PointRCNN的loss计算与推理实现
Posted NNNNNathan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PointRCNN的loss计算与推理实现相关的知识,希望对你有一定的参考价值。
在我前面的文章中,已经完成了PointRCNN的网络构建,链接在这:
 https://blog.csdn.net/qq_41366026/article/details/123214165?spm=1001.2014.3001.5501
https://blog.csdn.net/qq_41366026/article/details/123214165?spm=1001.2014.3001.5501注:OpenPCDet的损失实现已与原论文和原代码仓库不同,网络构建时候已经叙述过此问题。同时原来的实现中,PointRCNN是分阶段训练,先训练第一阶段之后在训练第二阶段网络。但是在OpenPCDet已经变成联合训练。
1、loss计算
1、第一阶段loss计算
第一阶段的损失包含了两部分:
1. 对该帧中所有的点云计算前背景分类loss
2. 对属于前景的点云计算box的回归loss
1.1 前背景分类loss计算
由于在一帧点云中属于前背景点的数量差异较大,作者在此处使用了Focal Loss:
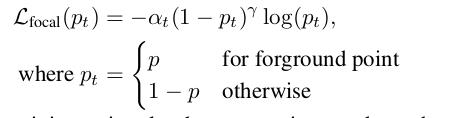
其中alpha和gamma都与RetinaNet中保持一致,分别为0.25、2。
在计算前背景点的分类loss时,对每个GT enlarge 0.2米后才包括的点,类别置为-1,不计算这些点的分类loss,来提高网络的泛化性,网络构建已经有提到过。
代码在:pcdet/models/dense_heads/point_head_template.py
每个proposal与之对应的GT,
其中IOU大于0.6为前景,数值为1
0.45-0.6忽略不计算loss,数值为-1
0.45为背景,数值为0
def get_cls_layer_loss(self, tb_dict=None):
# 第一阶段点的GT类别
point_cls_labels = self.forward_ret_dict['point_cls_labels'].view(-1)
# 第一阶段点的预测类别
point_cls_preds = self.forward_ret_dict['point_cls_preds'].view(-1, self.num_class)
# 取出属于前景的点的mask,0为背景,1,2,3分别为前景,-1不关注
positives = (point_cls_labels > 0)
# 背景点分类权重置0
negative_cls_weights = (point_cls_labels == 0) * 1.0
# 前景点分类权重置0
cls_weights = (negative_cls_weights + 1.0 * positives).float()
# 使用前景点的个数来normalize,使得一批数据中每个前景点贡献的loss一样
pos_normalizer = positives.sum(dim=0).float()
# 正则化每个类别分类损失权重
cls_weights /= torch.clamp(pos_normalizer, min=1.0)
# 初始化分类的one-hot (batch * 16384, 4)
one_hot_targets = point_cls_preds.new_zeros(*list(point_cls_labels.shape), self.num_class + 1)
# 将目标标签转换为one-hot编码形式 https://blog.csdn.net/guofei_fly/article/details/104308528
one_hot_targets.scatter_(-1, (point_cls_labels * (point_cls_labels >= 0).long()).unsqueeze(dim=-1).long(), 1.0)
# 原来背景为[1, 0, 0, 0] 现在背景为[0, 0, 0]
one_hot_targets = one_hot_targets[..., 1:]
# 计算分类损失使用focal loss
cls_loss_src = self.cls_loss_func(point_cls_preds, one_hot_targets, weights=cls_weights)
# 各类别loss置求总数
point_loss_cls = cls_loss_src.sum()
# 分类损失权重
loss_weights_dict = self.model_cfg.LOSS_CONFIG.LOSS_WEIGHTS
# 分类损失乘以分类损失权重
point_loss_cls = point_loss_cls * loss_weights_dict['point_cls_weight']
if tb_dict is None:
tb_dict =
# 使用.item()将tensor转换成标量,抛弃Backward属性,可以优化显存,
tb_dict.update(
'point_loss_cls': point_loss_cls.item(),
'point_pos_num': pos_normalizer.item()
)
return point_loss_cls, tb_dictFocal Loss计算代码在:pcdet/utils/loss_utils.py
def sigmoid_cross_entropy_with_logits(input: torch.Tensor, target: torch.Tensor):
""" PyTorch Implementation for tf.nn.sigmoid_cross_entropy_with_logits:
max(x, 0) - x * z + log(1 + exp(-abs(x))) in
https://www.tensorflow.org/api_docs/python/tf/nn/sigmoid_cross_entropy_with_logits
Args:
input: (B, #anchors, #classes) float tensor.
Predicted logits for each class
target: (B, #anchors, #classes) float tensor.
One-hot encoded classification targets
Returns:
loss: (B, #anchors, #classes) float tensor.
Sigmoid cross entropy loss without reduction
"""
loss = torch.clamp(input, min=0) - input * target + \\
torch.log1p(torch.exp(-torch.abs(input)))
return loss
def forward(self, input: torch.Tensor, target: torch.Tensor, weights: torch.Tensor):
"""
Args:
input: (B, #anchors, #classes) float tensor. eg:(4, 321408, 3)
Predicted logits for each class :一个anchor会预测三种类别
target: (B, #anchors, #classes) float tensor. eg:(4, 321408, 3)
One-hot encoded classification targets,:真值
weights: (B, #anchors) float tensor. eg:(4, 321408)
Anchor-wise weights.
Returns:
weighted_loss: (B, #anchors, #classes) float tensor after weighting.
