用于小规模低成本场景的kafka + eCAL架构设计
Posted 丁劲犇
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用于小规模低成本场景的kafka + eCAL架构设计相关的知识,希望对你有一定的参考价值。
Kafka作为存储、性能兼备的消息队列,适用场景很多,伸缩性也很强。如何调节kafka的配置参数,以及设计专题、分区的数量、物理位置,很大程度上影响到整个架构的成败。很多文章是站在数据中心的角度来谈kafka的配置,而对于小团队,往往只希望把Kafka作为一个跨进程、可追溯的隔离器来使用,取代繁琐的文件或者自定义TCP/UDP接口。此时,单独讨论这种场景就显得有必要了。
- 少量的物理服务器,甚至只有1台。
- 单股光纤甚至千兆网。
本文先试图通过调优,来允许kafka队列在有限资源下发挥更大作用;而后,介绍一种折中的架构设计,引入车联网的eCAL解决问题。
1. 磁盘与网络是最重要的两个瓶颈
无论是集群还是单机,磁盘与网络都是最重要的瓶颈。不管Kafka用了0拷贝等各种加速策略,底层的物理设备都会影响到架构的可用性。
1.1 固态硬盘与机械盘阵
根据我的测试,在机械硬盘情况下,若并发读写的会话足够多,机械硬盘照样会遇到并发陷阱——由缓存命中失败导致的频繁机械磁头巡道。这种情况在多个大流量topic同时读写的情况下尤其显著,特别是在消费的数据时间上间隔较远的时刻下。
典型的现象就是写入延迟很大,磁盘占用100%。明明网络带宽没用完,但是写不进去了。遇到这种情况,需要仔细分析,对症下药。
- 查看 server.properties文件,关注参数“num.io.threads”
# The number of threads that the server uses for processing requests, which may include disk I/O
num.io.threads=8
如果没有修改过这个值,应该是8. 建议把这个值缩小到2,观察一下情况有无好转。对于机械硬盘来说,限制并发读写的会话,会提高一部分效率。
- 若在虚拟机中使用kafka,打开“使用主机缓存”选项,可能有助于提高吞吐率。
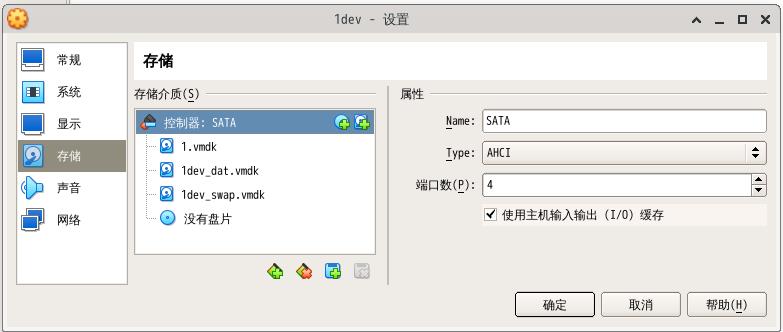
- 使用SSD
如果上述情况都无法缓解磁盘的延迟问题,果断上SSD。在大量并发随机读写的情况下,一个机械盘阵要比一块16TB的企业级SSD 慢很多。
1.2 网络带宽
kafka是一种TCP协议的消息队列。这种消息队列的出口带宽与消费者组的个数是 xN的关系。如果1个专题-分区的入口带宽为10MBps,开100个消费者组,则是 1000MBps, 基本就必须要上光纤解决问题了。所以,要非常重视消费者组的数目。当必须要维持消费者组的数目时,解决问题的策略有以下几条。
- 启用 zstd压缩
近期版本的kafka支持zstd压缩,比gzip的CPU开销小。可以在生产者方启动 zstd压缩,一般能够达到超过2倍的压缩率
if (rd_kafka_conf_set(conf, "compression.type", "zstd", errstr,
sizeof(errstr)) != RD_KAFKA_CONF_OK)
cbprintf( "%s\\n", errstr);
rd_kafka_conf_destroy(conf);
return false;
if (rd_kafka_conf_set(conf, "compression.level", "9", errstr,
sizeof(errstr)) != RD_KAFKA_CONF_OK)
cbprintf( "%s\\n", errstr);
rd_kafka_conf_destroy(conf);
return false;
但此时要注意的是,compression.level 会显著提高生产者的CPU占用。如果来不及,需要降低compression.level。
- 双网卡分流
使用2张网卡,为1个broker提供物理传输,能够进行分流。broker可以在2个IP地址监听,这样,物理上把消费者的流量引导到不同的网卡上。
2. 并行计算策略的调整
对于捉襟见肘的计算存储资源而言,可能需要更为底层手段控制流量和磁盘的开销。对于TCP承载的消息队列,消费数据要聚焦。尤其要避免浪费带宽。比如,3个算法消费者组共视一份数据,则需要的流量是x3的。如果是针对1份数据的3种处理,必须放在3个消费者组里(1个组里的不同消费者看到的数据不同,不满足需求),则建议使用1个消费者+3个处理子模块的方式,而不是都直接从kafka消费数据。这相当于使用一个消费者进行第二层分包。这种区别如下图所示:
上图中,模拟的是双分区的集群。算法1、算法2、算法3都是消费者,直接连接在集群。因此,他们总共会消费3次完整的数据。如果我们在算法与集群之间,添加一个管理者,统一消费数据,则可以只消费1份数据量,如下图所示:
3.同时使用2种消息队列
在上图中,我们引入了管理者来降低吞吐量。但这带来了显著的复杂度,有坑。有没有一种节省带宽和磁盘的局部消息队列可以完成这个功能呢?
我们可以使用一种局部的消息队列,或者一个本地kafka实例、一个本地的数据库来完成这个功能。一个典型的高速局部消息队列就是 eCAL。
https://eclipse-ecal.github.io/ecal/

