对order by的理解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对order by的理解相关的知识,希望对你有一定的参考价值。
参考技术A前言
日常开发中,我们经常会使用到order by,亲爱的小伙伴,你是否知道order by 的工作原理呢?order by的优化思路是怎样的呢?使用order by有哪些注意的问题呢?本文将跟大家一起来学习,攻克order by~
一个使用order by 的简单例子
假设用一张员工表,表结构如下:
表数据如下:
我们现在有这么一个需求:查询前10个,来自深圳员工的姓名、年龄、城市,并且按照年龄小到大排序。对应的 SQL 语句就可以这么写:
这条语句的逻辑很清楚,但是它的底层执行流程是怎样的呢?
order by 工作原理
explain 执行计划
我们先用Explain关键字查看一下执行计划
我们可以发现,这条SQL使用到了索引,并且也用到排序。那么它是怎么排序的呢?
全字段排序
mysql 会给每个查询线程分配一块小内存,用于排序的,称为 sort_buffer。什么时候把字段放进去排序呢,其实是通过idx_city索引找到对应的数据,才把数据放进去啦。
我们回顾下索引是怎么找到匹配的数据的,现在先把索引树画出来吧,idx_city索引树如下:
idx_city索引树,叶子节点存储的是主键id。还有一棵id主键聚族索引树,我们再画出聚族索引树图吧:
我们的查询语句是怎么找到匹配数据的呢?先通过idx_city索引树,找到对应的主键id,然后再通过拿到的主键id,搜索id主键索引树,找到对应的行数据。
加上order by之后,整体的执行流程就是:
执行示意图如下:
将查询所需的字段全部读取到sort_buffer中,就是全字段排序。这里面,有些小伙伴可能会有个疑问,把查询的所有字段都放到sort_buffer,而sort_buffer是一块内存来的,如果数据量太大,sort_buffer放不下怎么办呢?
磁盘临时文件辅助排序
实际上,sort_buffer的大小是由一个参数控制的:sort_buffer_size。如果要排序的数据小于sort_buffer_size,排序在sort_buffer 内存中完成,如果要排序的数据大于sort_buffer_size,则借助磁盘文件来进行排序
如何确定是否使用了磁盘文件来进行排序呢?可以使用以下这几个 命令
可以从 number_of_tmp_files 中看出,是否使用了临时文件。
number_of_tmp_files 表示使用来排序的磁盘临时文件数。如果number_of_tmp_files>0,则表示使用了磁盘文件来进行排序。
使用了磁盘临时文件,整个排序过程又是怎样的呢?
TPS: 借助磁盘临时小文件排序,实际上使用的是归并排序算法。
小伙伴们可能会有个疑问,既然sort_buffer放不下,就需要用到临时磁盘文件,这会影响排序效率。那为什么还要把排序不相关的字段(name,city)放到sort_buffer中呢?只放排序相关的age字段,它不香吗?可以了解下rowid 排序。
rowid 排序
rowid 排序就是,只把查询SQL需要用于排序的字段和主键id,放到sort_buffer中。那怎么确定走的是全字段排序还是rowid 排序排序呢?
实际上有个参数控制的。这个参数就是max_length_for_sort_data,它表示MySQL用于排序行数据的长度的一个参数,如果单行的长度超过这个值,MySQL 就认为单行太大,就换rowid 排序。我们可以通过 命令 看下这个参数取值。
max_length_for_sort_data 默认值是1024。因为本文示例中name,age,city长度=64+4+64 =132 < 1024, 所以走的是全字段排序。我们来改下这个参数,改小一点.
使用rowid 排序的话,整个SQL执行流程又是怎样的呢?
执行示意图如下:
对比一下全字段排序的流程,rowid 排序多了一次回表。
什么是回表?拿到主键再回到主键索引查询的过程,就叫做回表”
我们通过optimizer_trace,可以看到是否使用了rowid排序的:
全字段排序与rowid排序对比
一般情况下,对于InnoDB存储引擎,会优先使用全字段排序。可以发现 max_length_for_sort_data 参数设置为1024,这个数比较大的。一般情况下,排序字段不会超过这个值,也就是都会走全字段排序。
order by的一些优化思路
我们如何优化order by语句呢?