"""
pred_sigmoid = torch.sigmoid(input) # (batch_size, 321408, 3) f(x) = 1 / (1 + e^(-x))
# 这里的加权主要是解决正负样本不均衡的问题:正样本的权重为0.25,负样本的权重为0.75
# 交叉熵来自KL散度,衡量两个分布之间的相似性,针对二分类问题:
# 合并形式: L = -(y * log(y^) + (1 - y) * log(1 - y^)) <-->
# 分段形式:y = 1, L = -y * log(y^); y = 0, L = -(1 - y) * log(1 - y^)
# 这两种形式等价,只要是0和1的分类问题均可以写成两种等价形式,针对focal loss做类似处理
# 相对熵 = 信息熵 + 交叉熵, 且交叉熵是凸函数,求导时能够得到全局最优值-->(sigma(s)- y)x
# https://zhuanlan.zhihu.com/p/35709485
alpha_weight = target * self.alpha + (1 - target) * (1 - self.alpha) # (4, 321408, 3)
pt = target * (1.0 - pred_sigmoid) + (1.0 - target) * pred_sigmoid
focal_weight = alpha_weight * torch.pow(pt, self.gamma)
# (batch_size, 321408, 3) 交叉熵损失的一种变形,具体推到参考上面的链接
bce_loss = self.sigmoid_cross_entropy_with_logits(input, target)
loss = focal_weight * bce_loss # (batch_size, 321408, 3)
if weights.shape.__len__() == 2 or \\
(weights.shape.__len__() == 1 and target.shape.__len__() == 2):
weights = weights.unsqueeze(-1)
assert weights.shape.__len__() == loss.shape.__len__()
# weights参数使用正anchor数目进行平均,使得每个样本的损失与样本中目标的数量无关
return loss * weights1.2. 前景点回归loss计算
此处直接使用了SmoothL1损失计算前景点与GT直接的loss。对角度的编码使用了residual-cos-based的方法。所以这里的8个回归参数分别是:(x,y,z,l,w,h,cos(theta),sin(theta))
代码在:pcdet/models/dense_heads/point_head_template.py
def get_box_layer_loss(self, tb_dict=None):
# 使用GT来找出属于前景的点 (batch * 16384)
pos_mask = self.forward_ret_dict['point_cls_labels'] > 0
# 得到前景点的GT box参数 (batch * 16384, 8)
point_box_labels = self.forward_ret_dict['point_box_labels']
# 得到网络预测的前景点参数(batch * 16384, 8)
point_box_preds = self.forward_ret_dict['point_box_preds']
# 前景点的回归权重置1;背景点为0,不计算loss
reg_weights = pos_mask.float()
# 使用前景点的个数来normalize,使得一批数据中每个前景点贡献的loss一样
pos_normalizer = pos_mask.sum().float()
reg_weights /= torch.clamp(pos_normalizer, min=1.0)
# 使用带权重的SmoothL1Loss来计算第一阶段中box的回归损失
point_loss_box_src = self.reg_loss_func(
point_box_preds[None, ...], point_box_labels[None, ...], weights=reg_weights[None, ...]
)
# 求和
point_loss_box = point_loss_box_src.sum()
# 回归loss权重
loss_weights_dict = self.model_cfg.LOSS_CONFIG.LOSS_WEIGHTS
# 回归损失乘回归权重
point_loss_box = point_loss_box * loss_weights_dict['point_box_weight']
# 使用.item()将tensor转换成标量,抛弃Backward属性,可以优化显存,
if tb_dict is None:
tb_dict =
tb_dict.update('point_loss_box': point_loss_box.item())
return point_loss_box, tb_dictSmoothL1损失计算在:pcdet/utils/loss_utils.py
def smooth_l1_loss(diff, beta):
# 如果beta非常小,则直接用abs计算,否则按照正常的Smooth L1 Loss计算
if beta < 1e-5:
loss = torch.abs(diff)
else:
n = torch.abs(diff) # (batch_size, 321408, 7)
# smoothL1公式,如上面所示 --> (batch_size, 321408, 7)
loss = torch.where(n < beta, 0.5 * n ** 2 / beta, n - 0.5 * beta)
return loss
def forward(self, input: torch.Tensor, target: torch.Tensor, weights: torch.Tensor = None):
"""
Args:
input: (B, #anchors, #codes) float tensor.
Ecoded predicted locations of objects.
target: (B, #anchors, #codes) float tensor.
Regression targets.
weights: (B, #anchors) float tensor if not None.
Returns:
loss: (B, #anchors) float tensor.
Weighted smooth l1 loss without reduction.
"""
# 如果target为nan,则等于input,否则等于target
target = torch.where(torch.isnan(target), input, target) # ignore nan targets# (batch_size, 321408, 7)
diff = input - target # (batch_size, 321408, 7)
# code-wise weighting
if self.code_weights is not None:
diff = diff * self.code_weights.view(1, 1, -1) #(batch_size, 321408, 7) 乘以box每一项的权重
loss = self.smooth_l1_loss(diff, self.beta)
# anchor-wise weighting
if weights is not None:
assert weights.shape[0] == loss.shape[0] and weights.shape[1] == loss.shape[1]
# weights参数使用正anchor数目进行平均,使得每个样本的损失与样本中目标的数量无关
loss = loss * weights.unsqueeze(-1)
return loss将第一阶段的的得到的loss相加,就得到第一阶段总的loss。
2、第二阶段loss计算
第一阶段的损失也包含了两部分:
1. 对ROI与GT的3D IOU大于0.6的ROI计算分类loss
2. 对ROI与GT的3D IOU大于0.55的ROI计算回归loss
2.1. 前景ROI置信度loss计算
第二阶段的分类损失计算,用于预测前面ROI的类别置信度分数。每个proposal与之对应的GT, 其中IOU大于0.6为前景,数值为1 0.45-0.6忽略不计算loss,数值为-1 0.45为背景,数值为0。
因此,此处直接使用BCE损失计算置信度分数。
def get_box_cls_layer_loss(self, forward_ret_dict):
loss_cfgs = self.model_cfg.LOSS_CONFIG
# 每个proposal的预测置信度 shape (batch *128, 1)
rcnn_cls = forward_ret_dict['rcnn_cls']
"""
每个proposal与之对应的GT,
其中IOU大于0.6为前景,数值为1
0.45-0.6忽略不计算loss,数值为-1
0.45为背景,数值为0
rcnn_cls_labels shape (batch *128 ,)
"""
rcnn_cls_labels = forward_ret_dict['rcnn_cls_labels'].view(-1)
if loss_cfgs.CLS_LOSS == 'BinaryCrossEntropy':
# shape (batch *128, 1)--> (batch *128, )
rcnn_cls_flat = rcnn_cls.view(-1)
batch_loss_cls = F.binary_cross_entropy(torch.sigmoid(rcnn_cls_flat), rcnn_cls_labels.float(),
reduction='none')
# 生成前背景mask
cls_valid_mask = (rcnn_cls_labels >= 0).float()
# 求loss值,并根据前背景总数进行正则化
rcnn_loss_cls = (batch_loss_cls * cls_valid_mask).sum() / torch.clamp(cls_valid_mask.sum(), min=1.0)
elif loss_cfgs.CLS_LOSS == 'CrossEntropy':
batch_loss_cls = F.cross_entropy(rcnn_cls, rcnn_cls_labels, reduction='none', ignore_index=-1)
cls_valid_mask = (rcnn_cls_labels >= 0).float()
rcnn_loss_cls = (batch_loss_cls * cls_valid_mask).sum() / torch.clamp(cls_valid_mask.sum(), min=1.0)
else:
raise NotImplementedError
# 乘以分类损失权重
rcnn_loss_cls = rcnn_loss_cls * loss_cfgs.LOSS_WEIGHTS['rcnn_cls_weight']
tb_dict = 'rcnn_loss_cls': rcnn_loss_cls.item()
return rcnn_loss_cls, tb_dict2.2. 前景ROI box 回归loss计算
这里需要ROI于GT的3D IOU大于0.55的ROI计算回归loss。在OpenPCDet中,PointRCNN的第二阶段的回归loss由两部分组成;其中第一部分为前景ROI与GT的每个参数的SmoothL1 Loss,第二部分为前景ROI与GT的Corner Loss。
1 SmoothL1 Loss
直接对前景roi的微调结果和GT计算Loss,这里的角度残差计算直接使用SmoothL1函数计算,原因是因为被认为属于前景的ROI其与GT的3D IOU大于0.55,所以两个box之间的角度偏差在正负45度以内。
2 CORNER LOSS REGULARIZATION
Corner Loss来源于F-PointNet,用于联合优化box的7个预测参数;在F-PointNet中指出,直接使用SmoothL1来回归box的参数,是直接对box的中心点,box的长宽高,box的朝向分别进行优化的。这样的优化可能会出现,box的中心点和长宽高已经可以十分准确的回归时,角度的预测却出现了偏差,导致3D IOU的降低的主要原因由角度预测错误引起。因此提出需要在(IOU metric)的度量方式下联合优化3D Box。为了解决这个问题,提出了一个正则化损失即Corner Loss,公式如下:
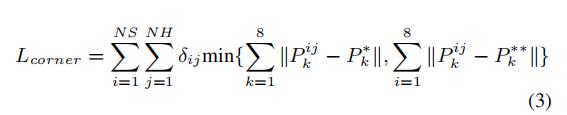
Corner Loss是GTBox和预测Box的8个顶点的差值的和,因为一个box的顶点会被box的中心、box的长宽高、box的朝向所决定;因此 Corner Loss 可以作为这个多任务优化参数的正则项。
公式中,NS和NH分别代表了预测框和GT框,然后将box的坐标系都转换到以自身的中心坐标点上,P的i,j,k代表了box的不同类别的尺度,旋转角,和预定义的顶角顺序;在计算loss时,为了避免因为角度估计错误而导致的过大的正则化项,因此,会同时计算角度预测方向正确和完成相反的两种情况,并取其中最小值为该box的loss。δij为一个二维mask,用于选取需要计算loss的距离项。
代码在:pcdet/models/roi_heads/roi_head_template.py
def get_box_reg_layer_loss(self, forward_ret_dict):
loss_cfgs = self.model_cfg.LOSS_CONFIG
code_size = self.box_coder.code_size # 7
# (batch * 128, )#每帧点云中,有128个roi,只需要对iou大于0.55的roi计算loss
reg_valid_mask = forward_ret_dict['reg_valid_mask'].view(
-1)
# 每个roi的gt_box canonical坐标系下 (batch , 128, 7)
gt_boxes3d_ct = forward_ret_dict['gt_of_rois'][..., 0:code_size]
# 每个roi的gt_box 点云坐标系下 (batch * 128, 7)
gt_of_rois_src = forward_ret_dict['gt_of_rois_src'][..., 0:code_size].view(-1, code_size)
# 每个roi的调整参数 (rcnn_batch_size, C) (batch * 128, 7)
rcnn_reg = forward_ret_dict['rcnn_reg']
# 每个roi的7个位置大小转向角参数 (batch , 128, 7)
roi_boxes3d = forward_ret_dict['rois']
rcnn_batch_size = gt_boxes3d_ct.view(-1, code_size).shape[0] # 256
# 获取前景mask
fg_mask = (reg_valid_mask > 0)
# 用于正则化
fg_sum = fg_mask.long().sum().item()
