yolov5 代码解读 损失函数 loss.py
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了yolov5 代码解读 损失函数 loss.py相关的知识,希望对你有一定的参考价值。
参考技术A把one-hot label 转换为soft label,一般认为这样更容易work。
self.loss_fcn = nn.BCEWithLogitsLoss(reduction=\'none\') # must be nn.BCEWithLogitsLoss()
这里reduction用none因为在forward里返回的时候取mean。
刚开始看这几行非常confused,查了很久。
https://github.com/ultralytics/yolov5/issues/1030
这个issue里说减少false negative的影响,我觉得应该写错了,是减少false positive的影响。
false negative指gt有框而network没有predict到,这时候的weight应该要比较大才对。
,当 ,即 时,alpha_factor=0,这应该是false positive的情况。
直白的说,network觉得这里有一个obj,但是gt说没有,这种情况不应该过多的惩罚。
如果采用绝对值的话,会减轻pred和gt差异过大造成的影响。
假设gt是1,pred_prob如果很小,那么就是hard,这样算出来的p_t也会小,最后modulating_factor大。
对alpha_factor也是类似的。alpha_factor对应于foreground,一般设置为0.25。
这里modulating_factor的算法和QFL论文写的一致。
原本FL用class label,也就是one-hot discrete label来supervise;而QFL将其换成了IoU continuous label。
我们先明确一下p和targets的shape
p,也就是prediction,[num_dec_layer, batch_size, num_anchor, height, width, 85],这里85是80个class和4个offset以及1个confidence。
targets [nt, 6]
BCEcls, BCEobj是两个criteria,在scratch的hyp中g=0所以没有用focal loss,是普通的BCEloss
cp 和 cn 是soft label的probability,比如0.95 0.05。
balance控制obj loss的加权系数,autobalance决定加权系数也就是balance是否自动更新,autobalance一般是False。
self.balance = 3: [4.0, 1.0, 0.4] ,有三个layer的输出,第一个layer的weight是4,第二个1,以此类推。如果有5个layer的输出才用右边那个weight数组。
gr 是iou ratio。
targets就是这个batch里所有的labels,targets(img_idx, cls_idx, x, y, w, h),shape为[nt, 6]。可参考utils/datasets.py line 522, 599。
随便打印几行targets也可以验证我们的分析。
x, y, w, h是归一化后的结果。
先复制了三份一样的targets,在最后面加了一维表明anchor idx,本来是6现在变成7。
gain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gain t = targets * gain 这里是把 grid size 拿出来乘,恢复到特征图的维度。
在 match 里面比较简单,容易看懂,就是 anchor 和 target 不能差的太离谱,误差小于阈值就 match。
下一步在扩展 targets,个人认为是 positive examples 太少了,所以根据 center 在 cell 中的相对位置,添加相邻的两个 cell 作为 targets。
举个例子,如果 center 在 cell 的左上角,那么 cell 本身,和 cell 的左边一个位置,还有 cell 的上边一个位置,这三个 cell 都作为 targets。
我个人觉得这里的写法是非常巧妙的,取了 grid xy 和 inverse(类似于 flip)。
(gxy % 1. < g) ,这里的 g 是 0.5,如果仅考虑这个条件, 好像可以 直接判断是否选取左边 cell 和上边 cell。
但是要考虑到边界情况,如果当前已经处于最上方,已经没有上边 cell 可以选择了,这就是 (gxy > 1.) 起到的作用,判断 edge case。
如果本来大于 0.5,那么 inverse 后就小于 0.5 了,所以可以使用相同的逻辑选择右边 cell 和下边 cell ,类似地推理到 edge case。
最后一点要提的是使用 clamp_ 确保返回的 grid indices 不是非法值,旧版本 code 没用这个检查,不过好像也没什么差。
lcls, lbox, lobj 这三个用来存放loss,默认使用pytorch提供的BCE loss。
pxy = ps[:, :2].sigmoid() * 2. - 0.5 在learn的时候不需要加cx cy。
bbox回归的公式可以参考model/yolo.py line56, 57。
Objectness 这里 gr 设置为 1.0,也就意味着直接拿 iou 作为 confidence。
至于为什么返回 loss 的时候为什么要乘 bs,还不是很清楚,第二个返回值就是为了打印信息用的。
在train的时候,target是在feature map的scale。
在inference的时候,直接乘img map scale的anchor size就可以了,也就是配置文件里的anchor。
yolov5 优化系列:修改损失函数
1.使用 Focal loss
在util/loss.py中,computeloss类用于计算损失函数
# Focal loss
g = h['fl_gamma'] # focal loss gamma
if g > 0:
BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
其中这一段就是开启Focal loss的关键!!!
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
使用的data/hyps/hyp.scratch-low.yaml为参数配置文件,进去修改fl_gamma即可