联合索引优化
再回顾下示例SQL的查询计划
我们给查询条件city和排序字段age,加个联合索引idx_city_age。再去查看执行计划:
可以发现,加上idx_city_age联合索引,就不需要Using filesort排序了。为什么呢?因为索引本身是有序的,我们可以看下idx_city_age联合索引示意图,如下:
整个SQL执行流程变成酱紫:
流程示意图如下:
从示意图看来,还是有一次回表操作。针对本次示例,有没有更高效的方案呢?有的,可以使用覆盖索引:
覆盖索引:在查询的数据列里面,不需要回表去查,直接从索引列就能取到想要的结果。换句话说,你SQL用到的索引列数据,覆盖了查询结果的列,就算上覆盖索引了。”
我们给city,name,age 组成一个联合索引,即可用到了覆盖索引,这时候SQL执行时,连回表操作都可以省去啦。
调整参数优化
我们还可以通过调整参数,去优化order by的执行。比如可以调整sort_buffer_size的值。因为sort_buffer值太小,数据量大的话,会借助磁盘临时文件排序。如果MySQL服务器配置高的话,可以使用稍微调整大点。
我们还可以调整max_length_for_sort_data的值,这个值太小的话,order by会走rowid排序,会回表,降低查询性能。所以max_length_for_sort_data可以适当大一点。
当然,很多时候,这些MySQL参数值,我们直接采用默认值就可以了。
使用order by 的一些注意点:没有where条件,order by字段需要加索引吗
日常开发过程中,我们可能会遇到没有where条件的order by,那么,这时候order by后面的字段是否需要加索引呢。如有这么一个SQL,create_time是否需要加索引:
无条件查询的话,即使create_time上有索引,也不会使用到。因为MySQL优化器认为走普通二级索引,再去回表成本比全表扫描排序更高。所以选择走全表扫描,然后根据全字段排序或者rowid排序来进行。
如果查询SQL修改一下:
分页limit过大时,会导致大量排序怎么办?
假设SQL如下:
索引存储顺序与order by不一致,如何优化?
假设有联合索引 idx_age_name, 我们需求修改为这样:查询前10个员工的姓名、年龄,并且按照年龄小到大排序,如果年龄相同,则按姓名降序排。对应的 SQL 语句就可以这么写:
我们看下执行计划,发现使用到Using filesort
这是因为,idx_age_name索引树中,age从小到大排序,如果age相同,再按name从小到大排序。而order by 中,是按age从小到大排序,如果age相同,再按name从大到小排序。也就是说,索引存储顺序与order by不一致。
我们怎么优化呢?如果MySQL是8.0版本,支持Descending Indexes,可以这样修改索引:
使用了in条件多个属性时,SQL执行是否有排序过程
如果我们有联合索引idx_city_name,执行这个SQL的话,是不会走排序过程的,如下:
但是,如果使用in条件,并且有多个条件时,就会有排序过程。
这是因为:in有两个条件,在满足深圳时,age是排好序的,但是把满足上海的age也加进来,就不能保证满足所有的age都是排好序的。因此需要Using filesort。
SQL的GROUP BY 与 Order By
1、概述
“Group By”从字面意义上理解就是根据“By”指定的规则对数据进行分组,所谓的分组就是将一个“数据集”划分成若干个“小区域”,然后针对若干个“小区域”进行数据处理。
2、原始表
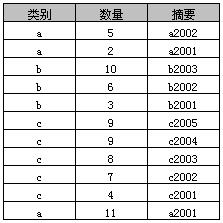
3、简单Group By
示例1
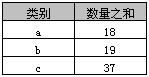
select 类别, sum(数量) as 数量之和 from A group by 类别
返回结果如下表,实际上就是分类汇总。
4、Group By 和 Order By
示例2
select 类别, sum(数量) AS 数量之和 from A group by 类别 order by sum(数量) desc
返回结果如下表
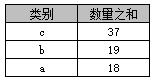
在Access中不可以使用“order by 数量之和 desc”,但在SQL Server中则可以。
5、Group By中Select指定的字段限制
示例3
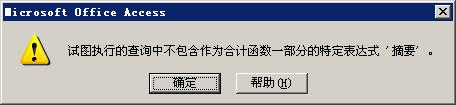
select 类别, sum(数量) as 数量之和, 摘要 from A group by 类别 order by 类别 desc
示例3执行后会提示下错误,如下图。这就是需要注意的一点,在select指定的字段要么就要包含在Group By语句的后面,作为分组的依据;要么就要被包含在聚合函数中。
