)-ImageNet数据集的准备
Posted wyy_persist
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了)-ImageNet数据集的准备相关的知识,希望对你有一定的参考价值。
5.准备ImageNet数据集
一旦你下载了ImageNet数据集,你可能会有点不知所措。你现在有超过120万的图片驻留在磁盘上,没有一个人有“人类可读”文件的名字,没有一个明显的方式提取类标签,这是完全不清楚你应该培养一个定制的这些图像卷积神经网络——你自己变成了什么?
别担心,我帮你搞定。在本章中,我们将从理解ImageNet文件结构开始,包括原始图像和开发工具包(即“DevKit”)。从这里,我们将编写一个帮助器Python实用程序脚本,该脚本将使我们能够解析imagenetfilename +类标签,创建一个漂亮的输出文件,将给定的输入文件名映射到相应的标签(每行一个文件名和一个标签)。
最后,我们将使用这些输出文件和mxnet im2rec工具,它将采取我们的映射并创建高效打包的记录(.rec)文件,可以用于训练深度学习模型上的数据集太大,无法装入主内存。我们会发现,这个。rec格式不仅比HDF5更紧凑,而且它的I/O效率也更高,使我们能够更快地训练我们的网络。
我们在本章中应用的技术和工具将允许我们在后面的章节从ImageNet数据集上从头开始训练我们自己的定制cnn。在后面的章节中,比如我们关于汽车制造和车型识别以及年龄和性别预测的案例研究,我们将再次使用这些相同的工具来帮助我们创建图像数据集。
一定要密切关注这个数据集,并在处理它时花点时间。我们将要编写的代码不一定是“深度学习代码”,而是非常有用的实用脚本,它将促进我们在未来训练网络的能力。
//2022.2.7日晚上22:35开始学习笔记
5.1 了解ImageNet文件结构
让我们开始理解ImageNetfile的结构。我假设您已经完成了ILSVRC2015_CLS-LOC.tar的下载。gzfile,可能需要重新启动下载至少两到三次(当我个人下载了巨大的166GB存档时,它重新启动两次,总共花费了27.15小时下载)。然后,我使用以下命令解压存档:
我建议在上床睡觉之前启动这个命令,以确保在早上醒来时它已经完全打开。请记住,仅在训练集中就有超过120万张图像,因此解压过程将需要一些时间。
一旦tarball完成解压缩,你就会有一个名为ILSVRC2015的目录:
首先,我们有Annotations目录。此目录仅用于本地化挑战(即,对象检测),因此我们可以忽略此目录。
Data目录更重要。在内部数据中,我们将找到一个名为CLS-LOC的子目录:
在这里,我们可以找到培训、测试和验证的“分割”:

我之所以在引文中提到“分割”这个词,是因为我们还需要做很多工作,才能以一种格式获得这些数据,这样我们就可以在这些数据上训练卷积神经网络,并获得最先进的分类结果。让我们继续,分别查看每一个子目录。
5.1.1 测试目录
测试目录中包含100000个图像,1000个类,每个类中有100张图片;
每个类有100个数据点;
然而,我们无法将这些图像直接用于我们的实验。回忆一下,ILSVRC挑战实际上是图像分类算法的标准。为了保持这个挑战的公平性(并确保没有人作弊),测试集的标签保持私有。
首先,一个人/团队/组织使用培训和测试拆分来训练他们的算法。一旦他们对结果感到满意,就会对测试集进行预测。然后,来自测试集的预测会自动上传到ImageNet评估服务器,在那里它们会与ground-truth标签进行比较。在任何情况下,任何竞争对手都没有接触到测试真实的标签。ImageNet评估服务器然后返回它们的总体精度。
本书的一些读者可能可以访问ImageNet评估服务器,在这种情况下,我鼓励您进一步探索这种格式,并考虑提交您自己的预测。然而,许多其他读者并没有直接在ImageNet网站注册帐户就获得了ImageNet。任何一种方式都是完全可以的(前提是您遵守我在第4章中提到的许可协议),但是您将不能访问评估服务器。因为我想保持这一章的开放性和可访问所有人,无论你如何获得ImageNet,我们将忽略测试目录,创建我们自己的测试集样本训练数据,就像我们对小ImageNet挑战的第11章和第十二章医生包。
5.1.2 训练数据集目录
ImageNet的train目录由一组子目录组成:

//截止到2022.2.7日晚上23:06
//2022.2.23日晚上22:42开始学习笔记
从P33页开始学习
首先,这些子目录名可能看起来不可读。然而,回想一下ImageNet上的第4章,数据集是根据WordNet ID[10]组织的,这些ID被称为同义词集或简称为“syn集”。语法集映射到特定的概念/对象,例如金鱼、秃鹰、飞机或原声吉他。因此,在这些奇怪标记的子目录中,每个类大约有732-1300张图像。
例如,WordNet ID n01440764包含1300张“tench”图片,这是一种欧洲淡水鱼,与小鱼家族关系密切(图5.1):
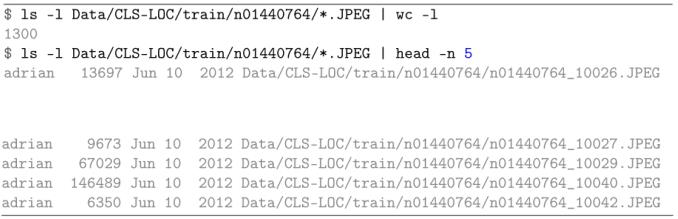

假设训练图像的WordNet ID与训练cls一起内置到文件名中。txtfile我们将在本章后面回顾,对于我们来说,将给定的训练图像与其类标签相关联是相当简单的。
//截止到2022.2.23晚上23:14
//2022.2.24日下午5:44开始学习笔记
5.1.3 ImageNet validation目录
与测试目录类似,val目录每个类包含50000个图像(1000个类中每个类包含50个图像):
这50000个图像中的每一个都存储在一个“平面”目录中,这意味着没有额外的子目录用于帮助我们将给定图像与类标签关联:
此外,通过检查文件名,您可以看到文件路径中没有类标签标识信息(如WordNet ID等)。幸运的是,我们将在本章后面回顾一个名为val.txt的文件,它为我们提供了从文件名到类标签的映射。
此外,通过检查文件名,您可以看到文件路径中没有类标签标识信息(如WordNet ID等)。幸运的是,我们将在本章后面回顾一个名为val.txt的文件,它为我们提供了从文件名到类标签的映射。
5.1.4 ImageNet“ImageSets”目录
现在,我们已经浏览了train、test和val子目录,让我们回到注释和数据文件夹。在这里,您将看到一个名为ImageSets的目录。让我们将目录更改为ImageSet并进行调查:
我们可以忽略测试。因为我们将根据训练数据构建自己的测试。然而,我们需要看看这两个列车的cls。txt(其中“cls”代表“分类”)和val.txt。这些文件包含训练图像(1281167)和验证图像(50000)的基本文件名。可以使用以下命令验证此事实:
该文件报告了总共1331167个要处理的图像。调查列车cls。txt,您可以看到内容只是一个基本图像文件名(不带文件扩展名)和一个唯一的整数ID,每行一行:

基本imagefilename将允许我们导出完整的imagefilename。唯一整数只是一个递增的计数器,每行递增一个。
val.txt也是如此:
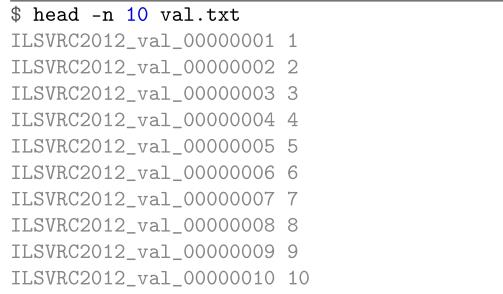
图像的唯一整数ID没有太大帮助,除非我们需要确定“黑名单”图像。ImageNet数据集策展人标记为“黑名单”的图像在其类别标签中过于模糊,因此不应在评估过程中予以考虑。在本章后面,我们将循环检查所有黑名单上的图像,并通过检查与每个验证图像关联的唯一整数ID将它们从验证集中删除。
使用列车cls的好处。txt和val.txt文件是我们不必使用路径列出培训和验证子目录的内容。列出图片–相反,我们可以简单地循环这些图片中的每一行。TXT文件。在本章后面的部分,我们将使用这两个文件,将原始ImageNetFile转换为。rec格式,适用于使用mxnet进行培训。
5.1.5 ImageNet“DevKit”目录
除了在第4章中下载原始图像本身,您还下载了ILSVRC 2015 DevKit。此存档包含我们需要将imagefile名称映射到其相应类标签的实际索引文件。您可以取消ILSVRC2015_devkit的归档。焦油gzfile使用以下命令:
从技术上讲,你可以把这个文件放在你系统中任何你喜欢的地方(因为我们将创建一个Python配置文件来指向重要的路径位置);然而,出于组织目的,我个人喜欢将其与注释、数据和图像集子目录一起保存。我建议您复制devkit目录,以便它与我们的注释、数据和图像集目录共存:
您在此处指定的确切路径将取决于您的系统。我只是展示了我在个人系统上运行的示例命令。实际使用的命令将是相同的,但需要更新相应的文件路径。
有关复制和分发ImageNet数据集及相关评估软件的更多信息,请阅读COPYINGfile。自述。txtfile包含关于ILSVRC挑战的信息,包括数据集的结构(我们在本章中提供了对数据集的更详细的回顾)。顾名思义,评估目录包含用于评估测试集预测的MATLAB例程——因为我们将导出自己的测试集,所以可以忽略此目录。
最重要的是,我们有数据目录。在数据中,你会发现许多元文件,包括MATLAB和纯文本(.txt)格式:

在此目录中,我们最关心的是以下三个文件:
- map_clsloc.txt
- ILSVRC2015_clsloc_validation_ground_truth.txt
- ILSVRC2015_clsloc_validation_blacklist.txt
这张地图。txtfile将我们的WordNet ID映射到人类可读的类标签,因此是将WordNet ID转换为人类可以解释的标签的最简单方法。通过列出该文件的前几行,我们可以看到映射本身:

在这里,我们可以看到WordNet ID n02119789映射到kit_fox类别标签。n02096294 WordNet ID对应于澳大利亚_梗,一种狗。ImageNet数据集中的所有1000个类都将继续此映射。如上文第5.1.3节所述,val目录中的图像不包含文件名中内置的任何类别标签信息;但是,我们确实在ImageSets目录中有val.txt文件。val.txt文件列出了验证集的(部分)图像文件名。val.txt文件中有50000个条目(每行)。ILSVRC2015\\u clsloc\\u validation\\u ground\\u truth中也有50000条条目(每行一条)。txt。
让我们看看这些条目:

正如我们所见,每一行上都列出了一个整数。获取val.txt的第一行和ILSVRC2015的第一行_clsloc_validation_ground_truth。我们最终会得到:
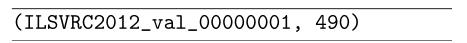

如果我们要开放ILSVRC2012_val_u00000001。JPEG我们将看到图5.2中的图像。很明显,这是一种蛇——但是什么类型的蛇呢?如果我们检查地图。txt,我们看到带有490的类标签ID是WordNet ID n01751748,这是一条海蛇:

因此,我们需要同时使用val.txt和ILSVRC2015_clsloc_validation_ground_truth。txt来构建我们的验证集。
我们也来看看ILSVRC2015_clsloc_validation_黑名单的内容。txt:

正如我之前提到的,一些ValidationFile在其类标签中被认为过于模糊。因此,ILSVRC组织者将这些图像标记为“黑名单”,这意味着它们不应包含在验证集中。在构建验证集时,我们需要检查此黑名单集的验证图像ID–如果我们发现给定图像属于此集合,我们将忽略它并将其从验证集中排除。
如您所见,构建ImageNet数据集需要许多文件。我们不仅需要原始图像本身,还需要大量的数据。txtfiles用于构造从原始training和validationfilename到相应类标签的映射。这将是一个很难手动执行的过程,因此在下一节中,我将向您展示我个人在构建ImageNet数据集时使用的ImageNetHelper类。
5.2 构建ImageNet数据集
//截止到P39页
构建ImageNet数据集的总体目标是,我们可以从零开始训练卷积神经网络。因此,我们将在为CNN准备ImageNet数据集的上下文中回顾如何构建ImageNet数据集。为此,我们首先定义一个配置文件,该文件存储所有相关的图像路径、纯文本路径和我们希望包含的任何其他设置。
从那里,我们将定义一个名为ImageNetHelper的Python类,它将使我们能够快速而轻松地构建:
- 我们的。lst文件用于培训、测试和验证分离。lst文件中的每一行都包含唯一的图像ID、类标签和输入图像的完整路径。然后,我们将能够将这些.lst文件与mxnet工具im2rec结合使用,将我们的图像文件转换为一个高效打包的记录文件。
- 训练集的红、绿、蓝通道平均值,我们稍后将在执行均值归一化时使用。
5.2.1 第一个ImageNet配置文件
每当在ImageNet上训练CNN时,我们将创建一个具有以下目录结构的项目:

正如目录和文件名所示,这个配置文件是针对AlexNet的。在config目录中,我们放置了两个文件:
__init__.py文件将config转换为一个Python包,实际上可以通过import语句导入到我们自己的脚本中——这个文件使我们能够在实际配置中使用Python语法/库,使得为ImageNet配置神经网络的过程更容易。实际的ImageNet配置然后存储在imagenet_alexnet_config.py中。
我决定创建一个别名为ImageNet的符号链接(通常称为“符号链接”或“捷径”),而不是输入ImageNet数据集的完整路径(即/raid/datasets/ ImageNet /)。这节省了我大量的击键和输入长的路径。在下面的例子中,你可以看到(1)lists目录的完整路径和(2)符号链接版本:

要创建自己的符号链接(在基于unix的环境中),可以使用ln命令。下面的示例命令将在我当前的工作目录中创建一个名为imagenet的符号链接,它链接到我/raid驱动器中的完整的imagenet数据集:

你可以修改上面的命令到你自己的路径。
无论你选择在哪里存储你的基础ImageNet数据集目录,现在花时间创建两个子目录- list和rec:

在上面的命令中,我假设您已经创建了一个名为imagenet的符号链接,以指向基本数据集目录。如果不是,请指定您的完整路径。列表和rec子目录将在本章后面用到。
py脚本将负责构建从输入图像文件到输出类标签的映射。脚本train_alexnet.py将用于在ImageNet上从头开始训练AlexNet。最后,test_alexnet.py脚本将用于评估AlexNet在我们的测试集中的性能。
后两个脚本将在第6章中讨论,所以现在,让我们简单地回顾一下imagenet_alexnet_config.py——在本书中,我们运行的所有ImageNet实验中,这个文件将基本上保持不变。因此,花点时间理解这个文件的结构是很重要的。
继续,打开imagenet_alexnet_config.py,插入以下代码:
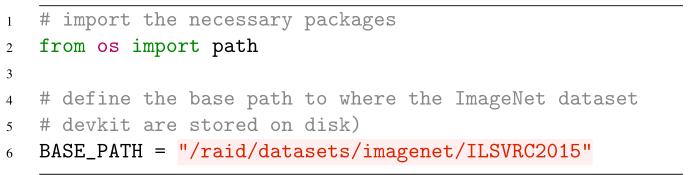
第2行导入了我们唯一需要的Python包,path子模块。path子模块包含一个名为path的特殊变量。这是操作系统的路径分隔符。在Unix机器上,路径分隔符是/——示例文件的路径可能看起来像/to/your/file.txt。然而,在Windows上,路径分隔符是\\,使得示例文件的路径路径为\\到\\file.txt。我们希望配置工作与操作系统无关,因此我们将使用该path.sep变量随时方便。
然后,第6行定义了ImageNet数据集在磁盘上的BASE_PATH。这个目录应该包含您的四个注释、数据、devkit和ImageSets目录。
由于ImageNet数据集的大小,我决定将所有ImageNet相关文件存储在系统的RAID驱动器上(这就是为什么你看到BASE_PATH以/ RAID开头)。你应该修改BASE_PATH,并将其更新到ImageNet数据集存储在系统中的位置。您可以随意使用我们在之前的Python深度学习计算机视觉示例中使用的数据集目录——如果您在主分区上有足够的空间来存储整个数据集,那么数据集项目结构将会工作得很好。
我想再次提醒您,您需要在自己的系统上更新BASE_PATH变量——现在请花点时间来做这件事。
从BASE_PATH中,我们可以得到三个更重要的路径:

IMAGES_PATH与BASE_PATH连接在一起,指向包含测试、训练和val图像的原始图像的目录。IMAGE_SETS_PATH指向包含重要的train_cl .txt和val.txt文件的目录,这些文件显式地列出了每个集合的文件名。最后,正如它的名字所暗示的,DEVKIT_PATH是我们的DevKit所在的基本路径,特别是我们将在第5.1.5节中解析的纯文本文件。
说到DevKit,让我们定义WORD_IDS,它是map_clsloc.txt文件的路径,该文件将1000个可能的WordNet id映射到(1)唯一的标识整数和(2)人类可读的标签。