eCAL是用于可靠直连局域网的跨平台M2M消息队列,初衷是在车载智能电路上实现稳定可靠的传感器交互。值得注意的是,这种交互使用的是UDP组播协议。这种协议的好处是接收本身就是1对多的。只要确保局域网环境的稳定,UDP也基本不会丢包。
如此一来,消费者管理算法模块的时候,就可以选择把数据从Kafka下载到本地交换机,而后用eCAL组播给算法模块。
需要注意的问题是确保 连续性。需要有计数器检验数据的连续性,以防止UDP的丢包。
====
有了gpt,我已经不太想继续写Blog了。发现我以前踩的坑,一问就全解决了,不需要再用Blog来固化知识了。
2022-03-10-NLP文本场景的数据优化
NLP 文本场景的数据优化
@(NLP)[数据增强, 噪声]
序言
数据增强(Data Augmentation,简称DA),是指根据现有数据,合成新数据的一类方法。毕竟数据才是真正的效果天花板,有了更多数据后可以提升效果、增强模型泛化能力、提高鲁棒性等。数据增强主要在CV应用中比较常见,然而由于NLP任务天生的难度,类似CV的裁剪方法可能会改变语义,既要保证数据质量又要保证多样性,所以大家在做数据增强时要十分谨慎。
数据增强的目的
- 在很多机器学习场景下,没有足够的数据(数据稀缺场景)来训练高质量的模型。
- 提高训练数据的多样性,从而得到在真实场景下(很多没有见过的数据)更好的泛化效果。
- 样本不均衡
- 为了模型安全,应对模型的对抗攻击。
NLP数据增强研究基本现状1
- 在CV上很成功,逐渐在NLP任务上发现有效
- 在文本分类2领域数据增强方法也比较多,其他任务例如NER,多标签分类等就相对少一些;
- 语言输入是离散,而且一定的文本改变容易引起文本分布的巨大改变,无法做到像图片那样不可见的抖动;
- 一般算法都可以从输入文本空间和文本编码空间进行数据增强。
- 对抗攻击: 相比较CV的对抗,文本的对抗存在很大差异。文本输入为离散的
问题:
- 数据增广在当前迁移学习大背景下的大规模预训练模型上有用吗?
Data Augmentation in NLP
Paraphrasing:对句子中的词、短语、句子结构做一些更改,保留原始的语义 Noising:在保证label不变的同时,增加一些离散或连续的噪声,对语义的影响不大 Sampling:旨在根据目前的数据分布选取新的样本,会生成更多样的数据
Data Augmentation Approaches in Natural LanguageProcessing: A Survey3
Paraphrasing
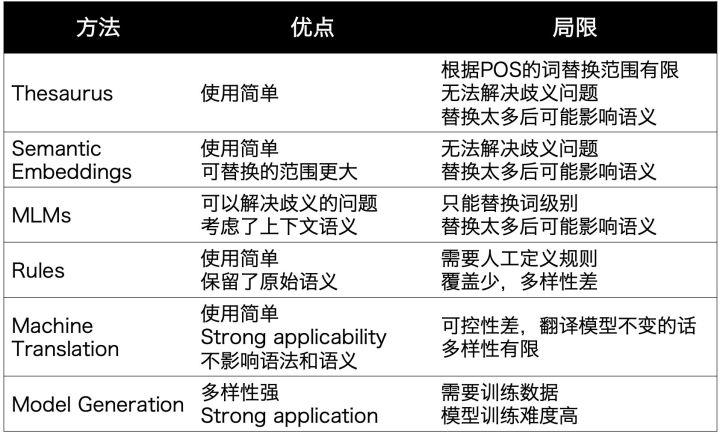
小结: 在尽可能保留句子整体语义的情况下,增加文本丰富度,包括让每个词拥有更加丰富的上下文context,让相似的语义表达有更多样的语法构成,词汇构成等等