tb_dict =
if loss_cfgs.REG_LOSS == 'smooth-l1':
rois_anchor = roi_boxes3d.clone().detach().view(-1, code_size)
rois_anchor[:, 0:3] = 0
rois_anchor[:, 6] = 0
"""
编码GT和roi之间的回归残差
由于在第二阶段选出的每个roi都和GT的 3D_IOU大于0.55,
所有roi_box和GT_box的角度差距只会在正负45度以内;
因此,此处的角度直接使用SmoothL1进行回归,
不再使用residual-cos-based的方法编码角度
"""
reg_targets = self.box_coder.encode_torch(
gt_boxes3d_ct.view(rcnn_batch_size, code_size), rois_anchor
)
# 计算第二阶段的回归残差损失 [B, M, 7]
rcnn_loss_reg = self.reg_loss_func(
rcnn_reg.view(rcnn_batch_size, -1).unsqueeze(dim=0),
reg_targets.unsqueeze(dim=0),
)
# 这里只计算3D iou大于0.55的roi_box的loss
rcnn_loss_reg = (rcnn_loss_reg.view(rcnn_batch_size, -1) * fg_mask.unsqueeze(dim=-1).float()).sum() / max(
fg_sum, 1)
rcnn_loss_reg = rcnn_loss_reg * loss_cfgs.LOSS_WEIGHTS['rcnn_reg_weight']
tb_dict['rcnn_loss_reg'] = rcnn_loss_reg.item()
# 此处使用了F-PointNet中的corner loss来联合优化roi_box的 中心位置、角度、大小
if loss_cfgs.CORNER_LOSS_REGULARIZATION and fg_sum > 0:
# TODO: NEED to BE CHECK
# 取出对前景ROI的回归结果(num_of_fg_roi, 7)
fg_rcnn_reg = rcnn_reg.view(rcnn_batch_size, -1)[fg_mask]
# 取出所有前景ROI(num_of_fg_roi, 7)
fg_roi_boxes3d = roi_boxes3d.view(-1, code_size)[fg_mask]
# 前景ROI(1, num_of_fg_roi, 7)
fg_roi_boxes3d = fg_roi_boxes3d.view(1, -1, code_size)
# 前景ROI(1, num_of_fg_roi, 7)
batch_anchors = fg_roi_boxes3d.clone().detach()
# 取出前景ROI的角度
roi_ry = fg_roi_boxes3d[:, :, 6].view(-1)
# 取出前景ROI的xyz
roi_xyz = fg_roi_boxes3d[:, :, 0:3].view(-1, 3)
# 将前景ROI的xyz置0,转化到以自身中心为原点(CCS坐标系),
# 用于解码第二阶段得到的回归预测结果
batch_anchors[:, :, 0:3] = 0
# 根据第二阶段的微调结果来解码出最终的预测结果
rcnn_boxes3d = self.box_coder.decode_torch(
fg_rcnn_reg.view(batch_anchors.shape[0], -1, code_size), batch_anchors
).view(-1, code_size)
# 将canonical坐标系下的角度转回到点云坐标系中 (num_of_fg_roi, 7)
rcnn_boxes3d = common_utils.rotate_points_along_z(
rcnn_boxes3d.unsqueeze(dim=1), roi_ry
).squeeze(dim=1)
# 将canonical坐标系的中心坐标转回原点云雷达坐标系中
rcnn_boxes3d[:, 0:3] += roi_xyz
# corner loss 根据前景的ROI的refinement结果和对应的GTBox 计算corner_loss
loss_corner = loss_utils.get_corner_loss_lidar(
rcnn_boxes3d[:, 0:7], # 前景的ROI的refinement结果
gt_of_rois_src[fg_mask][:, 0:7] # GTBox
)
# 求出所有前景ROI corner loss的均值
loss_corner = loss_corner.mean()
loss_corner = loss_corner * loss_cfgs.LOSS_WEIGHTS['rcnn_corner_weight']
# 将两个回归损失求和
rcnn_loss_reg += loss_corner
tb_dict['rcnn_loss_corner'] = loss_corner.item()
else:
raise NotImplementedError
return rcnn_loss_reg, tb_dictget_corner_loss_lidar代码在pcdet/utils/loss_utils.py
def get_corner_loss_lidar(pred_bbox3d: torch.Tensor, gt_bbox3d: torch.Tensor):
"""
Args:
pred_bbox3d: (N, 7) float Tensor.
gt_bbox3d: (N, 7) float Tensor.
Returns:
corner_loss: (N) float Tensor.
"""
assert pred_bbox3d.shape[0] == gt_bbox3d.shape[0]
# 将预测box的7个坐标值转换到其在3D空间中对应的8个顶点
pred_box_corners = box_utils.boxes_to_corners_3d(pred_bbox3d)
# 将GTBox的7个坐标值转换到其在3D空间中对应的8个顶点
gt_box_corners = box_utils.boxes_to_corners_3d(gt_bbox3d)
# 再计算GTBox和预测的box的方向完全相反的情况
gt_bbox3d_flip = gt_bbox3d.clone()
gt_bbox3d_flip[:, 6] += np.pi
gt_box_corners_flip = box_utils.boxes_to_corners_3d(gt_bbox3d_flip)
# 所有的box和GT取距离最小值,防止因为距离相反产生较大的loss(N, 8)
corner_dist = torch.min(torch.norm(pred_box_corners - gt_box_corners, dim=2),
torch.norm(pred_box_corners - gt_box_corners_flip, dim=2))
# (N, 8)
corner_loss = WeightedSmoothL1Loss.smooth_l1_loss(corner_dist, beta=1.0)
# 对每个box的8个顶点的差距求均值
return corner_loss.mean(dim=1)
boxes_to_corners_3d在pcdet/utils/box_utils.py
def boxes_to_corners_3d(boxes3d):
"""
7 -------- 4
/| /|
6 -------- 5 .