为了构建我们的训练集,我们需要定义TRAIN_LIST路径,该路径包含训练数据的≈120万个(部分)图像文件名:

定义一些验证配置:

VAL_LIST变量指向ImageSets目录下的val.txt文件。提醒一下,val.txt列出了50,000个验证文件的(部分)图像文件名。为了获得验证数据的ground-truth标签,我们需要定义VAL_LABELS路径——这样做使我们能够将单个图像文件名与类标签连接起来。最后,VAL_BLACKLIST文件包含被列入黑名单的验证文件的唯一整数id。当我们构建ImageNet数据集时,我们将明确地注意确保这些图像不包含在验证数据中。
在下一个代码块中,我们定义了NUM_CLASSES变量和NUM_TEST_IMAGES变量:

对于ImageNet数据集,有1000个可能的图像类,因此NUM_CLASSES被设置为1000。为了得到我们的测试集,我们需要从训练集中采样图像。我们将NUM_TEST_IMAGES设置为50 × 1000 = 50,000张图片。正如我前面提到的,我们将使用im2rec mxnet工具将磁盘上的原始图像文件转换为适合使用mxnet库进行培训的记录文件。
为了完成这个操作,我们首先需要定义MX_OUTPUT路径,然后派生几个其他变量:

所有由(1)我们的Python帮助工具或(2)im2rec二进制文件输出的文件都将存储在基目录MX_OUTPUT中。基于我组织数据集的方式(详见Starter Bundle的第6章),我选择将所有输出文件包含在imagenet目录中,该目录还存储了原始图像、DevKit等。你应该将输出文件存储在任何你觉得舒服的地方——我只是提供了一个如何在我的机器上组织数据集的示例。
如前所述,在应用Python实用程序脚本之后,我们将剩下三个文件——train。Lst, val.lst和test。lst—这些文件将包含(整数)类标签id和每个数据分割的图像文件名的完整路径(第40-42行)。然后,im2rec工具将这些。lst文件作为输入,并创建。rec文件,存储实际的原始图像+类标签在一起,类似于构建一个HDF5数据集在第十章的实践者:

这里的区别是这些记录文件要紧凑得多(因为我们可以将图像存储为压缩的JPEG或PNG文件,而不是原始的NumPy数组位图)。此外,这些记录文件仅用于mxnet库,允许我们获得比原始HDF5数据集更好的性能。
出于组织目的,我选择在imagenet目录中包含列表和rec子目录——我强烈建议你也这么做。如果您遵循我的目录结构,现在请花时间创建您的列表和rec子目录。如果等到我们检查并执行build_imagenet.py时,您可能会忘记创建这些子目录,从而导致脚本出错。但别担心!你可以简单地回去创建列表,rec和重新执行脚本。
当构建我们的数据集时,我们需要为每个RGB通道计算DATASET_MEAN以便执行均值归一化:

该配置只以JSON格式存储方法将被序列化到磁盘的路径。假设你在同一台机器上运行所有的实验(或者至少是在具有相同ImageNet目录结构的机器上),你必须从实验到实验编辑的唯一配置如下:

第54行定义了BATCH_SIZE,在训练期间,图像将在其中通过网络传递。对于AlexNet,我们将使用128个小批量。根据给定CNN的深度,我们可能希望减少这个批大小。NUM_DEVICES属性控制在训练给定的神经网络时使用的设备数量(是否为cpu、gpu等)。你应该根据机器上可供培训的设备数量来配置这个变量。
5.2.2 我们的ImageNet帮助工具
现在我们已经创建了一个示例配置文件,接下来让我们进入ImageNetHelper类,我们将使用它分别为训练、测试和验证分割生成.lst文件。这个类是一个重要的实用工具助手,所以我们将更新pyimagesearch模块,并将其存储在utils子模块中的imagenethelper.py文件中:

继续打开imagenethelper.py,我们将定义实用程序类:

第6行定义了ImageNetHelper的构造函数。构造函数只需要一个参数:一个名为config的对象。该配置实际上是我们在前一节中定义的imagenet_alexnet_config文件。通过将这个文件作为一个对象传递给ImageNetHelper,我们可以访问所有的文件路径和其他配置。然后在第11行和第12行上构建标签映射和验证黑名单。我们将在本节的后面回顾buildClassLabels和buildBlacklist方法。
让我们从buildClassLabels开始:

在第17行,我们读取了WORD_IDs文件的全部内容,该文件将WordNet id映射到(1)表示该类的唯一整数和(2)人类可读的标签。然后,我们定义labelMappings字典,它以WordNet ID作为键,以整数类标签作为值。
现在,整个WORD_IDS文件已经加载到内存中,我们可以循环遍历每一行:
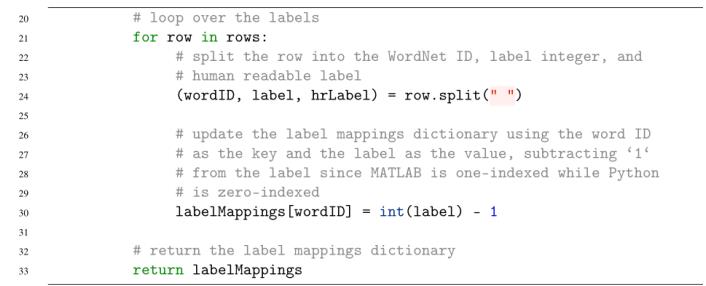
对于每一行,我们将其分解为一个三元组(因为行中的每一项都用一个空格隔开),包括:

现在我们有了这些值,我们可以更新我们的labelMappings字典。字典的关键是WordNet ID, wordID。我们的值就是标签的值减去1。
为什么要减1 ?请记住,ILSVRC提供的ImageNet工具是使用MATLAB构建的。MA TLAB编程语言是1索引的(意味着它从1开始计数),而Python编程语言是0索引的(我们从0开始计数)。因此,要将MA TLAB索引转换为Python索引,我们只需从标签中减去一个值1。
在第33行,将labelMappings字典返回给调用函数。
接下来我们有buildBlacklist函数:

这个函数非常简单。在第38行,我们读取了VAL_BLACKLIST文件的全部内容。VAL_BLACKLIST文件包含验证文件的唯一整数名(每行一个),由于标签不明确,我们应该从验证集中排除这些文件。我们只需将字符串分解为一个列表(以换行符(newline \\n)分隔),并将行转换为set对象。set对象允许我们在O(1)时间内确定给定的验证图像是否属于黑名单。
我们的下一个函数负责摄取TRAIN_LIST和IMAGES_PATH配置,为训练集构造一组图像路径和相关的整数类标签:
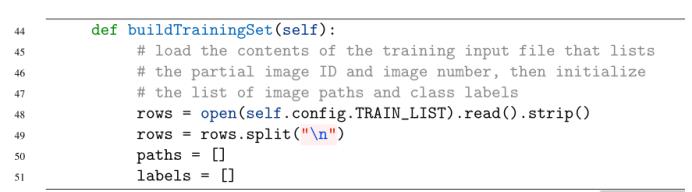
在第48行,我们加载了TRAIN_LIST文件的全部内容,并在第49行将其分成几行。回想一下,TRAIN_LIST文件包含了图像文件的部分路径——train_cl .txt文件的示例如下:

我们的工作是为(1)完整的图像路径和(2)相应的类标签构建两个列表(第50和51行)。为了构建列表,我们需要分别遍历每一行:

每一行由两个条目组成——训练图像文件的partialPath(例如,n01440764/ n01440764_10026)和imageNum。imageNum变量只是一个簿记计数器——它在构建训练集时没有任何作用;我们会忽略它。第63行和64行负责构建到给定IMAGES_PATH和partialPath的训练图像的完整路径。
该路径由三个组件组成:
- IMAGES_PATH,我们所有的train, test和val目录都在这里。
- 硬编码的训练字符串,它表明我们正在为训练图像构建一个文件路径。
- partialPath,它是映像本身的子目录和基文件名。
我们将文件扩展名附加到. jpeg以创建最终的图像路径。下面是一个示例路径:

在调试用于生成这些.lst文件的Python脚本时,请确保在继续之前验证文件路径。我建议使用简单的ls命令来检查该文件是否存在。如果ls返回并告诉您文件路径不存在,那么您就知道您的配置中出现了错误。
在第65行,我们提取了worddid。wordID是partialPath的子目录,因此,我们只需对/字符进行拆分,就可以提取wordID。一旦有了wordID,就可以在labelMappings中查找相应的整数类标签(第66行)。
给定路径和标签,我们可以分别更新路径和标签列表:

第74行返回调用函数的路径和标签的二元组。这些值稍后将使用(待定义的)build_dataset.py脚本以.lst文件的形式写入磁盘。
我们需要创建路径的最后一个函数是buildValidationSet,它负责构建我们的验证图像路径和验证类标签:
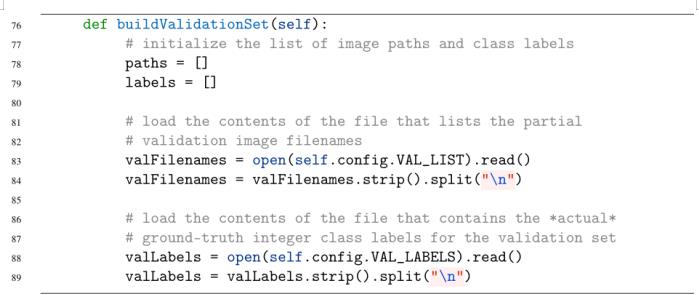
我们的buildValidationSet函数与我们的buildTrainingSet非常相似,只是增加了一些额外的东西。首先,我们初始化图像路径列表和类标签(第78和79行)。我们加载VAL_LIST的内容,其中包含验证文件的部分文件名(第83和84行)。为了构建类标签,我们需要读入VAL_LABELS的内容——这个文件包含VAL_LIST中每个条目的整数类标签。
给定valfilename和vallabel,我们可以创建路径和标签列表:
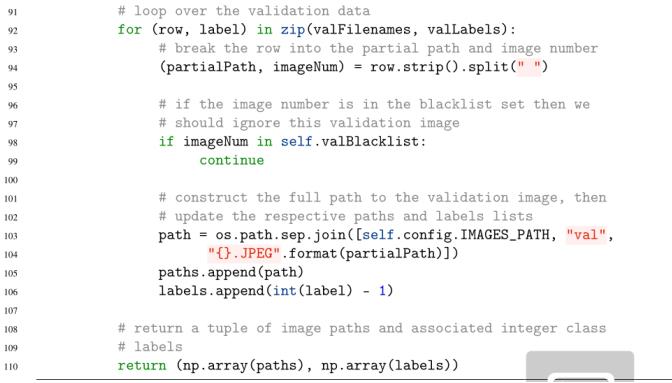
在第92行,我们循环遍历每个valfilename和vallabel。我们解压第94行中的行,以提取partialPath和imageNum。不像在训练集中,imageNum在这里很重要——我们检查第98行和第99行,看看imageNum是否在黑名单集中,如果是,我们忽略它。
然后,第103行和第104行构造到验证文件的路径。我们在第105行更新了路径列表。然后在第106行更新标签列表,在那里,我们再次小心地将标签减去1,因为索引为0。最后,第110行向调用函数返回验证路径和标签的二元组。
现在ImageNetHelper已经定义好了,我们可以继续构造.lst文件,这些文件将被提交到im2rec中。
5.2.3 创建list和均值文件
就像前面几章中的build_*.py脚本一样,build_imagenet.py脚本看起来非常相似。在高水平上,我们将:
- 构建训练集。2. 构建验证集。3.通过对训练集进行采样来构造测试集。4. 遍历每个集合。5. 将映像路径+相应的类标签写入磁盘。
现在让我们开始build_imagenet.py:

第2行导入imagenet_alexnet_config模块,并将其别名为config。然后,我们从scikit-learn中导入train_test_split函数,这样我们就可以从我们的训练集构造一个测试分割。我们还将导入新定义的ImageNetHelper类,以帮助我们构建imageNet数据集。
接下来,我们可以构建训练和验证路径+类标签:

然后我们需要从trainPaths和trainLabels中取样NUM_TEST_IMAGES来构造我们的测试分割:

从这里开始,我们的代码看起来与我们之前使用Python进行计算机视觉深度学习的“数据集构建”脚本几乎相同:

第28-31行定义了一个数据集列表。数据集列表中的每个条目都是一个4元组,由4个值组成:1。拆分的类型(例如,培训、测试或验证)。2. 图片路径。3.图像标签。4. mxnet所需的输出.lst文件的路径。
我们还将在第34行初始化RGB通道的平均值。接下来,让我们循环遍历数据集列表中的每个条目:

第40行打开了一个指向outputPath的文件指针。然后在第43-46行构建一个progressbar小部件。进度条当然是不需要的,但是我发现在构建数据集时提供ETA信息是很有帮助的(计算可能需要很长时间)。
我们现在需要在split中的每个单独的图像和标签上循环:
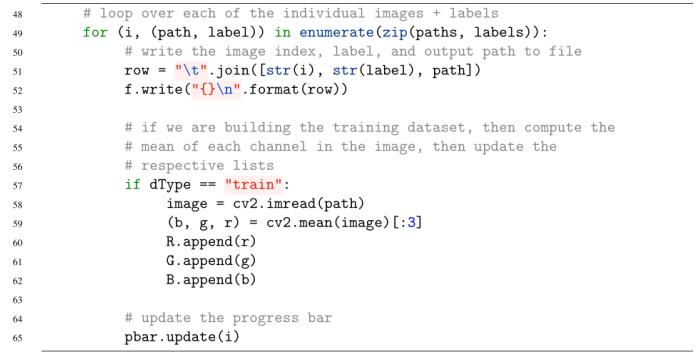
对于每个路径和标签,我们向输出的.lst文件中写入三个值:
- 索引i(这是一个唯一的整数,mxnet可以与集合中的图像关联)。
- 整数类标签。
- 映像文件的完整路径。
每个值都由制表符分隔,每行有一组值。下面是这样一个输出文件的示例:

然后,mxnet中的im2rec工具将获取这些.lst文件,并构建我们的.rec数据集。在第57-62行,我们检查我们的数据集类型是否为train -如果是,我们计算图像的RGB平均值并更新相应的通道列表。
我们的最终代码块处理清理文件指针和序列化RGB意味着磁盘:

执行脚本结果:
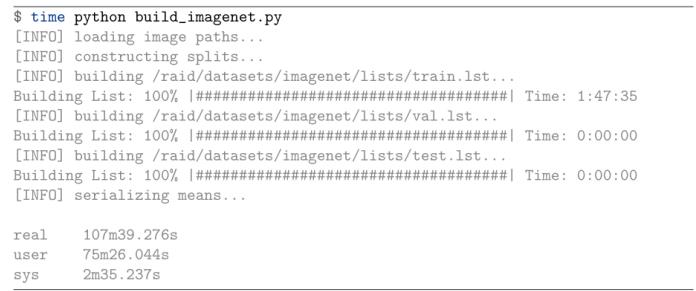
正如您所看到的,训练集以107m39秒完成所需的时间最长,这是因为120万张图像中的每一张都需要从磁盘加载并计算其平均值。测试和验证.lst文件以一种秒的方式写入磁盘,因为我们所需要做的只是将图像路径和标签写入文件(不需要额外的I/O)。
要验证培训、测试和验证文件的.lst文件是否成功创建,请检查MX_OUTPUT目录的内容。下面你可以找到我的MX_OUTPUT/lists目录(我选择存储.lst文件)的内容:

对每个文件进行行数,我们的测试集中有50,000张图片,验证集中有50,000张图片,测试集中有1,231,167张图片:
给定这些.lst文件,让我们使用mxnet的im2rec构建我们的记录打包数据集。
5.2.4 构建紧凑的记录文件
现在我们有了.lst文件,为每个单独的培训、测试和验证文件构建.rec文件是轻而易举的事。下面你可以找到我的示例命令来生成火车。使用mxnet的im2rec二进制文件:

在我的系统上,我编译了mxnet库在我的主目录;因此,im2rec的全路径为“/mxnet/im2rec”。你可能需要调整这个路径,如果你编译mxnet在您的机器上的不同位置。另一种解决方案是简单地将im2rec二进制文件放在系统的PATH中。
im2rec的第一个参数是输出序列的路径。这个路径应该匹配imagenet_alexnet_config.py上的TRAIN_MX_LIST变量。第二个参数是一个空字符串。这个参数表示映像文件的根路径。因为我们已经在.lst文件中导出了磁盘上映像的完整路径,所以可以简单地将该参数留空。然后,我们有了im2rec的最终必需参数——这是我们输出记录文件数据库的路径,压缩的图像和类标签将存储在这里。这个参数应该匹配imagenet_alexnet_config.py中的TRAIN_MX_REC变量。
接下来,我们为im2rec提供三个可选参数:
- resize:这里我们指出我们的图像应该沿着最短的尺寸调整为256像素。这种调整不仅降低了图像的输入分辨率(从而减少了输出.rec文件的大小),还使我们能够在训练过程中进行数据增强。
- encoding:这里我们可以提供JPEG或PNG编码。我们将使用
以上是关于)-ImageNet数据集的准备的主要内容,如果未能解决你的问题,请参考以下文章