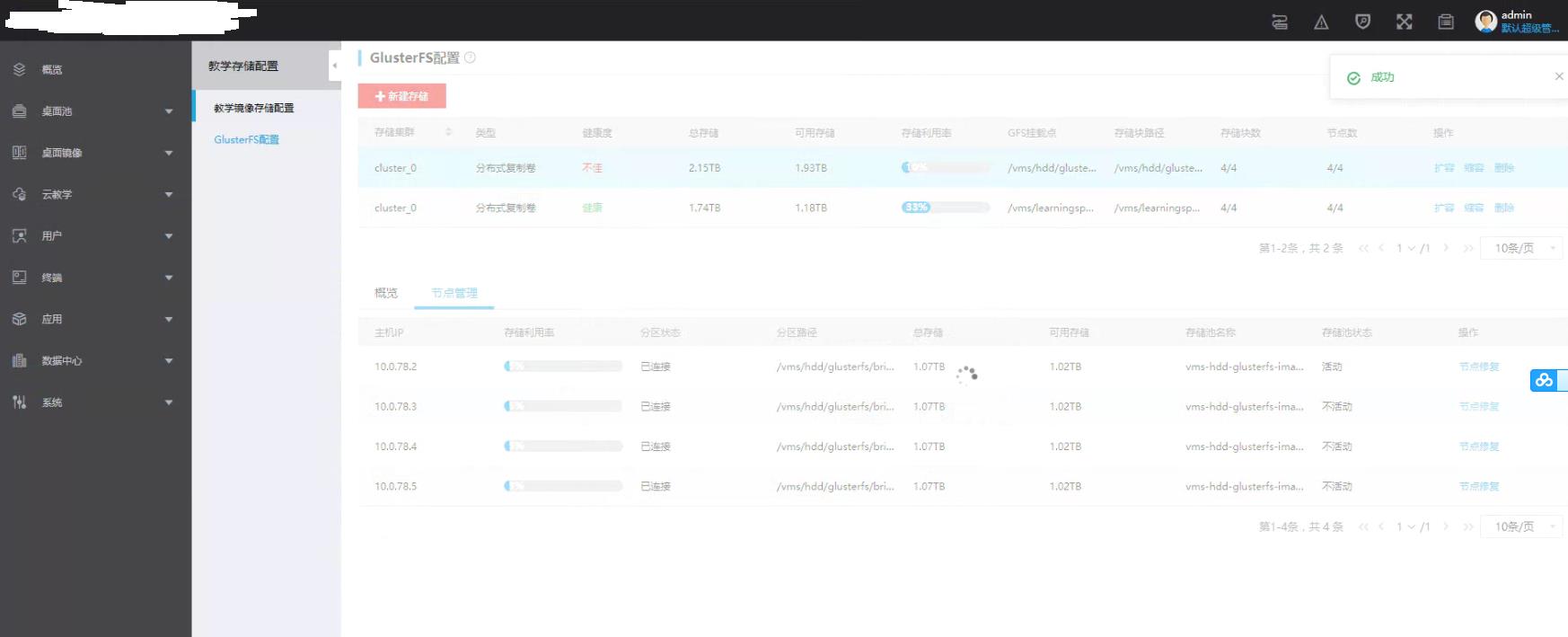
但是第二个存储卷(SSD磁盘创建的卷)无法直接修复成功。
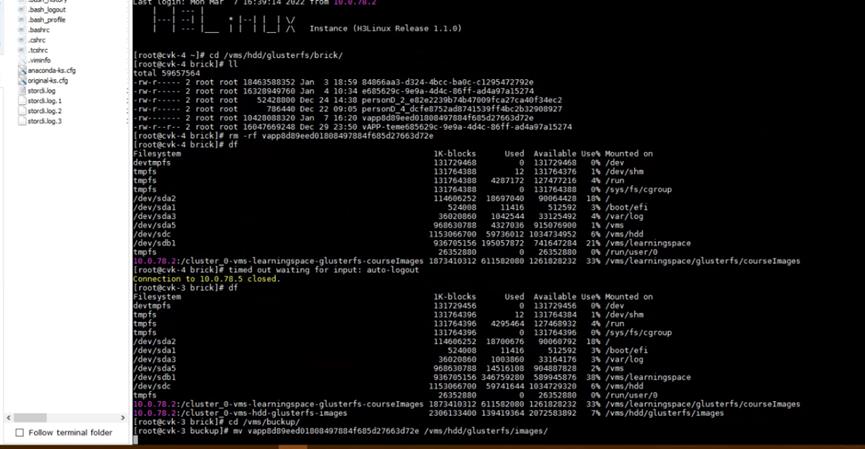
因此再次使用上面的检查命令排查一下环境状态,发现脑裂了,glusterfs发现一个镜像文件的在两个副本下表现不一致(通过文件大小就可以看出),不知道用哪个文件,就认为该文件处于脑裂状态,最终导致存储池启动异常。
# gluster volume heal volume_name info //检查脑裂和节点连接状态