| | | |
. 3 -------- 0
|/ |/
2 -------- 1
Args:
boxes3d: (N, 7) [x, y, z, dx, dy, dz, heading], (x, y, z) is the box center
Returns:
"""
boxes3d, is_numpy = common_utils.check_numpy_to_torch(boxes3d)
# shape (8, 3)
template = boxes3d.new_tensor((
[1, 1, -1], [1, -1, -1], [-1, -1, -1], [-1, 1, -1],
[1, 1, 1], [1, -1, 1], [-1, -1, 1], [-1, 1, 1],
)) / 2
corners3d = boxes3d[:, None, 3:6].repeat(1, 8, 1) * template[None, :, :]
corners3d = common_utils.rotate_points_along_z(corners3d.view(-1, 8, 3), boxes3d[:, 6]).view(-1, 8, 3)
corners3d += boxes3d[:, None, 0:3]
return corners3d.numpy() if is_numpy else corners3d至此,PointRCNN的所有loss计算就完成了,下面看看推理的实现。
2、网络推理实现
2.1 预测结果生成
看回第二阶段中roi精调的代码,在预测阶段,需要根据前面提出的roi和第二阶段的精调结果生成最终的预测结果;分别是
batch_cls_preds (1,100,1) 每个ROI Box的置信度得分
batch_box_preds (1,100,7) 每个ROI Box的7个参数 (x,y,z,l,w,h,theta)
注:在推理阶段,batch size 默认为1,ROI的个数是100个。
代码在:pcdet/models/roi_heads/pointrcnn_head.py
def forward(self, batch_dict):
"""
Args:
batch_dict:
Returns:
"""
# 生成proposal;在训练时,NMS保留512个结果,NMS_thresh为0.8;在测试时,NMS保留100个结果,NMS_thresh为0.85
targets_dict = self.proposal_layer(
batch_dict, nms_config=self.model_cfg.NMS_CONFIG['TRAIN' if self.training else 'TEST']
)
# 在训练模式时,需要为每个生成的proposal匹配到与之对应的GT_box
if self.training:
targets_dict = self.assign_targets(batch_dict)
"""
略
"""
# (total_rois, num_features, 1) --> (total_rois, 7)
rcnn_reg = self.reg_layers(shared_features).transpose(1, 2).contiguous().squeeze(dim=1) # (B, C)
if not self.training:
"""
在此处生成最终的预测框
"""
batch_cls_preds, batch_box_preds = self.generate_predicted_boxes(
batch_size=batch_dict['batch_size'], rois=batch_dict['rois'], cls_preds=rcnn_cls, box_preds=rcnn_reg
)
batch_dict['batch_cls_preds'] = batch_cls_preds
batch_dict['batch_box_preds'] = batch_box_preds
batch_dict['cls_preds_normalized'] = False
else:
targets_dict['rcnn_cls'] = rcnn_cls
targets_dict['rcnn_reg'] = rcnn_reg
self.forward_ret_dict = targets_dict
return batch_dict生成最终预测box的函数为generate_predicted_boxes
代码在:pcdet/models/roi_heads/roi_head_template.py
def generate_predicted_boxes(self, batch_size, rois, cls_preds, box_preds):
"""
Args:
batch_size:
rois: (B, N, 7)
cls_preds: (BN, num_class)
box_preds: (BN, code_size)
Returns:
"""
# 回归编码的7个参数 x, y, z, l, w, h, θ
code_size = self.box_coder.code_size
# 对ROI的置信度分数预测batch_cls_preds : (B, num_of_roi, num_class or 1)
batch_cls_preds = cls_preds.view(batch_size, -1, cls_preds.shape[-1])
# 对ROI Box的参数调整 batch_box_preds : (B, num_of_roi, 7)
batch_box_preds = box_preds.view(batch_size, -1, code_size)
# 取出每个roi的旋转角度,并拿出每个roi的xyz坐标,
# local_roi用于生成每个点自己的bbox,
# 因为之前的预测都是基于CCS坐标系下的,所以生成后需要将原xyz坐标上上去
roi_ry = rois[:, :, 6].view(-1)
roi_xyz = rois[:, :, 0:3].view(-1, 3)
local_rois = rois.clone().detach()
local_rois[:, :, 0:3] = 0
# 得到CCS坐标系下每个ROI Box的经过refinement后的Box结果
batch_box_preds = self.box_coder.decode_torch(batch_box_preds, local_rois).view(-1, code_size)
# 完成CCS到点云坐标系的转换
# 将canonical坐标系下的box角度转回到点云坐标系中
batch_box_preds = common_utils.rotate_points_along_z(
batch_box_preds.unsqueeze(dim=1), roi_ry
).squeeze(dim=1)
# 将canonical坐标系下的box的中心偏移估计加上roi的中心,转回到点云坐标系中
batch_box_preds[:, 0:3] += roi_xyz
batch_box_preds = batch_box_preds.view(batch_size, -1, code_size)
# batch_cls_preds 每个ROI Box的置信度得分
# batch_box_preds 每个ROI Box的7个参数 (x,y,z,l,w,h,theta)
return batch_cls_preds, batch_box_predsdecode_torch完成预测结果和原ROI Box解码。 这里的对角度的解码直接将refine的预测结果与ROI的角度相加,因为他们的误差在正负45度以内。
代码在:pcdet/utils/box_coder_utils.py
# batch_cls_preds 每个ROI Box的置信度得分
# batch_box_preds 每个ROI Box的7个参数 (x,y,z,l,w,h,theta)
rotate_points_along_z为围绕偏航角(yaw)的旋转
代码在pcdet/utils/common_utils.py
def rotate_points_along_z(points, angle):
"""
Args:
points: (B, N, 3 + C)
angle: (B), angle along z-axis, angle increases x ==> y
Returns:
"""
# 首先利用torch.from_numpy().float将numpy转化为torch
points, is_numpy = check_numpy_to_torch(points)
angle, _ = check_numpy_to_torch(angle)
# 构造旋转矩阵batch个
cosa = torch.cos(angle)
sina = torch.sin(angle)
zeros = angle.new_zeros(points.shape[0])
ones = angle.new_ones(points.shape[0])
rot_matrix = torch.stack((
cosa, sina, zeros,
-sina, cosa, zeros,
zeros, zeros, ones
), dim=1).view(-1, 3, 3).float()
# 对点云坐标进行旋转
points_rot = torch.matmul(points[:, :, 0:3], rot_matrix)
# 将旋转后的点云与原始点云拼接
points_rot = torch.cat((points_rot, points[:, :, 3:]), dim=-1)
# 将点云转化为numpy格式,并返回
return points_rot.numpy() if is_numpy else points_rot2.2. 后处理
后处理完成了最终100个ROI的NMS操作;同时需要注意的是,每个box的最终分类结果是由第一阶段得出,第二阶段的分类结果得到的是该类别属于前景或背景的置信度得分;此处实现与FRCNN不同,需注意。
代码在:pcdet/models/detectors/detector3d_template.py
def post_processing(self, batch_dict):
"""
Args:
batch_dict:
batch_size:
batch_cls_preds: (B, num_boxes, num_classes | 1) or (N1+N2+..., num_classes | 1)
or [(B, num_boxes, num_class1), (B, num_boxes, num_class2) ...]