Noiseing
作者给出了以下5种增加噪声的方法: 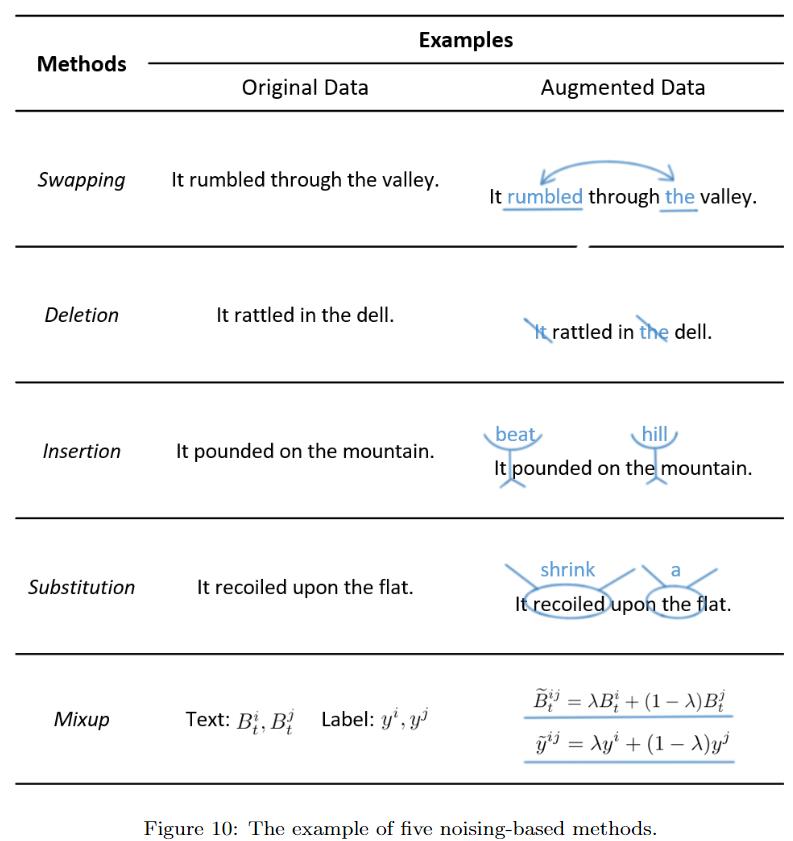
- Swapping:除了交换词之外,在分类任务中也可以交换instance或者sentence
- Deletion:可以根据tf-idf等词的重要程度进行删除
- Insertion:可以把同义词随机插入句子中
- Substitution:把一些词随机替换成其他词(非同义),模拟misspelling的场景。为了避免改变label,可以使用label-independent的词,或者利用训练数据中的其他句子
- Mixup:这个方法最近两年比较火,把句子表示和标签分别以一定权重融合,引入连续噪声,可以生成不同label之间的数据,但可解释性较差 总的来说,引入噪声的DA方法使用简单,但会对句子结构和语义造成影响,多样性有限,主要还是提升鲁棒性。 ConSERT时用到的方法:
- 对抗样本
- Dropout:也是SimCSE用到的,还有R-drop,都是通过dropout来加入连续噪声
- Feature Cut-off:比如BERT的向量都是768维,可以随机把一些维度置为0,这个效果也不错
小结: 增加模型稳健性,在不过多影响training error的前提下,降低模型的复杂度从而降低generalization error, 类比dropout,l2,random noise injection
Sampling
 Sampling是指从数据分布中采样出新的样本,不同于较通用的paraphrasing,采样更依赖任务,需要在保证数据可靠性的同时增加更多多样性,比前两个数据增强方法更难。作者整理了4种方法:
Sampling是指从数据分布中采样出新的样本,不同于较通用的paraphrasing,采样更依赖任务,需要在保证数据可靠性的同时增加更多多样性,比前两个数据增强方法更难。作者整理了4种方法:
- Rules:用规则定义新的样本和label,比如把句子中的主谓进行变换
- Seq2Seq Models:根据输入和label生成新的句子,比如在NLI任务中,有研究者先为每个label(entailment,contradiction,neutral)训一个生成模型,再给定新的句子,生成对应label的。对比之下,paraphrasing主要是根据当前训练样本进行复述
- Language Models:给定label,利用语言模型生成样本,有点像前阵子看的谷歌UDG。有些研究会加个判别模型过滤
- Self-training:先有监督训练一个模型,再给无监督数据打一些标签,有点蒸馏的感觉
增强方法选择依据

