为什么用PyTorch?PyTorch如何支持深度学习?
Posted 人邮异步社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为什么用PyTorch?PyTorch如何支持深度学习?相关的知识,希望对你有一定的参考价值。
为什么用PyTorch
通过将模型应用到例证,深度学习允许我们执行很多复杂任务,如机器翻译、玩战略游戏以及在杂乱无章的场景中识别物体等。为了在实践中做到这一点,我们需要灵活且高效的工具,以便能够适用于这些复杂任务,能够在合理的时间内对大量数据进行训练。我们需要已被训练过的模型在输入变量变化的情况下正确执行。接下来看看我们决定使用PyTorch的一些原因。
PyTorch很容易被推广,因为它很简单。许多研究人员和实践者发现它易于学习、使用、扩展和调试。它是Python化的,虽然和任何复杂领域一样,它有注意事项和最佳实践示例,但对于以前使用过Python的开发人员来说,使用该库和使用其他Python库一样。
更具体地说,在PyTorch中编写深度学习机是很自然的事情。PyTorch为我们提供了一种数据类型,即张量,通常用来存储数字、向量、矩阵和数组。此外,PyTorch还提供了操作它们的函数,我们可以使用这些函数来增量编程。如果我们愿意,还可以进行交互式编程,就像平常使用Python一样。如果你知道NumPy,那么你对交互式编程应是非常熟悉的。
PyTorch具备2个特性,使得它与深度学习关联紧密。首先,它使用GPU加速计算,通常比在CPU上执行相同的计算速度快50倍。其次,PyTorch提供了支持通用数学表达式数值优化的工具,该工具用于训练深度学习模型。请注意,这2个特性适用于一般的科学计算,而不只适用于深度学习。事实上,我们完全可以将PyTorch描述为一个在Python中为科学计算提供优化支持的高性能库。
PyTorch设计的驱动因素之一是表现力,它允许开发人员实现复杂的模型,而不会被PyTorch库强加过高的复杂性(PyTorch不是一个框架)。PyTorch可以说是最无缝地将深度学习领域的思想转化为Python代码的软件之一。因此,PyTorch在研究中得到广泛的采用,国际会议上的高引用次数就证明了这一点[3]。
PyTorch从研发到成为产品的过程是一件值得关注的事情。虽然PyTorch最初专注于研究工作流,但它已经配备了高性能的C++运行环境,用于部署模型进行推理而不依赖Python,并且还可用于设计和训练C++模型。它还提供了与其他语言的绑定,以及用于部署到移动设备的接口。这些特性允许我们利用PyTorch的灵活性,还允许我们的程序在难以获得完整的Python运行环境或可能需要极大的开销的情况下运行。
当然,易用性和高性能是很容易做到的,我们希望当你深入阅读本书的时候,会认同这句话。
深度学习竞争格局
虽然所有的类比都有瑕疵,但2017年1月PyTorch 0.1的发布标志着深度学习库、包装器和数据交换格式从“寒武纪”爆炸式增长过渡到一个整合和统一的时代。
注意
当前深度学习发展迅速,以至于当你读到本书的印刷版时,它可能已经过时了。如果你不了解这里提到的一些库也很正常。
PyTorch第1个测试版本发布时情况如下。
- Theano和TensorFlow是最早的低级别库,它们使用一个模型,该模型让用户自定义一个计算图,然后执行它。
- Lasagne和Keras是Theano的高级包装器,同时Keras还对TensorFlow和CNTK进行了包装。
- Caffe、Chainer、DyNet、Torch(以Lua为基础的PyTorch前身)、MXNet、CNTK、DL4J等库在深度学习生态系统中占据了不同的位置。
在接下来大约2年的时间里,情况发生了巨大的变化。除了一些特定领域的库,随着其他深度学习库使用量的减少,PyTorch和TensorFlow社区的地位得到了巩固。变化情况可以总结为以下几点。
- Theano是最早的深度学习框架之一,目前它已经停止开发。
- TensorFlow:完全对Keras进行封装,将其提升为一流的API;提供了一种立即执行的“急切模式(eager mode)”,这种模式有点儿类似于PyTorch处理计算的方式;TensorFlow 2.0默认采用急切模式。
- JAX是谷歌的一个库,它是独立于TensorFlow开发的,作为一个与GPU、Autograd和JIT编译器具有对等功能的NumPy库,它已经开始获得关注。