multihead_label_mapping: [(num_class1), (num_class2), ...]
batch_box_preds: (B, num_boxes, 7+C) or (N1+N2+..., 7+C)
cls_preds_normalized: indicate whether batch_cls_preds is normalized
batch_index: optional (N1+N2+...)
has_class_labels: True/False
roi_labels: (B, num_rois) 1 .. num_classes
batch_pred_labels: (B, num_boxes, 1)
Returns:
"""
# post_process_cfg后处理参数,包含了nms类型、阈值、使用的设备、nms后最多保留的结果和输出的置信度等设置
post_process_cfg = self.model_cfg.POST_PROCESSING
# 推理默认为1
batch_size = batch_dict['batch_size']
# 保留计算recall的字典
recall_dict =
# 预测结果存放在此
pred_dicts = []
# 逐帧进行处理
for index in range(batch_size):
if batch_dict.get('batch_index', None) is not None:
assert batch_dict['batch_box_preds'].shape.__len__() == 2
batch_mask = (batch_dict['batch_index'] == index)
else:
assert batch_dict['batch_box_preds'].shape.__len__() == 3
# 得到当前处理的是第几帧
batch_mask = index
# box_preds shape (所有anchor的数量, 7)
box_preds = batch_dict['batch_box_preds'][batch_mask]
# 复制后,用于recall计算
src_box_preds = box_preds
if not isinstance(batch_dict['batch_cls_preds'], list):
# (所有anchor的数量, 3)
cls_preds = batch_dict['batch_cls_preds'][batch_mask]
# 同上
src_cls_preds = cls_preds
assert cls_preds.shape[1] in [1, self.num_class]
if not batch_dict['cls_preds_normalized']:
# 损失函数计算使用的BCE,所以这里使用sigmoid激活函数得到类别概率
cls_preds = torch.sigmoid(cls_preds)
else:
cls_preds = [x[batch_mask] for x in batch_dict['batch_cls_preds']]
src_cls_preds = cls_preds
if not batch_dict['cls_preds_normalized']:
cls_preds = [torch.sigmoid(x) for x in cls_preds]
# 是否使用多类别的NMS计算,否,不考虑不同类别的物体会在3D空间中重叠
if post_process_cfg.NMS_CONFIG.MULTI_CLASSES_NMS:
if not isinstance(cls_preds, list):
cls_preds = [cls_preds]
multihead_label_mapping = [torch.arange(1, self.num_class, device=cls_preds[0].device)]
else:
multihead_label_mapping = batch_dict['multihead_label_mapping']
cur_start_idx = 0
pred_scores, pred_labels, pred_boxes = [], [], []
for cur_cls_preds, cur_label_mapping in zip(cls_preds, multihead_label_mapping):
assert cur_cls_preds.shape[1] == len(cur_label_mapping)
cur_box_preds = box_preds[cur_start_idx: cur_start_idx + cur_cls_preds.shape[0]]
cur_pred_scores, cur_pred_labels, cur_pred_boxes = model_nms_utils.multi_classes_nms(
cls_scores=cur_cls_preds, box_preds=cur_box_preds,
nms_config=post_process_cfg.NMS_CONFIG,
score_thresh=post_process_cfg.SCORE_THRESH
)
cur_pred_labels = cur_label_mapping[cur_pred_labels]
pred_scores.append(cur_pred_scores)