Method Stacking 实际应用时可以应用多种方法、或者一种方法的不同粒度。
作者推荐了两款工具eda4和uda5, eda_chinese6, nlpaug7
第一,在使用增强的数据时,如果数据质量不高,可以先让模型在增强后的数据上pre-train,之后再用有标注数据训练。如果要一起训练,在增强数据量过大的情况下,可以对原始训练数据过采样
第二,在进行数据增强时注意这些超参数的调整: 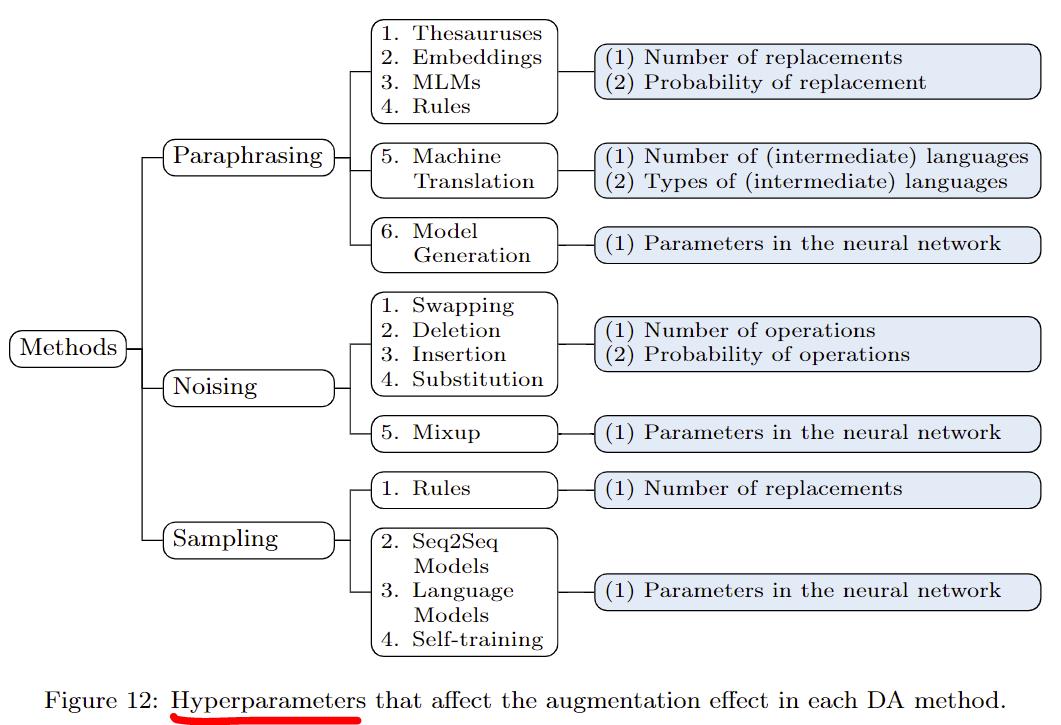 第三,其实增强很多简单数据的提升有限,可以注重困难样本的生成。比如有研究加入对抗训练、强化学习、在loss上下文章等。如果用生成方法做数据增强,也可以在生成模型上做功夫,提升数据多样性。
第三,其实增强很多简单数据的提升有限,可以注重困难样本的生成。比如有研究加入对抗训练、强化学习、在loss上下文章等。如果用生成方法做数据增强,也可以在生成模型上做功夫,提升数据多样性。
第四,如果生成错数据可能引入更多噪声,可以增加其他模型对准确性进行过滤。
分类任务
1、Mixup: Mixup-Transformer: Dynamic Data Augmentation for NLP Tasks
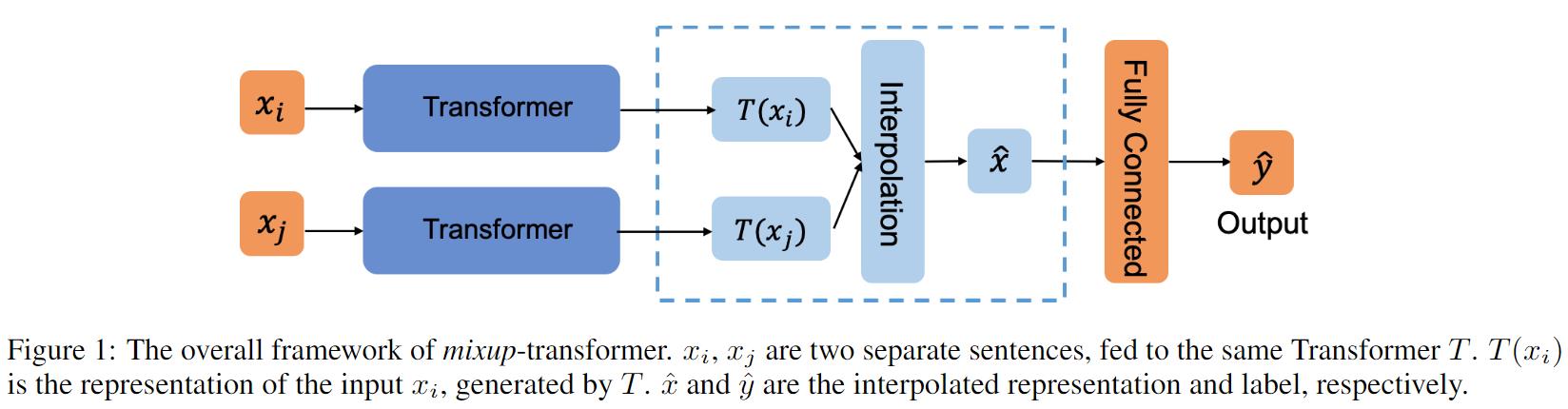

