如何在已有CM集群环境中添加kafka组件
Posted 彭宇成
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何在已有CM集群环境中添加kafka组件相关的知识,希望对你有一定的参考价值。
参考
场景
怎么局部升级当前cm集群呢,比如添加kafka组件、spark组件等
分析
一、升级原因
1、 现有集群组件只能做一些离线类统计分析,无法满足当前实时类业务计算的需求。
2、 现有集群计算引擎是基于MR2,计算能力相对较弱。
综合以上因素,决定在已有的集群组件中添加 : flume、kafka 与 spark 组件,以期提升集群的计算能力,满足当前实时计算的业务需求。
二、升级过程
1 、spark组件的添加
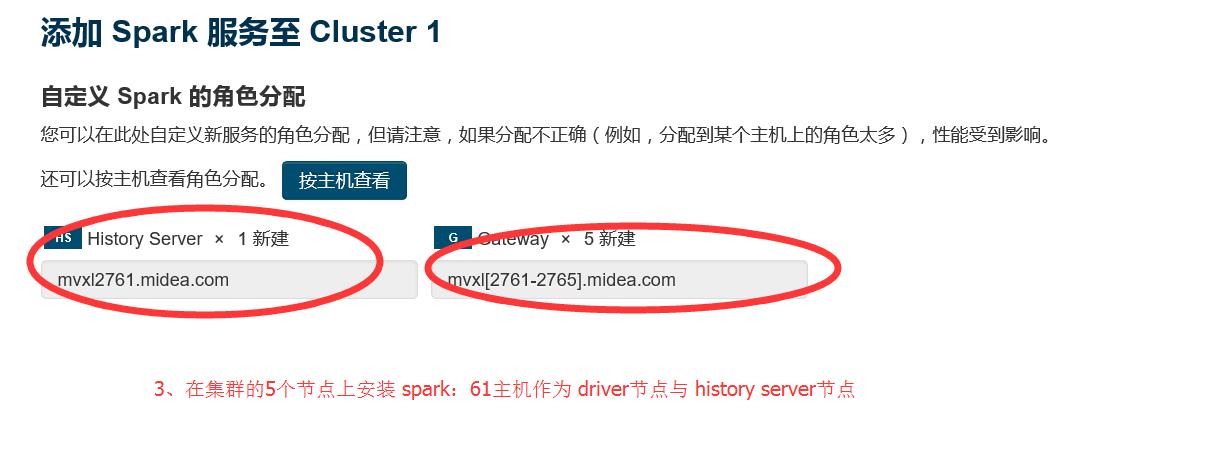
在集群的每个节点上安装 spark 组件,以YARN模式管理计算资源
1.1 在 CM主页选择添加服务

1.2 添加spark组件

1.3 选择要安装spark服务的节点
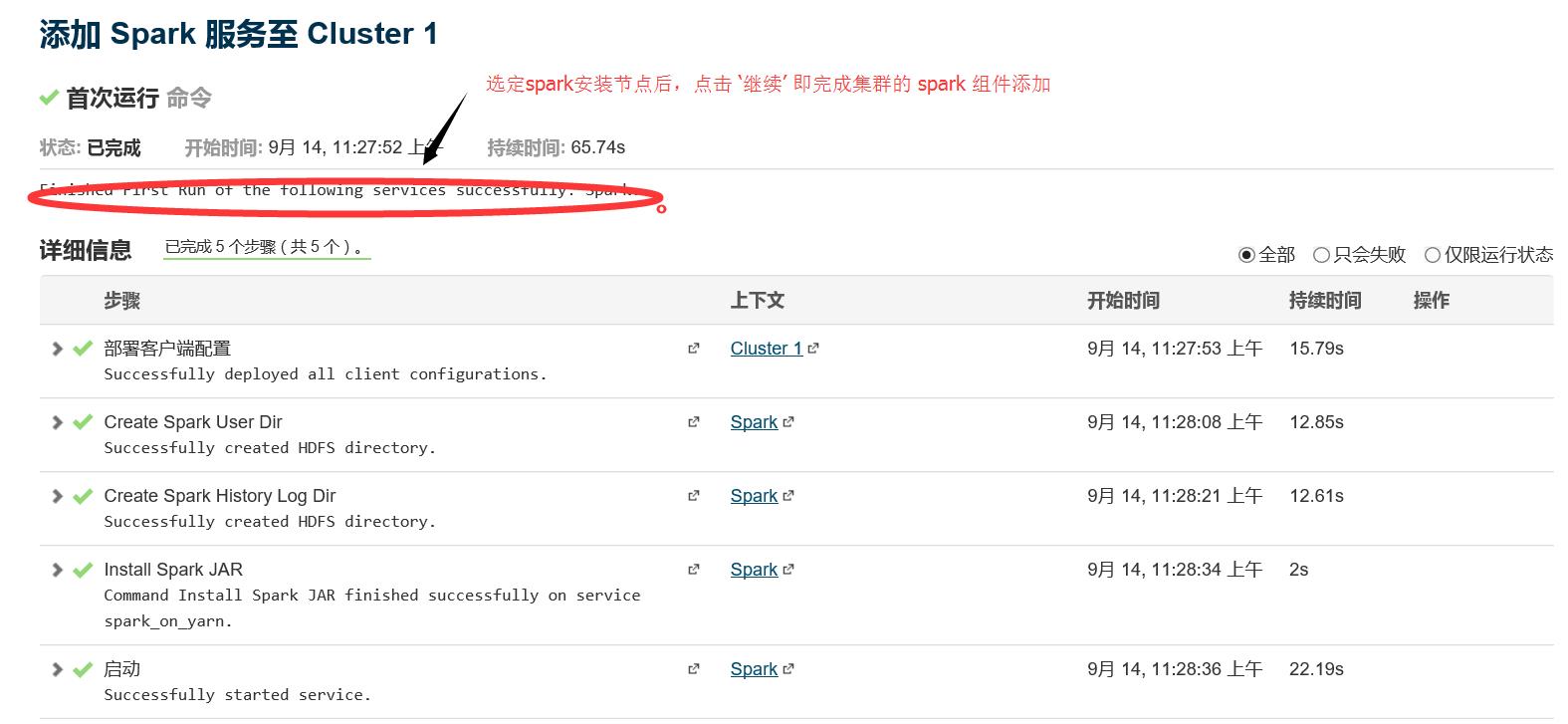
1.4 安装完毕
2、 kafka组件的添加
kafka组件的安装,可分为在线与离线安装,这里采用在线安装的方式进行,具体安装步骤如下:
2.1 进入 Parcel 主页
2.2 与 2.3 进入 Parcel配置界面

2.4 在Parcel主界面点击 ‘检查更新Parcel’