- PyTorch:Caffe2完全并入PyTorch,作为其后端模块;替换了从基于Lua的Torch项目重用的大多数低级别代码;增加对开放式神经网络交换(Open Neural Network Exchange,ONNX)的支持,这是一种与外部框架无关的模型描述和交换格式;增加一种称为“TorchScript”的延迟执行的“图模型”运行环境;发布了1.0版本;取代CNTK和Chainer成为各自企业赞助商选择的框架。
TensorFlow拥有强大的生产线、广泛的行业社区以及巨大的市场份额。由于使用方便,PyTorch在研究和教学领域取得了巨大进展,并且随着研究人员和毕业的学生进入该行业,PyTorch的势头越来越好。它还在生产解决方案方面积累了经验。有趣的是,随着TorchScript和急切模式的出现,PyTorch和TensorFlow的特征集开始趋同,尽管在这些特征的呈现和整体体验上仍然存在很大的差异。
PyTorch如何支持深度学习概述
我们已经提及了PyTorch的一些构成要素,接下来我们将正式介绍PyTorch的主要组件的高级映射。我们可以通过查看一个PyTorch深度学习项目所需要的组件来更好地了解这些内容。
首先,正如Python一样,PyTorch有一个扩展名为“.py”的文件,但在该文件中有很多非Python代码。事实上,由于性能原因,PyTorch大部分是用C++和CUDA编写的,CUDA是一种来自英伟达的类C++的语言,可以被编译并在GPU上以并行方式运行。有一些方法可以直接在C++环境中运行PyTorch,我们将在第15章中讨论这些方法。此功能的动机之一是为生产环境中部署模型提供可靠的策略。但是,大多数情况下我们都是使用Python来与PyTorch交互的,包括构建模型、训练模型以及使用训练过的模型解决实际问题等。
实际上,Python API正是PyTorch在可用性以及与更广泛Python生态系统集成方面的亮点。让我们来看看PyTorch的心智模型。
正如我们前面已经提到的那样,PyTorch的核心是一个提供多维数组(张量)以及由torch模块提供大量操作的库。张量及操作可以在CPU或GPU上使用。在PyTorch中,将运算从CPU转移到GPU不需要额外的函数调用。PyTorch提供的第2个核心功能是张量可以跟踪对其执行的操作的能力,并分析和计算任何输入对应的输出的导数。该功能用于数值优化,是由张量自身提供的,通过PyTorch底层自动求导引擎来调度。
通过使用张量以及张量自动求导的标准库,PyTorch可以用于物理学、渲染、优化、仿真、建模等,而且我们很可能会看到PyTorch在科学应用的各个领域以创造性的方式使用。但PyTorch首先是一个深度学习库,因此它提供了构建和训练神经网络所需的所有构建模块。图1.2展示了完成一个深度学习项目的标准步骤,从加载数据到训练模型,最后将该模型部署到生产中。
用于构建神经网络的PyTorch核心模块位于torch.nn中,它提供了通用的神经网络层和其他架构组件。全连接层、卷积层、激活函数和损失函数都可以在这里找到(在本书剩余部分,我们将详细地介绍这些内容)。这些组件可用于构建和初始化图1.2所示的未训练的模型。为了训练模型,我们需要一些额外的东西:模型训练的数据源、一个使模型适应训练数据的优化器,以及一种把模型和数据传输到硬件的方法,该硬件用于执行模型训练所需的计算。
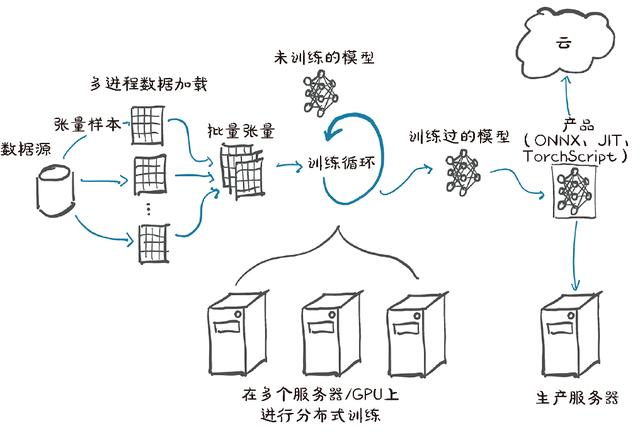
图1.2 PyTorch项目的基础、高级结构,包括数据加载、训练和生产部署等
在图1.2的左侧,我们看到训练数据在到达模型之前,需要进行大量的数据处理[4]。首先,我们需要从外部获取数据,通常是从作为数据源的某种存储中获取数据。然后我们需要将数据中的每个样本转换成PyTorch可以处理的张量。数据预处理是我们自定义数据(无论什么样的格式)与PyTorch中torch.utils.data包下的Dataset类提供的标准张量之间的桥梁。由于不同问题处理过程截然不同,因此我们需要自己定义数据源。在第4章中,我们将详细介绍如何将各种类型的数据表示为张量。