fl_gamma实际上就是公式中红色椭圆的部分
看看代码更易于理解:
def forward(self, pred, true):
loss = self.loss_fcn(pred, true)
# p_t = torch.exp(-loss)
# loss *= self.alpha * (1.000001 - p_t) ** self.gamma # non-zero power for gradient stability
# TF implementation https://github.com/tensorflow/addons/blob/v0.7.1/tensorflow_addons/losses/focal_loss.py
pred_prob = torch.sigmoid(pred) # prob from logits
p_t = true * pred_prob + (1 - true) * (1 - pred_prob)
alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
modulating_factor = (1.0 - p_t) ** self.gamma
loss *= alpha_factor * modulating_factor
if self.reduction == 'mean':
return loss.mean()
elif self.reduction == 'sum':
return loss.sum()
else: # 'none'
return loss
调参上的技巧

1.1 增加alpha
focalloss其实是两个参数,一个参数就是我们前述的fl_gamma,同样的道理我们也可以增加fl_alpha来调节alpha参数
(1)进入参数配置文件

增加
fl_alpha: 0.95 # my focal loss alpha:nagetive example rate
(2)然后回到核心代码那里替换这一段
# Focal loss
g = h['fl_gamma'] # focal loss gamma
if g > 0:
a=h['fl_alpha']
BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
# ————————————————使用Varifocal Loss损失函数———————————————————————————————————
#BCEcls, BCEobj = VFLoss(BCEcls, g,a), VFLoss(BCEobj, g,a)
# print(BCEcls)
# print
# ————————————————使用Varifocal Loss损失函数———————————————————————————————————
Varifocal 和foacl loss二选一,另一个注释掉就行
(2)使用Varifocal Loss
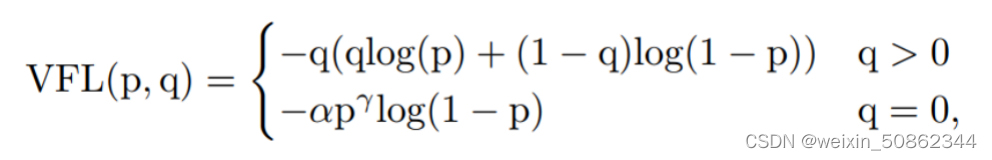
p输入为前景类的预测概率;q为ground-truth
class VFLoss(nn.Module):
def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
super(VFLoss, self).__init__()
# 传递 nn.BCEWithLogitsLoss() 损失函数 must be nn.BCEWithLogitsLoss()
self.loss_fcn = loss_fcn #
self.gamma = gamma
self.alpha = alpha
self.reduction = loss_fcn.reduction
self.loss_fcn.reduction = 'mean' # required to apply VFL to each element
def forward(self, pred, true):
loss = self.loss_fcn(pred, true)
pred_prob = torch.sigmoid(pred) # prob from logits
#p
focal_weight = true * (true > 0.0).float() + self.alpha * (pred_prob - true).abs().pow(self.gamma) * (
true <= 0.0).float()
loss *= focal_weight
if self.reduction == 'mean':
return loss.mean()
elif self.reduction == 'sum':
return loss.sum()
else:
return loss
true:q,即为ground-truth
(pred_prob - true):p,即前景类的预测概率
直接使用代码会报这个错
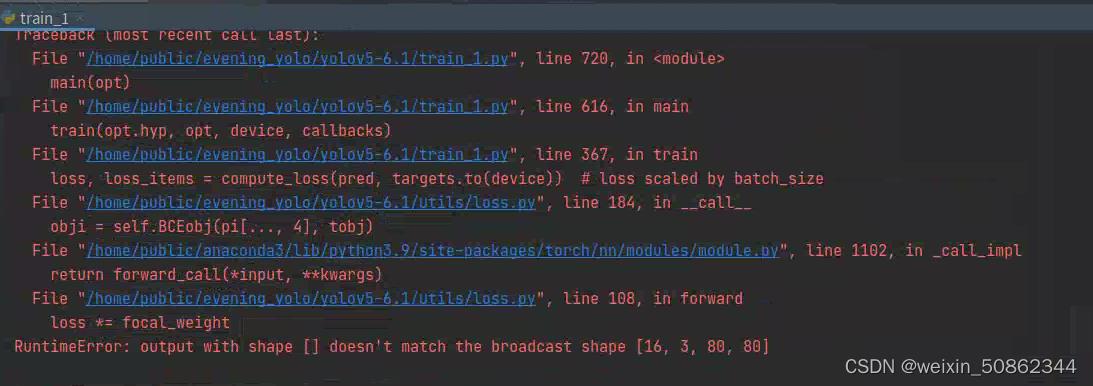
后面self.loss_fcn.reduction = 'mean'修改为self.loss_fcn.reduction = 'none'就没问题了
Focal loss和Varifocal Loss始终是不如原先的效果,可能很大一部分是参数问题
以上是关于yolov5 代码解读 损失函数 loss.py的主要内容,如果未能解决你的问题,请参考以下文章