在数据不足的情况下,只用40%的数据就可以比不应用增强方案的全量数据好。应用Mixup增强方法可以提升2.46%

2、On Data Augmentation for Extreme Multi-label Classification

3、分类算法中的数据增强方法:综述 
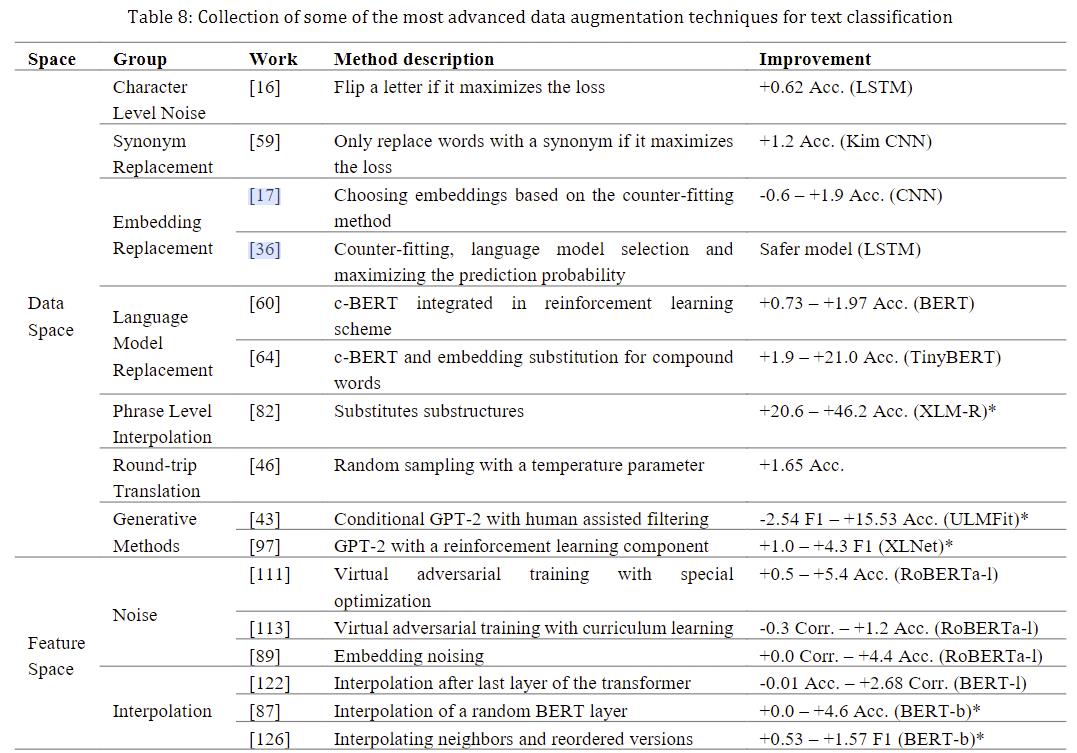
这些在线blog或者paper128中提到了很多增强方法,主要有如下特点
- 多分类任务,为英文任务
- 有针对不同应用场景进行分析的增强方法。虽然现在都用预训练模型,但是在数据增强方法中,通过额外的静态词embedding进行数据增强也是常见的方法。
4、EDA 
- paper:EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
- github: http://github.com/jasonwei20/eda_nlp
EDA主要采用表一中的同义词替换,随机插入,随机交换,随机删除,从可视化结果中来看,增强样本与原始样本分布基本是一致的。 作者给出了在实际使用EDA方法的建议,表格的左边是数据的规模$N_train$, 右边$\\alpha$是概率、比率 比如同义词替换中,替换的单词数$n=\\alpha * l$ , $l$是句子长度。随机插入、随机替换类似. $p=\\alpha * n_aug$ 代表使用EDA方法从每一个句子拓展出的句子数量。
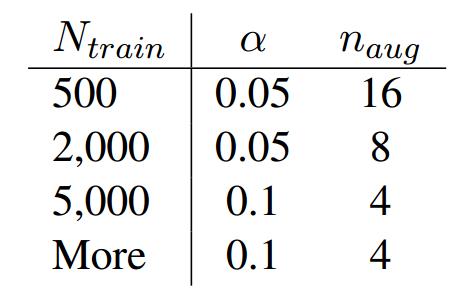
之后,又有新的AEDA 