由于数据存储通常很慢,还存在访问延迟,因此我们希望并行化数据加载。但是,由于Python提供的许多操作都不具有简单、高效的并行处理能力,因此我们需要多个进程来加载我们的数据,以便将它们组装成一个批次,即组装成一个包含多个样本的张量。这是相当复杂的,但由于它也是相对通用的,PyTorch很容易在DataLoader类中实现这些功能。它的实例可以生成子进程在后台从数据集中加载数据,提前将数据准备就绪,一旦训练循环开始就可以立即使用。我们将在第7章介绍和使用Dataset和DataLoader。
有了获取成批样本的机制,我们可以转向图1.2中心的训练循环。通常训练循环被实现为标准的Python for循环。在最简单的情况下,模型在本地CPU或单个GPU上执行所需的计算,一旦训练循环获得数据,计算就可以立即开始。很可能这就是你的基本设置,也是我们在本书中假设的设置。
在训练循环的每个步骤中,我们根据从数据加载器获得的样本来评估模型。然后我们使用某种准则或损失函数将模型的输出与期望的输出(目标)进行比较。PyTorch除了提供构建模型的组件,也有各种损失函数供我们使用,torch.nn包中也提供这些函数。在我们用损失函数将实际输出与期望的输出进行比较之后,我们需要稍微修改模型以使其输出更接近目标。正如前面提到的,这正是PyTorch底层的自动求导引擎的用武之地。但是我们还需要一个优化器来进行更新,这是PyTorch在torch.optiom中为我们提供的。在第5章中,我们将开始研究带有损失函数和优化器的训练循环,然后在第2部分开始我们的大项目之前,即在第6章到第8章中先训练一下我们使用PyTorch的技能。
使用更精细的硬件越来越普遍,如多GPU或多个服务器,将这些资源用于训练大型模型,如图1.2的底部中间部分所示。在这些情况下,
torch.nn.parallel.DistributedDataParallel和torch. distributed子模块可用于使用附加的硬件。
训练循环可能是深度学习项目中最乏味和耗时的部分。训练循环结束后,我们将得到一个模型,该模型的参数已经在我们的任务上得到了优化,如图1.2训练循环右侧部分所示的训练过的模型。有一个用来解决任务的模型是很好的,但是为了使它有用,我们需要将其放在需要工作的地方。如图1.2所示,在其右侧所示的部署部分可能涉及将模型放在生产服务器上,或将模型导出到云中,或者我们可将它与更大的应用程序集成,抑或在手机上运行它。
部署操作中一个特定的步骤是导出模型。如前所述,PyTorch默认为立即执行模式(急切模式)。每当Python解释器执行一个包含“PyTorch”的指令,相应的操作就会立即被底层的C++或CUDA的实现来执行。随着对张量进行操作的指令越来越多,后端实现将执行更多的操作。
PyTorch还提供了一种通过TorchScript提前编译模型的方法。使用TorchScript,PyTorch可以将模型序列化为一组独立于Python调用,如在C++程序或在移动设备上调用的指令集。我们可以把模型想象成一个具有有限指令集的虚拟机,用于特定的张量操作。这允许我们导出我们的模型,或者将其作为用于PyTorch运行时的TorchScript导出,或者将其以一种称为ONNX的标准格式导出。这些特性是PyTorch生产部署的基础,我们将在第15章中进行介绍。
本文摘自《PyTorch深度学习实战》

本书并不是一本参考书,相反,它是一本概念性的指南,旨在引导你在网上独立探索更高级的材料。因此,我们关注的是PyTorch提供的一部分特性,最值得注意的是循环神经网络,但PyTorch API的其他部分也同样值得重视。
本书指导读者使用Python和PyTorch实现深度学习算法。本书首先介绍PyTorch的核心知识,然后带领读者体验一个真实的案例研究项目:构建能够使用CT扫描检测恶性肺肿瘤的算法。你将学习用有限的输入训练网络,并处理数据,以获得一些结果。你将筛选出不可靠的初始结果,并专注于诊断和修复神经网络中的问题。最后,你将研究通过增强数据训练、改进模型体系结构和执行其他微调来改进结果的方法。通过这个真实的案例,你会发现PyTorch是多么有效和有趣,并掌握在生产中部署PyTorch模型的技能。
本书适合具有一定Python知识和基础线性代数知识的开发人员。了解深度学习的基础知识对阅读本书有一定的帮助,但读者无须具有使用PyTorch或其他深度学习框架的经验。
以上是关于为什么用PyTorch?PyTorch如何支持深度学习?的主要内容,如果未能解决你的问题,请参考以下文章