6、Group By All
示例4
select 类别, 摘要, sum(数量) as 数量之和 from A group by all 类别, 摘要
示例4中则可以指定“摘要”字段,其原因在于“多列分组”中包含了“摘要字段”,其执行结果如下表
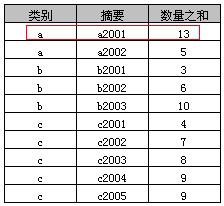
“多列分组”实际上就是就是按照多列(类别+摘要)合并后的值进行分组,示例4中可以看到“a, a2001, 13”为“a, a2001, 11”和“a, a2001, 2”两条记录的合并。
SQL Server中虽然支持“group by all”,但Microsoft SQL Server 的未来版本中将删除 GROUP BY ALL,避免在新的开发工作中使用 GROUP BY ALL。Access中是不支持“Group By All”的,但Access中同样支持多列分组,上述SQL Server中的SQL在Access可以写成
select 类别, 摘要, sum(数量) AS 数量之和 from A group by 类别, 摘要
7、Group By与聚合函数
在示例3中提到group by语句中select指定的字段必须是“分组依据字段”,其他字段若想出现在select中则必须包含在聚合函数中,常见的聚合函数如下表:
| 函数 | 作用 | 支持性 |
|---|---|---|
| sum(列名) | 求和 | |
| max(列名) | 最大值 | |
| min(列名) | 最小值 | |
| avg(列名) | 平均值 | |
| first(列名) | 第一条记录 | 仅Access支持 |
| last(列名) | 最后一条记录 | 仅Access支持 |
| count(列名) | 统计记录数 | 注意和count(*)的区别 |
示例5:求各组平均值
select 类别, avg(数量) AS 平均值 from A group by 类别;
示例6:求各组记录数目
select 类别, count(*) AS 记录数 from A group by 类别;
示例7:求各组记录数目
8、Having与Where的区别
- where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,where条件中不能包含聚组函数,使用where条件过滤出特定的行。
- having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件过滤出特定的组,也可以使用多个分组标准进行分组。
示例8
select 类别, sum(数量) as 数量之和 from A group by 类别 having sum(数量) > 18
示例9:Having和Where的联合使用方法
select 类别, SUM(数量)from A where 数量 gt;8 group by 类别 having SUM(数量) gt; 10
9、Compute 和 Compute By
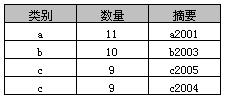
select * from A where 数量 > 8
执行结果:
示例10:Compute
select * from A where 数量>8 compute max(数量),min(数量),avg(数量)
执行结果如下:
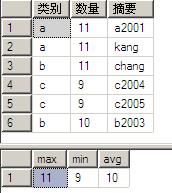
compute子句能够观察“查询结果”的数据细节或统计各列数据(如例10中max、min和avg),返回结果由select列表和compute统计结果组成。
示例11:Compute By
select * from A where 数量>8 order by 类别 compute max(数量),min(数量),avg(数量) by 类别
执行结果如下:
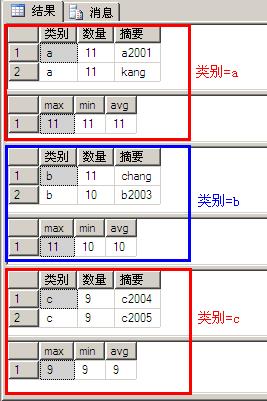
示例11与示例10相比多了“order by 类别”和“... by 类别”,示例10的执行结果实际是按照分组(a、b、c)进行了显示,每组都是由改组数据列表和改组数统计结果组成,另外:
- compute子句必须与order by子句用一起使用
- compute...by与group by相比,group by 只能得到各组数据的统计结果,而不能看到各组数据
在实际开发中compute与compute by的作用并不是很大,SQL Server支持compute和compute by,而Access并不支持
以上是关于对order by的理解的主要内容,如果未能解决你的问题,请参考以下文章
SQL语句的执行顺序怎么理解,特别是ORDER BY子句怎么理解?