Text Smoothing

sentence = "My favorite fruit is pear ."
lambd = 0.1 # interpolation hyperparameter
mlm.train() # enable dropout, dynamically mask
tensor_input = tokenizer(sentence, return_tensors="pt")
onehot_repr = convert_to_onehot(**tensor_input)
smoothed_repr = softmax(mlm(**tensor_input).logits[0])
interpolated_repr = lambd * onehot_repr + (1 - lambd) * smoothed_repr-code: https://github.com/1024er/cbert_aug
PromDA

- paper:https://arxiv.org/pdf/2202.12230.pdf
- 论文目的: low-resource Natural Language Understanding (NLU) tasks
少数据的场景,可能使用PLM不是最优的方案 我们期望构造的数据$\\mathcalT_LM$与已有的数据集$\\mathcalT$不同,能够从中学习到一些新的信息。 冻结PLMs参数可能有助于在训练过程中进行泛化。然而,寻找合适的离散任务引入并不容易以端到端方式进行优化,而且需要额外的人力。
引入**$soft Prompt$** 
DualCL

- paper: Dual Contrastive Learning: Text Classification via Label-Aware Data Augmentation
- github: https://github.com/hiyouga/Dual-Contrastive-Learning
- 设计主要思想: 将类别与文本表征map到同一个空间
传统自监督对比学习损失函数定义如下左侧公式,但是没有利用标注信息。将标注信息考虑进去,
到目前为止发展起来的监督对比学习似乎是对分类问题的无监督对比学习的一种简单朴素的适配。
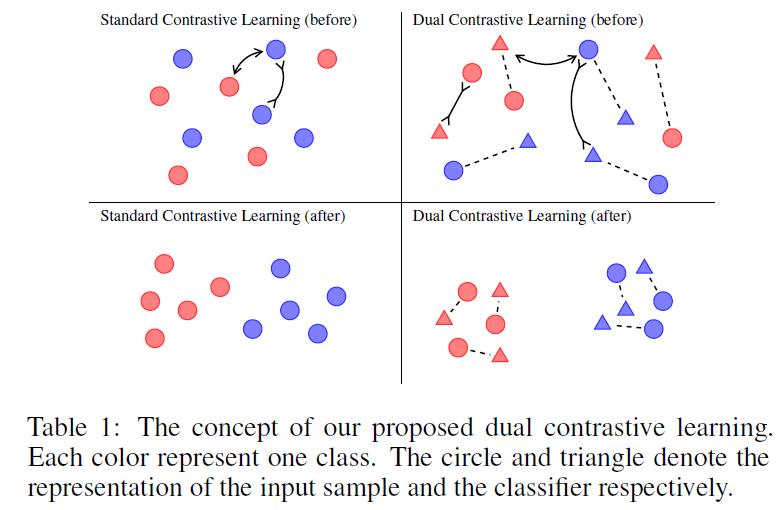
- K+1+ 其他文本
- 学习到多个表征,其中1个原来的[CLS],另外K个是用来判断分类的结果的。$$ \\haty_i = \\arg\\max_k(\\theta_i^k \\cdot z_i)$$
算法对比结果,少样本与全样本的对比: 
Sample Efficiency of Data Augmentation Consistency Regularization

DA-ERM(data augmentation empirical risk minimization): DAC可以使用未标记的样本,因为可以在不知道真实标签的情况下增加训练样本并执行一致的预测。这绕过了传统算法只能增加标记样本并将其添加到训练集的限制 
少量数据+data augmentation 少量数据+unlabel data

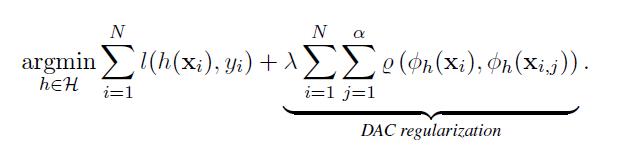 我们可以看到对标注样本$\\phi(x_i)$和增强产生的样本$\\phi(x_i,j)$之间的差异作为惩罚项。
我们可以看到对标注样本$\\phi(x_i)$和增强产生的样本$\\phi(x_i,j)$之间的差异作为惩罚项。
我们从经验和理论上论证了DAC与DA-ERM(用增强样本扩展训练集)相比的优点。理论上,线性回归和逻辑回归的泛化误差更小,两层神经网络的泛化上界更紧。另一个好处是,DAC可以更好地处理由强扩充数据引起的模型错误规范。在经验上,我们提供了关于增广ERM和一致性正则化的比较。这些共同证明了一致性规则化优于DA-ERM的有效性
ALP: Data Augmentation using Lexicalized PCFGs for Few-Shot Text Classification
- 标题:ALP:基于词汇化PCFGS的Few-Shot文本分类数据增强
- 链接:https://arxiv.org/abs/2112.11916
- 作者:Hazel Kim,Daecheol Woo,Seong Joon Oh,Jeong-Won Cha,Yo-Sub Han
- 机构: Yonsei University, Seoul, Republic of Korea, NAVER AI Lab, Changwon National University, Changwon, Republic of Korea
- 备注:Accepted to AAAI2022
这个是基于文法分析树的方式进行数据增强的
NER^prompt base在NER中的应用
该任务中需要生成句子和token级别的标签。且序列标注为细粒度的文本任务。 现有的生成模型智能生成没有标签的序列; 启发式的数据增强方法不可行,直接对标签替换或者上下文替换,被注入错误的可能性比较大,相比较分类任务更容易破坏序列上下文关系。
An Analysis of Simple Data Augmentation for Named Entity Recognition

