DBSCAN聚类以及sklearn库代码实现
Posted Icy Hunter
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DBSCAN聚类以及sklearn库代码实现相关的知识,希望对你有一定的参考价值。
DBSCAN聚类是一种基于样本密度的聚类方式,同时能够允许样本不被聚到任何类别之中,从而我们可以利用DBSCAN聚类来帮助我们找出一些离群点,即异常值检测。
首先给出一些相关概念





因此,DBSCAN算法的伪代码如下:


直接看变量意思不太能反应过来,稍微写写大概就懂了。
思路就是先确定核心对象,然后再随机从核心对象出发计算密度可达的样本,即一直判断核心对象邻域的样本是否还是核心对象,如果是核心对象,那么就把未访问过的样本入队,如果不是了,那么此样本就为这一簇目前的边界了,就不会往外延申了。最后将开始找到的核心对象的集合中减去目前已经形成一簇中的核心对象。然后再从剩下的核心对象继续随机选取计算,循环往复,直到核心对象的集合为空时,聚类结束,而哪些未被核心对象邻域所包含的点,就为离散点了。
代码如下:
import numpy as np
from sklearn.cluster import DBSCAN
from sklearn import metrics
from sklearn.datasets import make_blobs
from sklearn.preprocessing import StandardScaler
# 生成750个3个聚类中心的数据集
centers = [[1, 1], [-1, -1], [1, -1]]
X, labels_true = make_blobs(
n_samples=750, centers=centers, cluster_std=0.4, random_state=0
)
# 数据标准化
X = StandardScaler().fit_transform(X)
# DBSCAN聚类
# eps为邻域半径
# min_samples为确定为核心对象的最小样本数据,即当一个点在他eps半径的区域内共有10个点(包括他自己),那么这个点被确定为核心对象
db = DBSCAN(eps=0.3, min_samples=10).fit(X)
# 找出所有核心点,可视化时图片放大
core_samples_mask = np.zeros_like(db.labels_, dtype=bool)
core_samples_mask[db.core_sample_indices_] = True
labels = db.labels_
# 聚类标签数以及噪声点数
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
n_noise_ = list(labels).count(-1)
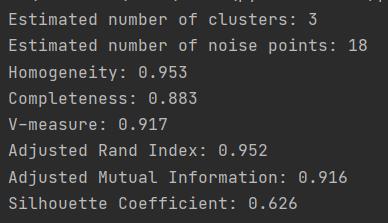
print("Estimated number of clusters: %d" % n_clusters_) # 输出聚类的簇数
print("Estimated number of noise points: %d" % n_noise_) # 输出噪声点个数
# 需要有正确的标签
print("Homogeneity: %0.3f" % metrics.homogeneity_score(labels_true, labels)) # 同质性homogeneity:每个群集只包含单个类的成员。
print("Completeness: %0.3f" % metrics.completeness_score(labels_true, labels)) # 完整性completeness:给定类的所有成员都分配给同一个群集。
print("V-measure: %0.3f" % metrics.v_measure_score(labels_true, labels)) # 两者的调和平均V-measure:
print("Adjusted Rand Index: %0.3f" % metrics.adjusted_rand_score(labels_true, labels)) # 调整兰德系数,ARI取值范围为[−1,1],值越大意味着聚类结果与真实情况越吻合。从广义的角度来讲,ARI衡量的是两个数据分布的吻合程度。
print(
"Adjusted Mutual Information: %0.3f"
% metrics.adjusted_mutual_info_score(labels_true, labels)
) # 互信息(Mutual Information)也是用来衡量两个数据分布的吻合程度。利用基于互信息的方法来衡量聚类效果需要实际类别信息,MI与NMI取值范围为[0,1],AMI取值范围为[−1,1],它们都是值越大意味着聚类结果与真实情况越吻合。
# 不需要有正确的标签
print("Silhouette Coefficient: %0.3f" % metrics.silhouette_score(X, labels)) # 轮廓系数(Silhouette coefficient)适用于实际类别信息未知的情况。对于一个样本集合,它的轮廓系数是所有样本轮廓系数的平均值。
# 轮廓系数取值范围是[−1,1],同类别样本越距离相近且不同类别样本距离越远,分数越高。
# #############################################################################
# Plot result
import matplotlib.pyplot as plt
# Black removed and is used for noise instead.
unique_labels = set(labels)
colors = [plt.cm.Spectral(each) for each in np.linspace(0, 1, len(unique_labels))]
for k, col in zip(unique_labels, colors):
if k == -1:
# Black used for noise.
col = [0, 0, 0, 1]
class_member_mask = labels == k
xy = X[class_member_mask & core_samples_mask]
plt.plot(
xy[:, 0],
xy[:, 1],
"o",
markerfacecolor=tuple(col),
markeredgecolor="k",
markersize=14,
)
xy = X[class_member_mask & ~core_samples_mask]
plt.plot(
xy[:, 0],
xy[:, 1],
"o",
markerfacecolor=tuple(col),
markeredgecolor="k",
markersize=6,
)
plt.title("Estimated number of clusters: %d" % n_clusters_)
plt.show()`
运行结果

图中大圆为核心对象,小圆为非核心对象,黑点为离散点即不属于任何一类。
本文参考:周志华-机器学习;
https://scikit-learn.org/stable/auto_examples/cluster/plot_dbscan.html#sphx-glr-auto-examples-cluster-plot-dbscan-py;
机器学习评价指标大汇总
以上是关于DBSCAN聚类以及sklearn库代码实现的主要内容,如果未能解决你的问题,请参考以下文章