pred_labels.append(cur_pred_labels)
pred_boxes.append(cur_pred_boxes)
cur_start_idx += cur_cls_preds.shape[0]
final_scores = torch.cat(pred_scores, dim=0)
final_labels = torch.cat(pred_labels, dim=0)
final_boxes = torch.cat(pred_boxes, dim=0)
else:
# 得到类别预测的最大概率,和对应的索引值
cls_preds, label_preds = torch.max(cls_preds, dim=-1)
if batch_dict.get('has_class_labels', False):
# 如果有roi_labels在里面字典里面,
# 使用第一阶段预测的label为改预测结果的分类类别
label_key = 'roi_labels' if 'roi_labels' in batch_dict else 'batch_pred_labels'
label_preds = batch_dict[label_key][index]
else:
# 类别预测值加1
label_preds = label_preds + 1
# 无类别NMS操作
# selected : 返回了被留下来的anchor索引
# selected_scores : 返回了被留下来的anchor的置信度分数
selected, selected_scores = model_nms_utils.class_agnostic_nms(
# 每个anchor的类别预测概率和anchor回归参数
box_scores=cls_preds, box_preds=box_preds,
nms_config=post_process_cfg.NMS_CONFIG,
score_thresh=post_process_cfg.SCORE_THRESH
)
# 无此项
if post_process_cfg.OUTPUT_RAW_SCORE:
max_cls_preds, _ = torch.max(src_cls_preds, dim=-1)
selected_scores = max_cls_preds[selected]
# 得到最终类别预测的分数
final_scores = selected_scores
# 根据selected得到最终类别预测的结果
final_labels = label_preds[selected]
# 根据selected得到最终box回归的结果
final_boxes = box_preds[selected]
# 如果没有GT的标签在batch_dict中,就不会计算recall值
recall_dict = self.generate_recall_record(
box_preds=final_boxes if 'rois' not in batch_dict else src_box_preds,
recall_dict=recall_dict, batch_index=index, data_dict=batch_dict,
thresh_list=post_process_cfg.RECALL_THRESH_LIST
)
# 生成最终预测的结果字典
record_dict =
'pred_boxes': final_boxes,
'pred_scores': final_scores,
'pred_labels': final_labels
pred_dicts.append(record_dict)
return pred_dicts, recall_dict其中 无类别的NMS操作在:pcdet/models/model_utils/model_nms_utils.py
def class_agnostic_nms(box_scores, box_preds, nms_config, score_thresh=None):
# 1.首先根据置信度阈值过滤掉部过滤掉大部分置信度低的box,加速后面的nms操作
src_box_scores = box_scores
if score_thresh is not None:
# 得到类别预测概率大于score_thresh的mask
scores_mask = (box_scores >= score_thresh)
# 根据mask得到哪些anchor的类别预测大于score_thresh-->anchor类别
box_scores = box_scores[scores_mask]
# 根据mask得到哪些anchor的类别预测大于score_thresh-->anchor回归的7个参数
box_preds = box_preds[scores_mask]
# 初始化空列表,用来存放经过nms后保留下来的anchor
selected = []
# 如果有anchor的类别预测大于score_thresh的话才进行nms,否则返回空
if box_scores.shape[0] > 0:
# 这里只保留最大的K个anchor置信度来进行nms操作,
# k取min(nms_config.NMS_PRE_MAXSIZE, box_scores.shape[0])的最小值
box_scores_nms, indices = torch.topk(box_scores, k=min(nms_config.NMS_PRE_MAXSIZE, box_scores.shape[0]))