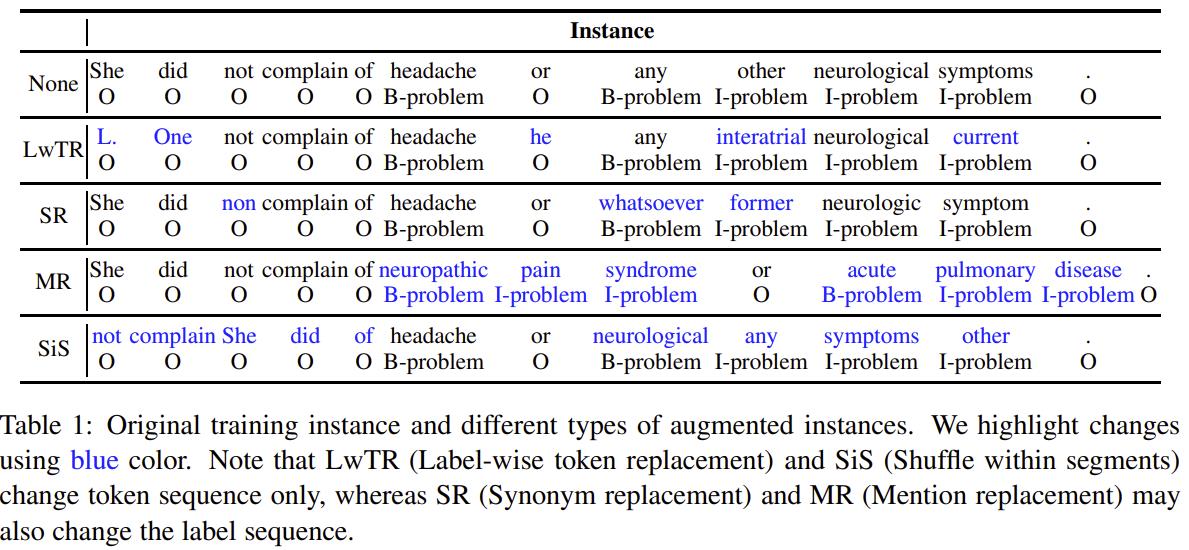
- **Label-wise token replacement (LwTR) **:即同标签token替换,对于每一token通过二项分布来选择是否被替换;如果被替换,则从训练集中选择相同的token进行替换。
- **Synonym replacement (SR) **:即同义词替换,利用WordNet查询同义词,然后根据二项分布随机替换。如果替换的同义词大于1个token,那就依次延展BIO标签。
- **Mention replacement (MR) **:即实体提及替换,与同义词方法类似,利用训练集中的相同实体类型进行替换,如果替换的mention大于1个token,那就依次延展BIO标签,如上图:「headache」替换为「neuropathic pain syndrome」,依次延展BIO标签。
- Shuffle within segments (SiS) :按照mention来切分句子,然后再对每个切分后的片段进行shuffle。如上图,共分为5个片段: [She did not complain of], [headache], [or], [any other neurological symptoms], [.]. 。也是通过二项分布判断是否被shuffle(mention片段不会被shuffle),如果shuffle,则打乱片段中的token顺序。
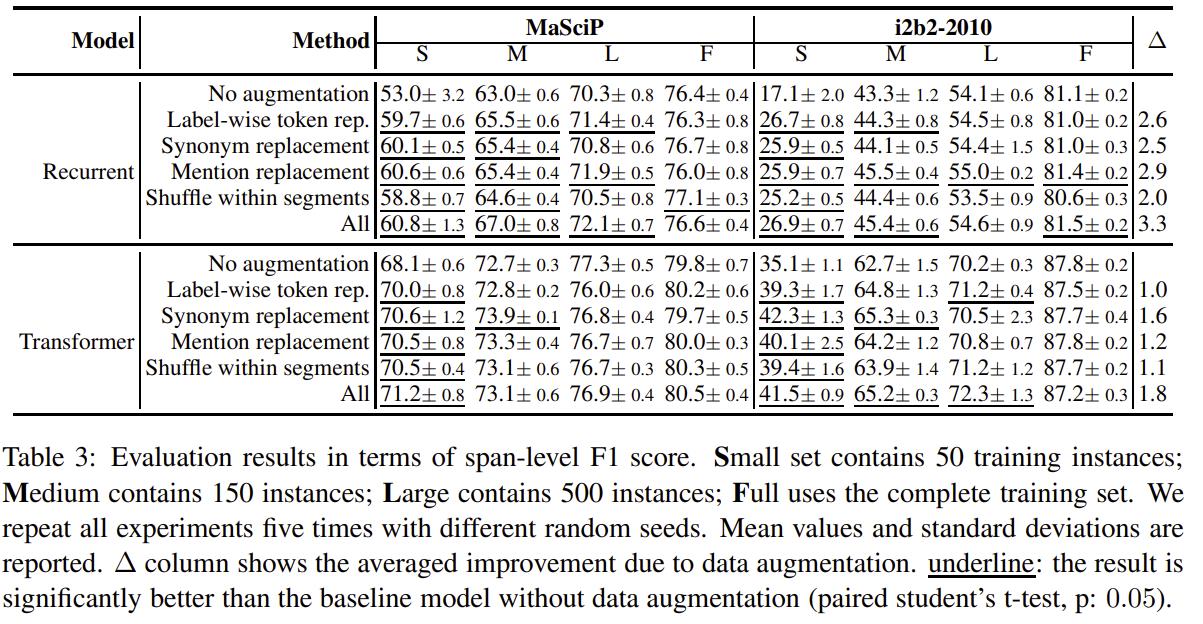
由上图可以看出:
- 各种数据增强方法都超过不使用任何增强时的baseline效果。
- 对于RNN网络,实体提及替换优于其他方法;对于Transformer网络,同义词替换最优。
- 总体上看,所有增强方法一起使用(ALL)会优于单独的增强方法。
- 低资源条件下,数据增强效果增益更加明显;充分数据条件下,数据增强可能会带来噪声,甚至导致指标下降;
DAGA: Data Augmentatino with a Generation Approach for Low-resource Tagging Tasks