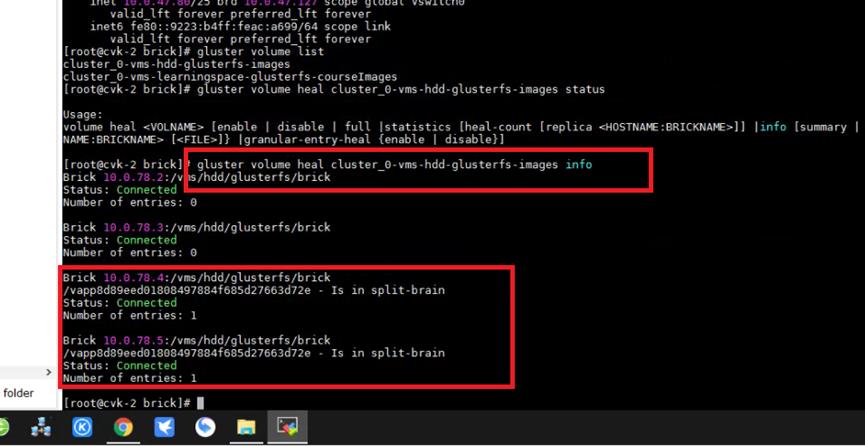
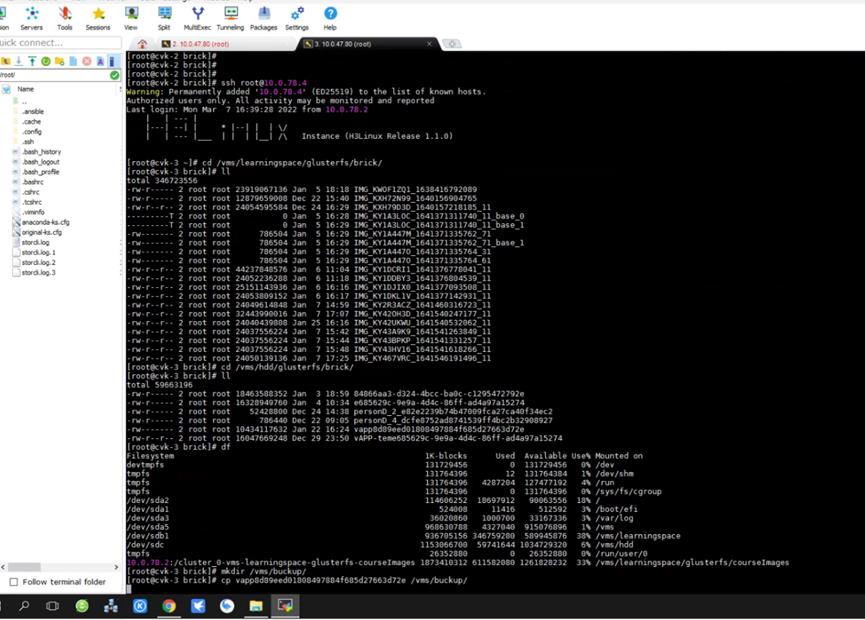
处理方法很简单,将副本对任意一个brick下的该脑裂文件备份,然后副本对上均删除该文件。
然后再到管理平台点击手动修复,直到恢复正常,
最后再将该文件移动到存储卷中,彻底恢复如初
问题原因:
GlusterFS脑裂一般是网络原因造成,本问题未做深究
以上是关于GlusterFS脑裂案例-brick中的存储数据不一致的主要内容,如果未能解决你的问题,请参考以下文章