# box_scores_nms只是得到了类别的更新结果;
# 此处更新box的预测结果 根据tokK重新选取并从大到小排序的结果 更新boxes的预测
boxes_for_nms = box_preds[indices]
# 调用iou3d_nms_utils的nms_gpu函数进行nms,
# 返回的是被保留下的box的索引,selected_scores = None
# 根据返回索引找出box索引值
keep_idx, selected_scores = getattr(iou3d_nms_utils, nms_config.NMS_TYPE)(
boxes_for_nms[:, 0:7], box_scores_nms, nms_config.NMS_THRESH, **nms_config
)
selected = indices[keep_idx[:nms_config.NMS_POST_MAXSIZE]]
if score_thresh is not None:
# 如果存在置信度阈值,scores_mask是box_scores在src_box_scores中的索引,即原始索引
original_idxs = scores_mask.nonzero().view(-1)
# selected表示的box_scores的选择索引,经过这次索引,
# selected表示的是src_box_scores被选择的box索引
selected = original_idxs[selected]
return selected, src_box_scores[selected]最终得到每个预测Box的类别、置信度得分、box的7个参数。
3、PointRCNN的结果
PointRCNN原论文结果
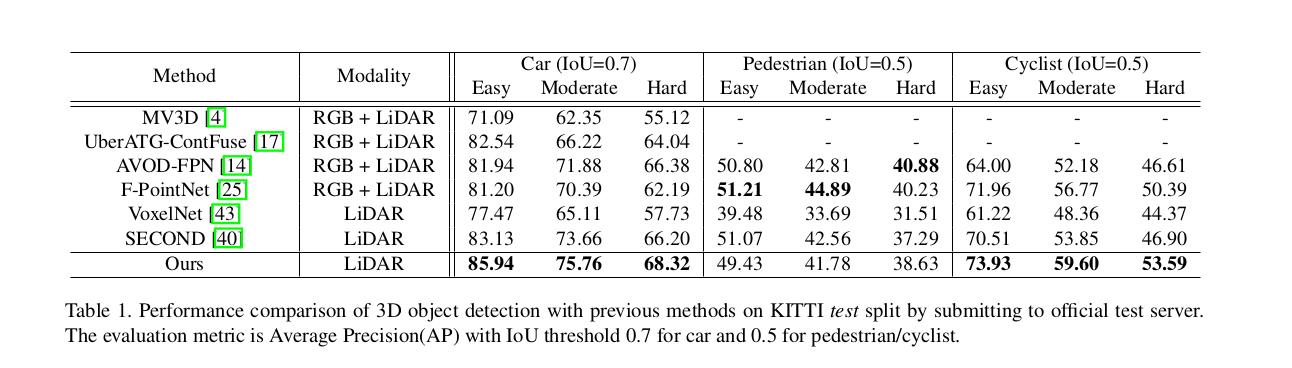
PointRCNN在KITTI数据集测试结果(结果仅显示在kitti验证集moderate精度)
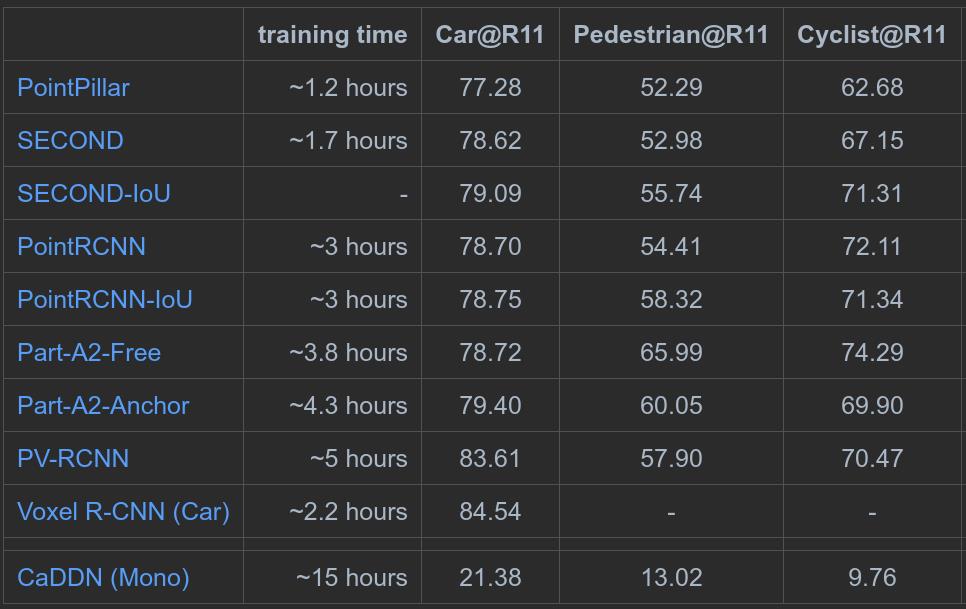
4、消融实验
4.1 不同特征组合对refinement的影响
在将CCS的坐标和每个点的池化后的特征输入送给refinement网络前,分别对不同的特征进行了组合操作;这里采用控制变量的思路,分别来测试不同的组合会在refinement网络中得到的效果。(所有的实验都是用相同的第一阶段提议网络)。结果如下图:
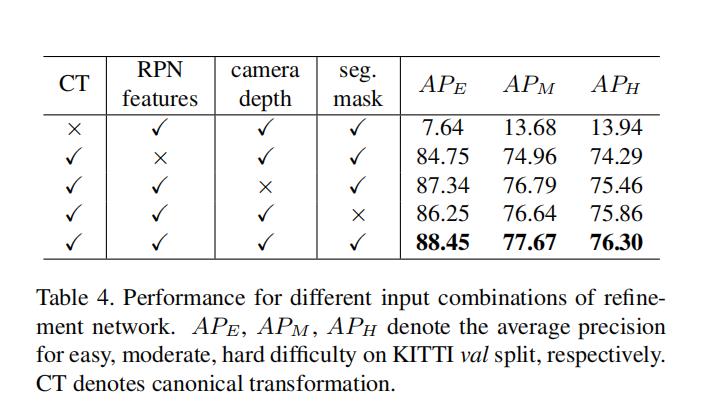
1、如果送入refinement网络中没有将坐标系转换到CCS坐标系下,检测的结果十分糟糕,这说明了将该该proposal的点转换到CCS坐标系下可以极大程度的消除旋转和定位的的变化,降低网络学习的难度,同时也提高了refinement网络学习的效果。
2、如果将来自第一阶段的每个点经过PointNet++的特征进行移除的话,网络在中等难度的目标检测精度上下降了2.71%mAP,这说明了在第一阶段中每个点经过分割得到的特征是有效的。
3、对于每个点加上自身相对于相机的深度信息和CLS_SCORE点的分割特征对最终的结果影响较轻微,但是需要注意的是,加上来自相机的深度信息可以补全因为转换到CCS后每个点的深度信息丢失的情况,同时CLS_SCORE也可以在点的池化时候指明哪些是前景点。
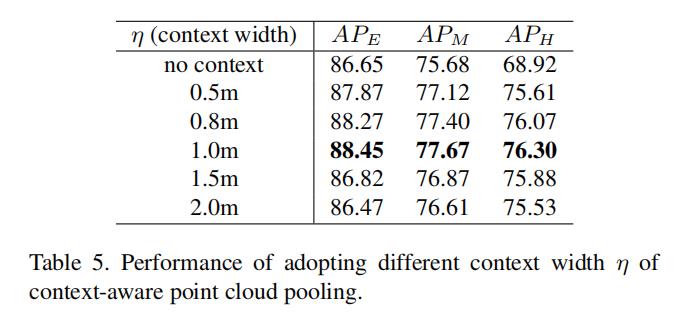
4.2. 感知点云池化
这里与PCDet的代码实现不同,论文中的实现是在点云池化的过程中,将池化的box范围进行了一定范围的扩展,结果也显示延长1米对最终的结果是最好的,因为每个proposal内就能拥有更多的周围环境信息,可以得到更准确的置信度估计和提高位置回归的准确度。但是如果延长的的太长,又会在ROI池化的过程中引入其它物体景点变成噪声,影响结果。
注:PCDet的实现中,yaml文件中在此处并没有enlarge每个proposal,同时在实现中,因为作者已经将池化操作进行了编译,所以这里暂不做详细讨论。
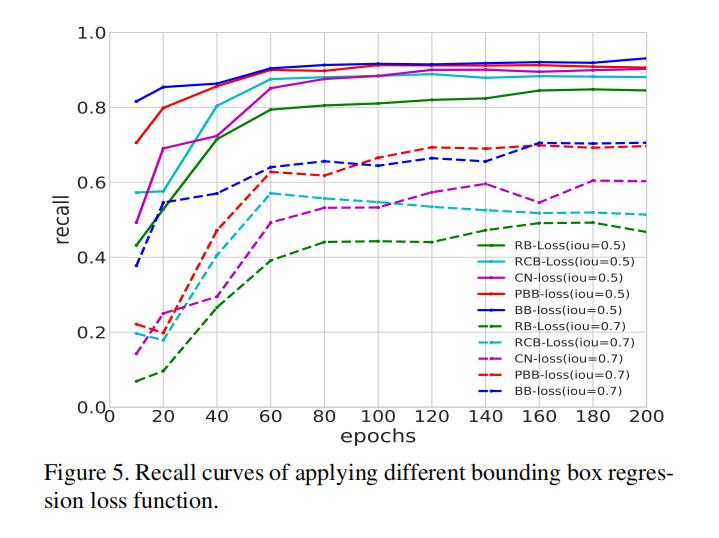
4.3 3D BBox的损失函数
在原论文中,作者对每个阶段的box回归和角度预测都是用的bin-based的方式进行的,详情可以看训练的文章内容。在PCDet的实现中,第一阶段和第二阶段box回归变成了smoothL1,角度回归变成了residual-cos-based,第二阶段的box由于是基于前面的proposal,每个proposal的3D IOU与GT Box大于0.55,它们之间的角度差仅在正负45度内,所以也直接使用了smoothL1作为损失函数;为了联合优化box和GT,还在第二阶段的box回归上加入了Corner loss进行正则化约束。
下图为不同回归函数的效果
至此PointRCNN的网络构建和推理就全部解析完了,之后会带来史帅另一个模型PVRCNN的解析。
参考文献或文章:
2、论文阅读-PointRCNN+python3.5实现_有所为,有所成长-CSDN博客_pointrcnn代码
3、https://arxiv.org/abs/1812.04244
4、http://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=3d
5、GitHub - open-mmlab/OpenPCDet: OpenPCDet Toolbox for LiDAR-based 3D Object Detection.
以上是关于PointRCNN的loss计算与推理实现的主要内容,如果未能解决你的问题,请参考以下文章