DAGA的思想简单来讲就是标签线性化:即将原始的**「序列标注标签」与「句子token」进行混合,也就是变成「Tag-Word」**的形式,如下图:将「B-PER」放置在「Jose」之前,将「E-PER」放置在「Valentin」之前;对于标签「O」则不与句子混合。标签线性化后就可以生成一个句子了,文章基于此句子就可以进行「语言模型生成」了。
SeqMix

- 标题: SeqMix: Augmenting Active Sequence Labeling via Sequence Mixup
- 链接: https://rongzhizhang.org/pdf/emnlp20_SeqMix.pdf
- 开源代码: https://github.com/rz-zhang/SeqMix
- 备注: EMNLP 2020
Boundary Smoothing for Named Entity Recognition

- 标题: 针对命名实体识别的span类的算法的边界平滑
- code: https://github.com/syuoni/eznlp
An example of hard and smoothed boundaries. The example sentence has ten tokens and two entities of spans (1, 2) and (3, 7), colored in red and blue, respectively. The first subfigure presents the entity recognition targets of hard boundaries. The second subfigure presents the corresponding targets of smoothed boundaries, where the span (1, 2) is smoothed by a size of 1, and the span (3, 7) is smoothed by a size of 2. 其中周边区域有$\\epsilon$的概率会被赋值,此时原标注位置值为$1 - \\epsilon$,周边区域$D$赋值$\\epsilon / D$,
对NER标签位置的平滑处理,提升模型的泛化性。边界平滑可以防止模型对预测实体过于自信,从而获得更好的定标效果。D一般不用太大,1或者2即可, $\\epsilon$一般取[0.1, 0.2, 0.3] 
Footnotes
-
Steven Y. Feng, Varun Gangal, Jason Wei, Sarath Chandar, Soroush Vosoughi, Teruko Mitamura, & Eduard Hovy (2021). A Survey of Data Augmentation Approaches for NLP Meeting of the Association for Computational Linguistics. ↩ ↩2
-
Markus Bayer, Marc-André Kaufhold, & Christian Reuter (2021). A Survey on Data Augmentation for Text Classification.. arXiv: Computation and Language. ↩ ↩2
-
Li, B. , Hou, Y. , & Che, W. . (2021). Data augmentation approaches in natural language processing: a survey. ↩
-
Amit Chaudhary(2020). A Visual Survey of Data Augmentation in NLP. https://amitness.com/2020/05/data-augmentation-for-nlp ↩
 开发者涨薪指南
开发者涨薪指南
 48位大咖的思考法则、工作方式、逻辑体系
48位大咖的思考法则、工作方式、逻辑体系
以上是关于用于小规模低成本场景的kafka + eCAL架构设计的主要内容,如果未能解决你的问题,请参考以下文章