2.5 激活 kafka 组件

2.6 在CM主页添加 kafka服务

2.7 选择需要安装kafka组件的集群节点 ,相关配置都选择默认的
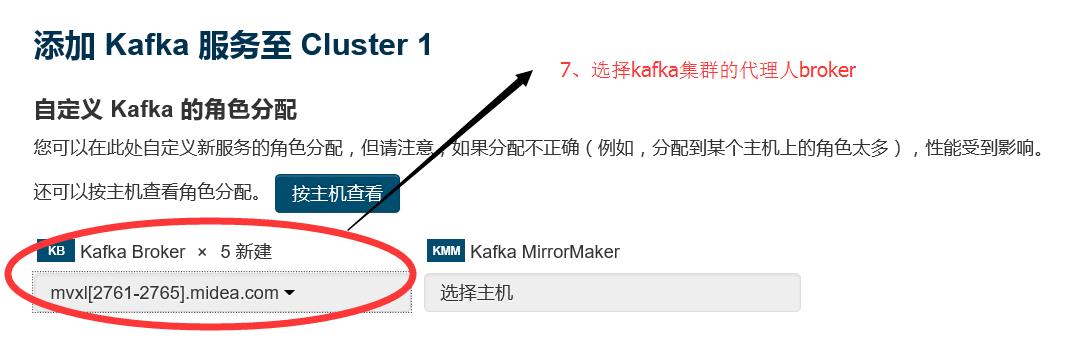
2.8 启动 kafka 集群
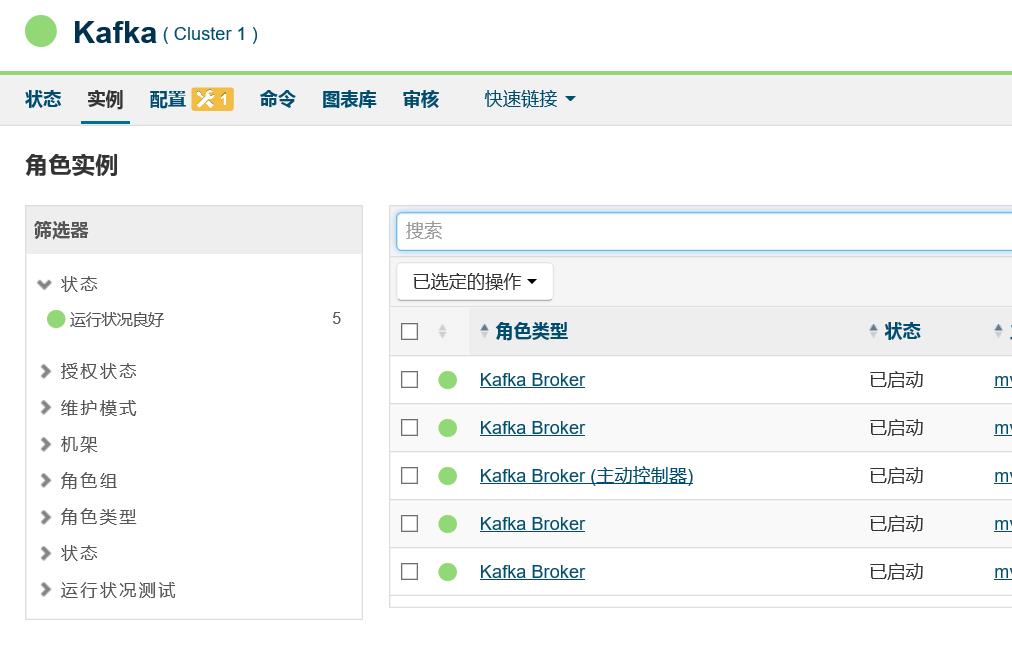
注意: 启动kafka集群的时候,可能出现如下异常 :
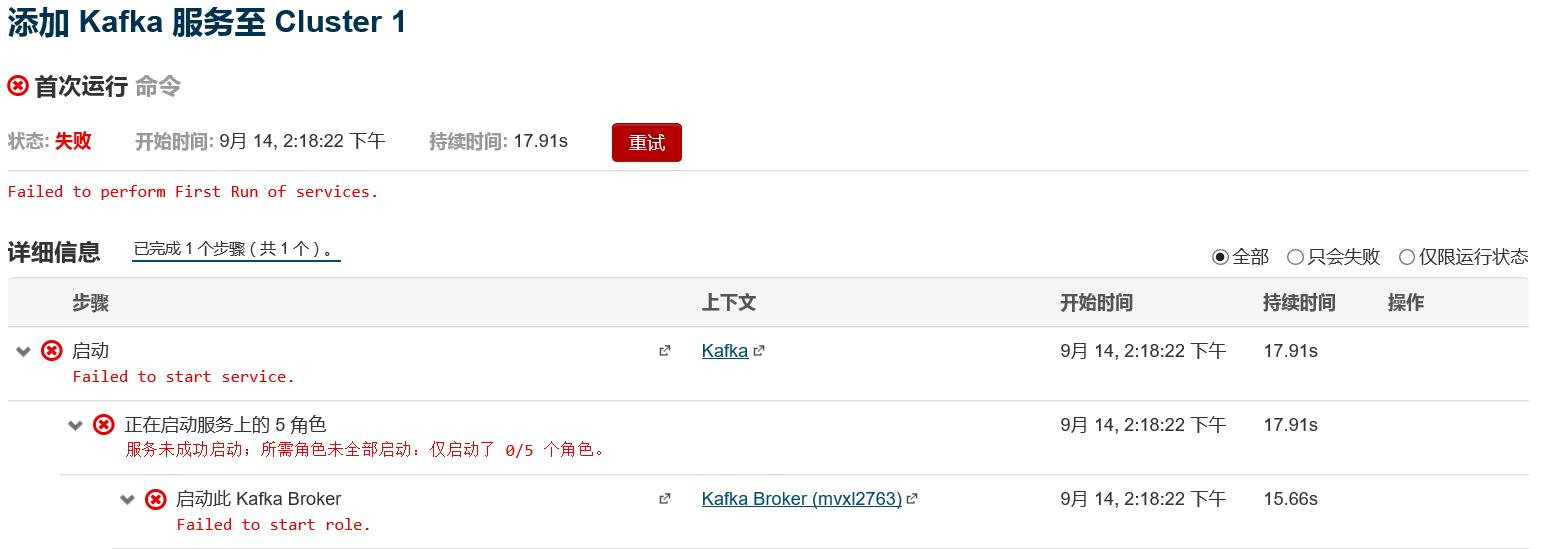
在CM 界面中查看 broker的异常日志后,发现:OutofMemeryException
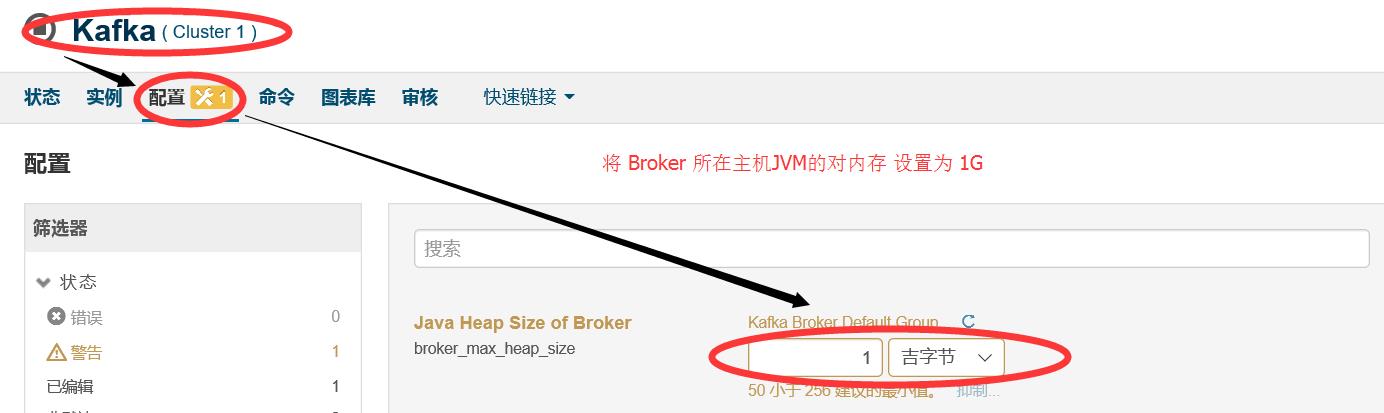
这是因为 Java Heap size of Broker这个选项默认配置是 50M ,需要将其修改成 256M 或者 更多,这里修改成 1G ,保存配置后,在启动kafka集群即可:
三、升级后的集群组件配置状况
生产环境 5 台 32核 256G ,处理一般复杂度的spark作业,能处理的最大数据规模是多大呢? 这个没法量化,以后遇到具体性能问题,再具体分析、优化。
以往的经验:5台8核16G的集群资源,编写一般复杂度的spark作业,处理 10G(大概一亿行数据量)级别的数据量,处理时间是 10分钟级别。
总结
开启集群资源管理之路,漫长啊 。。。
以上是关于如何在已有CM集群环境中添加kafka组件的主要内容,如果未能解决你的问题,请参考以下文章